当前位置:网站首页>Scripy tutorial classic practice [New Concept English]
Scripy tutorial classic practice [New Concept English]
2022-07-07 13:11:00 【Ali's love letter】
Scrapy Tutorial classic actual combat 【 New concept English 】
Preface
This tutorial aims to teach everyone who wants to learn about reptiles , Learning can also exercise your habit of reading documents .
In this tutorial , We assume that... Is already installed on your system Scrapy. If this is not the case , Please refer to the following environment configuration in this section .
We're going to grab http://www.yytingli.com/category/xgnyy/nce-1, This is a new concept English self-study website .
This tutorial will guide you through the following tasks :
Create a new Scrapy project
To write Reptiles Crawl websites and extract data
Use the command line to export the captured data
Change the spider to recursively track links
Use spider parameters
Please develop in strict accordance with the requirements , To avoid mistakes in development .
Development platform :windows
IDE:PyCharm 2021.3.2 (Professional Edition)
Language version :Python==3.9
Framework version :Scrapy==2.6.1
One 、 Introduction to web crawler
With the rapid development of Internet , More and more information is published on the Internet . This information is embedded in each
Among various website structures and styles , Although search engines can help people find these information , But it also has its
limitations . The goal of a general search engine is to cover the whole network as much as possible , It cannot be targeted at specific purposes and needs
Indexes . In the face of today's increasingly complex structure , And more and more information intensive data , General search engines can't deal with
It makes effective discovery and acquisition . Under the influence of such environment and demand , Web crawlers emerge as the times require , It is interconnected
The application of Web data provides a new method .
Two 、Scrapy The framework is introduced
Scrapy is a fast high-level web crawling and web scraping framework, used to crawl websites and extract structured data from their pages. It can be used for a wide range of purposes, from data mining to monitoring and automated testing.
According to the website :
Scrapy Is a fast advanced web crawl and web crawler framework , For grabbing websites and extracting structured data from their pages . It can be used for a wide range of purposes , From data mining to monitoring and automated testing .
Scrapy Framework is the foundation Python Development , So not Python Look here :
https://www.runoob.com/python3/python3-tutorial.html
https://www.liaoxuefeng.com/wiki/1016959663602400
3、 ... and 、 Prepare the development environment
Four 、 establish Scrapy project
First, open the command line window , The output command :
scrapy startproject newconcept
There will be created files in the current directory , The tree structure of the folder is as follows :
newconcept
│ items.py
│ middlewares.py
│ pipelines.py
│ settings.py
│ __init__.py
│
├─spiders
│ │
│ │ __init__.py
│ │
│ └─__pycache__
│ myspider.cpython-39.pyc
│ __init__.cpython-39.pyc
│
└─__pycache__
items.cpython-39.pyc
settings.cpython-39.pyc
__init__.cpython-39.pyc
Be careful ,__pycache__ File is pycharm Automatically generated , Never mind .
5、 ... and 、 Create the first spider
scrapy genspider myspider www.yytingli.com
After running , Found in the project folder spider A... Will be generated in the folder myspider.py file .
It looks something like this :
import scrapy
class MyspiderSpider(scrapy.Spider):
name = 'myspider'
allowed_domains = ['www.yytingli.com']
start_urls = ['http://www.yytingli.com']
def parse(self, response):
pass
All we have to do is pass Get rid of it and write our logic code ,parse Function receives a response Parameters , This parameter is the corresponding network request , We only need to care about how to deal with the response data .
6、 ... and 、 Web analytics
Web page analysis is divided into two parts :
1. Analyze the list page , Get the details page url.
2. Analysis details page , Crawl the data of each part .
We use Chrome The browser opens the new concept self-study website ,F12 Open developer tools , And press ctrl+shift+c Check page elements , Click on the title .
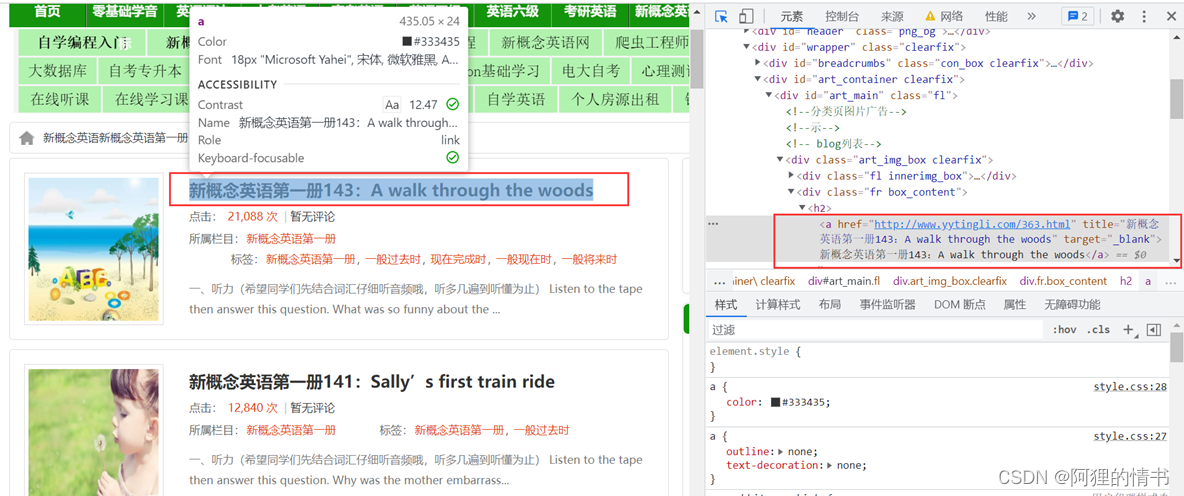
Pictured above , You can see the page elements on the right a In the tag href The attribute is the link address of the details page .
There are many ways to locate web elements , have access to bs4 In the library find Method ,select Method . It can be used xpath, It can be used pyquery , Direct use javascript operation dom Elements , You can also use the standard library directly re, Regular expressions to extract .
Here we use xpath Statement locates and parses elements .
The specific methods of element positioning and parsing web pages are not the focus of this tutorial , Here you can refer to :
Here is a little assignment for you , According to the above methods, analyze the structure of the detail page , And write code , The website is :http://www.yytingli.com/17.html, There are only two information we extract , The English text and translation content of the article .
7、 ... and 、 List page debugging
First you need to modify settings.py Configuration parameters in the file
find DEFAULT_REQUEST_HEADERS and ROBOTSTXT_OBEY Parameters , Changed to the following :
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9, */*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/96.0.4664.93 Safari/537.36',
}
ROBOTSTXT_OBEY = False
Scrapy Provide a shell Command line debugging method , We can use the following command to enter debugging :
scrapy shell http://www.yytingli.com/category/xgnyy/nce-1
After analyzing the web page , We use the test code we have written :
for i in response.xpath('// *[@id="art_main"]/div/div[2]/h2/a'):
title = i.xpath('@title').get()
link = i.xpath('@href').get()
print(title,link)
The test results are as follows :
In [8]: for i in response.xpath('// *[@id="art_main"]/div/div[2]/h2/a'):
...: title = i.xpath('@title').get()
...: link = i.xpath('@href').get()
...: print(title,link)
...:
New concept English volume 1 143:A walk through the woods http://www.yytingli.com/363.html
New concept English volume 1 141:Sally’s first train ride http://www.yytingli.com/360.html
New concept English volume 1 139:Is that you, John? http://www.yytingli.com/357.html
New concept English volume 1 137:A pleasant dream http://www.yytingli.com/354.html
New concept English volume 1 135:The latest report http://www.yytingli.com/351.html
New concept English volume 1 133:Sensational news http://www.yytingli.com/348.html
New concept English volume 1 131:Don’t be so sure http://www.yytingli.com/345.html
New concept English volume 1 129:70 miles an hour http://www.yytingli.com/342.html
New concept English volume 1 127:A famous actress http://www.yytingli.com/339.html
New concept English volume 1 125:Tea for two http://www.yytingli.com/336.html
New concept English volume 1 123:A trip to Australia http://www.yytingli.com/333.html
New concept English volume 1 121:The man in the hat http://www.yytingli.com/330.html
New concept English volume 1 119:A true story http://www.yytingli.com/327.html
New concept English volume 1 117:Tommy’s breakfast http://www.yytingli.com/323.html
New concept English volume 1 115:Knock, knock! http://www.yytingli.com/320.html
New concept English volume 1 113:small change http://www.yytingli.com/317.html
New concept English volume 1 111:The most expensive model http://www.yytingli.com/314.html
New concept English volume 1 109:A good idea http://www.yytingli.com/311.html
New concept English volume 1 107:It’s too small http://www.yytingli.com/308.html
New concept English volume 1 105:Hello, Mr.boss http://www.yytingli.com/305.html
above , We got the details page url And the title , Complete the test of the list page .
8、 ... and 、 Details page debugging
We can use the following command to enter debugging :
scrapy shell http://www.yytingli.com/31.html
After modification, enter debugging again , We use the test code we have written :
text = response.xpath('// *[@id="art_main1"]/div[2]/p[6]/text()').getall() # English text
translation = response.xpath('// *[@id="art_main1"]/div[2]/p[8]/text()').getall() # Article translation
We type in text View results , as follows :
In [2]: text
Out[2]:
['My coat and my umbrella please.',
'\nHere is my ticket.',
'\nThank you, sir.',
'\nNumber five.',
"\nHere's your umbrella and your coat.",
'\nThis is not my umbrella.',
'\nSorry sir.',
'\nIs this your umbrella?',
"\nNo, it isn't.",
'\nIs this it?',
'\nYes, it is.',
'\nThank you very much.']
We type in translation View results , as follows :
In [3]: translation
Out[3]:
[' Please bring me my coat and umbrella .',
'\n This is me ( Deposit things ) Brand .',
'\n thank you , sir .',
'\n yes 5 Number .',
'\n Here is your umbrella and coat ',
'\n This is not my umbrella .',
'\n I'm sorry , sir .',
'\n Is this umbrella yours ?',
'\n No , No !',
'\n Is this one ?',
'\n yes , It's this one .',
'\n Thank you very much .']
The above completes the debugging content of the details page .
Nine 、 Edit the entry file
After debugging , We have successfully obtained the data , You should write items.py file , Determine what we want to crawl .
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class NewconceptItem(scrapy.Item):
# List of pp.
title = scrapy.Field()
link = scrapy.Field()
# Details page
text = scrapy.Field()
translation = scrapy.Field()
Ten 、 Complete the crawler code
Now let's finish myspider.py file .
import scrapy
from newconcept.items import NewconceptItem
class MyspiderSpider(scrapy.Spider):
name = 'myspider'
allowed_domains = ['www.yytingli.com']
start_urls = ['http://www.yytingli.com/category/xgnyy/nce-1']
def parse(self, response):
for i in response.xpath('// *[@id="art_main"]/div/div[2]/h2/a'):
item = NewconceptItem()
title = i.xpath('@title').get()
link = i.xpath('@href').get()
item['link'] = link
item['title'] = title
yield scrapy.Request(url=link, meta={
'item': item}, callback=self.detail)
def detail(self, response):
item = response.meta['item']
text = response.xpath('// *[@id="art_main1"]/div[2]/p[6]/text()').getall()
translation = response.xpath('// *[@id="art_main1"]/div[2]/p[8]/text()').getall()
item['text'] = "".join(text).replace(' ', '').replace(':', '')
item['translation'] = "".join(translation).replace(' ', '').replace(':', '')
yield item
Switch to the project path and run with the command :
scrapy crawl myspider -o mydata.json
After the program is completed, a mydata.json file , Inside is what we want .
start_urls Class attribute is a list type , It determines what you just started crawling url list , Here we only use the first page of the list page for crawling demonstration , If you want to crawl all the pages , Please put start_urls Change the parameter as follows :
start_urls = ['http://www.yytingli.com/category/xgnyy/nce-1']+['http://www.yytingli.com/category/xgnyy/nce-1/page/%s'%i for i in range(2, 4)]
The contents of the file are as follows :
...
{
"link": "http://www.yytingli.com/348.html", "title": "\u65b0\u6982\u5ff5\u82f1\u8bed\u7b2c\u4e00\u518c133\uff1aSensational news", "text": "mink coat \u8c82\u76ae\u5927\u8863", "translation": "Reporter: Have you just made a new film, Miss Marsh?\nMiss Marsh: Yes, I have.\nReporter: Are you going to make another?\nMiss Marsh: No, I'm not. I'm going to retire. I feel very tired. I don't want to make another film for a long time."},
{
"link": "http://www.yytingli.com/354.html", "title": "\u65b0\u6982\u5ff5\u82f1\u8bed\u7b2c\u4e00\u518c137\uff1aA pleasant dream", "text": "JULIE: Are you doing the football pools, Brain?\nBRAIN: Yes, I've nearly finished, Julie. I'm sure we'll win something this week.\nJULIE: You always say that, but we never win anything! What will you do if you win a lot of money?\nBRAIN: If I win a lot of money I'll buy you a mink coat.\nJULIE: I don't want a mink coat! I want to see the world.\nBRAIN: All right. If we win a lot of money we'll travel round the world and we'll stay at the best hotels. Then we'll return home and buy a big house in the country. We'll have a beautiful garden and...\nJULIE: But if we spend all that money we'll be poor again. What'll we do then?\nBRAIN: If we spend all the money we'll try and win the football pools again.\nJULIE: It's a pleasant dream but everything depends on 'if'!", "translation": "\u6731 \u8389\u5e03\u83b1\u6069\uff0c\u4f60\u6b63\u5728\u4e0b\u8db3\u7403\u8d5b\u7684\u8d4c\u6ce8\u5417\uff1f\n\u5e03\u83b1\u6069\u662f\u7684\u3002\u6211\u8fd9\u5c31\u505a\u5b8c\u4e86\uff0c\u6731\u8389\u3002\u6211\u6562\u80af\u5b9a\u8fd9\u661f\u671f\u6211\u4eec\u4f1a\u8d62\u4e00\u70b9\u4ec0\u4e48\u7684\u3002\n\u6731 \u8389\u4f60\u8001\u662f\u90a3\u6837\u8bf4\uff0c\u4f46\u662f\u6211\u4eec\u4ece\u6765\u6ca1\u8d62\u8fc7\uff01\u8981\u662f\u4f60\u8d62\u4e86\u8bb8\u591a\u94b1\uff0c\u4f60\u6253\u7b97\u505a\u4ec0\u4e48\u5462\uff1f\n\u5e03\u83b1\u6069\u8981\u662f\u6211\u8d62\u4e86\u8bb8\u591a\u94b1\uff0c\u6211\u7ed9\u4f60\u4e70\u4ef6\u8c82\u76ae\u5927\u8863\u3002\n\u6731 \u8389\u6211\u4e0d\u8981\u8c82\u76ae\u5927\u8863\u3002\u6211\u8981\u53bb\u89c1\u89c1\u4e16\u9762\u3002\n\u5e03\u83b1\u6069\u597d\u5427\u3002\u8981\u662f\u6211\u4eec\u8d62\u4e86\u5f88\u591a\u94b1\uff0c\u6211\u4eec\u5c31\u53bb\u5468\u6e38\u4e16\u754c\uff0c\u5e76\u4e14\u4f4f\u6700\u597d\u7684\u65c5\u9986\u3002\u7136\u540e\u6211\u4eec\u8fd4\u56de\u5bb6\u56ed\uff0c\u5728\u4e61\u4e0b\u4e70\u5e62\u5927\u623f\u5b50\u3002\u6211\u4eec\u5c06\u6709\u4e00\u4e2a\u6f02\u4eae\u7684\u82b1\u56ed\u548c......"},
{
"link": "http://www.yytingli.com/357.html", "title": "\u65b0\u6982\u5ff5\u82f1\u8bed\u7b2c\u4e00\u518c139\uff1aIs that you, John?", "text": "GRAHAM TURNER: Is that you, John?\nJOHN SMITH: Yes, speaking.\nGRAHAM TURNER: Tell Mary we'll be late for dinner this evening.\nJOHN SMITH: I'm afraid I don't understand.\nGRAHAM TURNER: Hasn't Mary told you? She invited Charlotte and me to dinner this evening. I said I would be at your house at six o'clock, but the boss wants me to do some extra work. I'll have to stay at the office. I don't know when I'll finish. Oh, and by the way, my wife wants to know if Mary needs any help.\nJOHN SMITH: I don't know what you're talking about.\nGRAHAM TURNER: That is John Smith, isn't it?\nJOHN SMITH: Yes, I'm John Smith.\nGRAHAM TURNER: You are John Smith, the engineer, aren't you?\nJOHN SMITH: That's right.\nGRAHAM TURNER: You work for the Overseas Engineering Company, don't you?\nJOHN SMITH: No, I don't. I'm John Smith the telephone engineer and I'm repairing your telephone line.", "translation": "\u683c\u96f7\u5384\u59c6\u00b7\u7279\u7eb3\u662f\u4f60\u5417\uff0c\u7ea6\u7ff0\uff1f\n\u7ea6\u7ff0\u00b7\u53f2\u5bc6\u65af\u662f\u6211\uff0c\u8bf7\u8bb2\u3002\n\u683c\u96f7\u5384\u59c6\u00b7\u7279\u7eb3\u4f60\u544a\u8bc9\u739b\u4e3d\uff0c\u4eca\u665a\u5403\u996d\u6211\u4eec\u5c06\u665a\u5230\u4e00\u4f1a\u513f\u3002\n\u7ea6\u7ff0\u00b7\u53f2\u5bc6\u65af\u6050\u6015\u6211\u8fd8\u4e0d\u660e\u767d\u60a8\u7684\u610f\u601d\u3002\n\u683c\u96f7\u5384\u59c6\u00b7\u7279\u7eb3\u739b\u4e3d\u6ca1\u6709\u544a\u8bc9\u4f60\u5417\uff1f\u5979\u9080\u8bf7\u6211\u548c\u590f\u6d1b\u7279\u4eca\u665a\u53bb\u5403\u996d\u3002\u6211\u8bf4\u8fc7\u62116\u70b9\u5230\u4f60\u5bb6\uff0c\u4f46\u8001\u677f\u8981\u6211\u52a0\u73ed\u3002\u6211\u4e0d\u5f97\u4e0d\u7559\u5728\u529e\u516c\u5ba4\uff0c\u4e0d\u77e5\u9053\u4ec0\u4e48\u65f6\u5019\u624d\u80fd\u7ed3\u675f\u3002\u5594\uff0c\u987a\u4fbf\u95ee\u4e00\u53e5\uff0c\u6211\u59bb\u5b50\u60f3\u77e5\u9053\u739b\u4e3d\u662f\u5426\u9700\u8981\u5e2e\u5fd9\u3002\n\u7ea6\u7ff0\u00b7\u53f2\u5bc6\u65af\u6211\u4e0d\u77e5\u9053\u60a8\u5728\u8bf4\u4e9b\u4ec0\u4e48\u3002\n\u683c\u96f7\u5384\u59c6\u00b7\u7279\u7eb3\u4f60\u662f\u7ea6\u7ff0\u00b7\u53f2\u5bc6\u65af\uff0c\u5bf9\u5417\uff1f\n\u7ea6\u7ff0\u00b7\u53f2\u5bc6\u65af\u662f\u7684\uff0c\u6211\u662f\u7ea6\u7ff0\u00b7\u53f2\u5bc6\u65af\u3002\n\u683c\u96f7\u5384\u59c6\uff0c\u7279\u7eb3\u4f60\u662f\u5de5\u7a0b\u5e08\u7ea6\u7ff0\u00b7\u53f2\u5bc6\u65af\uff0c\u5bf9\u5417\uff1f\n\u7ea6\u7ff0\u00b7\u53f2\u5bc6\u65af\u5bf9\u3002\n\u683c\u96f7\u5384\u59c6\u00b7\u7279\u7eb3\u4f60\u5728\u6d77\u5916\u5de5\u7a0b\u516c\u53f8\u4e0a\u73ed\uff0c\u662f\u5417\uff1f\n\u7ea6\u7ff0\u00b7\u53f2\u5bc6\u65af\u4e0d\uff0c\u4e0d\u662f\u3002\u6211\u662f\u7535\u8bdd\u5de5\u7a0b\u5e08\u7ea6\u7ff0\u00b7\u53f2\u5bc6\u65af\uff0c\u6211\u6b63\u5728\u4fee\u7406\u60a8\u7684\u7535\u8bdd\u7ebf\u3002\n\n"},
Don't worry title Chinese display problem in , Use professional tools to read , perhaps python Read and display normally .
You can join QQ Group study and communicate with everyone , Here I will give you the answers to the problems in your study .
Click the link to join the group chat 【Python】:https://jq.qq.com/?_wv=1027&k=4fve4VeJ
边栏推荐
- TPG x AIDU|AI领军人才招募计划进行中!
- How to reset Firefox browser
- MySQL入门尝鲜
- JNA学习笔记一:概念
- .Net下極限生產力之efcore分錶分庫全自動化遷移CodeFirst
- Analysis of DHCP dynamic host setting protocol
- 人均瑞数系列,瑞数 4 代 JS 逆向分析
- 将数学公式在el-table里面展示出来
- Isprs2021/ remote sensing image cloud detection: a geographic information driven method and a new large-scale remote sensing cloud / snow detection data set
- 信号强度(RSSI)知识整理
猜你喜欢





![[Presto profile series] timeline use](/img/c6/83c4fdc5f001dab34ecf18c022d710.png)
随机推荐
【无标题】
leecode3. 无重复字符的最长子串
API query interface for free mobile phone number ownership
ORACLE进阶(五)SCHEMA解惑
JS判断一个对象是否为空
Unity 构建错误:当前上下文中不存在名称“EditorUtility”
Practical example of propeller easydl: automatic scratch recognition of industrial parts
【Presto Profile系列】Timeline使用
Cookie and session comparison
Day26 IP query items
MySQL master-slave replication
详细介绍六种开源协议(程序员须知)
解决缓存击穿问题
工具箱之 IKVM.NET 项目新进展
How to make the new window opened by electorn on the window taskbar
JNA学习笔记一:概念
事务的七种传播行为
Blog recommendation | Apache pulsar cross regional replication scheme selection practice
[Presto profile series] timeline use
Lingyunguang of Dachen and Xiaomi investment is listed: the market value is 15.3 billion, and the machine is implanted into the eyes and brain