当前位置:网站首页>Mysql高级篇学习总结13:多表连接查询语句优化方法(带join语句)
Mysql高级篇学习总结13:多表连接查询语句优化方法(带join语句)
2022-08-04 10:48:00 【koping_wu】
Mysql高级篇学习总结13:多表连接查询语句优化方法(带join语句)
1、关联查询优化
1、驱动表和被驱动表
驱动表是主表,被驱动表是从表
1)对于内连接来说:
SELECT * FROM A JOIN B ON ...
A表不一定是驱动表!!!优化器会根据查询语句进行优化,决定先查哪张表。先查询的那张表就是驱动表。
2)对于外连接来说:
SELECT * FROM A LEFT JOIN B ON ...
对于外连接,A表也不一定是驱动表,优化器也可以进行优化。
join连接的结论如下:
- 对于内连接来说,查询优化器可以决定谁作为驱动表、谁作为被驱动表
- 对于内连接来说,如果表的连接条件中只能有一个字段有索引,则有索引的字段所在的表会被作为被驱动表。
- 对于内连接来说,在两个表的连接条件都存在索引的情况下,会选择小表作为驱动表,即小表驱动大表。
那么为什么会得出上面的结论呢?可以继续看一下下面的2-4小节的分析。
2、Simple Nested-Loop Join(简单嵌套循环连接)
假设此时A表和B表都没有索引。
那么此时如果使用简单嵌套循环连接,那就是从A表中取出一条数据,然后遍历B表,将匹配的数据放入结果中;然后再取A表的下一条数据,然后再继续…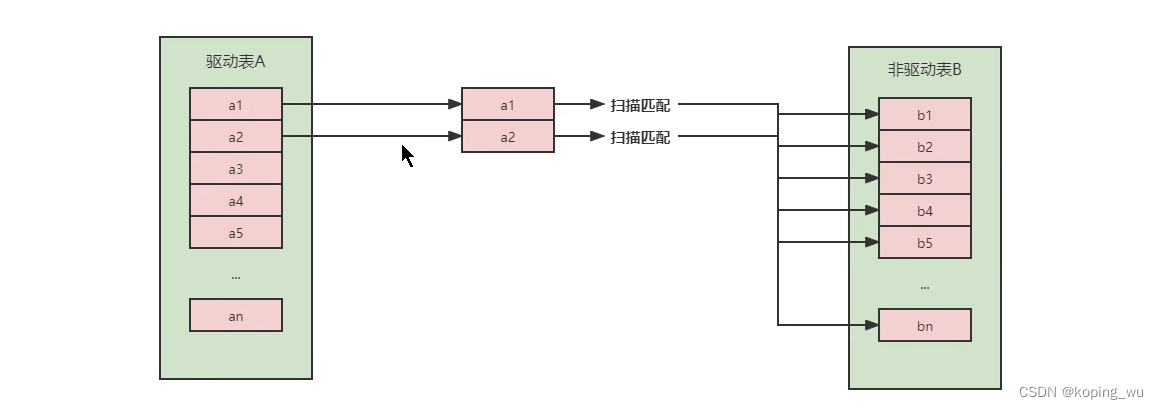
这种方式的效率是非常低的,如果表A中的数据有100条,表B中的数据有1000条,那么需要A*B=10万次。
开销统计如下: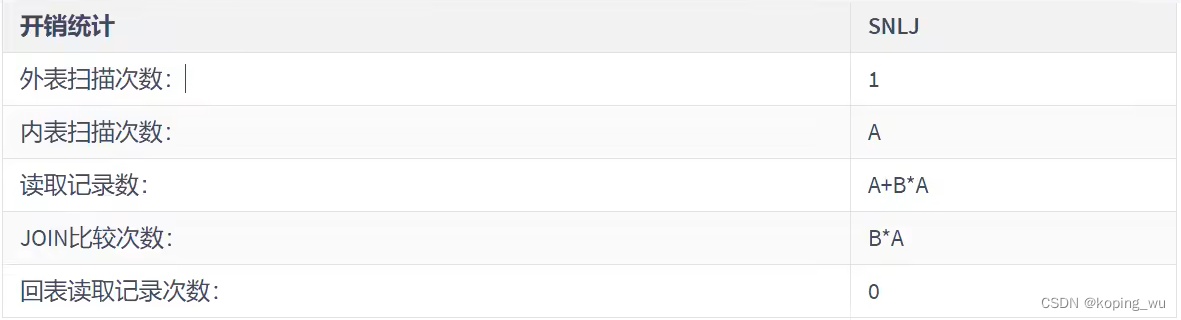
3、Index Nested-Loop Join(索引嵌套循环连接)
在包含join查询的语句中,如果都不包含索引,那么查找效率是很低的,这种情况就可以考虑进行优化,比如添加索引。
添加了索引的话,可以减少内层表数据的匹配次数。表A的每一条数据不用再和整个表B进行查询了,可以直接从表B中根据索引查出对应数据,这样可以大大减少内层表的匹配次数。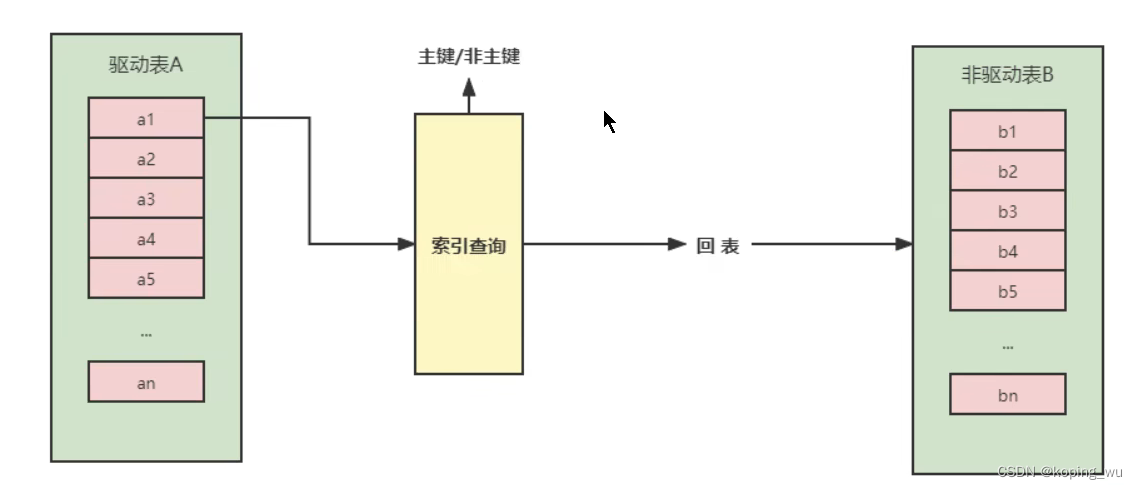
如下图,此时被驱动表加了索引,效率是非常高的。如果索引不是主键索引,还得进行一次回表查询。因此被驱动表是主键索引的话,效率会更高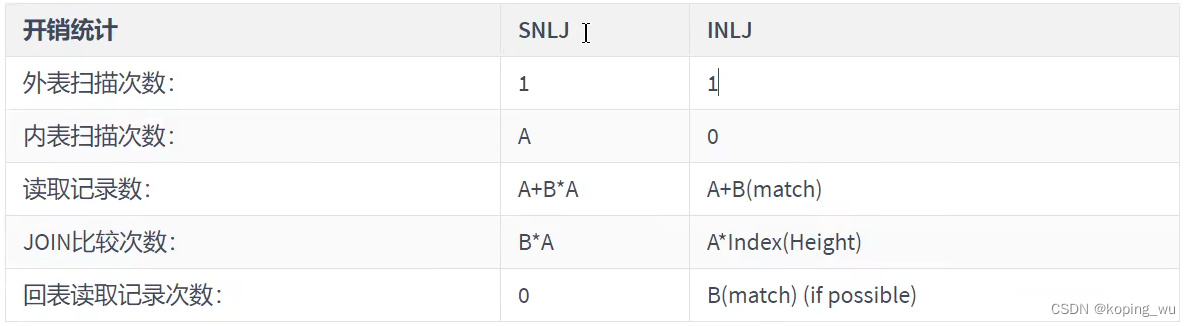
4、Block Nested-Loop Join(块嵌套循环连接)
如果存在索引,那么会使用idex的方式进行join。如果join的列没有索引,那么被驱动表要扫描的次数就太多了。
因为每次访问被驱动表,其表中的记录都会被加载到内存中;然后再从驱动表中取出一条进行匹配,匹配结束后清楚内存。然后再从驱动表中加载一条记录,再把被驱动表中的记录加载到内存中进行匹配。这样周而复始,大大增加了IO的次数。
为了减少被驱动表的IO次数,就出现了Block Nested-Loop Join(块嵌套循环连接)的方式。
不再是逐条获取驱动表的数据,而是一块一块地获取,引入了join buffer缓冲区,将驱动表join相关的部分数据列缓存到join buffer中,然后全表扫描被驱动表,被驱动表的每一条记录一次性和join buffer中的所有驱动表记录进行匹配。将简单嵌套循环中的多次比较合并成一次,降低了被驱动表的访问频率。
因此查询的时候尽量减少不必要的字段,可以让join buffer中可以存放更多的列。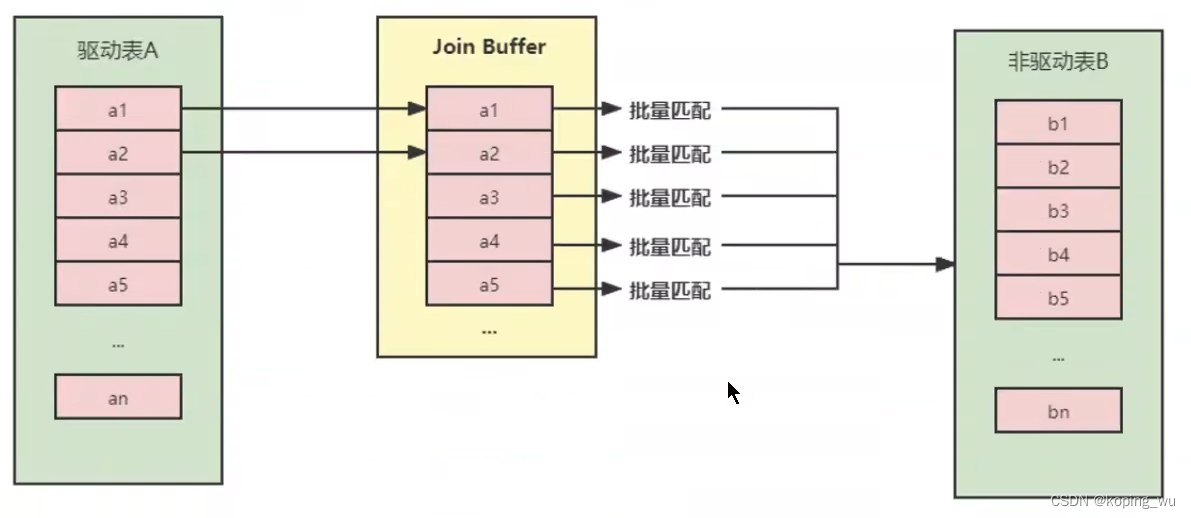
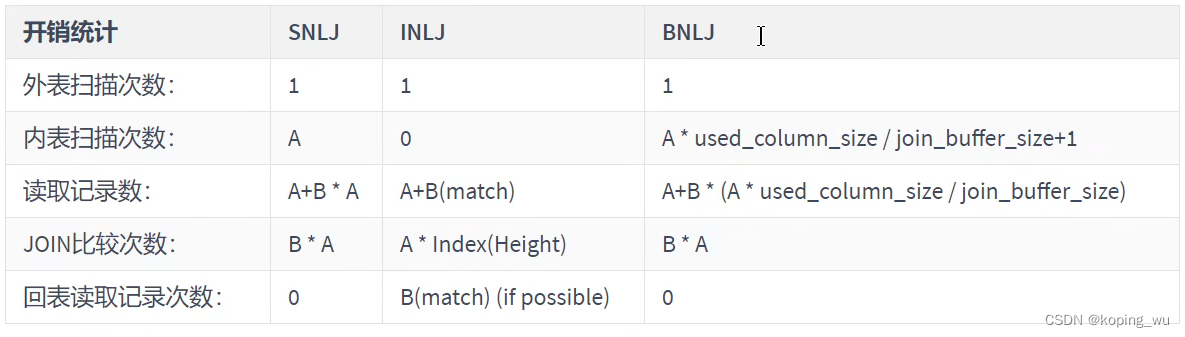
可以看到BNLJ相比于SNLJ来说:
1)内标扫描次数变少了
2)读取记录数变少了
参数设置:block_nested_loop
可以通过show variables like '%optimizer_switch%'查看block_nested_loop的状态,默认是开启的。
mysql> show variables like '%optimizer_switch%';
+------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Variable_name | Value |
+------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| optimizer_switch | index_merge=on,index_merge_union=on,index_merge_sort_union=on,index_merge_intersection=on,engine_condition_pushdown=on,index_condition_pushdown=on,mrr=on,mrr_cost_based=on,block_nested_loop=on,batched_key_access=off,materialization=on,semijoin=on,loosescan=on,firstmatch=on,duplicateweedout=on,subquery_materialization_cost_based=on,use_index_extensions=on,condition_fanout_filter=on,derived_merge=on,prefer_ordering_index=on |
+------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
驱动表能不能一次加载完,要看join buffer能不能存储所有的数据,默认情况下join_buffer_size=256k
mysql> show variables like '%join_buffer%';
+------------------+--------+
| Variable_name | Value |
+------------------+--------+
| join_buffer_size | 262144 |
+------------------+--------+
1 row in set (0.00 sec)
5、Join小结
join语句查询可以从以下5个方面进行考虑:
- 整体效率比较:INLJ > BNLJ > SNLJ
- 永远用小结果集驱动大结果集合(本质就是减少外层循环的数据数量)
- 为被驱动表匹配的条件增加索引(即减少内层表的循环匹配次数)
- 增大join buffer size的大小(一次缓存的数据越多,那么内层包的扫表次数就越少)
- 减少驱动表不必要的字段查询(字段越少,join buffer所缓存的数据就越多)
6、Hash Join
从Mysql的8.0.20版本开始将废弃BNLJ,因为从Mysql 8.0.18版本开始就加入了hash join,默认都会使用hash join了。
边栏推荐
- Jenkins使用手册(1) —— 软件安装
- ArrayList和LinkedList的区别
- 语音社交app源码——具备哪些开发优势?
- 数据使用要谨慎——不良数据带来严重后果
- STM32前言知识总结
- Graphic and text hands-on tutorial--ESP32 MQTT docking EMQX local server (VSCODE+ESP-IDF)
- 【Idea series】idea configuration
- safe-point(safepoint 安全点) 和 safe-region(安全区域)「建议收藏」
- Use pytest hook function to realize automatic test result push enterprise WeChat
- 黑马瑞吉外卖之员工账号的禁用和启用以及编辑修改
猜你喜欢



随机推荐
Win11 file types, how to change?Win11 modify the file suffix
【励志】复盘的重要性
Apache Calcite 框架原理入门和生产应用
语音社交app源码——具备哪些开发优势?
BOSS 直聘回应女大学生连遭两次性骚扰:高度重视求职者安全,可通过 App 等举报
RL78 development environment
helm安装
Graphical Hands-on Tutorial--ESP32 One-Key Network Configuration (Smartconfig, Airkiss)
AWS Lambda related concepts and implementation approach
学会使用set和map的基本接口
八、MFC对话框
转转测试环境的标签域名实践
【Idea series】idea configuration
无代码平台单项选择入门教程
Why are all hotel bathrooms transparent?
强烈推荐一款优秀且通用的后台管理系统
栈与队列的实现
浅析深度学习在图像处理中的应用趋势及常见技巧
Heap Sort
HCIP 第十七天