当前位置:网站首页>DETR介绍
DETR介绍
2022-07-07 11:07:00 【算法之名】
DETR是facebook发表于ECCV2020的使用Transformers进行端到端的目标检测的框架。

DETR只需要使用CNN提取图像特征,再单独使用Transformer就可以预测出目标边界框和分类。它不需要非极大值抑制,也不需要Anchor机制。

上图是DETR的网络架构图,DETR使用CNN提取图像特征,再单独使用Transformer得到预测出目标边界框,边界框和ground truth看作是一个几何预测问题。就是一个二分的匹配(bipartite matching),没有匹配上的物体归位no object这一类。
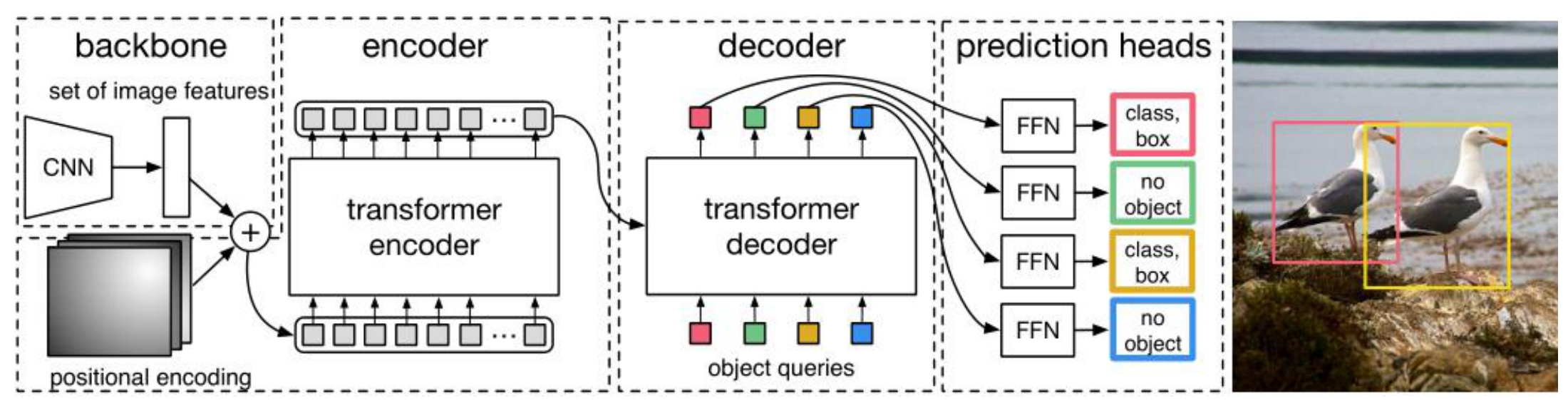
上图是更详细的描述DETR的网络结构,图像经过CNN获取到特征,再加上位置编码(poositioonal encoding),然后再展平送入到transformer encoder,encoder的输出再送入到transformer decoder,在decoder中还有object queries的输入,decoder的输出送入预测头(prediction heads),预测头中有前馈神经网络FFN进行物体类别和边界框的预测。
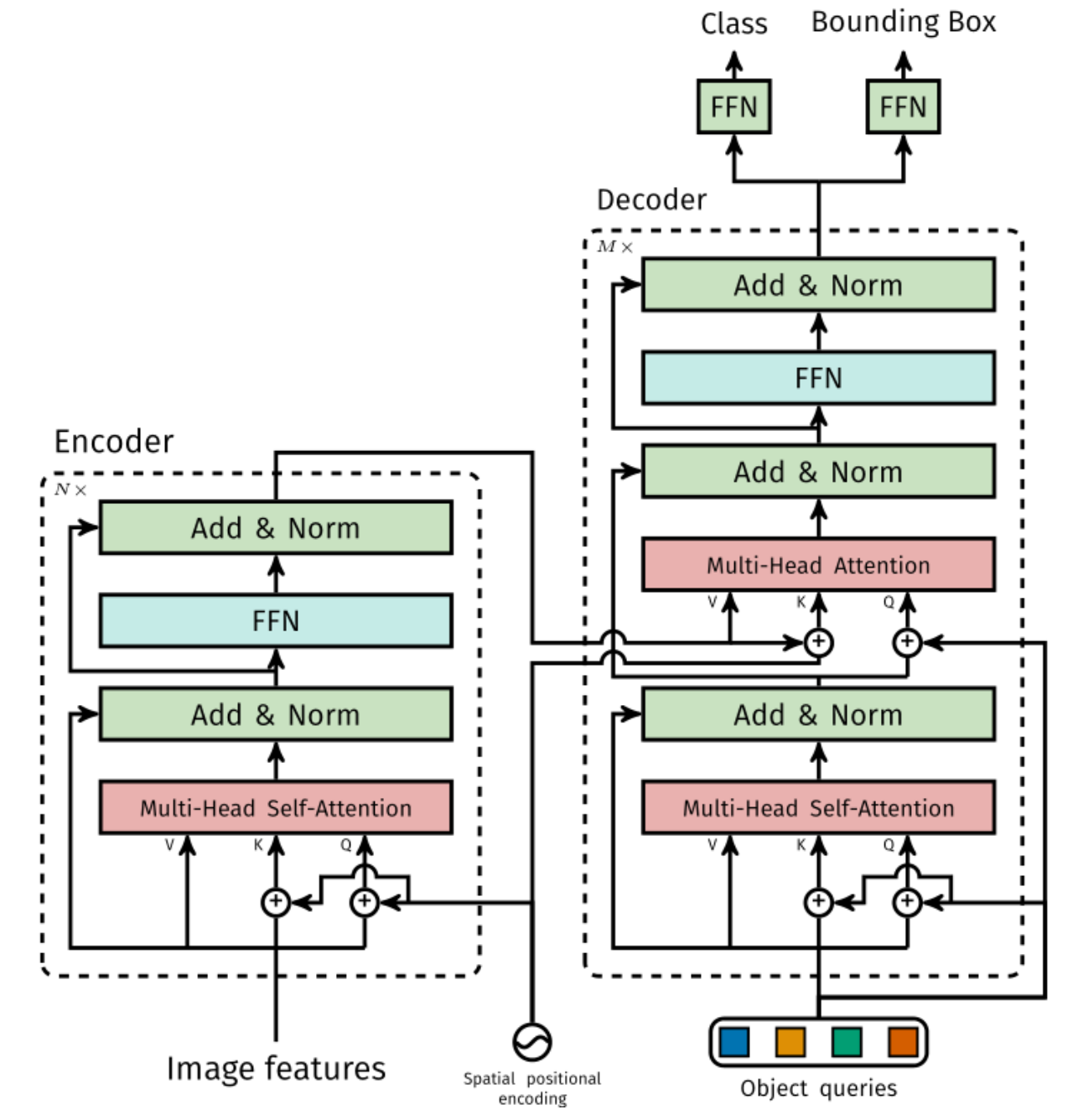
上图是DETR中Transformer具体的架构,它有Encoder和Decoder两部分,Encoder的输入就是CNN提取的图像特征加上位置编码,送入多头自注意力模块,再送入前馈神经网络模块。这样的Encoder层可以有多个,然后再送入Decoder,Decoder有Object queries,是可学习的位置嵌入作为输入,经过多头自注意力模块,再经过Encoder和Decoder之间的多头互注意力模块,再送入前馈神经网络处理。Decoder层也可以堆叠多个,最后送入前馈神经网络FFN进行物体类别预测和边界框的预测。
边栏推荐
- leecode3. 无重复字符的最长子串
- 2022-07-07 Daily: Ian Goodfellow, the inventor of Gan, officially joined deepmind
- [crawler] avoid script detection when using selenium
- HZOJ #236. 递归实现组合型枚举
- Day26 IP query items
- TPG x AIDU|AI领军人才招募计划进行中!
- 《ASP.NET Core 6框架揭秘》样章[200页/5章]
- PACP学习笔记三:PCAP方法说明
- Practical example of propeller easydl: automatic scratch recognition of industrial parts
- Users, groups, and permissions
猜你喜欢
![[untitled]](/img/6c/df2ebb3e39d1e47b8dd74cfdddbb06.gif)
[untitled]
How to apply @transactional transaction annotation to perfection?

About the problem of APP flash back after appium starts the app - (solved)
【Presto Profile系列】Timeline使用
Leetcode skimming: binary tree 23 (mode in binary search tree)
[untitled]

日本政企员工喝醉丢失46万信息U盘,公开道歉又透露密码规则
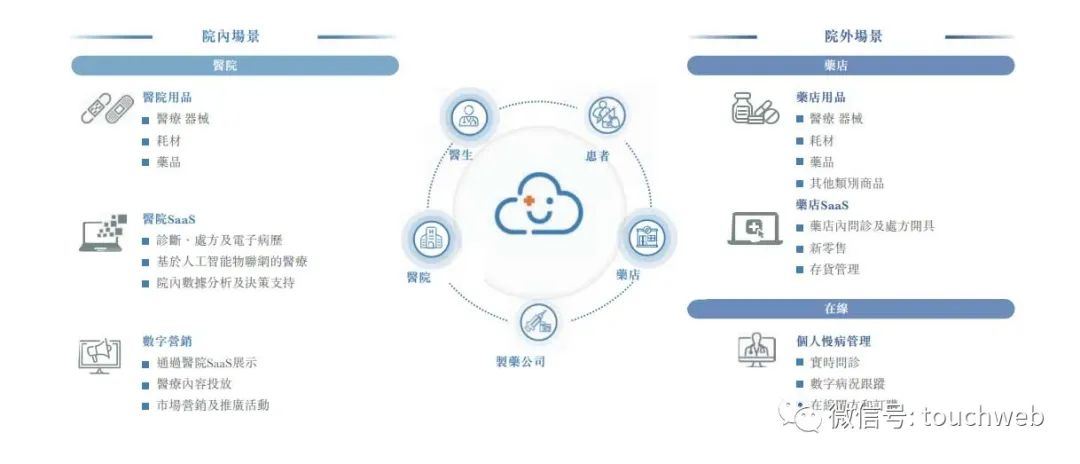
智云健康上市:市值150亿港元 SIG经纬与京新基金是股东
2022a special equipment related management (boiler, pressure vessel and pressure pipeline) simulated examination question bank simulated examination platform operation

飞桨EasyDL实操范例:工业零件划痕自动识别
随机推荐
初学XML
MySQL导入SQL文件及常用命令
DHCP 动态主机设置协议 分析
[crawler] avoid script detection when using selenium
JS判断一个对象是否为空
Guangzhou held work safety conference
- Oui. Migration entièrement automatisée de la Sous - base de données des tableaux d'effets sous net
Per capita Swiss number series, Swiss number 4 generation JS reverse analysis
Find ID value MySQL in string
How to apply @transactional transaction annotation to perfection?
PHP调用纯真IP数据库返回具体地址
共创软硬件协同生态:Graphcore IPU与百度飞桨的“联合提交”亮相MLPerf
Leetcode brush question: binary tree 24 (the nearest common ancestor of binary tree)
@What is the difference between resource and @autowired?
Leetcode question brushing: binary tree 26 (insertion operation in binary search tree)
Leetcode skimming: binary tree 20 (search in binary search tree)
TPG x AIDU|AI领军人才招募计划进行中!
环境配置篇
How to reset Google browser? Google Chrome restore default settings?
飞桨EasyDL实操范例:工业零件划痕自动识别