当前位置:网站首页>Flink | 多流转换
Flink | 多流转换
2022-07-07 11:28:00 【WK-WK】
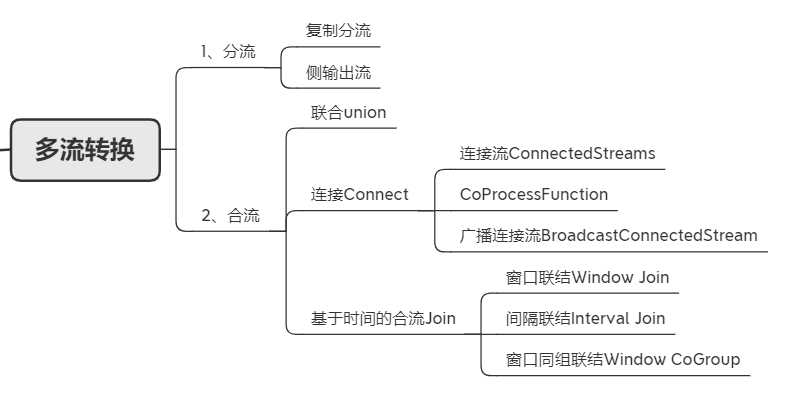
多流转换
文章目录
1.1 概述
描述
对于流的操作,根据需求的不同,会涉及到“分流”和“合流”的操作。分流
1、侧输出流分流合流
1、union
2、connect
3、join
4、coGroup
1.2 分流
1.2.1 复制流分流
描述
同一条流调用多次,相当于让这个流复制了多次,比较常用的是打印一条流,然后对这条流做过滤操作
stream.print();
stream.filter();弊端:
代码会有冗余,不够高效。
示例代码
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class SplitStreamByFilter {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Event> stream = env
.addSource(new ClickSource());
// 筛选 Mary 的浏览行为放入 MaryStream 流中
DataStream<Event> MaryStream = stream.filter(new FilterFunction<Event>()
{
@Override
public boolean filter(Event value) throws Exception {
return value.user.equals("Mary");
}
});
// 筛选 Bob 的购买行为放入 BobStream 流中
DataStream<Event> BobStream = stream.filter(new FilterFunction<Event>() {
211
@Override
public boolean filter(Event value) throws Exception {
return value.user.equals("Bob");
}
});
// 筛选其他人的浏览行为放入 elseStream 流中
DataStream<Event> elseStream = stream.filter(new FilterFunction<Event>()
{
@Override
public boolean filter(Event value) throws Exception {
return !value.user.equals("Mary") && !value.user.equals("Bob") ;
}
});
MaryStream.print("Mary pv");
BobStream.print("Bob pv");
elseStream.print("else pv");
env.execute();
}
}
1.2.2 侧输出流输出
描述
我们将一条流通过process算子进行转换时,得到的流的结构是单一的,但是侧输出流的类型不收限制使用
(1)定义
(2)把数据放到侧输出流中
(3)获取侧输出流内容
参考:处理函数【4.5侧输出流】
1.3 合流
1.3.1 union
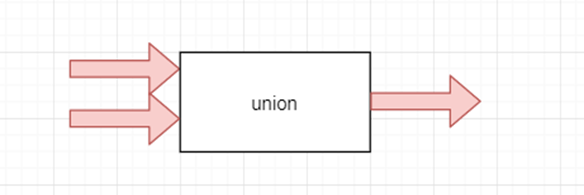
描述
将两条流融为一体,关键词“合成一个”使用
stream3 = stream1.union(stream2,…) stream1,stream2,stream3 他们三个数据结构相同
数据结构是指 DataStream 他们三个的类型都是 xxx注意
1、可以union多个流
2、要求数据结构一样
3、这里涉及到多个流合并,肯定会存在每个流水位线不一致的情况,当union时,用最小的水位线输出到下游。
示例代码
主类1
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<ClickEvent> stream1 =
env.socketTextStream("hadoop102", 7777)
.map(data -> {
String[] field = data.split(",");
return new ClickEvent(field[0].trim(), field[1].trim(),
Long.valueOf(field[2].trim()));
})
.assignTimestampsAndWatermarks(WatermarkStrategy.<ClickEvent>forBoundedOutOfOrderness(Duration.ofSeconds(2))
.withTimestampAssigner(new SerializableTimestampAssigner<ClickEvent>() {
@Override
public long extractTimestamp(ClickEvent element, long
recordTimestamp) {
return element.ts;
}
}));
stream1.print("stream1");
SingleOutputStreamOperator<ClickEvent> stream2 =
env.socketTextStream("hadoop103", 7777)
.map(data -> {
String[] field = data.split(",");
return new ClickEvent(field[0].trim(), field[1].trim(),
Long.valueOf(field[2].trim()));
})
.assignTimestampsAndWatermarks(WatermarkStrategy.<ClickEvent>forBoundedOutOfOrderness(Duration.ofSeconds(5))
.withTimestampAssigner(new SerializableTimestampAssigner<ClickEvent>() {
@Override
public long extractTimestamp(ClickEvent element, long
recordTimestamp) {
return element.ts;
}
}));
stream2.print("stream2");
// 合并两条流
stream1.union(stream2)
.process(new ProcessFunction<ClickEvent, String>() {
@Override
public void processElement(ClickEvent value, Context ctx,
Collector<String> out) throws Exception {
out.collect(" 水 位 线 : " +
ctx.timerService().currentWatermark());
}
})
.print();
env.execute();
public class ClickSource implements SourceFunction<ClickEvent> {
// 标志位
private boolean running = true;
private Random random = new Random();
private String[] userArr = {
"Mary", "Bob", "Alice", "John", "Liz"};
private String[] urlArr = {
"./home", "./cart", "./fav", "./prod?id=1", "./prod?id=2"};
// 进入的类型
@Override
public void run(SourceContext<ClickEvent> ctx) throws Exception {
while (running) {
ctx.collect(new ClickEvent(userArr[random.nextInt(userArr.length)], urlArr[random.nextInt(urlArr.length)], Calendar.getInstance().getTimeInMillis()));
// 睡一段事件不能一直发
Thread.sleep(100L);
}
}
// 停止逻辑
@Override
public void cancel() {
running = false;
}
}
public class ClickEvent {
// 事件的属性
public String username;
public String url;
public Long ts;
public ClickEvent(){
}
public ClickEvent(String username, String url, Long ts) {
this.username = username;
this.url = url;
this.ts = ts;
}
@Override
public String toString(){
return "ClickEvent{" +
"username='" + username + '\'' +
", url='" + url + '\'' +
", ts=" + new Timestamp(ts) +
'}';
}
}
1.3.2 Connect
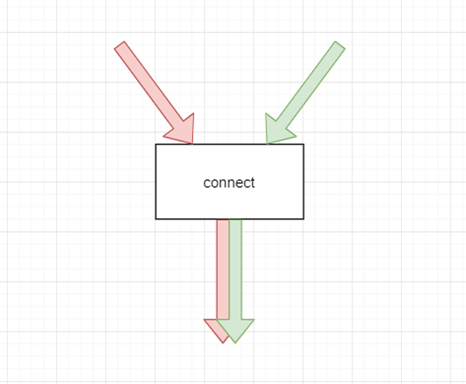
描述
将两条流联合起来,关键词“组装到一起”特点
1、两条流的数据结构可以不一样
2、只能应用于两条流的联合
3、两条流的数据是彼此独立的
4、输出流的类型相同使用
stream3 = stream1.connect(stream2);
stream1 的数据类型是 DataStream
stream2 的数据类型是 DataStraem组装起来的stream3 的数据类型是 ConnectedStreams<Integer,String>
对于stream3的处理使用到CoMapFunction算子 这个算子数据Co家族的算子
这个算子的两个方法
map1是对左流的处理
map2是对右流的处理
两者互不干扰
示例代码
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 源
DataStream<Integer> stream1 = env.fromElements(1,2,3);
DataStream<Long> stream2 = env.fromElements(1L,2L,3L);
// 合并流
ConnectedStreams<Integer, Long> connectedStreams = stream1.connect(stream2);
// 对合并流的处理
SingleOutputStreamOperator<String> result = connectedStreams
.map(new CoMapFunction<Integer, Long, String>() {
@Override
public String map1(Integer value) {
return "Integer: " + value;
}
@Override
public String map2(Long value) {
return "Long: " + value;
}
});
result.print();
env.execute("connect流");
这个流可以进行keyby,对于不同的流,放到不同的组里面去
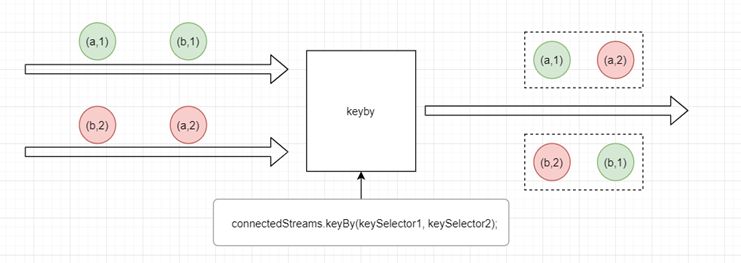
1.3.3 connet流key
描述
把两条流不同的key,放入到不同的组里面,将两条流放入到不同的key中注意
两条流的key类型必须一致代码示例
connectedStreams.keyBy(keySelector1, keySelector2);
这里只能说明匹配上了,逻辑上的处理,不能说明相同key的元素会相互关联,需要自定义键控状态分到用于存储元素的值。总结
匹配上的可以产生反应
匹配不上的绝对不可能产生反应
1.3.4 CoProcessFunction
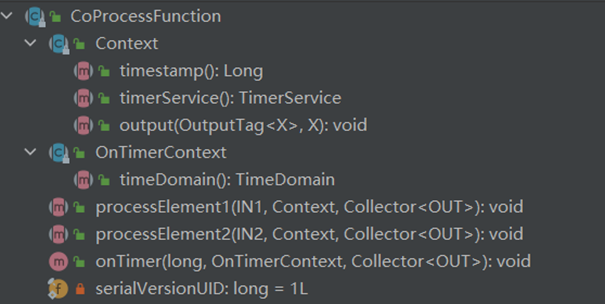
描述
对于连接流的操作,不管是没有keyby,亦或是keyby之后的流,需要通过协同处理函数进行处理示例
connectedStreams.process(new CoProcessFunction<IN1, IN2, OUT>{
public abstract void processElement1(IN1 value, Context ctx, Collector<OUT> out) throws Exception;
public abstract void processElement2(IN2 value, Context ctx, Collector<OUT> out) throws Exception;
})
说明
stream1.connect(stream2)
每当流中的一条元素到来时,对于stream1的数据会调用processElement1方法,对于stream2的数据会调用processElement2方法调用的时候没有先后顺序之分,那个流的元素过来就会调用那个方法
两个流中的数据相同时间过来的时候,会同步处理
这里记住:一个元素过来的时候调用相应的方法两个流中的元素产生反应
使用键控状态,将不同的流中的元素存储到不同的键控状态中
因为是相同的key,所以在状态的生命周期中,一个流中的元素可以访问另一个流中的元素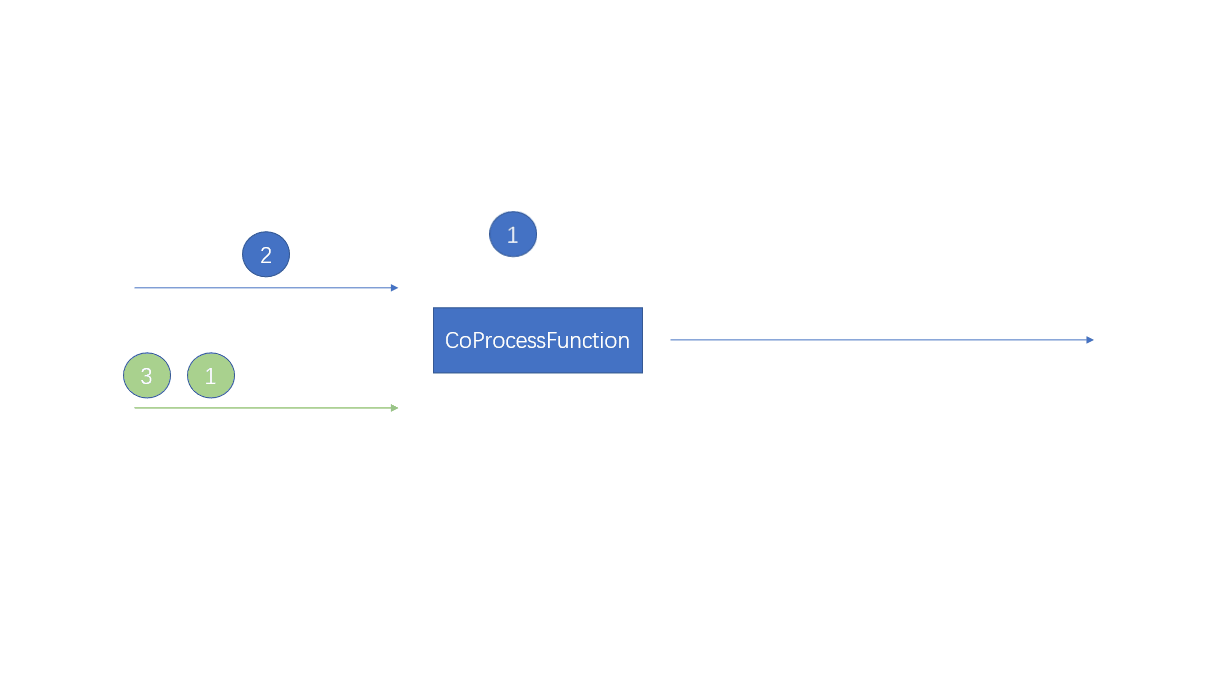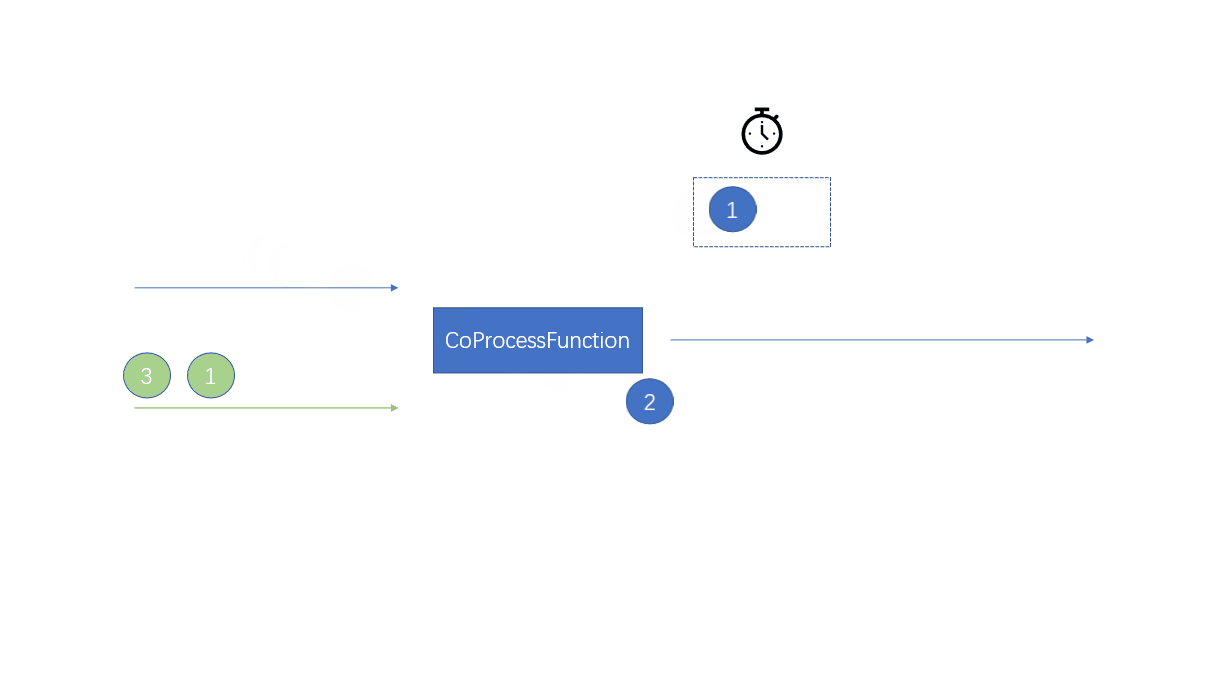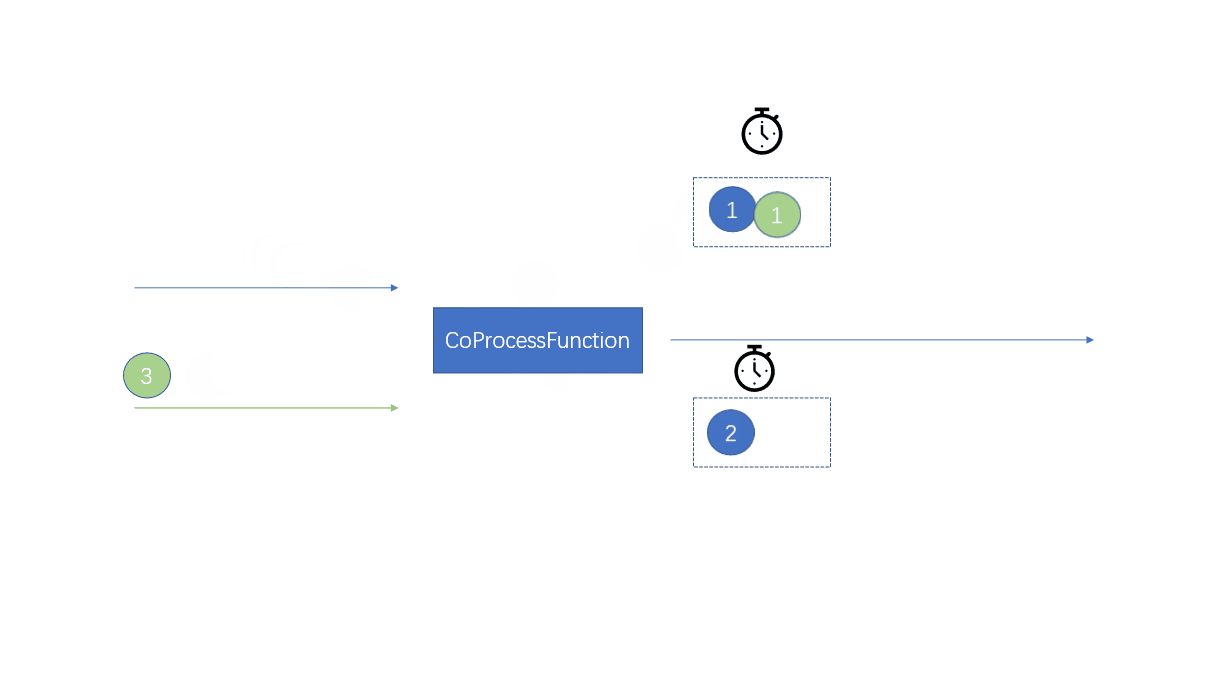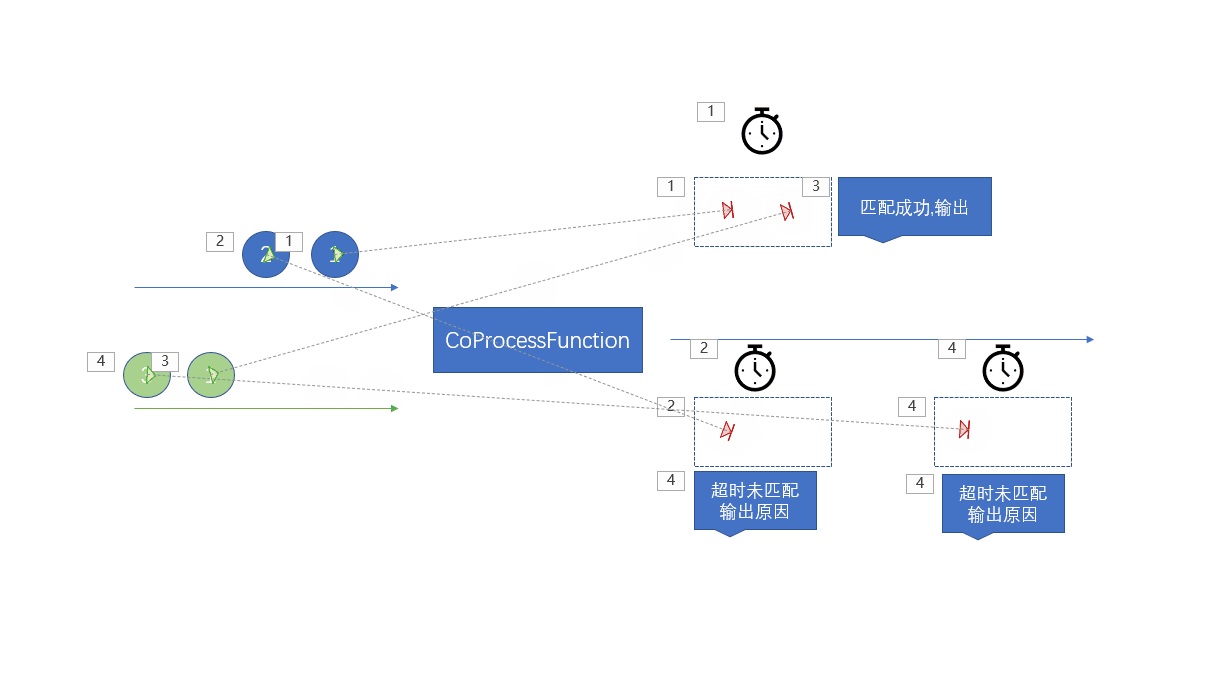
1.3.5 广播连接流
描述
因为规则是实时变动的,所以我们可以用一个单独的流来获取规则数据;而这些规则或配置是对整个应用全局有效的,所
以不能只把这数据传递给一个下游并行子任务处理,而是要“广播”(broadcast)给所有的并行子任务。而下游子任务收到广播出来的规则,会把它保存成一个状态,这就是所谓的“广播状态”(broadcast state)。说明
广播流状态底层是用一个 Map结构来保存的
- 广播流的定义
// 定义描述状态
MapStateDescriptor<String, Rule> ruleStateDescriptor = new MapStateDescriptor<>(...);
BroadcastStream<Rule> ruleBroadcastStream = ruleStream.broadcast(ruleStateDescriptor);
- 关联之后进行处理
stream
.connect(ruleBroadcastStream)
// 第一个泛型 stream的流结构
// 第二个泛型 ruleBroadcastStream的流结构
// 第三个泛型 输出的泛型
.process(new BroadcastProcessFunction<Integer, String, String>() {
// 处理stream
@Override
public void processElement(Integer value, BroadcastProcessFunction<Integer, String, String>.ReadOnlyContext ctx, Collector<String> out) throws Exception {
}
// 处理ruleBroadcastStream
@Override
public void processBroadcastElement(String value, BroadcastProcessFunction<Integer, String, String>.Context ctx, Collector<String> out) throws Exception {
}
});
1.4 基于时间的合流
- 描述
在普通离线场景下,join的场景很多,一个表根据id匹配另一个表里面的数据,实时场景下,需要将两条流的信息合并起来。类似于Hive中的join
1.4.1 窗口联结(Window Join)
- 描述
将元素根据key进行分组,然后放到不同的窗口中进行计算,两条流共享一个公共键。
- 调用
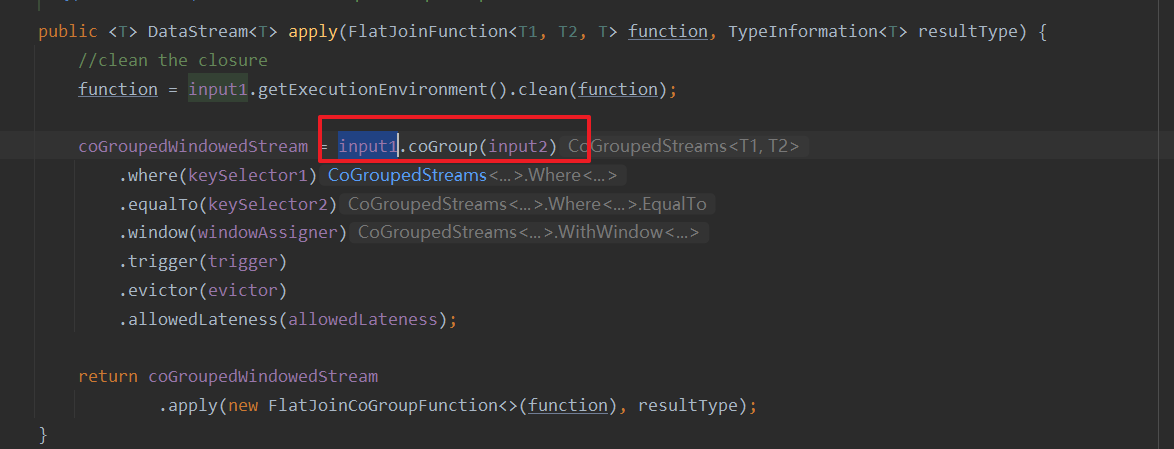
stream1.join(stream2)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(<WindowAssigner>)
.apply(<JoinFunction>)
where的keySelector是第一条流的key选择器,equalto是第二条流的key选择器。两条流的元素在同一窗口中,当窗口关闭的时候,进行JoinFunciton进行处理
这里的窗口可以为
1. 滚动窗口
1. 滑动窗口
1. 会话窗口
最后的apply函数可以看成特殊的窗口函数,这里只能调用.apply()进行转换

实际上是window的方法
- JoinFunction
是一个函数类的接口,使用时需要实现内部的join方法,什么时候触发,

- 调用,具体逻辑
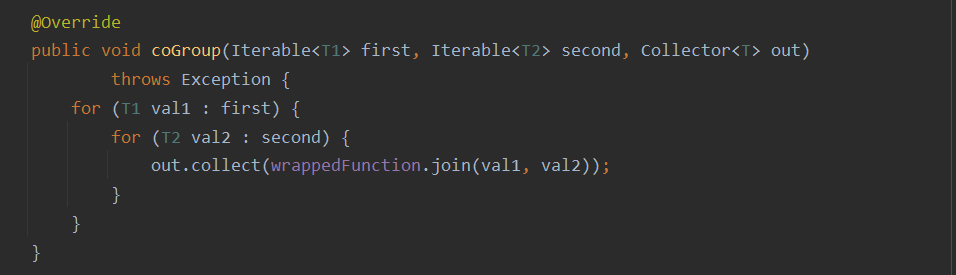
first代表这个窗口中第一条流的所有元素,second代表这个窗口中第二条流的所有元素
- 注意
同样因为apply方法是window的方法,同样可以设置触发器,或者设定延迟时间
1.4.4.1 处理流程
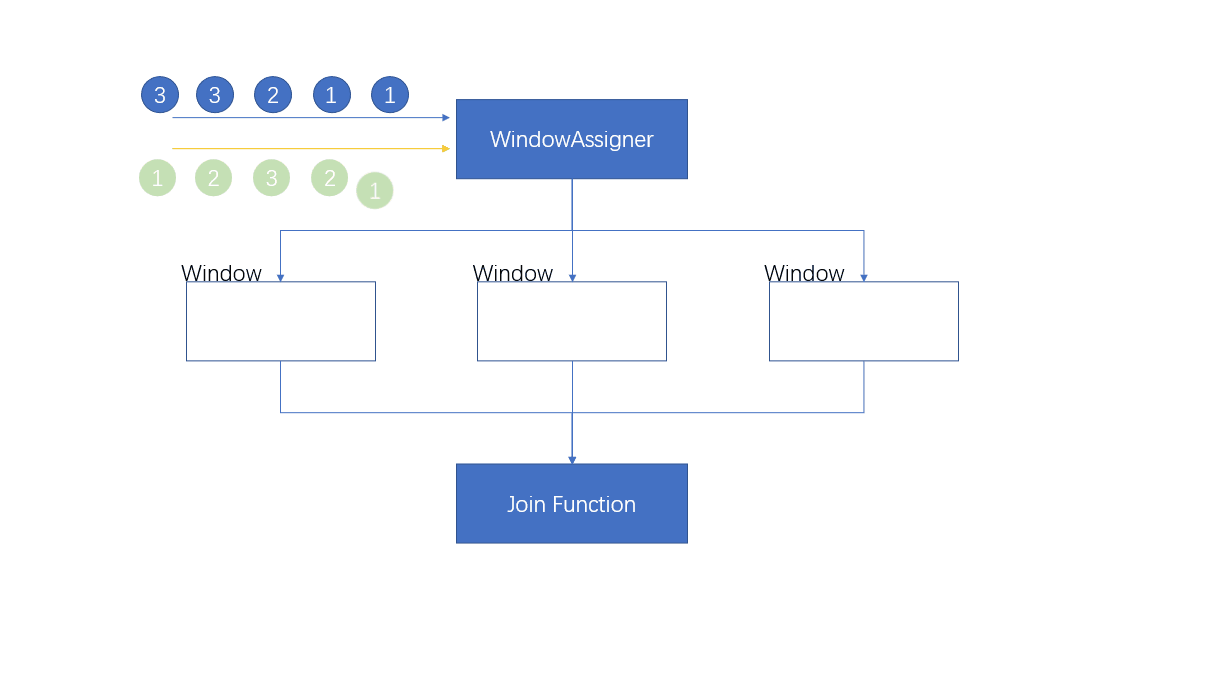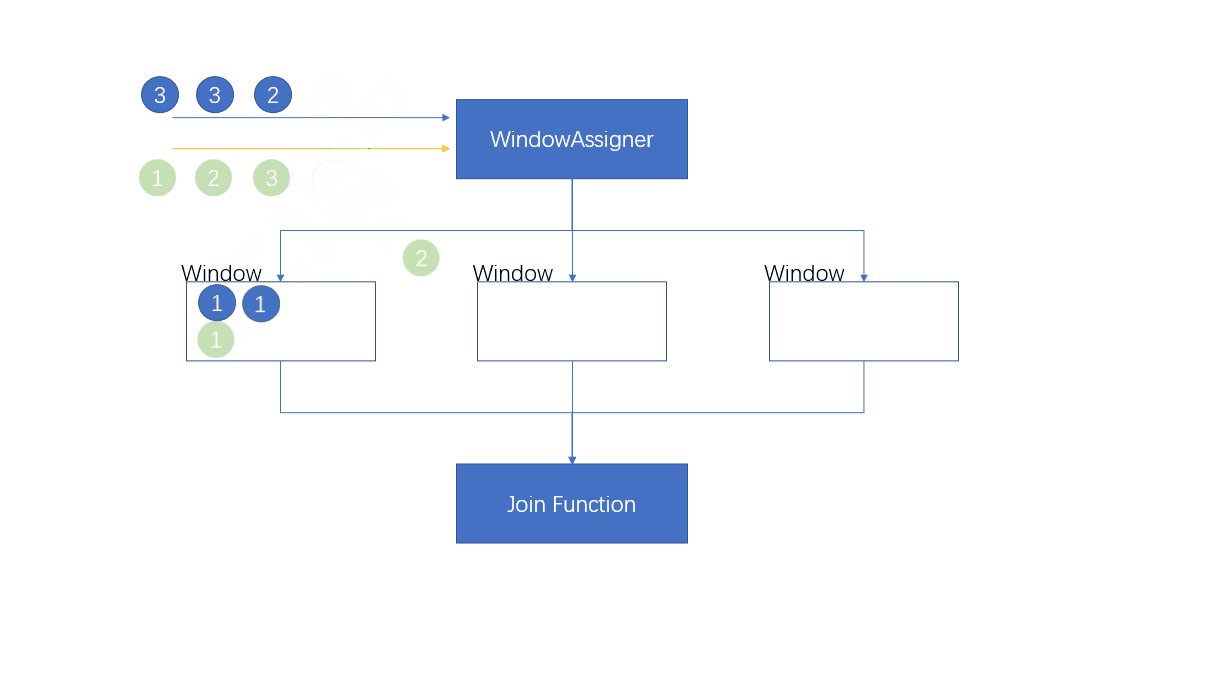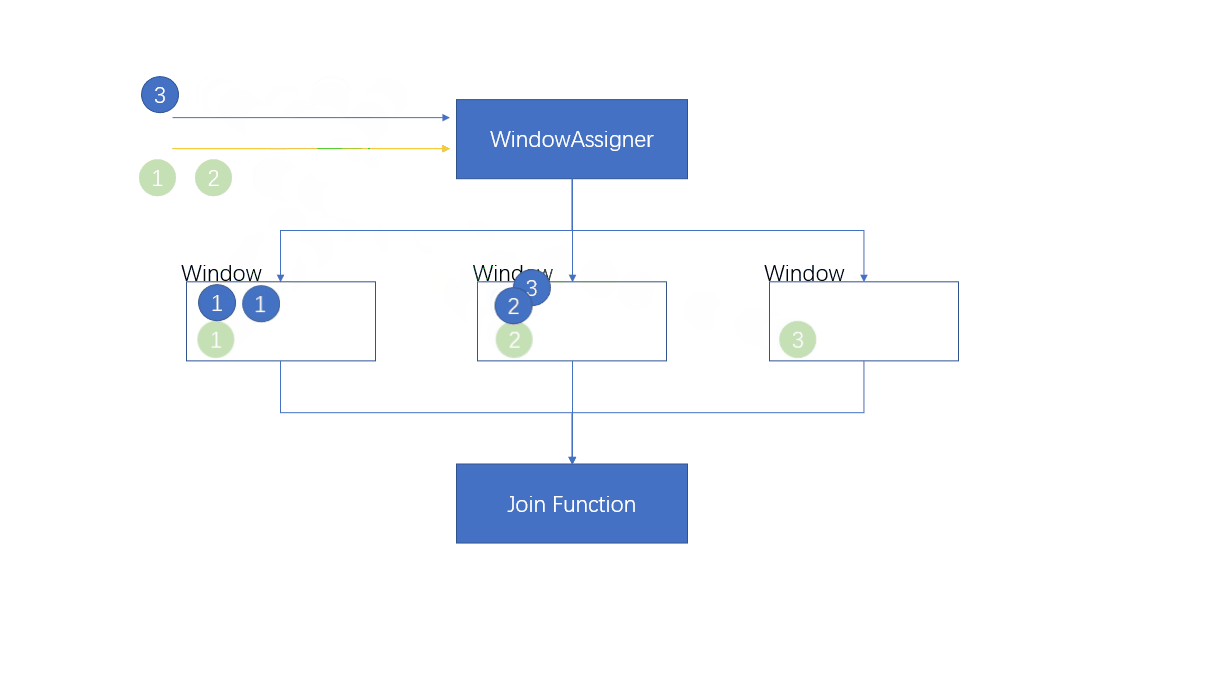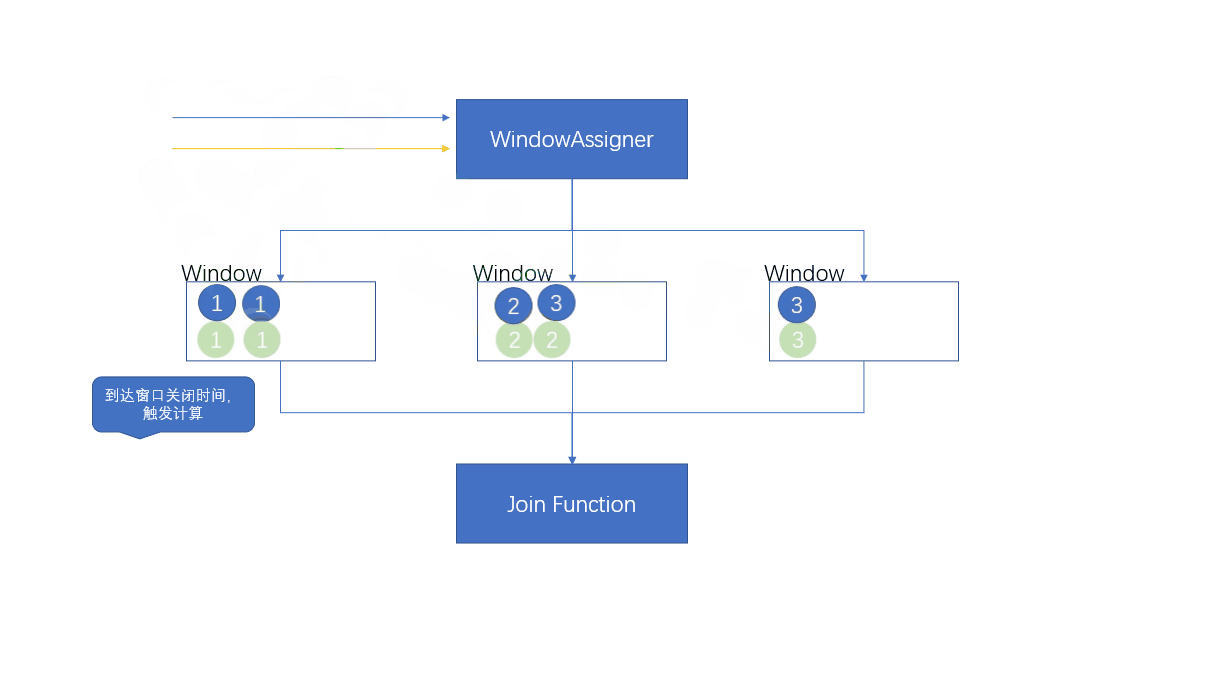
- 注意
当输出这个窗口的第一条元素到来的时候,才会创建窗口,当窗口关闭后,所属的窗口已经关闭,这是会不会新建一个窗口
会新建窗口,即使之前所属的窗口已经关闭。
如果key不唯一,会存在大量相同的key进入到一个窗口中,我们在前面看到窗口关闭触发计算的时候,本质上是循环遍历两个流的元素
时间复杂度为O(n^2),所以在实际解决问题中,需要避免这种情况,保证key的唯一
当窗口中元素只有一条流的元素,没有匹配到另一条流的元素,此时不会调用JoinFunction
- 在窗口apply方法中

除了joinFunction,还有一个flatJoinfunction
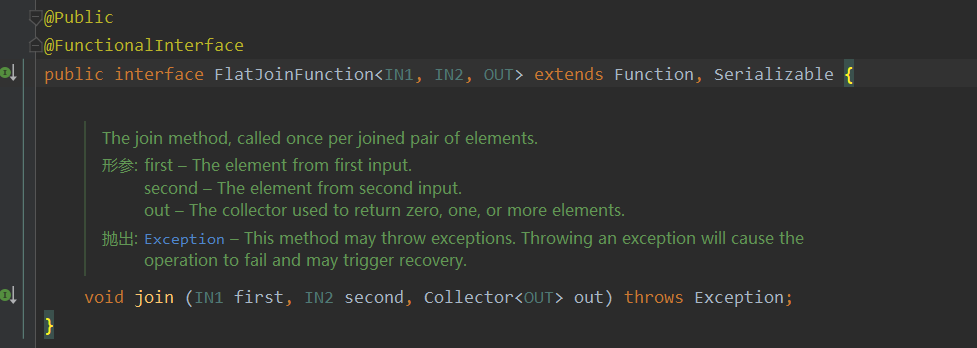
- 不同点
joinFunction,匹配一队只会输出一次,flatjoinFunction可以自定义输出零次或者多次。因为它是通过收集器向下游输出的
1.4.4.2 总结
这种方式类似于Hive中的
SELECT * FROM table1 t1, table2 t2 WHERE t1.id = t2.id;
本质上是内连接,不过有点区别的是,在窗口内的数据是这样的,如果元素数据不同的窗口,元素也匹配不上
1.4.2 间隔联结(Interval Join)
- 描述
从上面我们可以看到,尽管两个流的元素拥有相同的key,但是由于来到的时间不同,早来的元素所属的窗口已经关闭,另一个元素来的时候会创建新的窗口。在某些情况下,我们需要这两个元素匹配上,再用窗口这种方式就不太合适了。
针对上述需求,interval join可以完美解决。针对一条流上每个元素,开辟出其时间戳前后的一段间隔时间,看看这段时间有没有数据匹配。
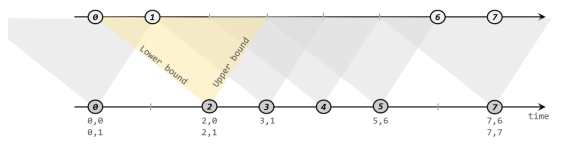
- 原理
在一条流的元素,定义一个 上界(upperBound)和 下界(lowerBound),也就是匹配这个元素,之前多长时间的元素,下界就是匹配这个元素之后多久的数据。包含上界和下界。
针对一个元素 a,所属的时间戳是t,那么它会匹配另一条流 [ t + lowerBound , t + upperBound ]
还有一个注意点,是另一条流对应key相同的这段时间的数据会匹配上
1.4.2.1 使用
间隔联结是基于KeyedStream的联结操作,调用方式如下
stream1
.keyBy(<KeySelector>)
.intervalJoin(stream2.keyBy(<KeySelector>))
.between(Time.milliseconds(-2), Time.milliseconds(1))
.process (new ProcessJoinFunction<Integer, Integer, String(){
@Override
public void processElement(Integer left, Integer right, Context ctx,
Collector<String> out) {
out.collect(left + "," + right);
}
});
- 注意
这里只匹配一次,只要能匹配上数据就输出
1.4.2.2 测试
1、主流join侧流相同时间段的多个侧流
ctx.collectWithTimestamp(Tuple2.of(1, "主流1"), 1000L);
ctx.collectWithTimestamp(Tuple2.of(1, "侧流1"), 1000L);
ctx.collectWithTimestamp(Tuple2.of(1, "侧流1"), 1500L);
ctx.collectWithTimestamp(Tuple2.of(1, "侧流1"), 2000L);
只要能匹配上就输出,a的范围是[0,3000L]
2、主流存在相同区域的两个元素,去join一个元素
ctx.collectWithTimestamp(Tuple2.of(1, "主流1"), 1000L);
ctx.collectWithTimestamp(Tuple2.of(1, "主流2"), 2000L);
ctx.collectWithTimestamp(Tuple2.of(1, "侧流1"), 1000L);
都会匹配上
3、主流存在相同区域的两个元素,去join多个元素
只要在主流每个元素的范围内都会匹配,说明会匹配重复的数据
1.4.2.3 底层实现原理

将流中相同时间戳的元素放进去
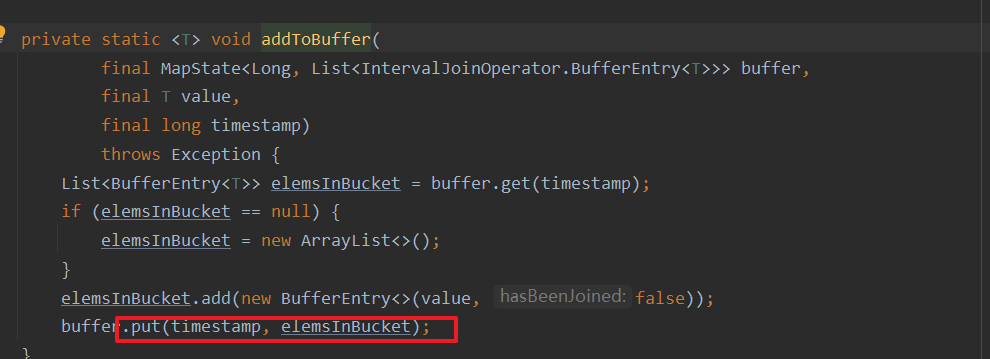
buffler本质是mapstate。如果这个时间戳的value,也就是list是空的时候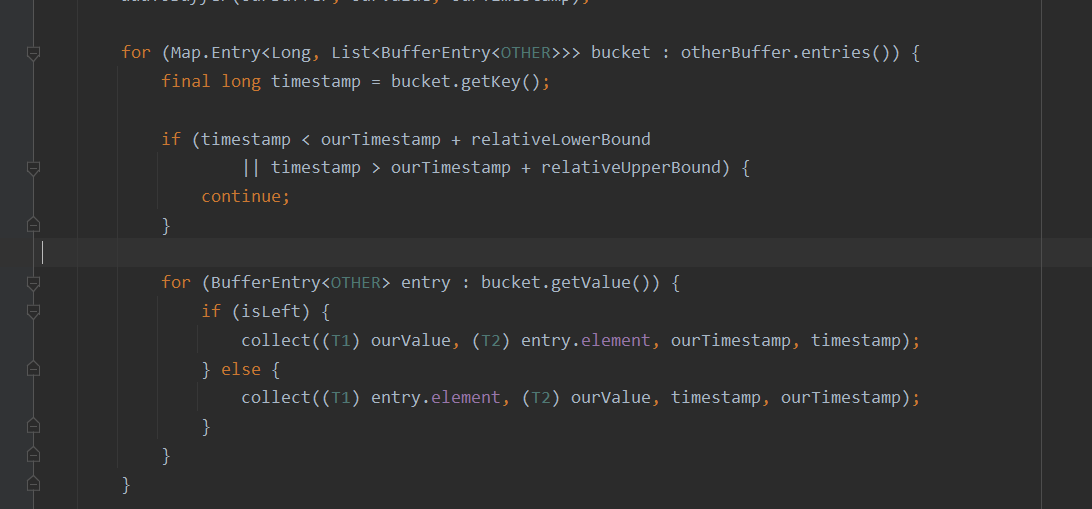
如果是
1、先keyby
2、在connect
3、定义两个mapstate,一个叫做leftbuffer、一个叫做rightBuffer
4、对两个元素的处理使用的同一个方法
主流

侧流
调用同一个方法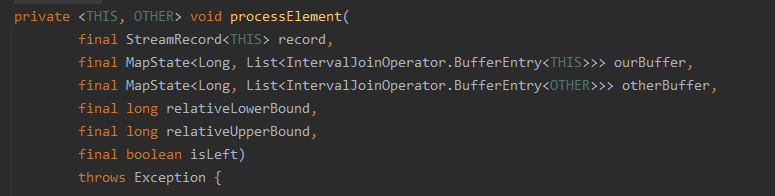
final THIS ourValue = record.getValue();
final long ourTimestamp = record.getTimestamp();
if (ourTimestamp == Long.MIN_VALUE) {
throw new FlinkException(
"Long.MIN_VALUE timestamp: Elements used in "
+ "interval stream joins need to have timestamps meaningful timestamps.");
}
if (isLate(ourTimestamp)) {
return;
}
addToBuffer(ourBuffer, ourValue, ourTimestamp);
for (Map.Entry<Long, List<BufferEntry<OTHER>>> bucket : otherBuffer.entries()) {
final long timestamp = bucket.getKey();
if (timestamp < ourTimestamp + relativeLowerBound
|| timestamp > ourTimestamp + relativeUpperBound) {
continue;
}
for (BufferEntry<OTHER> entry : bucket.getValue()) {
if (isLeft) {
collect((T1) ourValue, (T2) entry.element, ourTimestamp, timestamp);
} else {
collect((T1) entry.element, (T2) ourValue, timestamp, ourTimestamp);
}
}
}
long cleanupTime =
(relativeUpperBound > 0L) ? ourTimestamp + relativeUpperBound : ourTimestamp;
if (isLeft) {
internalTimerService.registerEventTimeTimer(CLEANUP_NAMESPACE_LEFT, cleanupTime);
} else {
internalTimerService.registerEventTimeTimer(CLEANUP_NAMESPACE_RIGHT, cleanupTime);
}
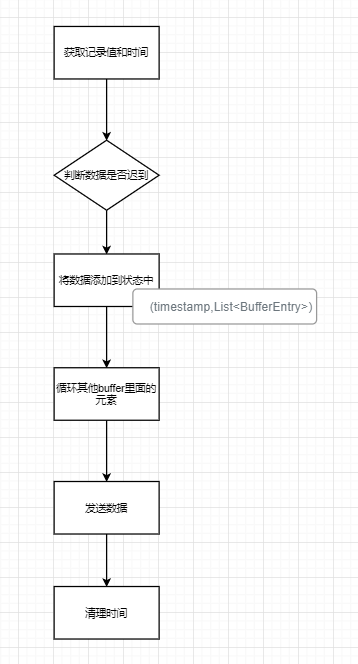
双向匹配的过程。
本质是,keyby + connet +mapstate<long,List> 一个时间戳的的所有数据

牛皮
1.4.3 窗口同组联结(Window CoGroup)
使用
strea1.coGroup(stream2)
.where(<keySelector>)
.equalTo(<KeySelector>)
.window(TumblingEventTimeWindows.of(Time.hours(1)))
.apply(<CoGroupFunction)
与join的区别
apply方法中用到的是CoGroupFunction
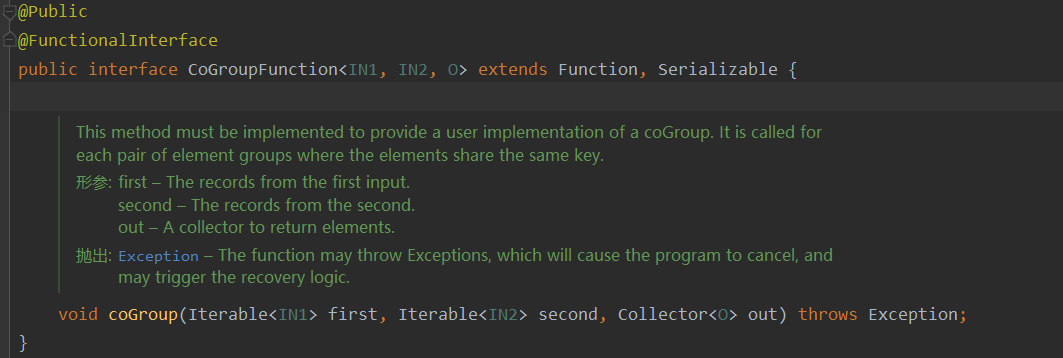
- 作用
把收集到的数据一次性传入,并且只调用一次CoGroupFunction,具体怎么调用由自己决定
即使一条流没有元素,另一条流也可以完成匹配。
总结
边栏推荐
- About the problem of APP flash back after appium starts the app - (solved)
- [Presto profile series] timeline use
- MongoDB的导入导出、备份恢复总结
- High end for 8 years, how is Yadi now?
- About how appium closes apps (resolved)
- Per capita Swiss number series, Swiss number 4 generation JS reverse analysis
- 10 张图打开 CPU 缓存一致性的大门
- Smart cloud health listed: with a market value of HK $15billion, SIG Jingwei and Jingxin fund are shareholders
- 【Presto Profile系列】Timeline使用
- Differences between MySQL storage engine MyISAM and InnoDB
猜你喜欢

Lingyunguang of Dachen and Xiaomi investment is listed: the market value is 15.3 billion, and the machine is implanted into the eyes and brain
Differences between MySQL storage engine MyISAM and InnoDB
LED light of single chip microcomputer learning notes

将数学公式在el-table里面展示出来

Practical example of propeller easydl: automatic scratch recognition of industrial parts
![[dark horse morning post] Huawei refutes rumors about](/img/d7/4671b5a74317a8f87ffd36be2b34e1.jpg)
[dark horse morning post] Huawei refutes rumors about "military master" Chen Chunhua; Hengchi 5 has a pre-sale price of 179000 yuan; Jay Chou's new album MV has played more than 100 million in 3 hours

PAcP learning note 1: programming with pcap
![[Presto profile series] timeline use](/img/c6/83c4fdc5f001dab34ecf18c022d710.png)
[Presto profile series] timeline use
High end for 8 years, how is Yadi now?
cmake 学习使用笔记(一)
随机推荐
飞桨EasyDL实操范例:工业零件划痕自动识别
线程池拒绝策略最佳实践
Ikvm of toolbox Net project new progress
JNA learning notes 1: Concepts
Mongodb slice summary
我那“不好惹”的00后下属:不差钱,怼领导,抵制加班
Day26 IP query items
JS function 返回多个值
How to make the new window opened by electorn on the window taskbar
日本政企员工喝醉丢失46万信息U盘,公开道歉又透露密码规则
Write it down once Net a new energy system thread surge analysis
Analysis of DHCP dynamic host setting protocol
MongoDB的导入导出、备份恢复总结
ORACLE进阶(五)SCHEMA解惑
TPG x AIDU|AI领军人才招募计划进行中!
Differences between MySQL storage engine MyISAM and InnoDB
User management summary of mongodb
学习突围2 - 关于高效学习的方法
ESP32系列专栏
High end for 8 years, how is Yadi now?