当前位置:网站首页>Horizontal of libsgm_ path_ Interpretation of aggregation program
Horizontal of libsgm_ path_ Interpretation of aggregation program
2022-07-07 14:10:00 【Stool flower*】
List of articles
One 、 Preface
I want to realize it recently AD_Census Scan line optimizer acceleration , I will C++ The procedure of is changed to CUDA After procedure , The speed is also reduced 100 times ( Chicken with vegetables cries in the storm ), But I can only find some reference routines online . Direct search AD_Census There is no , Only the curve can save the country , Look for more open source SGM The program of .
libSGM It is an open source program developed by Japanese players who have a good childhood , The source URL is here :fixstars/libSGM
This project is right C++ Use a lot , Various templates and other operations are used , Yes C++ It's hard for unfamiliar people to read , And there is no relevant interpretation on the Internet . Just as I read it, I also made some comments , So share it here , I hope that helps .
If there is infringement, please contact .( Reading open source code should not infringe hhh)
Two 、 Program interpretation
Because I just want to refer to AD_Census Scan line optimization part of , Corresponding to SGM That is, the cost aggregation part , So I only read horizontal_path_aggregation.cu This code , This code contains path_aggregation_common.hpp file , Will be interpreted together .
1. horizontal_path_aggregation.cu
The code is as follows , Basically every line is annotated , I suggest you copy the following code and paste it into the file VSCode To read .
There are many operations in the code , I really admire the author , hold C++ and CUDA The application is perfect , A website is posted here to help you understand :
- C++ Template details , Click in to find C++ Template
Non type parameters, Read it carefully . In fact, to put it simply, when you read the code As a constant That's all right. . - 【CUDA Basics 】5.6 Thread bundle shuffle instruction | Tan Sheng's blog (face2ai.com)
- Programming Guide :: CUDA Toolkit Documentation (nvidia.com)
2 and 3 Because the code uses CUDA Shuffle shuffle operation , From this application, we can see that the author is right CUDA The bottom level of understanding is how profound , You can read Tan Sheng's blog first__shfl,__shfl_up,__shfl_down, and__shfl_xorThe operation of these functions , Although they have been abandoned , Changed to__shfl_sync,__shfl_up_sync,__shfl_down_sync, and__shfl_xor_syncBut the truth is the same . - About CUDA Medium warp shuffle Function description This article is a brief look , Help you understand
__shfl_syncMedium mask What's the function . - cuda - Is mask adaptive in __shfl_up_sync call? - Stack Overflow
, stay Stack Overflow There is also a reading on it libSGM Brother of code hhh, In fact, there is not much knowledge in it , Just open it and have a look . - If you don't know anything else, just Baidu .
/* Copyright 2016 Fixstars Corporation Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http ://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. */
#include <cstdio>
#include "horizontal_path_aggregation.hpp"
#include "path_aggregation_common.hpp"
// Be careful : Below DP In fact, it refers to the cost of parallax , But for the sake of ease , I unified the narrative into a parallax block , In fact, it refers to the cost corresponding to parallax , Not parallax ! Not parallax ! Not parallax !
// A thread handles
namespace sgm {
namespace path_aggregation {
// DP Indicates parallax disparity
// Parallax block size ,8 Parallax a block
static constexpr unsigned int DP_BLOCK_SIZE = 8u;
// Parallax blocks processed by each thread , Deal with here 1 block , That is, each thread handles 8 Parallax
static constexpr unsigned int DP_BLOCKS_PER_THREAD = 1u;
// In each block warp The number of 4
static constexpr unsigned int WARPS_PER_BLOCK = 4u;
// Block size , That is, the number of threads in the block ,warp Number * warp size
static constexpr unsigned int BLOCK_SIZE = WARP_SIZE * WARPS_PER_BLOCK; // 32 * 4 = 128
// Horizontal path aggregation
// The template used here , Two non type parameters are used , Just regard these two parameters as constants
// DIRECTION Indicates direction ,1 To aggregate from left to right ,-1 To aggregate from right to left
// MAX_DISPARITY Indicates the maximum parallax range , Here to 128 For example
template <int DIRECTION, unsigned int MAX_DISPARITY>
__global__ void aggregate_horizontal_path_kernel(
uint8_t *dest,
const feature_type *left, // feature_type yes uint32_t
const feature_type *right,
int width,
int height,
unsigned int p1,
unsigned int p2,
int min_disp)
{
// Subgroup size , That is, the parallax range MAX_DISPARITY The number of parallax blocks required in
static const unsigned int SUBGROUP_SIZE = MAX_DISPARITY / DP_BLOCK_SIZE; // 128 / 8 = 16
// Every warp Number of subgroups processed
static const unsigned int SUBGROUPS_PER_WARP = WARP_SIZE / SUBGROUP_SIZE; // 32 / 16 = 2
// Every warp The number of paths , Because a thread processes a parallax block , So a warp Handle 32 Parallax blocks
// A subgroup 16 Parallax blocks , That is, a warp Handle 2 Subgroup , That is, two paths ? I don't know what path means
static const unsigned int PATHS_PER_WARP =
WARP_SIZE * DP_BLOCKS_PER_THREAD / SUBGROUP_SIZE; // 32 * 1 / 16 = 2
// Number of paths per block , ditto
static const unsigned int PATHS_PER_BLOCK =
BLOCK_SIZE * DP_BLOCKS_PER_THREAD / SUBGROUP_SIZE; // 128 * 1 / 16 = 8
static_assert(DIRECTION == 1 || DIRECTION == -1, "");
if(width == 0 || height == 0){
return;
}
// The cache required by each thread , Used to store the values in the right figure
feature_type right_buffer[DP_BLOCKS_PER_THREAD][DP_BLOCK_SIZE];
// Here is to declare an array of structures dp, The array has DP_BLOCKS_PER_THREAD( Here is 1) Elements , Each element is a DynamicProgramming Structure
// There are variables in this structure last_min and dp[DP_BLOCK_SIZE] And a function update()
// dp[DP_BLOCK_SIZE] The initial value of each element in is 0
DynamicProgramming<DP_BLOCK_SIZE, SUBGROUP_SIZE> dp[DP_BLOCKS_PER_THREAD];
const unsigned int warp_id = threadIdx.x / WARP_SIZE;
// One warp The group inside , here 2 A set of
const unsigned int group_id = threadIdx.x % WARP_SIZE / SUBGROUP_SIZE;
const unsigned int lane_id = threadIdx.x % SUBGROUP_SIZE;
// here SUBGROUP_SIZE by 16, So the return value of the function is 0x0000ffff, Every time I move left group_id * SUBGROUP_SIZE position
// group_id by 0 when , Move left 0 position , namely 0x0000ffff; by 1 when , Move left 16 A into 0xffff0000. In this way, only 16 Threads are valid .
// One thread is one lane, Process a parallax block ,8 Parallax
const unsigned int shfl_mask =
generate_mask<SUBGROUP_SIZE>() << (group_id * SUBGROUP_SIZE);
// Row number ,group id Change first , The second is warp id, And finally blockIdx.x
// A group is a row , One group has 16 Parallax blocks , need 16 Threads, that is lane,1 Parallax blocks 8 Parallax
const unsigned int y0 =
PATHS_PER_BLOCK * blockIdx.x +
PATHS_PER_WARP * warp_id +
group_id;
// feature_step It is used for one thread to process multiple DP Block situation , There are multiple DP Blocks are not contiguous adjacent blocks , It is
// next warp Blocks in
// Because a subgroup corresponds to 128 Parallax , That's a line , And one warp There are two subgroups , So a warp Can handle two lines
// So the next one warp To increase SUBGROUPS_PER_WARP * width, It means adding two lines
// If you don't understand what it means when you look here for the first time , It doesn't matter. , Look back first , Wait until you use this variable, then come back and taste it carefully
const unsigned int feature_step = SUBGROUPS_PER_WARP * width; // 2 * 1920?
// Each price corresponds 128 Parallax , So here we have to multiply by MAX_DISPARITY
const unsigned int dest_step = SUBGROUPS_PER_WARP * MAX_DISPARITY * width; // 2 * 128 * 1920
// dp Step size of block
const unsigned int dp_offset = lane_id * DP_BLOCK_SIZE;
left += y0 * width;
right += y0 * width;
dest += y0 * MAX_DISPARITY * width;
if(y0 >= height){
return;
}
// initialization ?
if(DIRECTION > 0){
for(unsigned int i = 0; i < DP_BLOCKS_PER_THREAD; ++i){
for(unsigned int j = 0; j < DP_BLOCK_SIZE; ++j){
right_buffer[i][j] = 0;
}
}
}else{
for(unsigned int i = 0; i < DP_BLOCKS_PER_THREAD; ++i){
for(unsigned int j = 0; j < DP_BLOCK_SIZE; ++j){
const int x = static_cast<int>(width - (min_disp + j + dp_offset));
if(0 <= x && x < static_cast<int>(width)){
// __ldg It should be used to read read read-only data
right_buffer[i][j] = __ldg(&right[i * feature_step + x]);
}else{
right_buffer[i][j] = 0;
}
}
}
}
// here x0 Is the starting index , If it is from left to right , The starting index is 0; If it's from right to left , The starting index should be width - DP_BLOCK_SIZE
// Just pass here (width - 1) & ~(DP_BLOCK_SIZE - 1) This logic is used to realize calculation width - DP_BLOCK_SIZE, The results are the same
// &、~ They are all bit-by-bit operations ,& It's bitwise and ,~ It's bit by bit inversion
// Notice the x0 Just the initial value , Next, after entering the cycle, it will increase , Each cycle increases DP_BLOCK_SIZE
int x0 = (DIRECTION > 0) ? 0 : static_cast<int>((width - 1) & ~(DP_BLOCK_SIZE - 1));
// iter Is the number of iterations , All iterations width / DP_BLOCK_SIZE Time , Each iteration is processed internally DP_BLOCK_SIZE Data
for(unsigned int iter = 0; iter < width; iter += DP_BLOCK_SIZE){
for(unsigned int i = 0; i < DP_BLOCK_SIZE; ++i){
// Index in a parallax block , altogether 8 Data is from 0~7, With x0 Change and change , From right to left is similar
const unsigned int x = x0 + (DIRECTION > 0 ? i : (DP_BLOCK_SIZE - 1 - i));
if(x >= width){
continue;
}
// Here each thread handles 1 individual DP block , So just iterate 1 Time , If you deal with multiple , You need to iterate many times . Each iteration only needs to deal with 1 Parallax .
for(unsigned int j = 0; j < DP_BLOCKS_PER_THREAD; ++j){
// y0 Is the line number , One group, one row , A group 16 Parallax blocks , That is to say 128 Parallax . For this j iteration , Every iteration y0 It's all the same
const unsigned int y = y0 + j * SUBGROUPS_PER_WARP;
if(y >= height){
continue;
}
// Take out the left value corresponding to the parallax of each parallax block
const feature_type left_value = __ldg(&left[j * feature_step + x]);
if(DIRECTION > 0){
// Take out the last right value of the parallax block , Because it will move to the right later , I'm afraid this value will be lost
const feature_type t = right_buffer[j][DP_BLOCK_SIZE - 1];
// right_buffer Shift each value to the right by one bit
// Pay attention here every time i The loop will move to the right once , etc. i The loop ends , It's totally shifted to the right 8 Time .
for(unsigned int k = DP_BLOCK_SIZE - 1; k > 0; --k){
right_buffer[j][k] = right_buffer[j][k - 1];
}
#if CUDA_VERSION >= 9000
// All parallax blocks within the current subgroup are swapped up t( The last parallax value ) to right_buffer[j][0]
// For example, the current thread is 12, Then get the thread 11 Of t Value to the first parallax of the parallax block corresponding to the current thread
// So it means : The whole subgroup SUBGROUP All parallax blocks in are shifted one bit to the right
// __shfl_up_sync Please see path_aggregation_common.hpp The comments in
right_buffer[j][0] = __shfl_up_sync(shfl_mask, t, 1, SUBGROUP_SIZE);
#else
right_buffer[j][0] = __shfl_up(t, 1, SUBGROUP_SIZE);
#endif
// For threads 0, Due to the first 1 The first parallax of parallax blocks has been shifted right to the second parallax , But there is no other parallax in front of the first parallax that can give him value
// So here we deal with the first parallax without value
// Be careful :right_buffer The initial values are all 0, But when lane id by 0 When ,right_buffer[j][0] Will take to right Value , In this way
// Every time i At the end of the cycle, you will get 8 individual right To fill in right_buffer.
if(lane_id == 0 && x >= min_disp){
right_buffer[j][0] =
__ldg(&right[j * feature_step + x - min_disp]);
}
}else{
// acutely !! Here it is. else Not in the above line if Of else, It is if(DIRECTION > 0) Of else, Wrong for the first time !!! I said why so confused
// ditto , Here, because I want to move left , So save first 0 Elements
const feature_type t = right_buffer[j][0];
for(unsigned int k = 1; k < DP_BLOCK_SIZE; ++k){
right_buffer[j][k - 1] = right_buffer[j][k];
}
#if CUDA_VERSION >= 9000
right_buffer[j][DP_BLOCK_SIZE - 1] =
__shfl_down_sync(shfl_mask, t, 1, SUBGROUP_SIZE);
#else
right_buffer[j][DP_BLOCK_SIZE - 1] = __shfl_down(t, 1, SUBGROUP_SIZE);
#endif
// Process the last thread ( That is, the last parallax block ) The last parallax value of
if(lane_id + 1 == SUBGROUP_SIZE){
if(x >= min_disp + dp_offset + DP_BLOCK_SIZE - 1){
right_buffer[j][DP_BLOCK_SIZE - 1] =
__ldg(&right[j * feature_step + x - (min_disp + dp_offset + DP_BLOCK_SIZE - 1)]);
}else{
right_buffer[j][DP_BLOCK_SIZE - 1] = 0;
}
}
}
// Save the local proxy value of each parallax block parallax
uint32_t local_costs[DP_BLOCK_SIZE];
for(unsigned int k = 0; k < DP_BLOCK_SIZE; ++k){
// __popc Is a statistical integer 1 The number of , Here is a process of calculating Hamming distance ( XOR first and then count 1 The number of )
local_costs[k] = __popc(left_value ^ right_buffer[j][k]);
}
// to update dp Medium dp、last_min
dp[j].update(local_costs, p1, p2, shfl_mask);
// hold dp.dp Deposit in dest in
store_uint8_vector<DP_BLOCK_SIZE>(
&dest[j * dest_step + x * MAX_DISPARITY + dp_offset],
dp[j].dp);
}
}
x0 += static_cast<int>(DP_BLOCK_SIZE) * DIRECTION;
}
}
template <unsigned int MAX_DISPARITY>
void enqueue_aggregate_left2right_path(
cost_type *dest,
const feature_type *left,
const feature_type *right,
int width,
int height,
unsigned int p1,
unsigned int p2,
int min_disp,
cudaStream_t stream)
{
static const unsigned int SUBGROUP_SIZE = MAX_DISPARITY / DP_BLOCK_SIZE;
static const unsigned int PATHS_PER_BLOCK =
BLOCK_SIZE * DP_BLOCKS_PER_THREAD / SUBGROUP_SIZE;
const int gdim = (height + PATHS_PER_BLOCK - 1) / PATHS_PER_BLOCK;
const int bdim = BLOCK_SIZE;
aggregate_horizontal_path_kernel<1, MAX_DISPARITY><<<gdim, bdim, 0, stream>>>(
dest, left, right, width, height, p1, p2, min_disp);
}
template <unsigned int MAX_DISPARITY>
void enqueue_aggregate_right2left_path(
cost_type *dest,
const feature_type *left,
const feature_type *right,
int width,
int height,
unsigned int p1,
unsigned int p2,
int min_disp,
cudaStream_t stream)
{
static const unsigned int SUBGROUP_SIZE = MAX_DISPARITY / DP_BLOCK_SIZE;
static const unsigned int PATHS_PER_BLOCK =
BLOCK_SIZE * DP_BLOCKS_PER_THREAD / SUBGROUP_SIZE;
const int gdim = (height + PATHS_PER_BLOCK - 1) / PATHS_PER_BLOCK;
const int bdim = BLOCK_SIZE;
aggregate_horizontal_path_kernel<-1, MAX_DISPARITY><<<gdim, bdim, 0, stream>>>(
dest, left, right, width, height, p1, p2, min_disp);
}
template void enqueue_aggregate_left2right_path<64u>(
cost_type *dest,
const feature_type *left,
const feature_type *right,
int width,
int height,
unsigned int p1,
unsigned int p2,
int min_disp,
cudaStream_t stream);
template void enqueue_aggregate_left2right_path<128u>(
cost_type *dest,
const feature_type *left,
const feature_type *right,
int width,
int height,
unsigned int p1,
unsigned int p2,
int min_disp,
cudaStream_t stream);
template void enqueue_aggregate_left2right_path<256u>(
cost_type *dest,
const feature_type *left,
const feature_type *right,
int width,
int height,
unsigned int p1,
unsigned int p2,
int min_disp,
cudaStream_t stream);
template void enqueue_aggregate_right2left_path<64u>(
cost_type *dest,
const feature_type *left,
const feature_type *right,
int width,
int height,
unsigned int p1,
unsigned int p2,
int min_disp,
cudaStream_t stream);
template void enqueue_aggregate_right2left_path<128u>(
cost_type *dest,
const feature_type *left,
const feature_type *right,
int width,
int height,
unsigned int p1,
unsigned int p2,
int min_disp,
cudaStream_t stream);
template void enqueue_aggregate_right2left_path<256u>(
cost_type *dest,
const feature_type *left,
const feature_type *right,
int width,
int height,
unsigned int p1,
unsigned int p2,
int min_disp,
cudaStream_t stream);
}
}
2. path_aggregation_common.hpp
The code is as follows , Here is mainly used update() function .
/* Copyright 2016 Fixstars Corporation Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http ://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. */
#ifndef SGM_PATH_AGGREGATION_COMMON_HPP
#define SGM_PATH_AGGREGATION_COMMON_HPP
#include <cstdint>
#include <cuda.h>
#include "utility.hpp"
namespace sgm {
namespace path_aggregation {
template <
unsigned int DP_BLOCK_SIZE,
unsigned int SUBGROUP_SIZE>
struct DynamicProgramming {
// Notice here is a structure
// Judge whether the incoming parameters meet the requirements
static_assert(
DP_BLOCK_SIZE >= 2,
"DP_BLOCK_SIZE must be greater than or equal to 2");
static_assert(
(SUBGROUP_SIZE & (SUBGROUP_SIZE - 1)) == 0,
"SUBGROUP_SIZE must be a power of 2");
uint32_t last_min;
// It seems to be used to store the visual difference ? How many parallaxes does a parallax block have ,dp The size of
uint32_t dp[DP_BLOCK_SIZE];
// Constructor running on the device ,dp All values are initialized to 0
__device__ DynamicProgramming()
: last_min(0)
{
for(unsigned int i = 0; i < DP_BLOCK_SIZE; ++i){
dp[i] = 0; }
}
// Update function on the device
// It is to deal with each parallax block dp Every value of , from k=0 Start , Until k=DP_BLOCK_SIZE - 1 Update one by one
// And find the minimum generation value of the current parallax block
// This code looks troublesome , In fact, there are only three parts ,k=0、k=DP_BLOCK_SIZE - 1 And the middle of these two values k
__device__ void update(
uint32_t *local_costs, uint32_t p1, uint32_t p2, uint32_t mask)
{
// Express lane Of id,lane In fact, that is thread, Under normal circumstances lane by [0,31], Here is a lane Process a parallax block , namely 8 Parallax
const unsigned int lane_id = threadIdx.x % SUBGROUP_SIZE;
//
const auto dp0 = dp[0];
uint32_t lazy_out = 0, local_min = 0;
{
// Here we deal with k=0 The case when , It may be different circumstances plus different penalties ??
const unsigned int k = 0;
#if CUDA_VERSION >= 9000
// stay CC3.0 above , Support shuffle Instructions , allow thread Read other directly thread The register value of , As long as the two thread In the same warp in , This ratio passes shared Memory Conduct thread The communication effect between is better ,latency A lower , At the same time, it does not consume additional memory resources to perform data exchange .
// Here are warp A concept in lane, One lane It's just one. warp One of them thread, Every lane In the same warp Zhongyou lane The index is uniquely determined , Therefore, its scope is [0,31]. In a one-dimensional block in , The index can be calculated by the following two formulas :laneID = threadIdx.x % 32; warpID = threadIdx.x / 32; for example , In the same block Medium thread1 and 33 Have the same lane Indexes 1.
// This sentence means to put the previous thread ( Parallax block ) The last parallax value of dp[DP_BLOCK_SIZE - 1] Move up to the current thread ( Parallax block )prev(previous) Variables
// __shfl_up_sync Specific to see :https://face2ai.com/CUDA-F-5-6-%E7%BA%BF%E7%A8%8B%E6%9D%9F%E6%B4%97%E7%89%8C%E6%8C%87%E4%BB%A4/
// https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#warp-shuffle-functions
// https://stackoverflow.com/questions/58869398/is-mask-adaptive-in-shfl-up-sync-call
const uint32_t prev =
__shfl_up_sync(mask, dp[DP_BLOCK_SIZE - 1], 1);
#else
const uint32_t prev = __shfl_up(dp[DP_BLOCK_SIZE - 1], 1);
#endif
// lane by 0 Minimum value when
uint32_t out = min(dp[k] - last_min, p2);
// lane The minimum value when it is other values
if(lane_id != 0){
out = min(out, prev - last_min + p1); }
out = min(out, dp[k + 1] - last_min + p1);
lazy_out = local_min = out + local_costs[k];
}
// k For other values ( Not the first and last )
// It will be updated here dp[0]~dp[5]
for(unsigned int k = 1; k + 1 < DP_BLOCK_SIZE; ++k){
uint32_t out = min(dp[k] - last_min, p2);
out = min(out, dp[k - 1] - last_min + p1);
out = min(out, dp[k + 1] - last_min + p1);
dp[k - 1] = lazy_out;
lazy_out = out + local_costs[k];
local_min = min(local_min, lazy_out);
}
{
// the last one k
const unsigned int k = DP_BLOCK_SIZE - 1;
#if CUDA_VERSION >= 9000
// Take down a thread dp0, That is, the first parallax of the next parallax block
const uint32_t next = __shfl_down_sync(mask, dp0, 1);
#else
const uint32_t next = __shfl_down(dp0, 1);
#endif
uint32_t out = min(dp[k] - last_min, p2);
out = min(out, dp[k - 1] - last_min + p1);
// Not the last one lane
if(lane_id + 1 != SUBGROUP_SIZE){
// This one is similar to that in the code dp[k+1] use next replace
out = min(out, next - last_min + p1);
}
// to update dp[6], dp[7]
dp[k - 1] = lazy_out;
dp[k] = out + local_costs[k];
local_min = min(local_min, dp[k]);
}
// Find the minimum cost in the subgroup
last_min = subgroup_min<SUBGROUP_SIZE>(local_min, mask);
}
};
template <unsigned int SIZE>
__device__ unsigned int generate_mask()
{
static_assert(SIZE <= 32, "SIZE must be less than or equal to 32");
return static_cast<unsigned int>((1ull << SIZE) - 1u);
}
}
}
#endif
3、 ... and 、 Review the whole process
Actually, after reading the above two codes , You may still not understand how this code works hhh, I was puzzled after reading it at first , I didn't realize it until the end , Here we are reviewing the whole code flow :
The following explanation is based on DP_BLOCK_SIZE=8,DP_BLOCKS_PER_THREAD=1,WARPS_PER_BLOCK=4,SUBGROUP_SIZE=16,DIRECTION=1, For example .
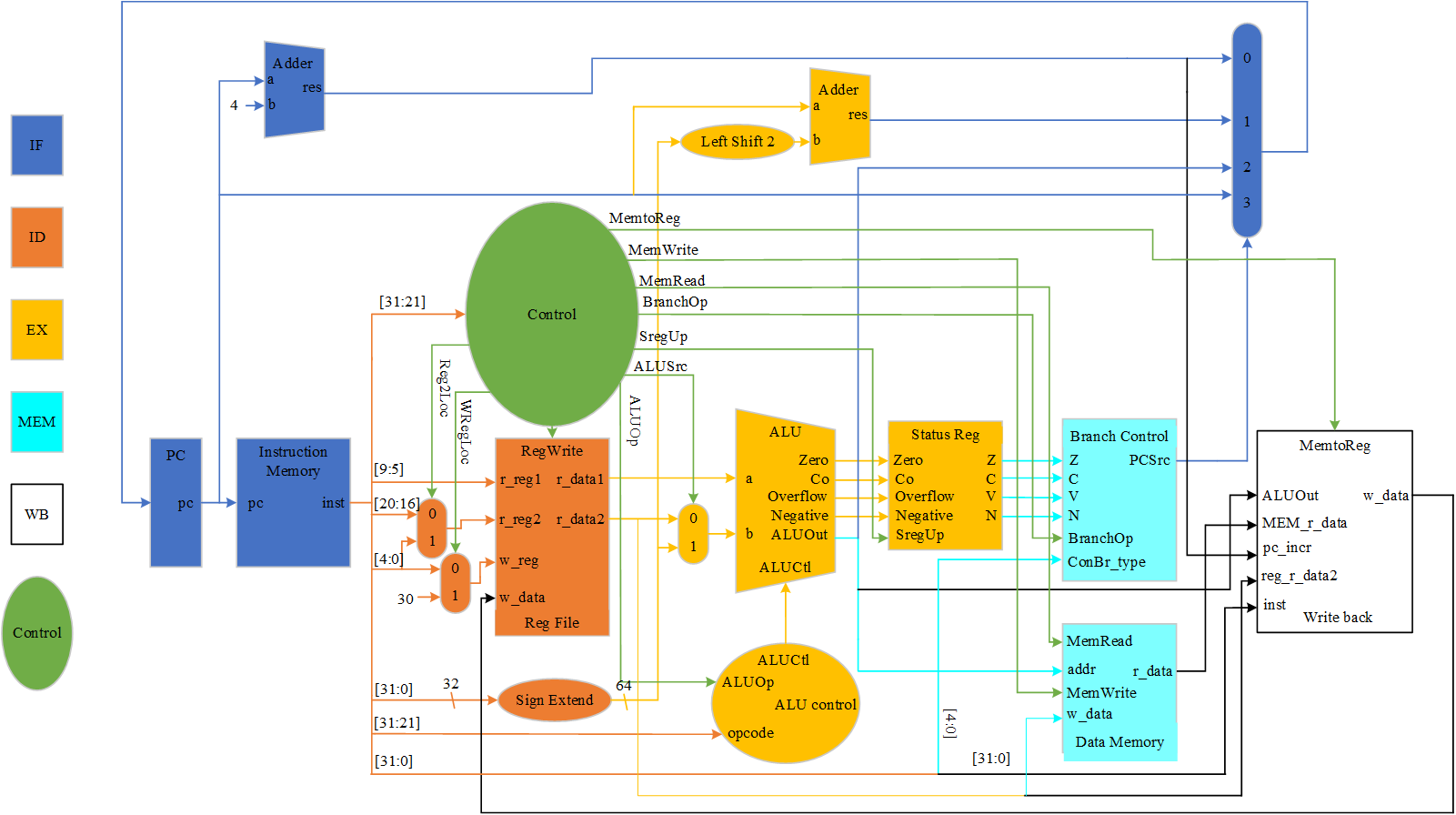
about aggregate_horizontal_path_kernel() function ,int x0 = (DIRECTION > 0) ? 0 : static_cast<int>((width - 1) & ~(DP_BLOCK_SIZE - 1)); This code is used to define some variables before , We won't pay much attention to it for the time being . Just look at y0 This variable :const unsigned int y0 = PATHS_PER_BLOCK * blockIdx.x + PATHS_PER_WARP * warp_id + group_id;,y0 And again 3 Variables :blockIdx.x、warp_id and group_id.group_id Is the easiest to start changing , When the thread is 0~ 15 It is 0, Thread is 16 ~ 31 It is 1. And then it's based on warp_id Make changes , Finally, according to blockIdx.x change .
With threads 0 And thread 1 give an example , You'll find it's two blockIdx.x、warp_id and group_id All three variables are 0, therefore y0 Namely 0, That is, the number of rows processed by these two threads is 0 That's ok . It's important here , Because in the following code :
left += y0 * width;
right += y0 * width;
dest += y0 * MAX_DISPARITY * width;
The initial values of these three pointers are all equal to y0 of ,0~15 The initial values of these three pointers of the thread are the same .
Besides , Pay attention to it. right_buffer Initialization of , When DIRECTION=1 when , All values are initialized to 0, No matter which thread comes in ,right_buffer The initial values in are 0, that right_buffer How is it updated ? Don't worry. , Look back first .
Understand the above y0 and right_buffer after , from x0 Then the code begins to understand :
- x0 Is the starting index processed by this thread , One warp Threads in are executed concurrently , So the starting index of each thread x0 All are 0. You may be surprised to see here , Shouldn't each thread handle different parallax blocks , Why is the starting index the same ? Don't worry. , I'll explain later .
- Enter the loop , There are three floors. loop, The outer layer is iter loop , Co cycle width / DP_BLOCK_SIZE Time ; The outer layer is i loop , Co cycle DP_BLOCK_SIZE Time , So the outer layer and the sub outer layer are combined to be a row of data of the image , common width individual , That is, a thread needs to process a row of data ; The inner layer is j loop , Co cycle DP_BLOCKS_PER_THREAD Time , Represents what each thread handles DP block .
- Enter into i After the loop, a x Variable :
const unsigned int x = x0 + (DIRECTION > 0 ? i : (DP_BLOCK_SIZE - 1 - i));, This variable is associated with x0 and i of , Every time i The loop will add 1, That is to say x Add 1;x0 stay i At the end of the cycle DP_BLOCK_SIZE(i Circulation means circulation DP_BLOCK_SIZE Time ,i The last cycle value is DP_BLOCK_SIZE-1,x Increase DP_BLOCK_SIZE-1,i At the end of the cycle ,x0 increase DP_BLOCK_SIZE, That is to say x increase DP_BLOCK_SIZE, This makes x The changes are connected ). - And then look j loop . In fact, here we let DP_BLOCKS_PER_THREAD=1, So this j Cycle is equivalent to no , by 0, Can not consider and j Related operation . Enter into j The loop defines a y Variable , Indicates line number , Actually sum y0 They are equal. , because j Always for 0.
- The next step is to take out the value in the left image :
const feature_type left_value = __ldg(&left[j * feature_step + x]);Please note that , When each thread executes here x The first is 0, So the left-hand value obtained is also Are all the same , All are left[0]. - Because we consider DIRECTION=1 The situation of , So program execution if(DIRECTION > 0) The code in . Define a variable first :
const feature_type t = right_buffer[j][DP_BLOCK_SIZE - 1];, This variable is processed by the current thread DP The last of the blocks dp Corresponding generation value , Take it out in advance and save it to t variable , Why? ? Because of the back for The cycle should be right right_buffer Move right , If you don't save the last value , This value will be overwritten by the previous value moved . - When right_buffer After moving right , Here comes the operation :
right_buffer[j][0] = __shfl_up_sync(shfl_mask, t, 1, SUBGROUP_SIZE);The author passes CUDA Shuffle operation , The last value of the previous thread is moved to the... Of the current thread 0 Values , This completes the movement between threads , It's 666 ah . So see here , You may wonder , What's this for? ??? Why move right ??? Don't panic. , To look down . - After completing the data movement between threads , Here comes another operation :
if(lane_id == 0 && x >= min_disp){
right_buffer[j][0] =
__ldg(&right[j * feature_step + x - min_disp]);
}
Some students will say , This is processing lane_id by 0 When , So threads 0 Do you , What's strange . you 're right , Here is to deal with 0 The second of the thread 0 Data , But notice , Before right_buffer In fact, the initial values are 0, But here is no 0 The value assigned to the data is right Corresponding value in . therefore right_buffer The value of is updated here .
Then the initial value has , Cooperate with the up and right shift operation , You'll find that , For threads 0 Each cycle will update one right_buffer[j][0], And each cycle will right_buffer Move all right one bit , Then the last updated right_buffer[j][0] Move right to right_buffer[j][1], And then gradually move to the right … Move right all the way to right_buffer[j][7]( Here to DP_BLOCK_SIZE=8 For example ).
Moved right to right_buffer[j][7] after , Pass the first 7 Click on the operation , Data movement between threads , therefore thread0 Of right_buffer[j][7] Will be moved to thread1 Of right_buffer[j][0] It's about , and thread0 Of right_buffer[j][7] Will be thread0 Of right_buffer[j][6] Covered with , This completes the data movement of all threads …
Isn't that amazing , You can complete all by moving right right_buffer Update .
if(DIRECTION > 0) Corresponding else Don't look at it , The operation is basically the same .
- Define a one-dimensional array local_costs, The size is DP_BLOCK_SIZE, Save the local proxy value corresponding to the current parallax . The partial cost is through Hamming Distance . XOR the left value with the right value corresponding to each parallax , Then count 1, taken Hamming distance .
- Finally through update() Function to update , Then the updated dp Value saved to dest in .
OKK!aggregate_horizontal_path_kernel() The function is finished , I can't help sighing the author's nb The place of . After reading it, I still feel that I don't understand it thoroughly , It's still a little difficult to change it into your own … Later, try whether you can go all the way to your own algorithm .
Let's talk about update() function :
- This function is actually relatively simple , The function is to update dp Array and last_min Value .
- The whole function is to process and update each value in a parallax block , And then calculate last_min And update . It is divided into 3 part :k = 0, k = 1~6, k = 7.
Four 、 Code reading skills
In the process of reading the code, I summarized some reading skills :
- When reading the code, there are many macro definitions that may not understand the meaning temporarily , It doesn't matter. , When you look at its usage scenarios later, you may understand .
- Most of the well written code actually has many assertion statements or other irrelevant statements ( Conditional compilation 、 Judge whether it overflows, etc ), These statements are not much different for us to understand the code , So you can create a copy of the code , Then delete these irrelevant codes , In this way, the subcode looks much cleaner , It's easy for you to understand . For example, there are so many cores of the above code :
template <int DIRECTION, unsigned int MAX_DISPARITY>
__global__ void aggregate_horizontal_path_kernel(
uint8_t *dest,
const feature_type *left, // feature_type yes uint32_t
const feature_type *right,
int width,
int height,
unsigned int p1,
unsigned int p2,
int min_disp)
{
const unsigned int y0 =
PATHS_PER_BLOCK * blockIdx.x +
PATHS_PER_WARP * warp_id +
group_id;
left += y0 * width;
right += y0 * width;
dest += y0 * MAX_DISPARITY * width;
// initialization
if(DIRECTION > 0){
for(unsigned int i = 0; i < DP_BLOCKS_PER_THREAD; ++i){
for(unsigned int j = 0; j < DP_BLOCK_SIZE; ++j){
right_buffer[i][j] = 0;
}
}
}
int x0 = (DIRECTION > 0) ? 0 : static_cast<int>((width - 1) & ~(DP_BLOCK_SIZE - 1));
// iter Is the number of iterations , All iterations width / DP_BLOCK_SIZE Time , Each iteration is processed internally DP_BLOCK_SIZE Data
for(unsigned int iter = 0; iter < width; iter += DP_BLOCK_SIZE){
for(unsigned int i = 0; i < DP_BLOCK_SIZE; ++i){
// Index in a parallax block , altogether 8 Data is from 0~7, With x0 Change and change , From right to left is similar
const unsigned int x = x0 + (DIRECTION > 0 ? i : (DP_BLOCK_SIZE - 1 - i));
// Here each thread handles 1 individual DP block , So just iterate 1 Time , If you deal with multiple , You need to iterate many times . Each iteration only needs to deal with 1 Parallax .
for(unsigned int j = 0; j < DP_BLOCKS_PER_THREAD; ++j){
// y0 Is the line number , One group, one row , A group 16 Parallax blocks , That is to say 128 Parallax . For this j iteration , Every iteration y0 It's all the same
const unsigned int y = y0 + j * SUBGROUPS_PER_WARP;
// Take out the left value corresponding to the parallax of each parallax block
const feature_type left_value = __ldg(&left[j * feature_step + x]);
if(DIRECTION > 0){
// Take out the last right value of the parallax block , Because it will move to the right later , I'm afraid this value will be lost
const feature_type t = right_buffer[j][DP_BLOCK_SIZE - 1];
// right_buffer Shift each value to the right by one bit
// Pay attention here every time i The loop will move to the right once , etc. i The loop ends , It's totally shifted to the right 8 Time .
for(unsigned int k = DP_BLOCK_SIZE - 1; k > 0; --k){
right_buffer[j][k] = right_buffer[j][k - 1];
}
right_buffer[j][0] = __shfl_up_sync(shfl_mask, t, 1, SUBGROUP_SIZE);
if(lane_id == 0 && x >= min_disp){
right_buffer[j][0] =
__ldg(&right[j * feature_step + x - min_disp]);
}
}
// Save the local proxy value of each parallax block parallax
uint32_t local_costs[DP_BLOCK_SIZE];
for(unsigned int k = 0; k < DP_BLOCK_SIZE; ++k){
// __popc Is a statistical integer 1 The number of , Here is a process of calculating Hamming distance ( XOR first and then count 1 The number of )
local_costs[k] = __popc(left_value ^ right_buffer[j][k]);
}
// to update dp Medium dp、last_min
dp[j].update(local_costs, p1, p2, shfl_mask);
// hold dp.dp Deposit in dest in
store_uint8_vector<DP_BLOCK_SIZE>(
&dest[j * dest_step + x * MAX_DISPARITY + dp_offset],
dp[j].dp);
}
}
x0 += static_cast<int>(DP_BLOCK_SIZE) * DIRECTION;
}
}
How about it? It's much better to look at it ?
3. Many variables you don't know how they are updated , Or how to use , stay VSCode You can click this variable , Then it will highlight , Then you can probably go to the following code to browse where this variable is used , This may be more helpful to your understanding .
Like this :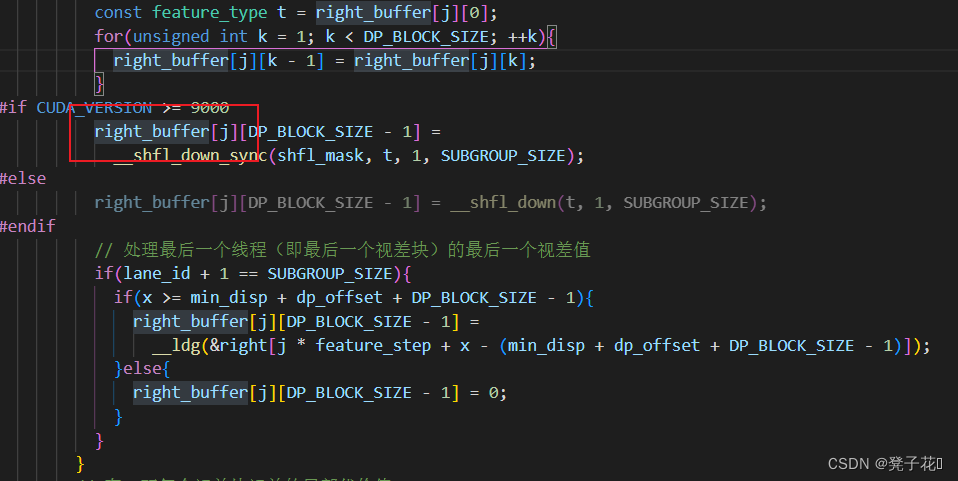
- It is recommended to write comments while reading the code , It's best to do the same when writing code , Otherwise, you will forget what the previous variable means after reading it .
- undetermined …
边栏推荐
- 2022-7-6 初学redis(一)在 Linux 下下载安装并运行 redis
- Transferring files between VMware and host
- 为租客提供帮助
- 社会责任·价值共创,中关村网络安全与信息化产业联盟对话网信企业家海泰方圆董事长姜海舟先生
- Learning breakout 2 - about effective learning methods
- js 获取当前时间 年月日,uniapp定位 小程序打开地图选择地点
- 属性关键字Aliases,Calculated,Cardinality,ClientName
- Move base parameter analysis and experience summary
- ARM Cortex-A9,MCIMX6U7CVM08AD 处理器应用
- 供应链供需预估-[时间序列]
猜你喜欢

【立体匹配论文阅读】【三】INTS
![Supply chain supply and demand estimation - [time series]](/img/2c/82d118cfbcef4498998298dd3844b1.png)
Supply chain supply and demand estimation - [time series]

LeetCode简单题分享(20)
Flink | multi stream conversion
. Net core about redis pipeline and transactions
Redis 核心数据结构 & Redis 6 新特性详
Use day JS let time (displayed as minutes, hours, days, months, and so on)
一个简单LEGv8处理器的Verilog实现【四】【单周期实现基础知识及模块设计讲解】

Excerpt from "misogyny: female disgust in Japan"
Build a secure and trusted computing platform based on Kunpeng's native security
随机推荐
Details of redis core data structure & new features of redis 6
[untitled]
Social responsibility · value co creation, Zhongguancun network security and Information Industry Alliance dialogue, wechat entrepreneur Haitai Fangyuan, chairman Mr. Jiang Haizhou
Excuse me, why is it that there are no consumption messages in redis and they are all piled up in redis? Cerely is used.
ndk初学习(一)
Use day JS let time (displayed as minutes, hours, days, months, and so on)
FC连接数据库,一定要使用自定义域名才能在外面访问吗?
118. Yanghui triangle
566. 重塑矩阵
VSCode 配置使用 PyLint 语法检查器
Flask session forged hctf admin
Attribute keywords aliases, calculated, cardinality, ClientName
Best practice | using Tencent cloud AI willingness to audit as the escort of telephone compliance
Parsing of XML files
2022-7-7 Leetcode 34.在排序数组中查找元素的第一个和最后一个位置
postgresql array类型,每一项拼接
[network security] SQL injection syntax summary
How can the PC page call QQ for online chat?
mysql导入文件出现Data truncated for column ‘xxx’ at row 1的原因
Dry goods | summarize the linkage use of those vulnerability tools