当前位置:网站首页>【Presto Profile系列】Timeline使用
【Presto Profile系列】Timeline使用
2022-07-07 10:58:00 【skyyws】
我们在Presto页面,可以通过“Splits”标签页查看整个查询的Timeline信息,如下所示:
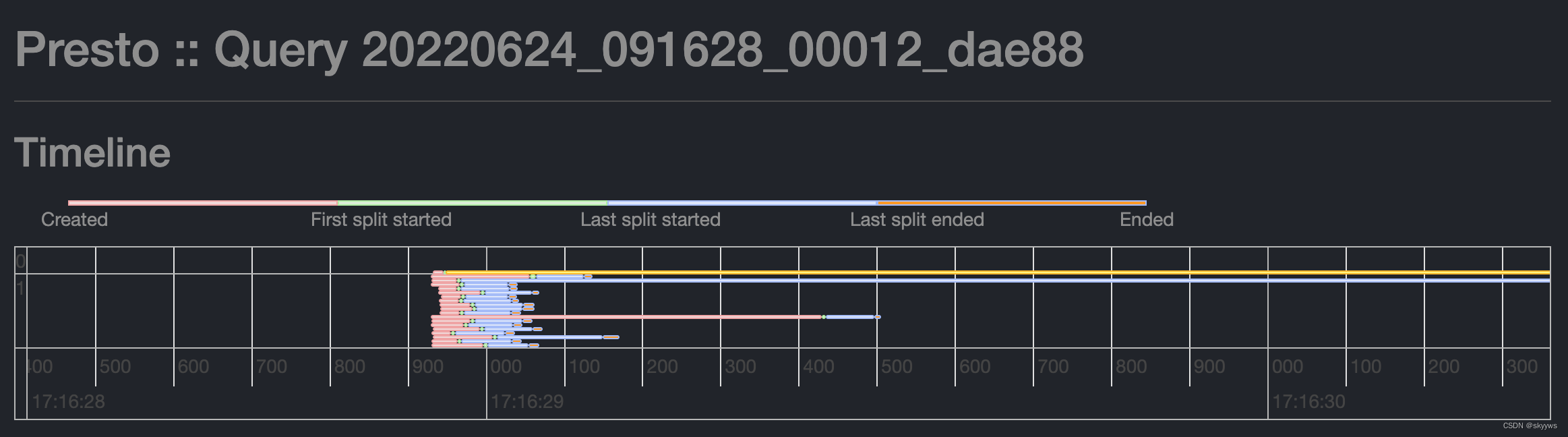
本文,我们就从代码层面来看一下这个Timeline的相关内容,以及我们该如何使用它来排查一个查询的瓶颈点。
一、代码研究
简单来说,上面的Timeline展示的是stage与task相关的信息。这里我们首先看下每个task的taskId信息。
1.1 TaskId
我们可以直接在查询的详细页面上展开某个stage,然后就可以看到该stage下的所有task信息,如下所示: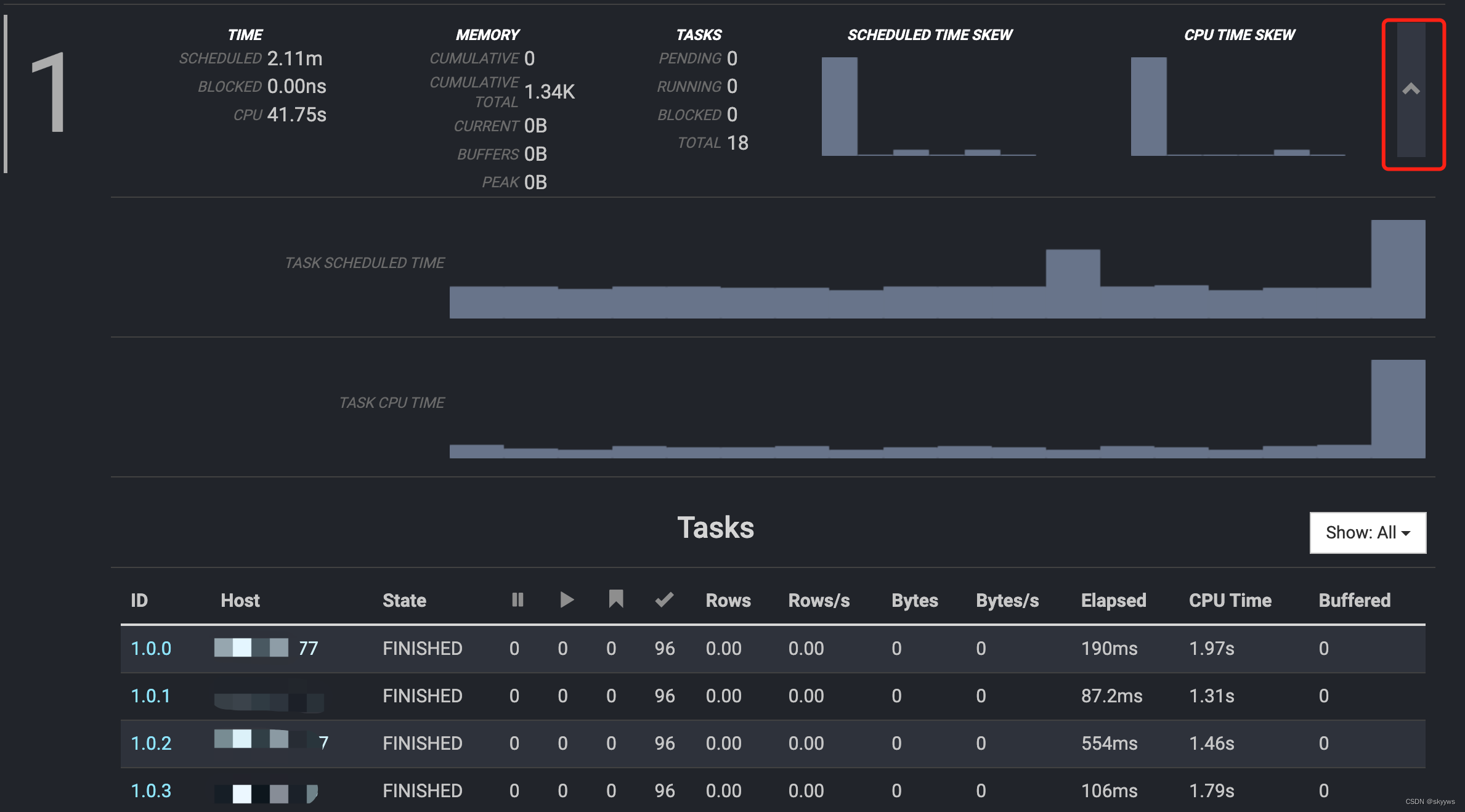
每个task都有自己的一个ID,例如1.0.2,这个就是taskId,主要由两部分组成:
//SqlStageExecution.java
TaskId taskId = new TaskId(stateMachine.getStageExecutionId(), nextTaskId.getAndIncrement());
SqlStageExecution
-StageExecutionStateMachine stateMachine
--StageExecutionId stageExecutionId
---StageId stageId
---int id
对于上面的1.0.2,其中stageExecutionId是1.0,而nextTaskId是2。对于stageExecutionId而言,其中1就是stageId,而0则是id。StageExecutionId相关的代码如下:
//LegacySqlQueryScheduler.java
List<StageExecutionAndScheduler> sectionStages =
sectionExecutionFactory.createSectionExecutions(
session,
section,
locationsConsumer,
bucketToPartition,
outputBuffers,
summarizeTaskInfo,
remoteTaskFactory,
splitSourceFactory,
0).getSectionStages();
//SectionExecutionFactory.java
SqlStageExecution stageExecution = createSqlStageExecution(
new StageExecutionId(stageId, attemptId),
可以看到,这个id是一个attemptId,默认是从0开始的,这里我们就暂时认为这个值在正常情况下都是0,相关代码不再深入展开。
1.2 Timeline相关成员
Timeline页面主要是由js的脚本来构造生成的,相关的代码如下:
//timeline.html
function renderTimeline(data) {
function getTasks(stage) {
return [].concat.apply(
stage.latestAttemptExecutionInfo.tasks,
stage.subStages.map(getTasks));
}
tasks = getTasks(data.outputStage);
tasks = tasks.map(function(task) {
return {
taskId: task.taskId.substring(task.taskId.indexOf('.') + 1),
time: {
create: task.stats.createTime,
firstStart: task.stats.firstStartTime,
lastStart: task.stats.lastStartTime,
lastEnd: task.stats.lastEndTime,
end: task.stats.endTime,
},
};
});
而这其中各个变量对应的Java类如下所示:
//作为整个Timeline的输入内容
QueryInfo data
-Optional<StageInfo> outputStage
//最终遍历处理每个TaskInfo
StageInfo stage
-StageExecutionInfo latestAttemptExecutionInfo
--List<TaskInfo> tasks
//循环处理outputStage的subStages中的每个<StageInfo
-List<StageInfo> subStages
//主要获取taskId进行分组、排序,stats中的几个time变量进行timeline展示
TaskInfo task
-TaskStats stats
1.3 Timeline阶段
在介绍Timeline的构造之前,先看一下timeline的几个节点,这里主要获取了每个task的五个阶段时间点,如下所示:
- Created
- First split started
- Last split started
- Last split ended
- Ended
从上一个时间点,到这个时间点之间,用一个颜色标识,作为一个阶段。一共四个阶段,如下所示:
- Created -> First split started:red
- First split started -> Last split started:green
- Last split started -> Last split ended:blue
- Last split ended -> Ended:orange
1.4 Timeline构造
服务端会根据上面的一些变量,然后通过js脚本来构造对应的变量,用于页面展示,相关代码如下所示:
//renderTimeline(timeline.html)
var groups = new vis.DataSet();
var items = new vis.DataSet();
for (var i = 0; i < tasks.length; i++) {
var task = tasks[i];
var stageId = task.taskId.substr(0, task.taskId.indexOf("."));
var taskNumber = task.taskId.substr(task.taskId.indexOf(".") + 1);
if (taskNumber == 0) {
groups.add({
id: stageId,
content: stageId,
sort: stageId,
subgroupOrder: 'sort',
});
}
首先就是获取stageId和taskNumber。例如对于1.0.2,分别就是1和0.2。处理stage的第一个task时,就将stage信息,加入到groups中。接着就开始处理这个task的各个阶段,以第一阶段为例:
items.add({
group: stageId,
start: task.time.create,
end: task.time.firstStart,
className: 'red',
subgroup: taskNumber,
sort: -taskNumber,
});
这里统计的就是task从create到第一个split start的时间,并表示为红色。遍历完成之后,所有的task都会被处理并放到items中。下面我们来看下groups和items两个成员的具体内容。
1.4.1 groups成员
通过直接在浏览器中对js进行调试,就可以看到groups的内容,如下所示:
由此可知,这个groups的成员就是对应的各个stage的id信息。
1.4.2 items成员
通过直接在浏览器中对js进行调试,同样可以看到items的信息,如下所示:
可以看到,每个task的每个阶段对应一个成员,例如task 1.0.16,它包含了四个成员,即group是1,subgroup是0.16,对应的分别就是stageId和taskNumber,这些成员的className不同,即不同的阶段,而sort则是-0.16,对应上面代码中的-taskNumber。
二、Timeline相关信息
介绍完Timeline的具体内容和代码实现之后,简单看下可以通过这个timeline获取哪些信息。
2.1 查看开始和结束时间
首先,可以通过缩放,来查看整个执行计划的概览:
此时,每一格代表的是5s,因此整个查询的时间范围大概是:6.24 17:16:25-6.24 17:16:45。如果我们再放大,就可以看到: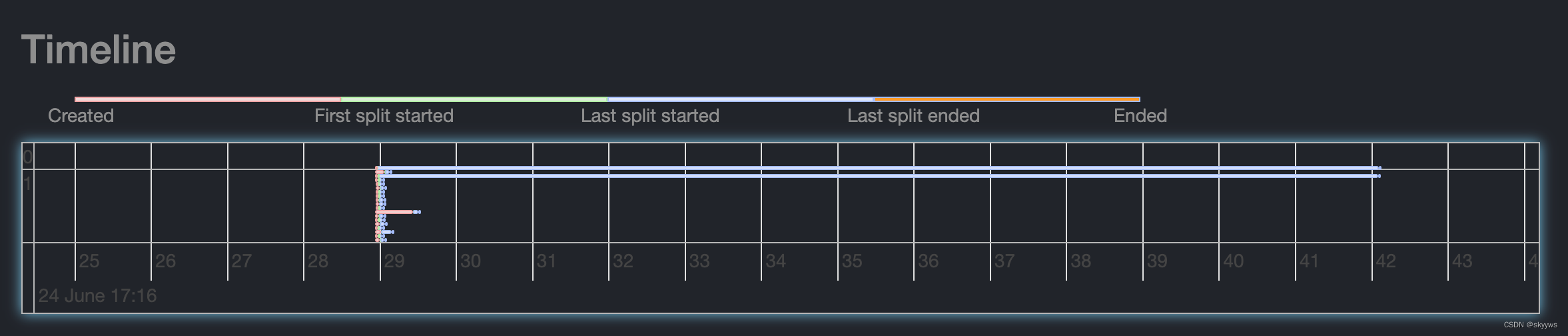
更精确的时间区间是:6.24 17:16:28-6.24 17:16:43。继续放大,然后双击鼠标,拖动整个timeline,就可以看到更加精确的时间: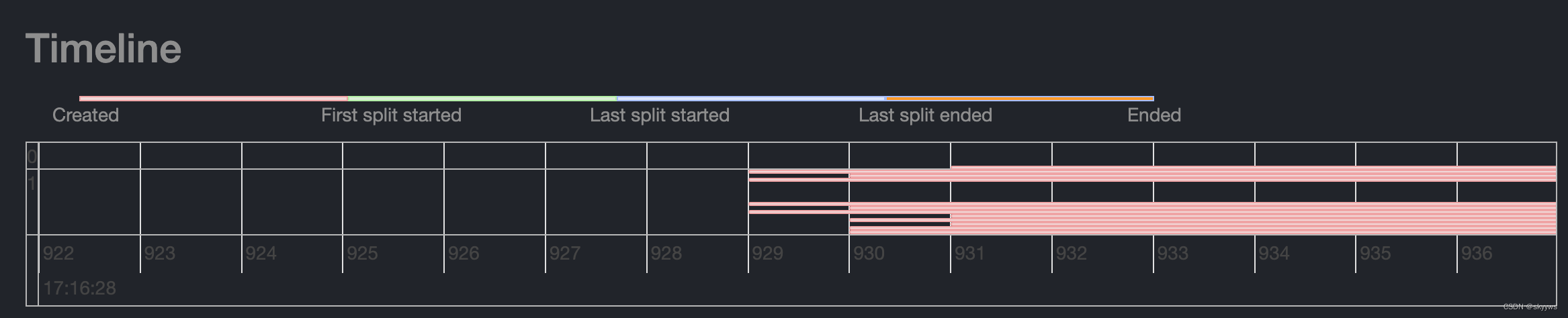

此时可以看到,开始时间是:6.24 17:16:28.929,而结束时间则是:6.24 17:16:42.093,所以整个查询持续的时间大约是13.164s,与overview中的基本一致: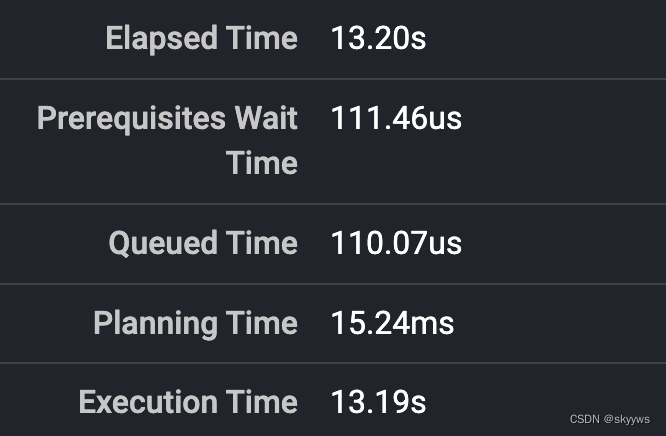
2.2 查看Stage分组
第二个重要的功能,就是查看stage信息。Timeline里面的每一个行代表一个task,下面会详细说到。首先会给task按照stage进行分组排序,排序是按照stageId进行的。我们可以通过纵坐标来查看stage信息: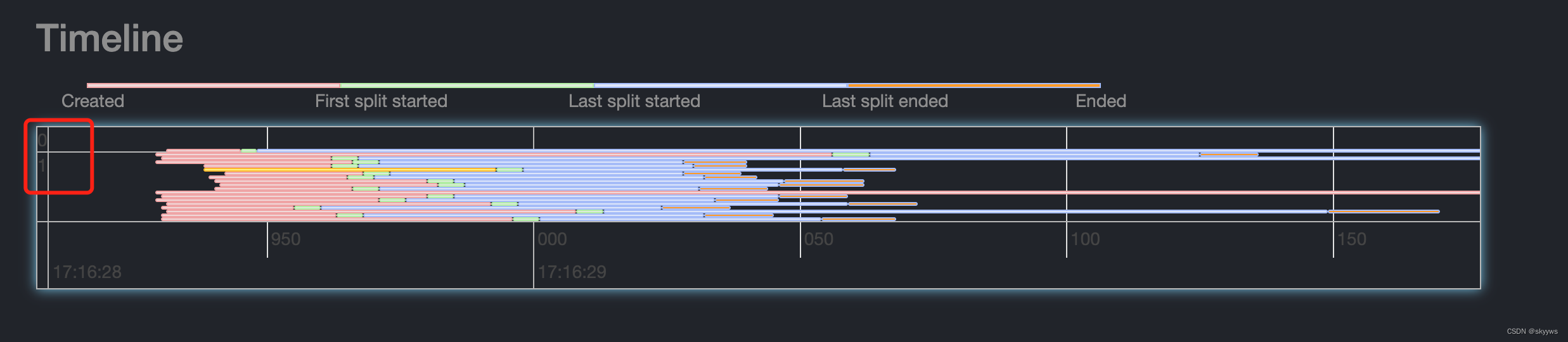
可以看到,上面的timeline有两个stage,分别是0和1。这样我们就很容易看出来stage数量以及每个stage的task数量。
2.3 查看Stage的task
我们还可以通过timeline查看每个task的耗时信息。我们继续以上面的timeline为例,这个查询的完整task信息如下所示:
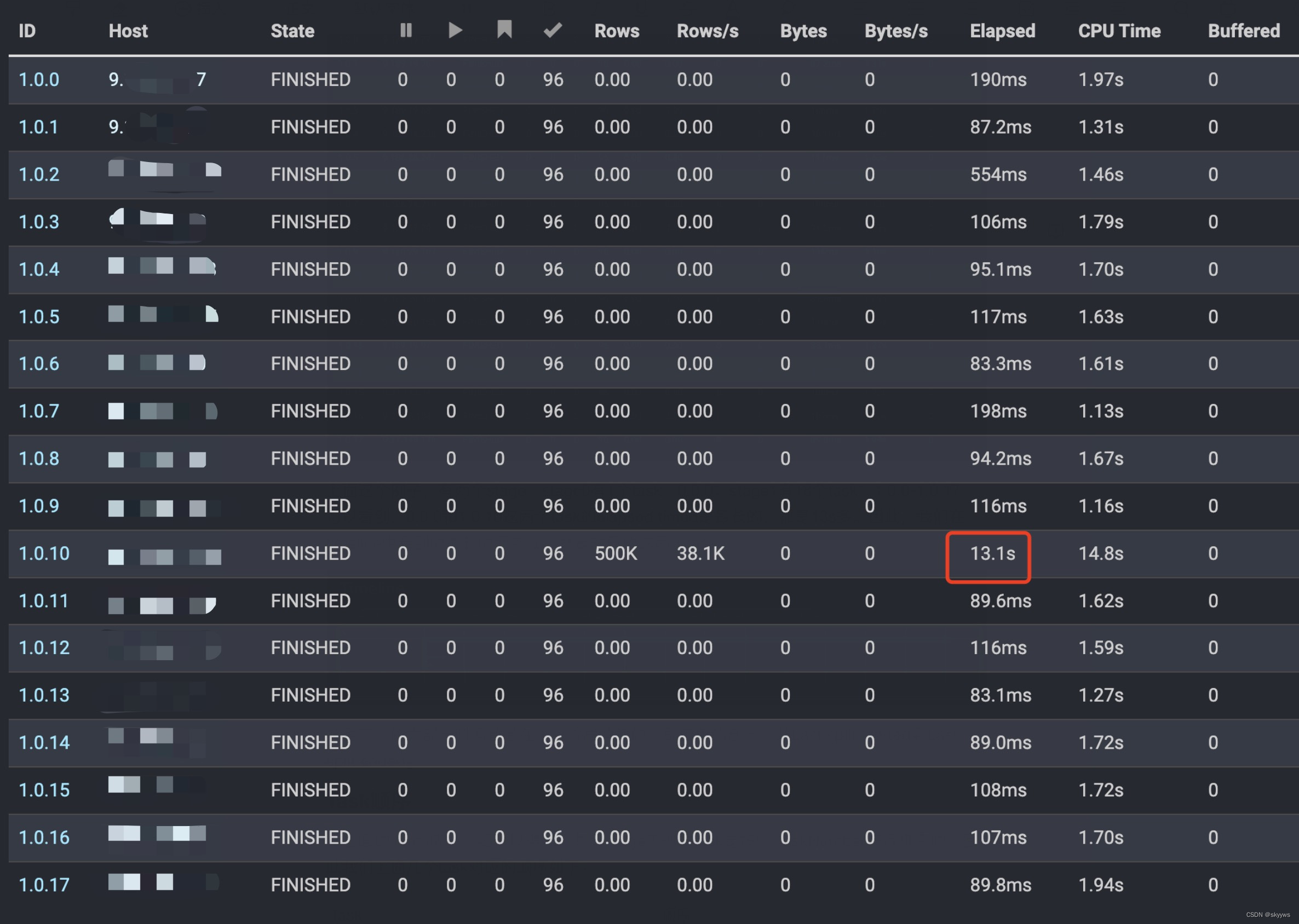
可以看到,有两个stage。stage0有1个task:0.0.0;stage1有18个task:1.0.0~1.0.17。其中,0.0.0和1.0.10这两个task的elapsed timed是最长的,都是13s多。因此,我们在timeline中看到的最长的两条线,就是对应的这两个task: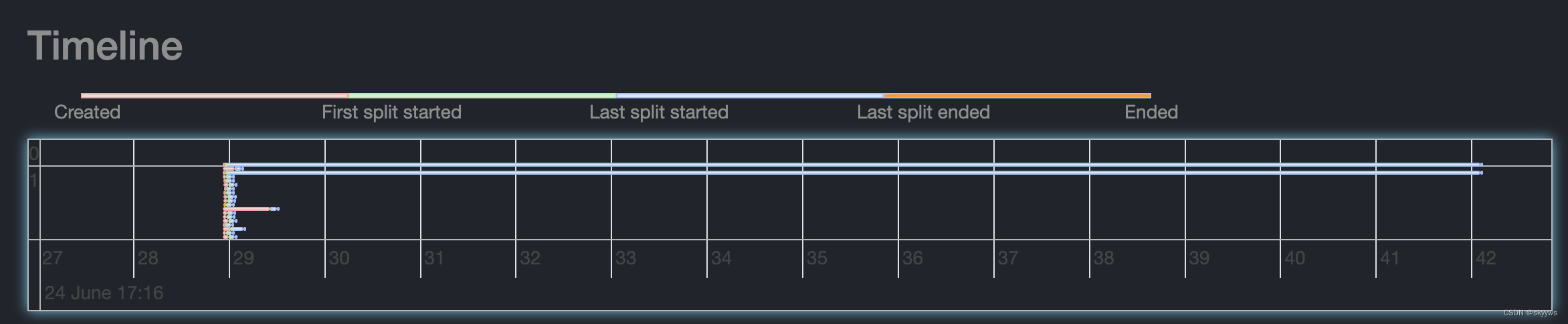
并且它们的大部分时间都是在第三阶段消耗的,即蓝色的部分,从Last split started到Last split ended。
2.3.1 Task顺序
从上面的items成员介绍可以得知,每个stage内部的task是按照-taskNumber进行排序的,因此我们上面几个task对应的顺序如下:
| Task | 顺序 |
|---|---|
| 1.0.0 | -0 |
| 1.0.1 | -0.1 |
| 1.0.2 | -0.2 |
| … | … |
| 1.0.10 | -0.1 |
| 1.0.11 | -0.11 |
| … | … |
| 1.0.17 | -0.17 |
这里需要注意的是1.0.1和1.0.10这两个task的sort值是一样的,都是-0.1。所以最终,上述Timeline的stage 1的task从上往下的顺序就是:
1.0.0 -> 1.0.10/1.0.1 -> 1.0.11 -> … -> 1.0.17 -> 1.0.2 -> … -> 1.0.9
结合上面详细的task图,我们得知:1.0.10耗时13.1s,1.0.2耗时554ms(相比其他task耗时比较长),这两个task正好位于timeline中的第二个(也可能是第三个)和中间部分: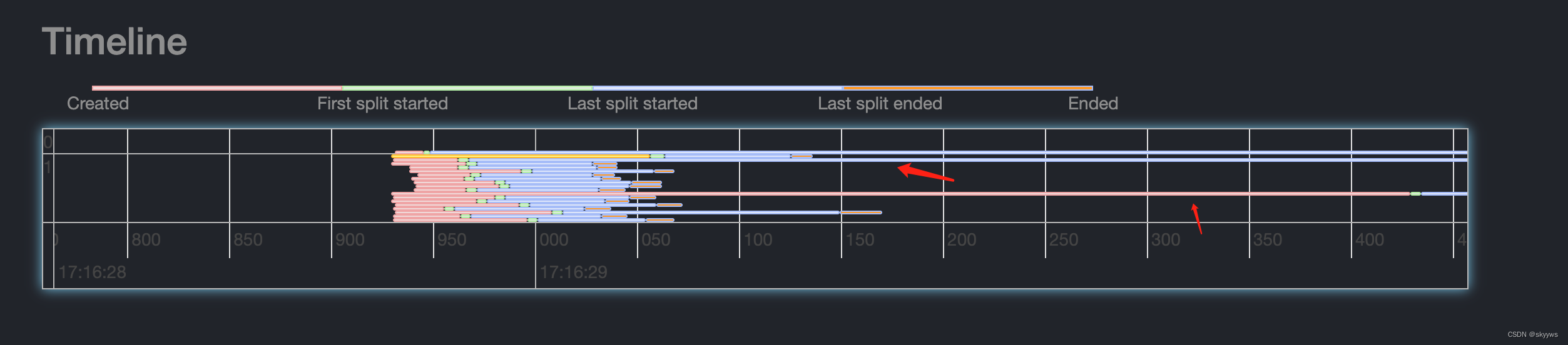
三、Timeline使用小结
通过上面的介绍,我们可以得知,timeline主要展示了各个stage以其task的概览信息。因此,我们通常可以使用timeline获取如下的一些信息:
1)快速查看整个查询的瓶颈点位于哪个stage;
2)快速定位stage内部的task是否有skew;
3)通过task不同颜色的长短,迅速定位是哪个阶段的耗时占比高;
4)根据找到的慢task,再结合task的详细信息进行进一步的排查。
例如,对于下面这种图: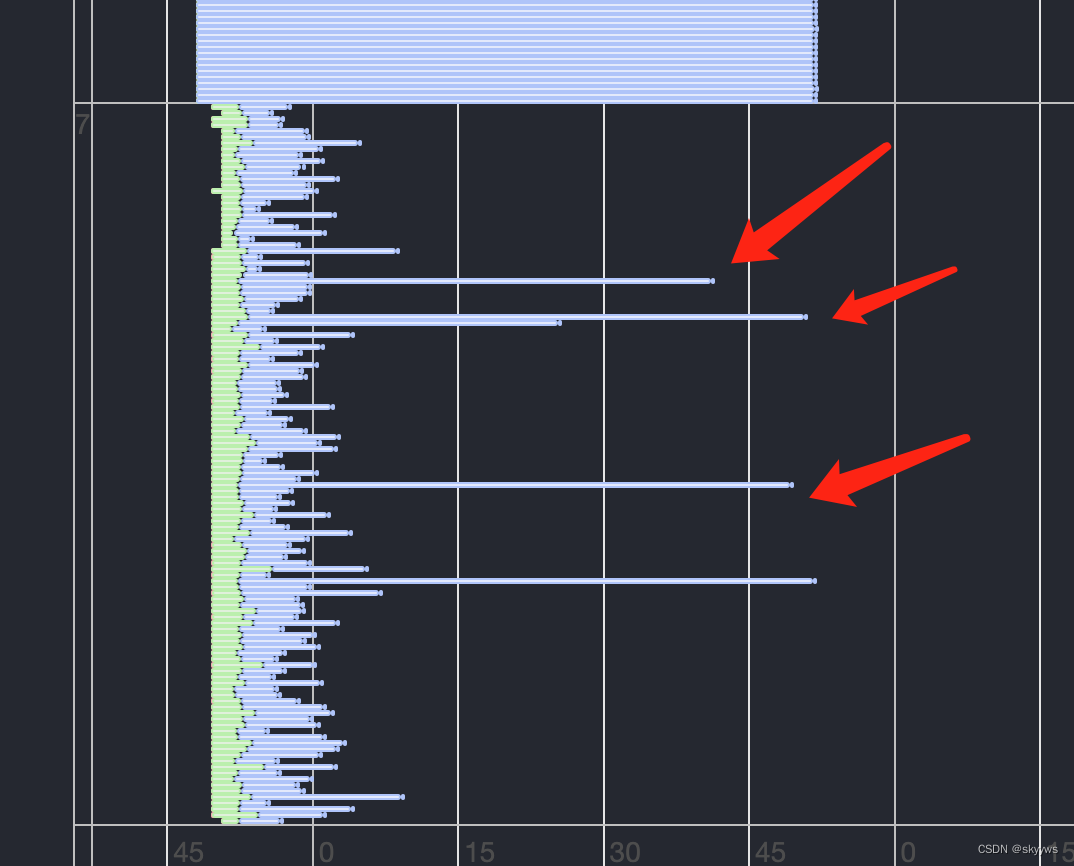
可以看到,最下面的stage(scan节点)存在部分task耗时明显很长,并且是蓝色线条,即Last split started到Last split ended。说明这些task的所有split中,至少有1个split耗时严重,此时我们就可以去查看这些task的详细信息了。
边栏推荐
- opencv的四个函数
- DHCP 动态主机设置协议 分析
- Day21 multithreading
- Four functions of opencv
- Enterprise custom form engine solution (XII) -- experience code directory structure
- Cookie
- Master formula. (used to calculate the time complexity of recursion.)
- Common text processing tools
- Cmu15445 (fall 2019) project 2 - hash table details
- How does MySQL create, delete, and view indexes?
猜你喜欢
Go语言学习笔记-结构体(Struct)
Image pixel read / write operation
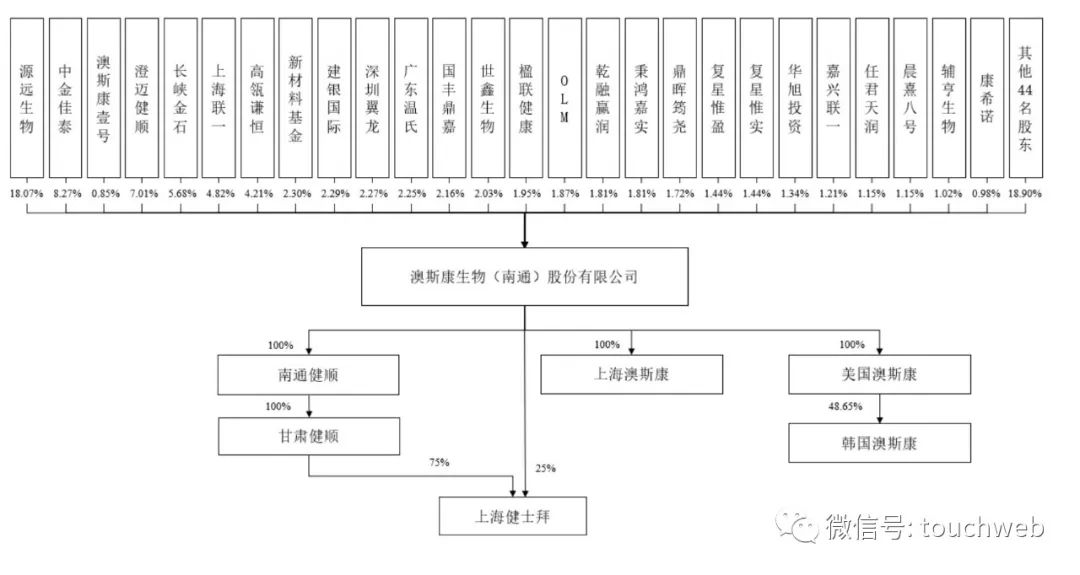
高瓴投的澳斯康生物冲刺科创板:年营收4.5亿 丢掉与康希诺合作

Day-19 IO stream
Cookie
Day-15 common APIs and exception mechanisms

2022 practice questions and mock examination of the third batch of Guangdong Provincial Safety Officer a certificate (main person in charge)
ISPRS2021/遥感影像云检测:一种地理信息驱动的方法和一种新的大规模遥感云/雪检测数据集
Aosikang biological sprint scientific innovation board of Hillhouse Investment: annual revenue of 450million yuan, lost cooperation with kangxinuo

Sequoia China completed the new phase of $9billion fund raising
随机推荐
初学XML
HZOJ #240. 图形打印四
【从 0 开始学微服务】【02】从单体应用走向服务化
Leetcode brush questions: binary tree 19 (merge binary tree)
【无标题】
在字符串中查找id值MySQL
Several ways to clear floating
ACL 2022 | small sample ner of sequence annotation: dual tower Bert model integrating tag semantics
货物摆放问题
MySQL master-slave replication
Query whether a field has an index with MySQL
File operation command
《ASP.NET Core 6框架揭秘》样章[200页/5章]
MySQL导入SQL文件及常用命令
博文推荐|Apache Pulsar 跨地域复制方案选型实践
Talk about four cluster schemes of redis cache, and their advantages and disadvantages
[statistical learning method] learning notes - support vector machine (Part 2)
MySQL importing SQL files and common commands
Enterprise custom form engine solution (XII) -- experience code directory structure
Star Enterprise Purdue technology layoffs: Tencent Sequoia was a shareholder who raised more than 1billion