当前位置:网站首页>Flink | multi stream conversion
Flink | multi stream conversion
2022-07-07 13:32:00 【WK-WK】
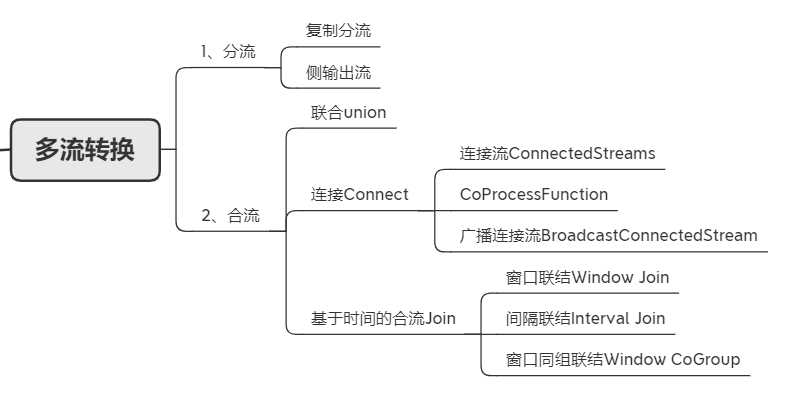
Multi stream conversion
List of articles
1.1 summary
describe
For stream operations , According to different needs , It will involve “ shunt ” and “ Confluence ” The operation of .shunt
1、 Side output flow diversionConfluence
1、union
2、connect
3、join
4、coGroup
1.2 shunt
1.2.1 Duplicate stream shunting
describe
The same stream is called multiple times , It is equivalent to making this stream copy many times , More commonly used is to print a stream , Then filter this stream
stream.print();
stream.filter();disadvantages :
The code will be redundant , Not enough efficient .
Sample code
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class SplitStreamByFilter {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Event> stream = env
.addSource(new ClickSource());
// Screening Mary The browsing behavior of MaryStream Streaming
DataStream<Event> MaryStream = stream.filter(new FilterFunction<Event>()
{
@Override
public boolean filter(Event value) throws Exception {
return value.user.equals("Mary");
}
});
// Screening Bob The act of putting into BobStream Streaming
DataStream<Event> BobStream = stream.filter(new FilterFunction<Event>() {
211
@Override
public boolean filter(Event value) throws Exception {
return value.user.equals("Bob");
}
});
// Filter other people's browsing behavior into elseStream Streaming
DataStream<Event> elseStream = stream.filter(new FilterFunction<Event>()
{
@Override
public boolean filter(Event value) throws Exception {
return !value.user.equals("Mary") && !value.user.equals("Bob") ;
}
});
MaryStream.print("Mary pv");
BobStream.print("Bob pv");
elseStream.print("else pv");
env.execute();
}
}
1.2.2 Side output stream output
describe
We will flow through process When the operator is converted , The structure of the resulting stream is single , But the type of side output stream is not limitedUse
(1) Definition
(2) Put the data into the side output stream
(3) Get the content of the side output stream
Reference resources : Processing function 【4.5 Side output stream 】
1.3 Confluence
1.3.1 union
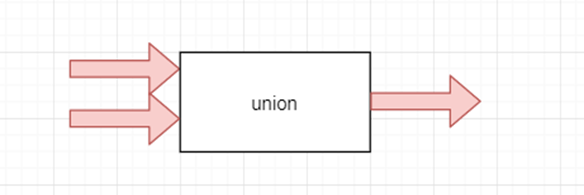
describe
Integrate the two streams , key word “ Synthesis of a ”Use
stream3 = stream1.union(stream2,…) stream1,stream2,stream3 Their three data structures are the same
Data structure means DataStream All three of them are xxxBe careful
1、 Sure union Multiple streams
2、 The data structure is required to be the same
3、 This involves merging multiple streams , There must be inconsistencies in each water level , When union when , Output to the downstream with the minimum water level .
Sample code
The main class 1
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<ClickEvent> stream1 =
env.socketTextStream("hadoop102", 7777)
.map(data -> {
String[] field = data.split(",");
return new ClickEvent(field[0].trim(), field[1].trim(),
Long.valueOf(field[2].trim()));
})
.assignTimestampsAndWatermarks(WatermarkStrategy.<ClickEvent>forBoundedOutOfOrderness(Duration.ofSeconds(2))
.withTimestampAssigner(new SerializableTimestampAssigner<ClickEvent>() {
@Override
public long extractTimestamp(ClickEvent element, long
recordTimestamp) {
return element.ts;
}
}));
stream1.print("stream1");
SingleOutputStreamOperator<ClickEvent> stream2 =
env.socketTextStream("hadoop103", 7777)
.map(data -> {
String[] field = data.split(",");
return new ClickEvent(field[0].trim(), field[1].trim(),
Long.valueOf(field[2].trim()));
})
.assignTimestampsAndWatermarks(WatermarkStrategy.<ClickEvent>forBoundedOutOfOrderness(Duration.ofSeconds(5))
.withTimestampAssigner(new SerializableTimestampAssigner<ClickEvent>() {
@Override
public long extractTimestamp(ClickEvent element, long
recordTimestamp) {
return element.ts;
}
}));
stream2.print("stream2");
// Merge two streams
stream1.union(stream2)
.process(new ProcessFunction<ClickEvent, String>() {
@Override
public void processElement(ClickEvent value, Context ctx,
Collector<String> out) throws Exception {
out.collect(" water position Line : " +
ctx.timerService().currentWatermark());
}
})
.print();
env.execute();
public class ClickSource implements SourceFunction<ClickEvent> {
// Sign a
private boolean running = true;
private Random random = new Random();
private String[] userArr = {
"Mary", "Bob", "Alice", "John", "Liz"};
private String[] urlArr = {
"./home", "./cart", "./fav", "./prod?id=1", "./prod?id=2"};
// Type of entry
@Override
public void run(SourceContext<ClickEvent> ctx) throws Exception {
while (running) {
ctx.collect(new ClickEvent(userArr[random.nextInt(userArr.length)], urlArr[random.nextInt(urlArr.length)], Calendar.getInstance().getTimeInMillis()));
// Sleeping for a period of time cannot happen all the time
Thread.sleep(100L);
}
}
// Stop logic
@Override
public void cancel() {
running = false;
}
}
public class ClickEvent {
// The nature of the event
public String username;
public String url;
public Long ts;
public ClickEvent(){
}
public ClickEvent(String username, String url, Long ts) {
this.username = username;
this.url = url;
this.ts = ts;
}
@Override
public String toString(){
return "ClickEvent{" +
"username='" + username + '\'' +
", url='" + url + '\'' +
", ts=" + new Timestamp(ts) +
'}';
}
}
1.3.2 Connect
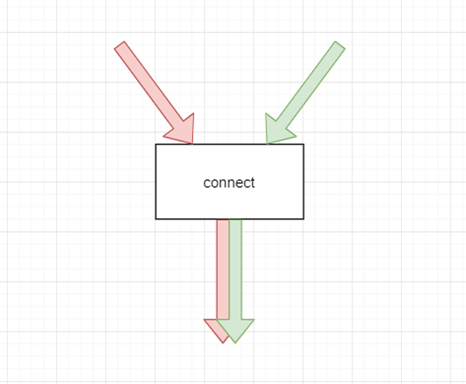
describe
Combine the two streams , key word “ Put it together ”characteristic
1、 The data structure of two streams can be different
2、 It can only be applied to the combination of two streams
3、 The data of the two streams are independent of each other
4、 The type of output stream is the sameUse
stream3 = stream1.connect(stream2);
stream1 The data type of is DataStream
stream2 The data type of is DataStraemAssembled stream3 The data type of is ConnectedStreams<Integer,String>
about stream3 The processing of uses CoMapFunction operator This operator data Co Family operators
Two methods of this operator
map1 It is the processing of left stream
map2 It is the processing of right stream
They don't interfere with each other
Sample code
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// Source
DataStream<Integer> stream1 = env.fromElements(1,2,3);
DataStream<Long> stream2 = env.fromElements(1L,2L,3L);
// Combined flow
ConnectedStreams<Integer, Long> connectedStreams = stream1.connect(stream2);
// Processing of merged streams
SingleOutputStreamOperator<String> result = connectedStreams
.map(new CoMapFunction<Integer, Long, String>() {
@Override
public String map1(Integer value) {
return "Integer: " + value;
}
@Override
public String map2(Long value) {
return "Long: " + value;
}
});
result.print();
env.execute("connect flow ");
This flow can be keyby, For different streams , Put them in different groups
1.3.3 connet flow key
describe
Put two different streams key, Put them into different groups , Put the two streams into different key inBe careful
Two stream key The type must be the sameCode example
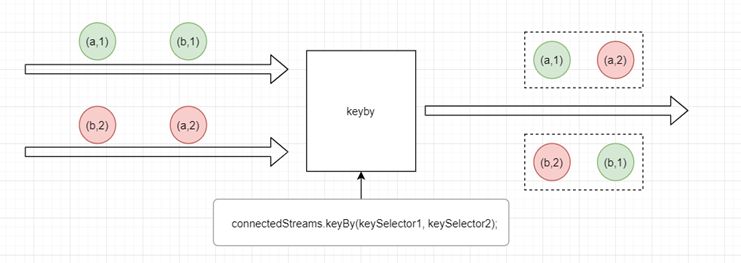
connectedStreams.keyBy(keySelector1, keySelector2);
This can only show that it matches , Logical processing , Cannot explain the same key The elements of will be interrelated , You need to customize the keying state to store the value of the element .summary
Matching can produce reaction
It's absolutely impossible to react if it doesn't match
1.3.4 CoProcessFunction
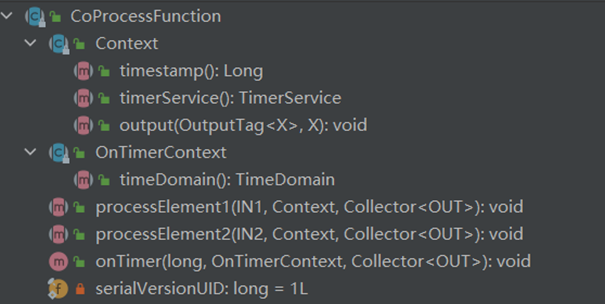
describe
For the operation of connection flow , Whether or not keyby, Or is it keyby Later flow , It needs to be processed through the collaborative processing functionExample
connectedStreams.process(new CoProcessFunction<IN1, IN2, OUT>{
public abstract void processElement1(IN1 value, Context ctx, Collector<OUT> out) throws Exception;
public abstract void processElement2(IN2 value, Context ctx, Collector<OUT> out) throws Exception;
})
explain
stream1.connect(stream2)
Whenever an element in the stream arrives , about stream1 The data of will call processElement1 Method , about stream2 The data of will call processElement2 MethodThere is no sequence when calling , The element of that stream will call that method
When the data in the two streams comes at the same time , Will synchronize
Remember here : When an element comes, call the corresponding methodThe elements in the two streams react
Use keyed state , Store elements in different streams in different keyed States
Because it's the same key, So in the life cycle of a state , Elements in one flow can access elements in another flow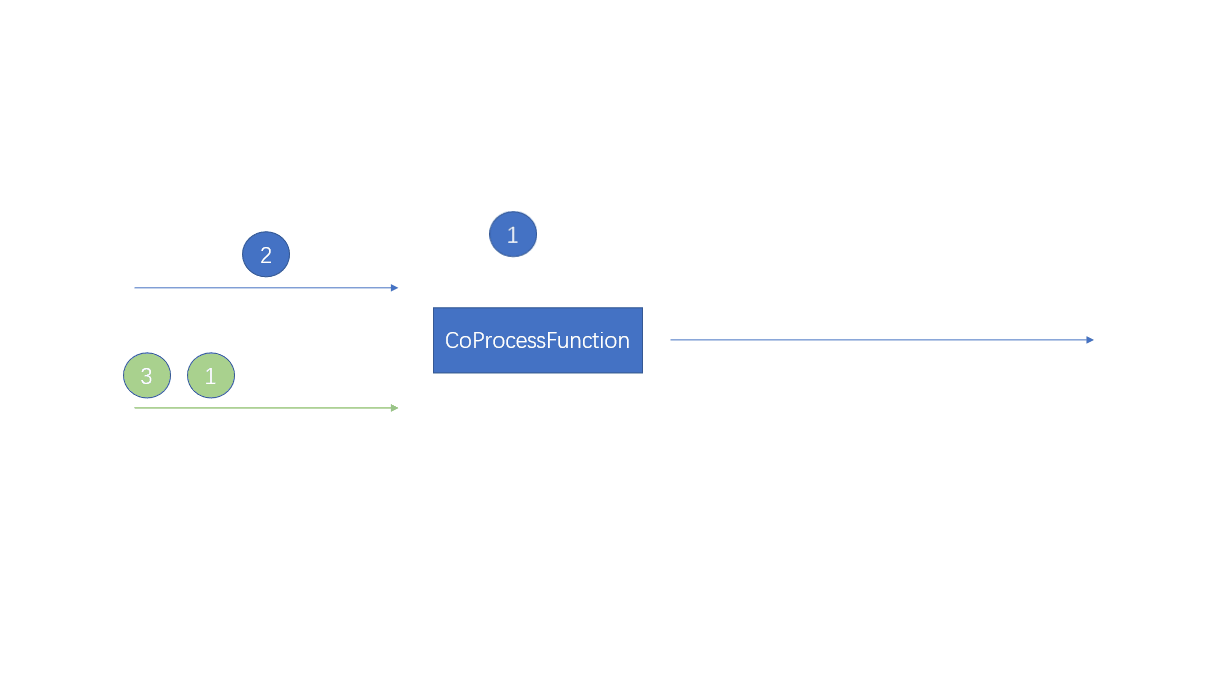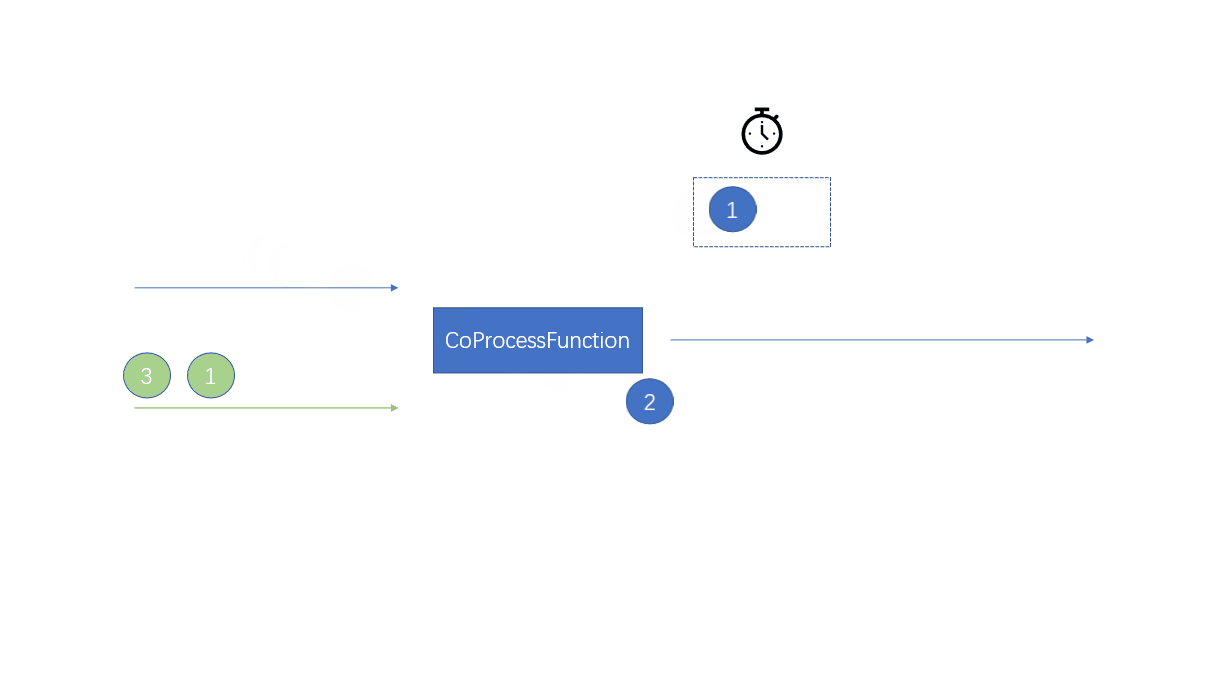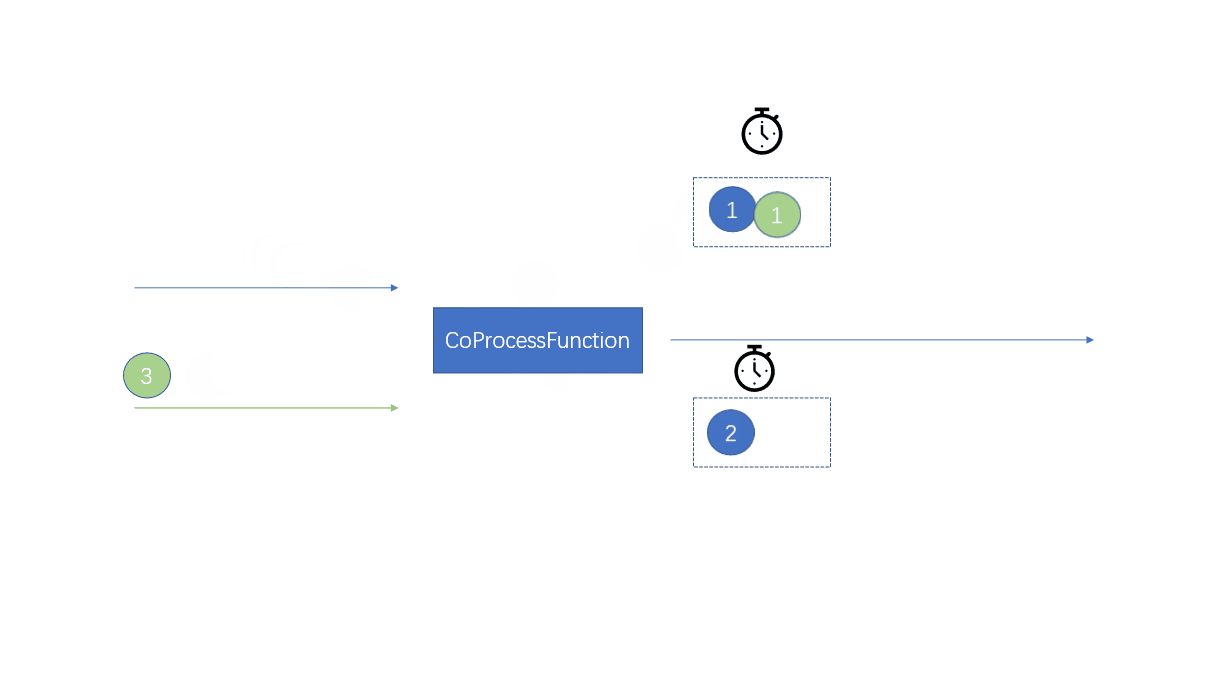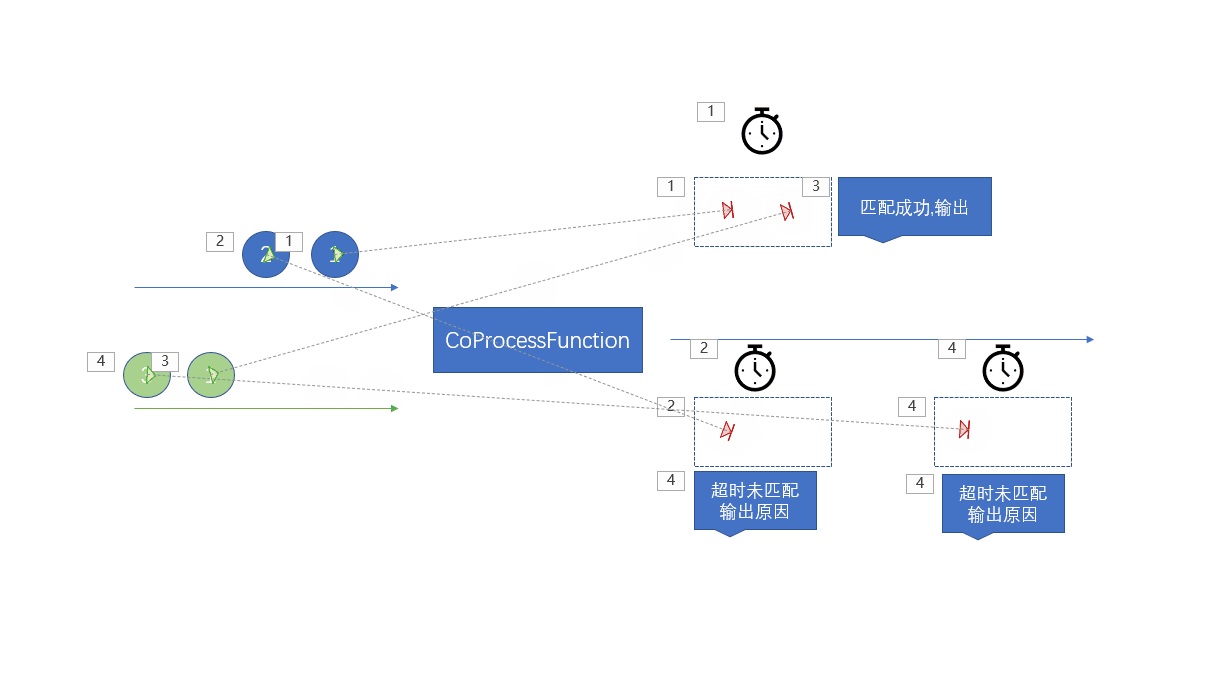
1.3.5 Broadcast connection flow
describe
Because the rules change in real time , So we can use a separate stream to get the rule data ; These rules or configurations are globally valid for the entire application , the
So you can't just pass this data to a downstream parallel subtask for processing , But to “ radio broadcast ”(broadcast) Give all parallel subtasks . And the downstream task receives the broadcast rules , Will save it in a state , That's what's called “ Broadcast status ”(broadcast state).explain
The bottom layer of broadcast stream state is a Map Structure to preserve
- Definition of broadcast stream
// Define and describe the state
MapStateDescriptor<String, Rule> ruleStateDescriptor = new MapStateDescriptor<>(...);
BroadcastStream<Rule> ruleBroadcastStream = ruleStream.broadcast(ruleStateDescriptor);
- Process after Association
stream
.connect(ruleBroadcastStream)
// The first generic stream Flow structure of
// The second generic ruleBroadcastStream Flow structure of
// The third generic Output generics
.process(new BroadcastProcessFunction<Integer, String, String>() {
// Handle stream
@Override
public void processElement(Integer value, BroadcastProcessFunction<Integer, String, String>.ReadOnlyContext ctx, Collector<String> out) throws Exception {
}
// Handle ruleBroadcastStream
@Override
public void processBroadcastElement(String value, BroadcastProcessFunction<Integer, String, String>.Context ctx, Collector<String> out) throws Exception {
}
});
1.4 Time based confluence
- describe
In ordinary offline scenarios ,join There are a lot of scenes , A table is based on id Match the data in another table , In real time scene , You need to combine the information of the two streams . Be similar to Hive Medium join
1.4.1 Window connection (Window Join)
- describe
Base elements on key Grouping , Then put it in different windows for calculation , Two streams share a common key .
- call
stream1.join(stream2)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(<WindowAssigner>)
.apply(<JoinFunction>)
where Of keySelector It's the first stream key Selectors ,equalto It's the second stream key Selectors . The elements of the two streams are in the same window , When the window closes , Conduct JoinFunciton To deal with
The window here can be
1. Scroll the window
1. The sliding window
1. Session window
final apply Function can be regarded as a special window function , Only... Can be called here .apply() convert

It's actually window Methods
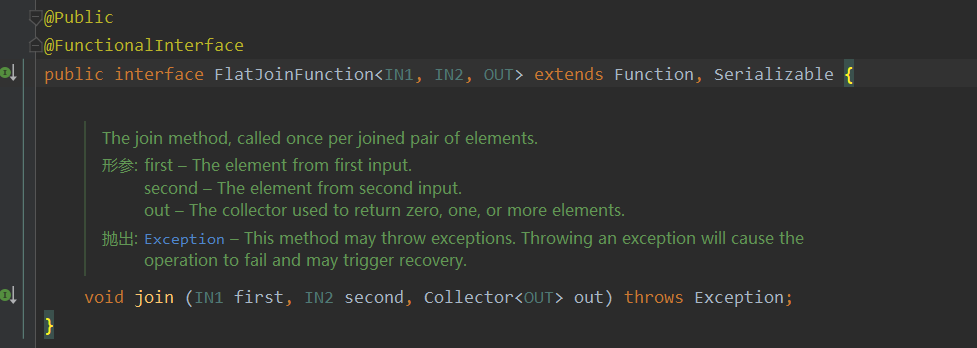
- JoinFunction
Is the interface of a function class , When using, you need to implement internal join Method , When to trigger ,

- call , The specific logic
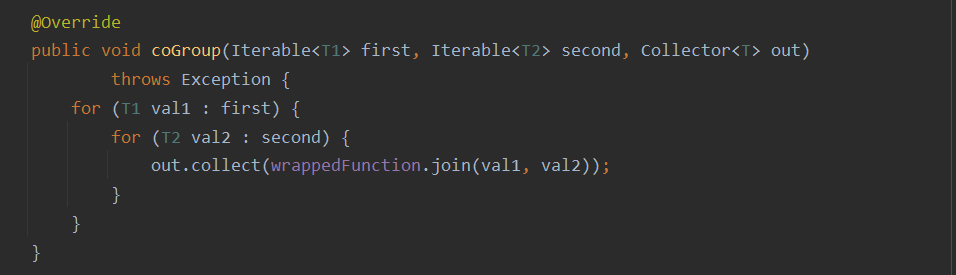
first All elements representing the first stream in this window ,second All elements representing the second stream in this window
- Be careful
Also because apply The method is window Methods , Triggers can also be set , Or set the delay time
1.4.4.1 Processing flow
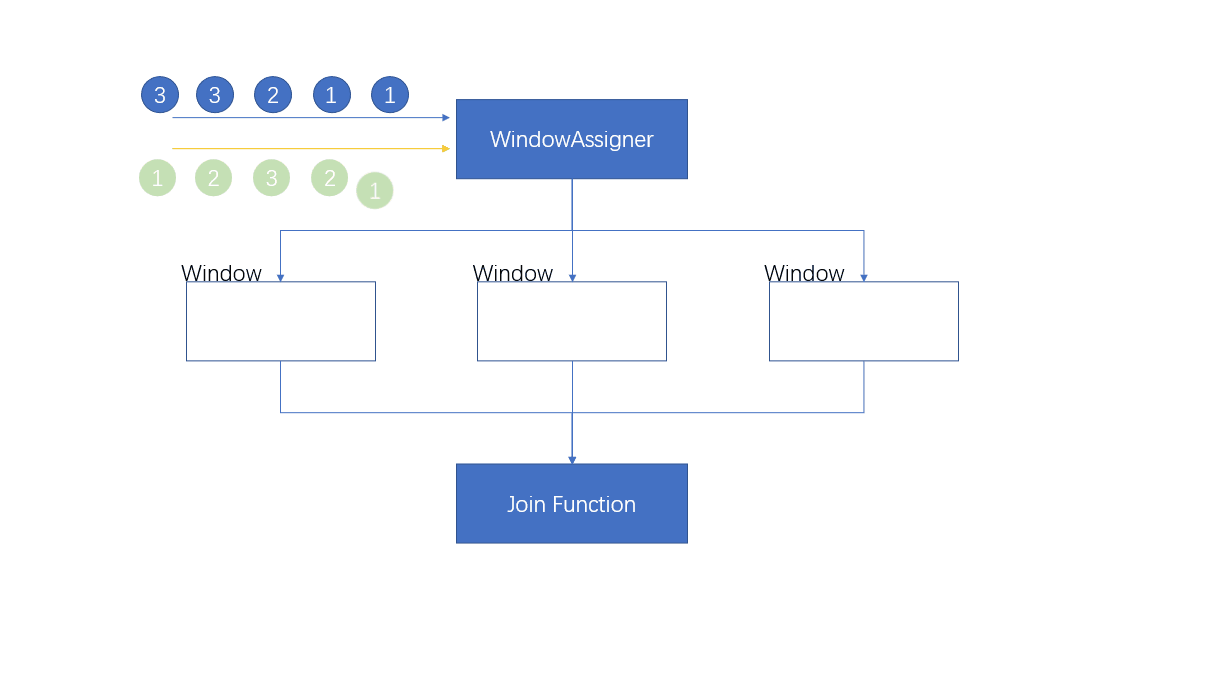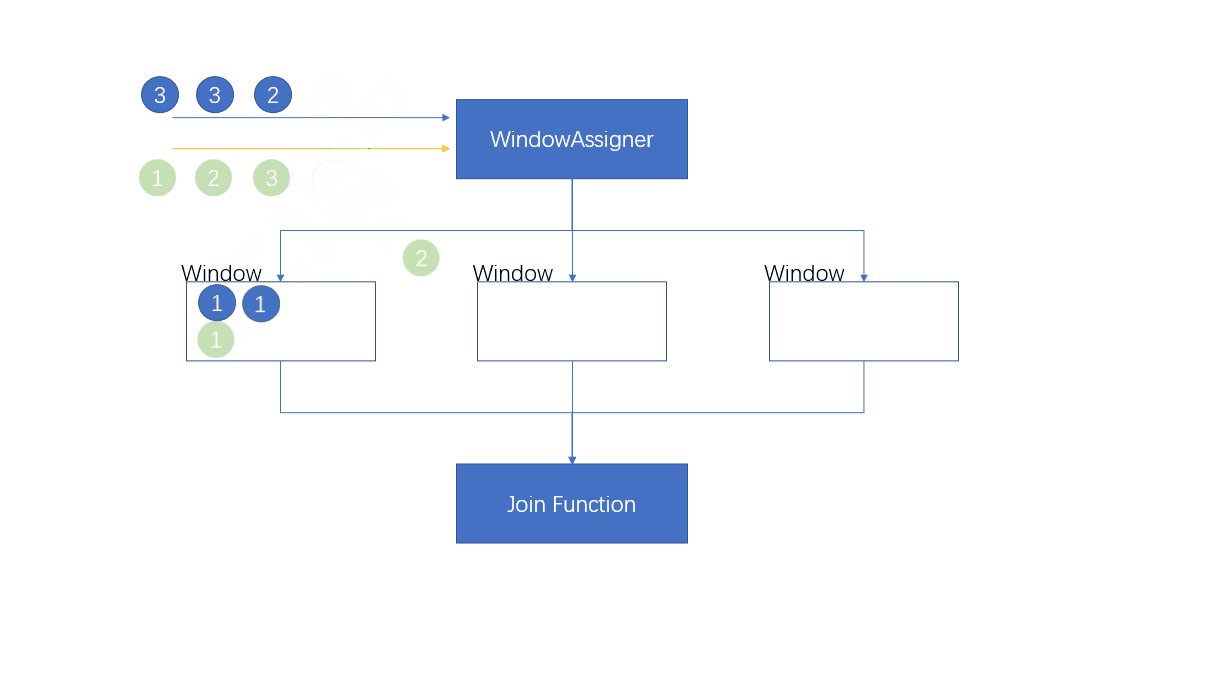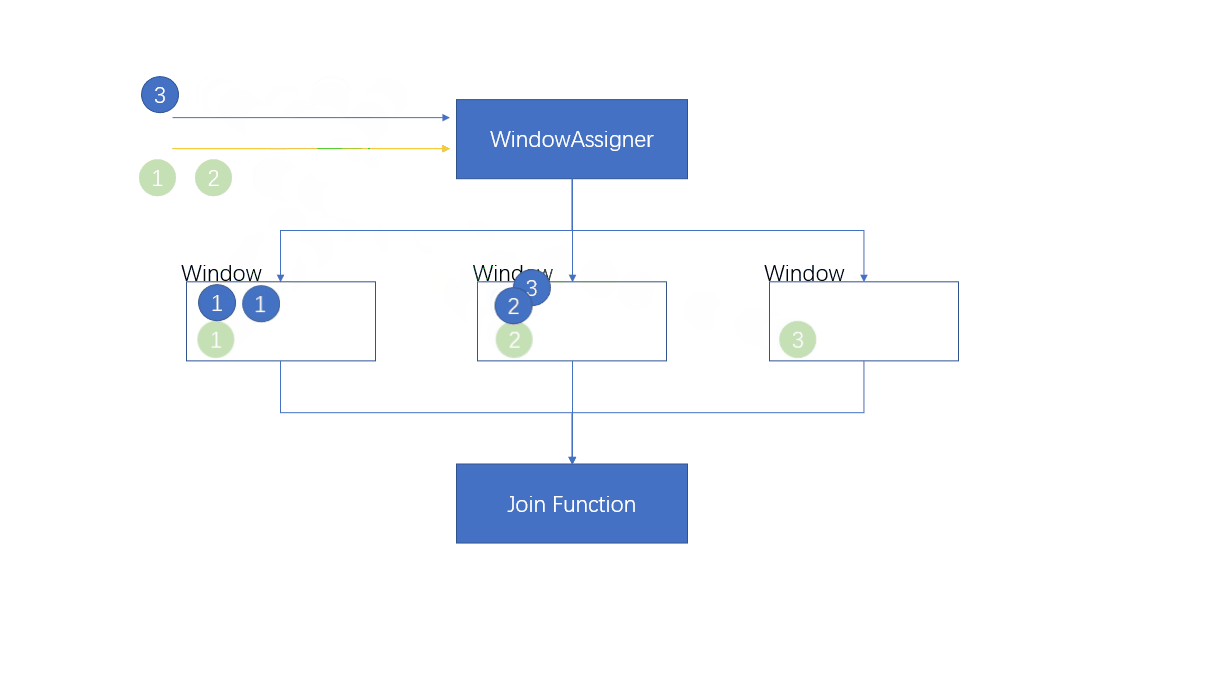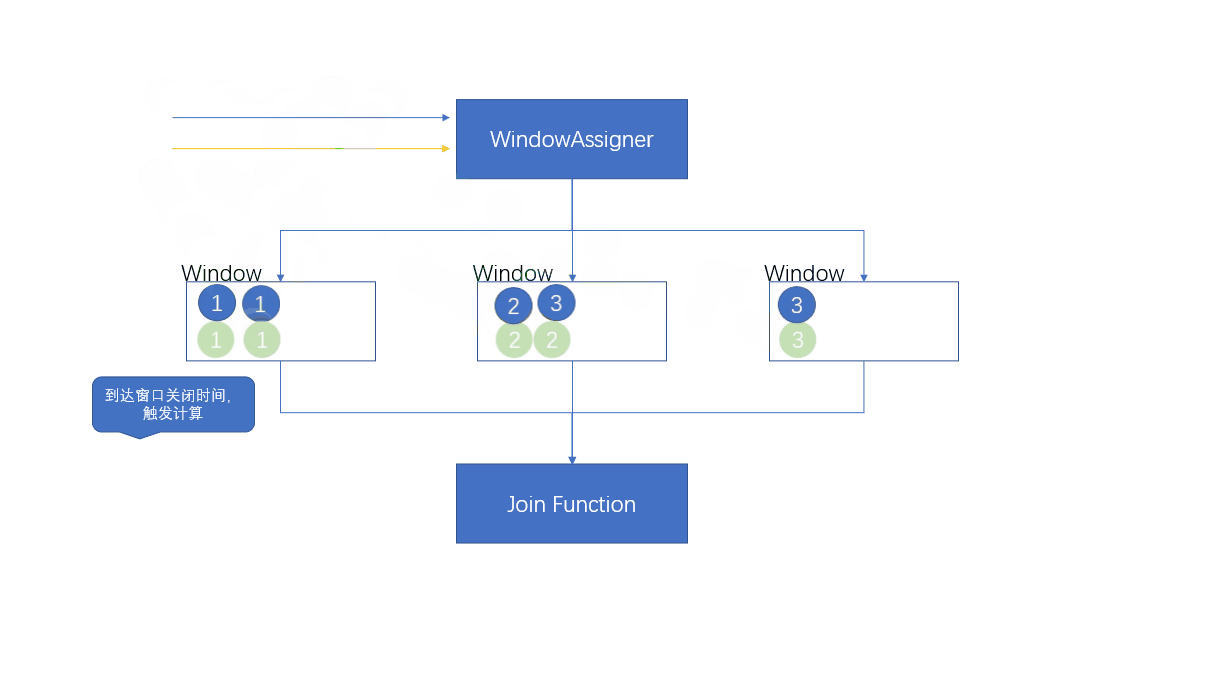
- Be careful
When the first element of the output window comes , Will create a window , When the window is closed , The window it belongs to has been closed , Will this create a new window
A new window will be created , Even if the previous window has been closed .
If key Is not the only , There will be a lot of the same key Enter a window , We saw earlier that when the window closes and triggers the calculation , Essentially, it loops through the elements of two streams
The time complexity is O(n^2), So in the actual problem solving , This situation needs to be avoided , Guarantee key The only
When there is only one flow of elements in the window , There are no elements matching to another stream , ... will not be called at this time JoinFunction
- At the window apply In the method

except joinFunction, One more flatJoinfunction
- Difference
joinFunction, Matching a team will only output once ,flatjoinFunction You can customize the output zero or more times . Because it is output downstream through the collector
1.4.4.2 summary
This way is similar to Hive Medium
SELECT * FROM table1 t1, table2 t2 WHERE t1.id = t2.id;
It is essentially internal connection , But the difference is , The data in the window is like this , If the element data is different from the window , Elements don't match
1.4.2 Interval connection (Interval Join)
- describe
We can see from above , Although the elements of the two streams have the same key, But due to the different time of arrival , The window of the early element has been closed , When another element comes, a new window will be created . In some cases , We need these two elements to match , It's not appropriate to use windows again .
For the above needs ,interval join It can be solved perfectly . For each element in a stream , Open up an interval before and after its timestamp , See if there is any data matching during this period .
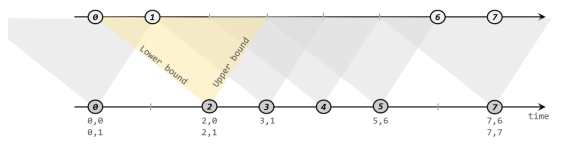
- principle
Elements in a stream , Define a upper bound (upperBound) and Lower bound (lowerBound), That is to match this element , How long before the element , The lower bound is the data of how long after this element is matched . Including upper bound and lower bound .
For an element a, The timestamp is t, Then it will match another stream [ t + lowerBound , t + upperBound ]
There is another point of attention , Is another flow corresponding key The data of the same period of time will match
1.4.2.1 Use
Interval connection is based on KeyedStream Connection operation of , The call method is as follows
stream1
.keyBy(<KeySelector>)
.intervalJoin(stream2.keyBy(<KeySelector>))
.between(Time.milliseconds(-2), Time.milliseconds(1))
.process (new ProcessJoinFunction<Integer, Integer, String(){
@Override
public void processElement(Integer left, Integer right, Context ctx,
Collector<String> out) {
out.collect(left + "," + right);
}
});
- Be careful
There is only one match here , As long as you can match the data, you can output
1.4.2.2 test
1、 Main stream join Side flow: multiple side flows in the same time period
ctx.collectWithTimestamp(Tuple2.of(1, " Main stream 1"), 1000L);
ctx.collectWithTimestamp(Tuple2.of(1, " Sidestream 1"), 1000L);
ctx.collectWithTimestamp(Tuple2.of(1, " Sidestream 1"), 1500L);
ctx.collectWithTimestamp(Tuple2.of(1, " Sidestream 1"), 2000L);
Output as long as it can match ,a The range is [0,3000L]
2、 The mainstream has two elements in the same area , Go to join An element
ctx.collectWithTimestamp(Tuple2.of(1, " Main stream 1"), 1000L);
ctx.collectWithTimestamp(Tuple2.of(1, " Main stream 2"), 2000L);
ctx.collectWithTimestamp(Tuple2.of(1, " Sidestream 1"), 1000L);
Will match
3、 The mainstream has two elements in the same area , Go to join Multiple elements
As long as it matches within the scope of each element in the mainstream , Description will match duplicate data
1.4.2.3 Underlying implementation principle

Put elements with the same timestamp in the stream
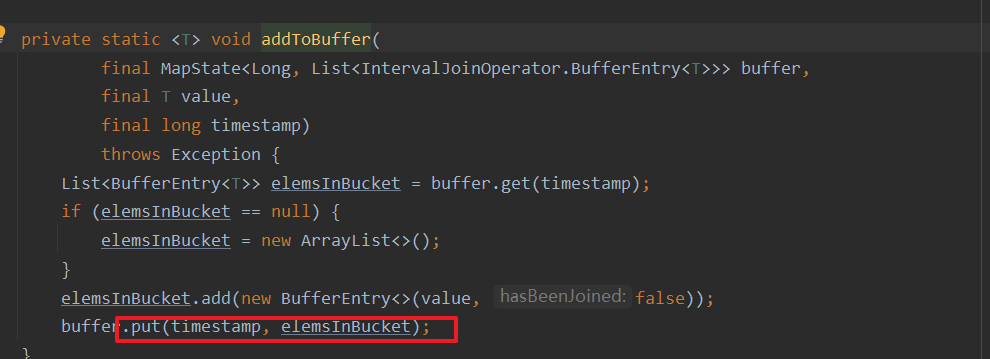
buffler The essence is mapstate. If this timestamp value, That is to say list When it's empty 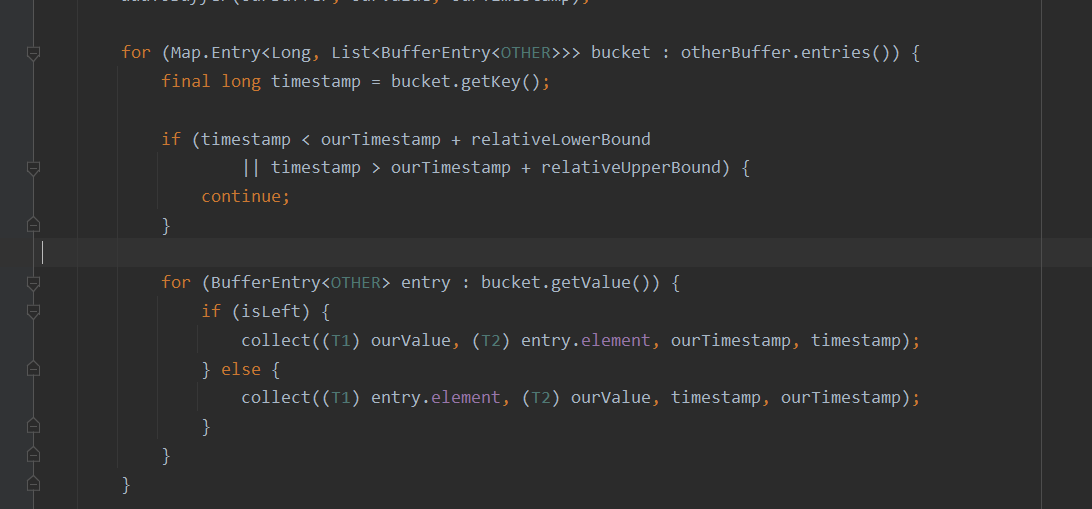
If it is
1、 First keyby
2、 stay connect
3、 Define two mapstate, A place called leftbuffer、 A place called rightBuffer
4、 The same method used for processing two elements
Main stream

Sidestream 
Call the same method 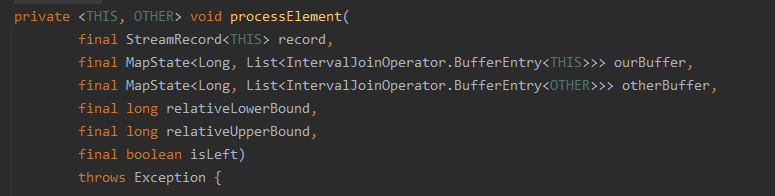
final THIS ourValue = record.getValue();
final long ourTimestamp = record.getTimestamp();
if (ourTimestamp == Long.MIN_VALUE) {
throw new FlinkException(
"Long.MIN_VALUE timestamp: Elements used in "
+ "interval stream joins need to have timestamps meaningful timestamps.");
}
if (isLate(ourTimestamp)) {
return;
}
addToBuffer(ourBuffer, ourValue, ourTimestamp);
for (Map.Entry<Long, List<BufferEntry<OTHER>>> bucket : otherBuffer.entries()) {
final long timestamp = bucket.getKey();
if (timestamp < ourTimestamp + relativeLowerBound
|| timestamp > ourTimestamp + relativeUpperBound) {
continue;
}
for (BufferEntry<OTHER> entry : bucket.getValue()) {
if (isLeft) {
collect((T1) ourValue, (T2) entry.element, ourTimestamp, timestamp);
} else {
collect((T1) entry.element, (T2) ourValue, timestamp, ourTimestamp);
}
}
}
long cleanupTime =
(relativeUpperBound > 0L) ? ourTimestamp + relativeUpperBound : ourTimestamp;
if (isLeft) {
internalTimerService.registerEventTimeTimer(CLEANUP_NAMESPACE_LEFT, cleanupTime);
} else {
internalTimerService.registerEventTimeTimer(CLEANUP_NAMESPACE_RIGHT, cleanupTime);
}
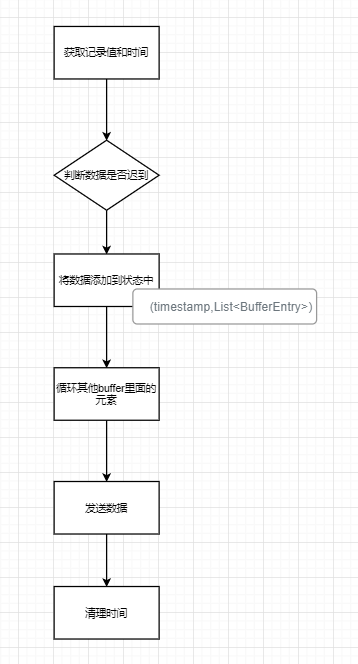
The process of bidirectional matching .
The essence is ,keyby + connet +mapstate<long,List> All data of a timestamp

Cowhide
1.4.3 The window is connected with the group (Window CoGroup)
Use
strea1.coGroup(stream2)
.where(<keySelector>)
.equalTo(<KeySelector>)
.window(TumblingEventTimeWindows.of(Time.hours(1)))
.apply(<CoGroupFunction)
And join The difference between
apply The method used is CoGroupFunction
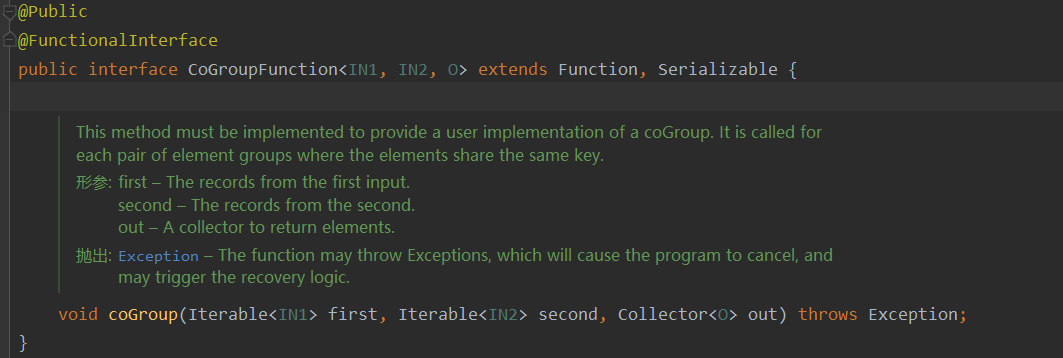
- effect
Send the collected data to , And only called once CoGroupFunction, How to call it is up to you
Even if a stream has no elements , Another stream can also complete matching .
summary
边栏推荐
- PAcP learning note 1: programming with pcap
- Simple and easy-to-use code specification
- LeetCode_ Binary search_ Medium_ 153. Find the minimum value in the rotation sort array
- 服务器到服务器 (S2S) 事件 (Adjust)
- PACP学习笔记三:PCAP方法说明
- 【等保】云计算安全扩展要求关注的安全目标和实现方式区分原则有哪些?
- 【面试高频题】难度 2.5/5,简单结合 DFS 的 Trie 模板级运用题
- 我那“不好惹”的00后下属:不差钱,怼领导,抵制加班
- MySQL error 28 and solution
- Split screen bug notes
猜你喜欢
High end for 8 years, how is Yadi now?

【堡垒机】云堡垒机和普通堡垒机的区别是什么?
Flink | 多流转换
Detr introduction

QQ的药,腾讯的票

Japanese government and enterprise employees got drunk and lost 460000 information USB flash drives. They publicly apologized and disclosed password rules
DID登陆-MetaMask
JS slow motion animation principle teaching (super detail)
MySQL入门尝鲜
Thread pool reject policy best practices
随机推荐
DETR介绍
云计算安全扩展要求关注的安全目标和实现方式区分原则有哪些?
ESP32构解工程添加组件
DID登陆-MetaMask
Split screen bug notes
MongoDB优化的几点原则
Write it down once Net a new energy system thread surge analysis
抓细抓实抓好安全生产各项工作 全力确保人民群众生命财产安全
Use of polarscatter function in MATLAB
xshell连接服务器把密钥登陆改为密码登陆
cmake 学习使用笔记(一)
Introduction and basic use of stored procedures
Navicat运行sql文件导入数据不全或导入失败
PACP学习笔记一:使用 PCAP 编程
[dark horse morning post] Huawei refutes rumors about "military master" Chen Chunhua; Hengchi 5 has a pre-sale price of 179000 yuan; Jay Chou's new album MV has played more than 100 million in 3 hours
JS determines whether an object is empty
Write it down once Net a new energy system thread surge analysis
1、深拷贝 2、call apply bind 3、for of for in 区别
Esp32 construction engineering add components
简单好用的代码规范