Abstract :MRS Support large data storage capacity 、 When computing resources need elastic expansion , Users store data in OBS In service , Use MRS The storage and calculation separation mode in which the cluster only performs data calculation and processing .
This article is shared from Huawei cloud community 《【 Cloud class 】EI The first 47 course MRS Offline data analysis - adopt Flink Job handling OBS data 》, author :Hello EI .
MRS Support large data storage capacity 、 When computing resources need elastic expansion , Users store data in OBS In service , Use MRS The storage and calculation separation mode in which the cluster only performs data calculation and processing .
Flink It is a unified computing framework combining batch processing and stream processing , Its core is a stream data processing engine that provides data distribution and parallel computing . Its biggest highlight is stream processing , It is the top open source stream processing engine in the industry .
This article will show you how to MRS Running in cluster Flink Homework to deal with OBS Data stored in .

Flink The most suitable application scenario is low latency data processing (Data Processing) scene : High concurrency pipeline Processing data , The delay is in the order of milliseconds , And both reliability .

In this example , We use MRS Cluster built-in Flink WordCount Operation procedure , To analyze OBS Source data saved in the file system , Count the number of word occurrences in the source data .
Of course, you can also get MRS Service sample code project , Reference resources Flink Development guide development others Flink Flow operation procedure .
The basic operation process of this case is as follows :
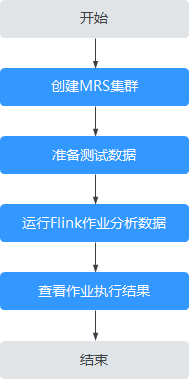
establish MRS colony
Create and purchase one that includes Flink Component's MRS colony , For details, see Buy custom clusters .
This article is based on the purchase MRS 3.1.0 Take the cluster of version , Cluster not turned on Kerberos authentication .
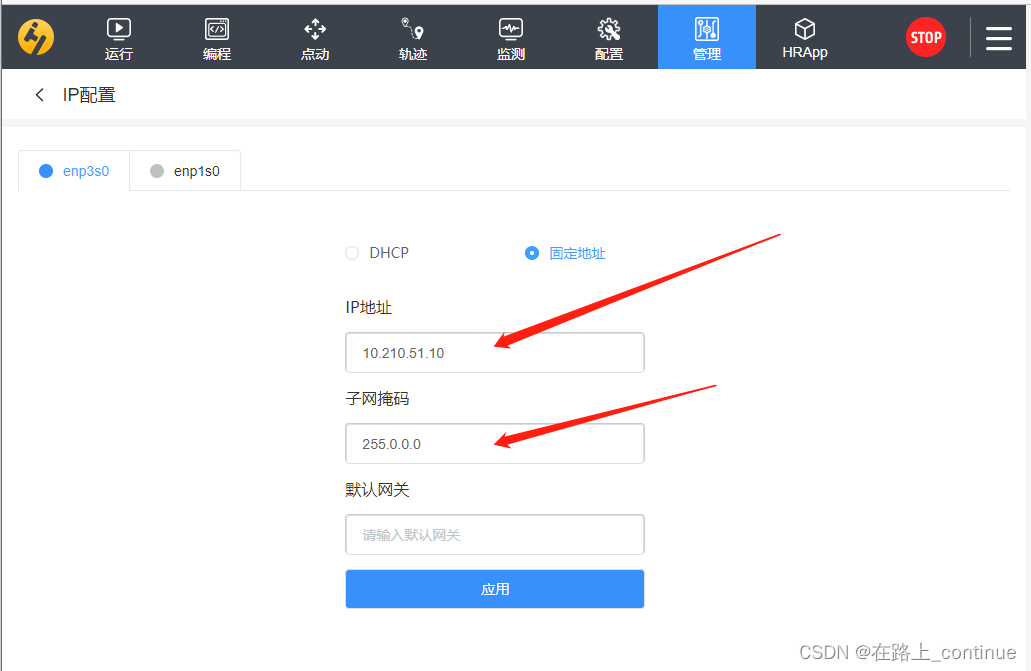
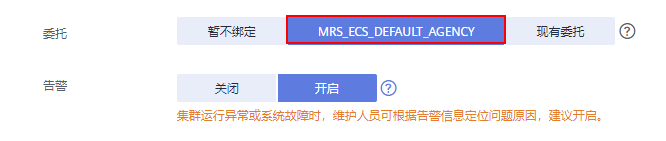
In this example , Because we have to analyze and deal with OBS Data in the file system , Therefore, the advanced configuration parameters of the cluster should be MRS Cluster binding IAM Authority delegation , Enable components in the cluster to dock OBS And have the operation permission of the corresponding file system directory .
You can directly select the system default “MRS_ECS_DEFAULT_AGENCY”, You can also create others with OBS Custom delegation of file system operation permissions .
After the cluster is successfully purchased , stay MRS In any node of the cluster , Use omm The user installs the cluster client , Please refer to Install and use the cluster client .
For example, the client installation directory is “/opt/client”.
Prepare test data
Creating Flink Before data analysis , We need to prepare the test data to be analyzed in advance , And upload the data to OBS File system .
1、 Create one locally “mrs_flink_test.txt” file , For example, the contents of the file are as follows :
This is a test demo for MRS Flink. Flink is a unified computing framework that supports both batch processing and stream processing. It provides a stream data processing engine that supports data distribution and parallel computing.
2、 Select “ Storage > Object storage service ”, Sign in OBS Administrative console .
3、 single click “ Parallel file system ”, Create a parallel file system , And upload the test data file .
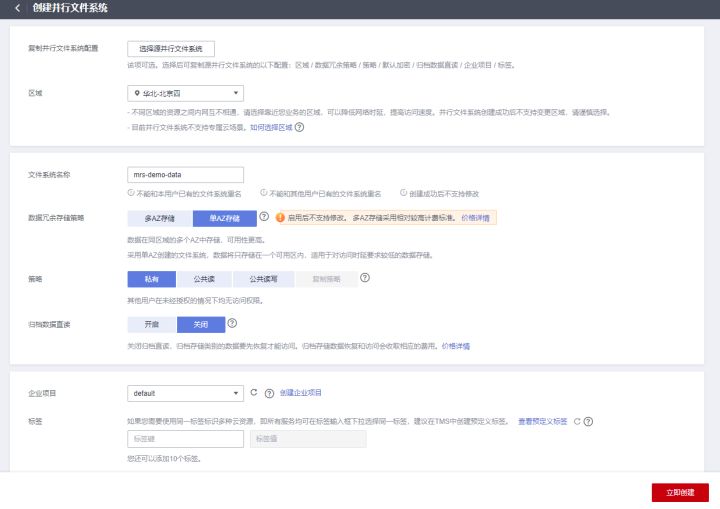
For example, the file system name created is “mrs-demo-data”, Click system name , stay “ file ” On the page , Create a new folder “flink”, Upload test data to this directory .
Then the complete path of the test data of this example is “obs://mrs-demo-data/flink/mrs_flink_test.txt”.

4、 Upload data analysis application .
When submitting jobs directly using the management console interface , Will have developed Flink Applications jar Files can also be uploaded to OBS File system , perhaps MRS Within cluster HDFS File system .
In this example, we use MRS Cluster built-in Flink WordCount Sample program , Can be obtained from MRS Get from the client installation directory of the cluster , namely “/opt/client/Flink/flink/examples/batch/WordCount.jar”.
take “WordCount.jar” Uploaded to the “mrs-demo-data/program” Under the table of contents .
Create and run Flink Homework
The way 1: Submit your homework online in the console interface .
- Sign in MRS Administrative console , single click MRS Cluster name , Enter the cluster details page .
- On the cluster details page “ overview ” Tab , single click “IAM User synchronization ” On the right side of the “ Click sync ” Conduct IAM User synchronization .
- single click “ Job management ”, Get into “ Job management ” Tab .
- single click “ add to ”, Add one Flink Homework .
- The type of assignment :Flink
- Job name : Customize , for example flink_obs_test.
- Execution path : This example uses Flink Client's WordCount Program, for example .
- Run program parameters : Use the default value .
- Execute program parameters : Set the input parameters of the application ,“input” For the test data to be analyzed ,“output” Output files for results .
For example, in this example , We set it to “--input obs://mrs-demo-data/flink/mrs_flink_test.txt --output obs://mrs-demo-data/flink/output”.
- Service configuration parameters : Use the default value , If you need to manually configure parameters related to the job , May refer to function Flink Homework .
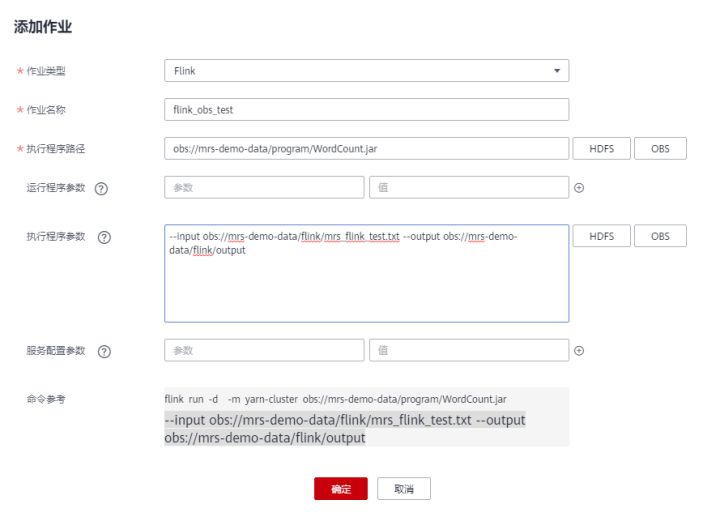
5. After confirming the job configuration information , single click “ determine ”, Complete the addition of the job , And wait for the run to complete .

The way 2: Submit jobs through the cluster client .
1、 Use root The user logs in to the cluster client node , Enter the client installation directory .
su - omm cd /opt/client source bigdata_env
2、 Execute the following command to verify whether the cluster can access OBS.
hdfs dfs -ls obs://mrs-demo-data/flink
3、 Submit Flink Homework , Specify source file data for consumption .
flink run -m yarn-cluster /opt/client/Flink/flink/examples/batch/WordCount.jar --input obs://mrs-demo-data/flink/mrs_flink_test.txt --output obs://mrs-demo/data/flink/output2
The results after execution are similar to the following :
... Cluster started: Yarn cluster with application id application_1654672374562_0011 Job has been submitted with JobID a89b561de5d0298cb2ba01fbc30338bc Program execution finished Job with JobID a89b561de5d0298cb2ba01fbc30338bc has finished. Job Runtime: 1200 ms
View job execution results
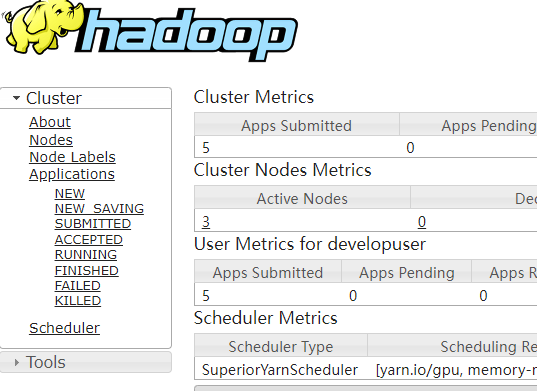
- After the job is submitted successfully , Sign in MRS Clustered FusionInsight Manager Interface , choice “ colony > service > Yarn”.
- single click “ResourceManager WebUI” Follow the link to Yarn Web UI Interface , stay Applications View the current page Yarn Detailed operation status and operation log of the job .
3. Wait for the job to complete , stay OBS The results of data analysis output can be viewed in the result output file specified in the file system .

download “output” File locally and open , You can view the output analysis results .
a 3 and 2 batch 1 both 1 computing 2 data 2 demo 1 distribution 1 engine 1 flink 2 for 1 framework 1 is 2 it 1 mrs 1 parallel 1 processing 3 provides 1 stream 2 supports 2 test 1 that 2 this 1 unified 1
When submitting a job using the cluster client command line , If you do not specify the output directory , You can also directly view the data analysis results in the job operation interface .
Job with JobID xxx has finished. Job Runtime: xxx ms Accumulator Results: - e6209f96ffa423974f8c7043821814e9 (java.util.ArrayList) [31 elements] (a,3) (and,2) (batch,1) (both,1) (computing,2) (data,2) (demo,1) (distribution,1) (engine,1) (flink,2) (for,1) (framework,1) (is,2) (it,1) (mrs,1) (parallel,1) (processing,3) (provides,1) (stream,2) (supports,2) (test,1) (that,2) (this,1) (unified,1)
Click to follow , The first time to learn about Huawei's new cloud technology ~
![Verilog implementation of a simple legv8 processor [4] [explanation of basic knowledge and module design of single cycle implementation]](/img/d3/20674983717d829489149b4d3bfedf.png)