当前位置:网站首页>RealBasicVSR测试图片、视频
RealBasicVSR测试图片、视频
2022-07-07 11:18:00 【cv-daily】
代码:https://github.com/ckkelvinchan/RealBasicVSR
RealBasicVSR测试图片和是视频总是报out of memory,显存不够,但是又需要测试,修改代码。
存在的问题:一次测试两张1080p的图,报显存不够。一张1080p的图片报错
Traceback (most recent call last):
File "inference_realbasicvsr.py", line 167, in <module>
main()
File "inference_realbasicvsr.py", line 134, in main
outputs = model(inputs, test_mode=True)['output'].cpu()
File "anaconda3/envs/realbasicvsr/lib/python3.8/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "anaconda3/envs/realbasicvsr/lib/python3.8/site-packages/mmcv/runner/fp16_utils.py", line 116, in new_func
return old_func(*args, **kwargs)
File "anaconda3/envs/realbasicvsr/lib/python3.8/site-packages/mmedit/models/restorers/srgan.py", line 95, in forward
return self.forward_test(lq, gt, **kwargs)
File "anaconda3/envs/realbasicvsr/lib/python3.8/site-packages/mmedit/models/restorers/real_esrgan.py", line 212, in forward_test
output = _model(lq)
File "anaconda3/envs/realbasicvsr/lib/python3.8/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "anaconda3/envs/realbasicvsr/lib/python3.8/site-packages/mmedit/models/backbones/sr_backbones/real_basicvsr_net.py", line 87, in forward
outputs = self.basicvsr(lqs)
File "anaconda3/envs/realbasicvsr/lib/python3.8/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "anaconda3/envs/realbasicvsr/lib/python3.8/site-packages/mmedit/models/backbones/sr_backbones/basicvsr_net.py", line 126, in forward
flows_forward, flows_backward = self.compute_flow(lrs)
File "anaconda3/envs/realbasicvsr/lib/python3.8/site-packages/mmedit/models/backbones/sr_backbones/basicvsr_net.py", line 98, in compute_flow
flows_backward = self.spynet(lrs_1, lrs_2).view(n, t - 1, 2, h, w)
File "anaconda3/envs/realbasicvsr/lib/python3.8/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "anaconda3/envs/realbasicvsr/lib/python3.8/site-packages/mmedit/models/backbones/sr_backbones/basicvsr_net.py", line 346, in forward
input=self.compute_flow(ref, supp),
File "anaconda3/envs/realbasicvsr/lib/python3.8/site-packages/mmedit/models/backbones/sr_backbones/basicvsr_net.py", line 281, in compute_flow
F.avg_pool2d(
RuntimeError: non-empty 3D or 4D input tensor expected but got ndim: 4
问题:
anaconda3/envs/realbasicvsr/lib/python3.8/site-packages/mmedit/models/backbones/sr_backbones/basicvsr_net.py里边要求最少得两张图。修改代码
def compute_flow(self, lrs):
"""Compute optical flow using SPyNet for feature warping. Note that if the input is an mirror-extended sequence, 'flows_forward' is not needed, since it is equal to 'flows_backward.flip(1)'. Args: lrs (tensor): Input LR images with shape (n, t, c, h, w) Return: tuple(Tensor): Optical flow. 'flows_forward' corresponds to the flows used for forward-time propagation (current to previous). 'flows_backward' corresponds to the flows used for backward-time propagation (current to next). """
n, t, c, h, w = lrs.size()
if t==1:
lrs_1 = lrs[:, 0, :, :, :].reshape(-1, c, h, w)
lrs_2 = lrs[:, 0, :, :, :].reshape(-1, c, h, w)
flows_backward = self.spynet(lrs_1, lrs_2).view(n, 1, 2, h, w)
if self.is_mirror_extended: # flows_forward = flows_backward.flip(1)
flows_forward = None
else:
flows_forward = self.spynet(lrs_2, lrs_1).view(n, 1, 2, h, w)
else:
lrs_1 = lrs[:, :-1, :, :, :].reshape(-1, c, h, w)
lrs_2 = lrs[:, 1:, :, :, :].reshape(-1, c, h, w)
flows_backward = self.spynet(lrs_1, lrs_2).view(n, t - 1, 2, h, w)
if self.is_mirror_extended: # flows_forward = flows_backward.flip(1)
flows_forward = None
else:
flows_forward = self.spynet(lrs_2, lrs_1).view(n, t - 1, 2, h, w)
return flows_forward, flows_backward
修改inference_realbasicvsr.py
import argparse
import glob
import os
import cv2
import mmcv
import numpy as np
import torch
from mmcv.runner import load_checkpoint
from mmedit.core import tensor2img
from realbasicvsr.models.builder import build_model
VIDEO_EXTENSIONS = ('.mp4', '.mov')
def parse_args():
parser = argparse.ArgumentParser(
description='Inference script of RealBasicVSR')
parser.add_argument('config', help='test config file path')
parser.add_argument('checkpoint', help='checkpoint file')
parser.add_argument('input_dir', help='directory of the input video')
parser.add_argument('output_dir', help='directory of the output video')
parser.add_argument(
'--max_seq_len',
type=int,
default=None,
help='maximum sequence length to be processed')
parser.add_argument(
'--is_save_as_png',
type=bool,
default=True,
help='whether to save as png')
parser.add_argument(
'--fps', type=float, default=25, help='FPS of the output video')
args = parser.parse_args()
return args
def init_model(config, checkpoint=None):
"""Initialize a model from config file. Args: config (str or :obj:`mmcv.Config`): Config file path or the config object. checkpoint (str, optional): Checkpoint path. If left as None, the model will not load any weights. device (str): Which device the model will deploy. Default: 'cuda:0'. Returns: nn.Module: The constructed model. """
if isinstance(config, str):
config = mmcv.Config.fromfile(config)
elif not isinstance(config, mmcv.Config):
raise TypeError('config must be a filename or Config object, '
f'but got {
type(config)}')
config.model.pretrained = None
config.test_cfg.metrics = None
model = build_model(config.model, test_cfg=config.test_cfg)
if checkpoint is not None:
checkpoint = load_checkpoint(model, checkpoint)
model.cfg = config # save the config in the model for convenience
model.eval()
return model
def main():
args = parse_args()
# initialize the model
model = init_model(args.config, args.checkpoint)
# read images
file_extension = os.path.splitext(args.input_dir)[1]
if file_extension in VIDEO_EXTENSIONS: # input is a video file
print("11111")
video_reader = mmcv.VideoReader(args.input_dir)
inputs = []
i=0
for frame in video_reader:
if i==0 or i==1:
inputs.append(np.flip(frame, axis=2))
i=i+1
elif file_extension == '': # input is a directory
print("22222")
input_paths = sorted(glob.glob(f'{
args.input_dir}/*'))
index_img=0
for input_path in input_paths:
inputs = []
torch.cuda.empty_cache()
img = mmcv.imread(input_path, channel_order='rgb')
inputs.append(img)
for i, img in enumerate(inputs):
img = torch.from_numpy(img / 255.).permute(2, 0, 1).float()
inputs[i] = img.unsqueeze(0)
inputs = torch.stack(inputs, dim=1)
# inputs=torch.unsqueeze(inputs, 1)
print("inputs", inputs.shape)
# map to cuda, if available
cuda_flag = False
if torch.cuda.is_available():
model = model.cuda()
cuda_flag = True
with torch.no_grad():
if isinstance(args.max_seq_len, int):
outputs = []
for i in range(0, inputs.size(1), args.max_seq_len):
imgs = inputs[:, i:i + args.max_seq_len, :, :, :]
if cuda_flag:
imgs = imgs.cuda()
outputs.append(model(imgs, test_mode=True)['output'].cpu())
outputs = torch.cat(outputs, dim=1)
else:
if cuda_flag:
inputs = inputs.cuda()
outputs = model(inputs, test_mode=True)['output'].cpu()
if os.path.splitext(args.output_dir)[1] in VIDEO_EXTENSIONS:
output_dir = os.path.dirname(args.output_dir)
mmcv.mkdir_or_exist(output_dir)
h, w = outputs.shape[-2:]
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
video_writer = cv2.VideoWriter(args.output_dir, fourcc, args.fps,
(w, h))
for i in range(0, outputs.size(1)):
img = tensor2img(outputs[:, i, :, :, :])
video_writer.write(img.astype(np.uint8))
cv2.destroyAllWindows()
video_writer.release()
else:
mmcv.mkdir_or_exist(args.output_dir)
for i in range(0, outputs.size(1)):
output = tensor2img(outputs[:, i, :, :, :])
# filename = os.path.basename(input_paths[i])
filename = os.path.basename(input_paths[index_img])
print("filename", filename)
if args.is_save_as_png:
file_extension = os.path.splitext(filename)[1]
filename = filename.replace(file_extension, '.png')
mmcv.imwrite(output, f'{
args.output_dir}/{
filename}')
index_img=index_img+1
else:
print("33333")
raise ValueError('"input_dir" can only be a video or a directory.')
if __name__ == '__main__':
main()
边栏推荐
- How does MySQL create, delete, and view indexes?
- MySQL master-slave replication
- DHCP 动态主机设置协议 分析
- “新红旗杯”桌面应用创意大赛2022
- Unity build error: the name "editorutility" does not exist in the current context
- php——laravel缓存cache
- HZOJ #236. Recursive implementation of combinatorial enumeration
- 学习突围2 - 关于高效学习的方法
- [untitled]
- Cmu15445 (fall 2019) project 2 - hash table details
猜你喜欢

关于 appium 启动 app 后闪退的问题 - (已解决)

共创软硬件协同生态:Graphcore IPU与百度飞桨的“联合提交”亮相MLPerf
通过Keil如何查看MCU的RAM与ROM使用情况
Leetcode skimming: binary tree 22 (minimum absolute difference of binary search tree)
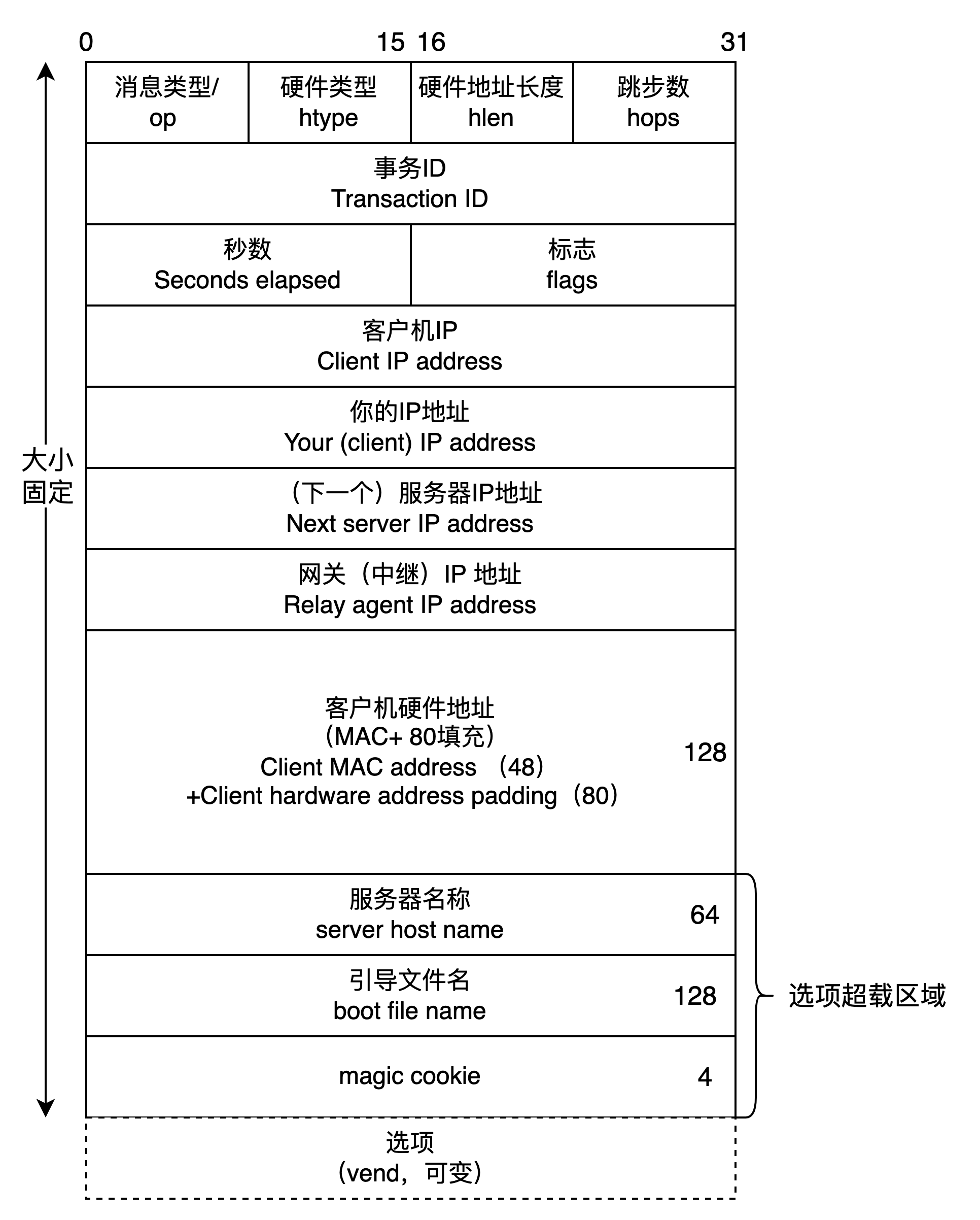
DHCP 动态主机设置协议 分析
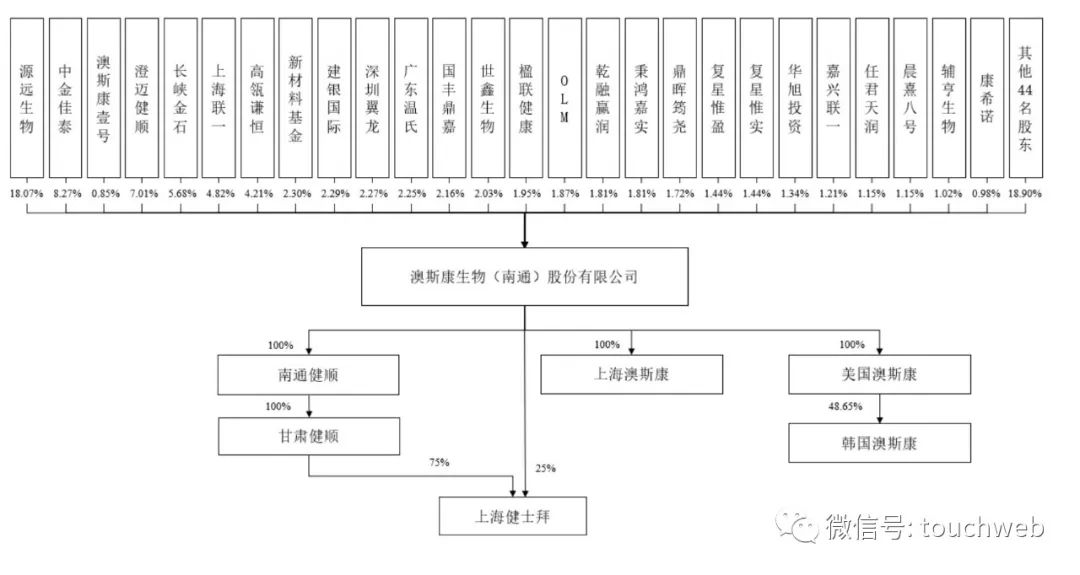
Aosikang biological sprint scientific innovation board of Hillhouse Investment: annual revenue of 450million yuan, lost cooperation with kangxinuo
AUTOCAD——大于180度的角度标注、CAD直径符号怎么输入?
Go语言学习笔记-结构体(Struct)
线程池拒绝策略最佳实践
About how appium closes apps (resolved)
随机推荐
Common text processing tools
Per capita Swiss number series, Swiss number 4 generation JS reverse analysis
How does MySQL create, delete, and view indexes?
《开源圆桌派》第十一期“冰与火之歌”——如何平衡开源与安全间的天然矛盾?
DETR介绍
共创软硬件协同生态:Graphcore IPU与百度飞桨的“联合提交”亮相MLPerf
如何让electorn打开的新窗口在window任务栏上面
事务的七种传播行为
Cmu15445 (fall 2019) project 2 - hash table details
About how appium closes apps (resolved)
Conversion from non partitioned table to partitioned table and precautions
MATLAB中polarscatter函数使用
非分区表转换成分区表以及注意事项
Cookie and session comparison
【学习笔记】AGC010
线程池拒绝策略最佳实践
Practical example of propeller easydl: automatic scratch recognition of industrial parts
Unity 构建错误:当前上下文中不存在名称“EditorUtility”
【学习笔记】线段树选做
人均瑞数系列,瑞数 4 代 JS 逆向分析