当前位置:网站首页>Neural networks and support vector machines for machine learning
Neural networks and support vector machines for machine learning
2022-06-22 00:03:00 【WihauShe】
neural network
Definition
Neural networks are widely parallel interconnected networks composed of adaptive simple units , Its organization can simulate the interaction of biological nervous system with real world objects
Neuron model
M-P Neuron model : Receive from n Input signals transmitted by other neurons through weighted connections , If the total input value is greater than the threshold value, it passes “ Activation function ” Processing to produce a neuron model
Activation function : Step function ( Discontinuous 、 Not smooth )、Sigmoid function
Perceptrons and multilayer networks
- The perceptron has two layers of neurons , The input layer receives the external input signal and passes it to the output layer , The output layer is M-P Neuron , Also known as “ Threshold logical unit ”. The perceptron has only output layer neurons to process the activation function , That is, only one layer of functional neurons , It can solve linear separable problems but not nonlinear separable problems .
- Cryptic layer ( Hidden layer ): A layer of neurons between the output layer and the input layer
- Neural networks with hidden layers are called multilayer networks
- Multilayer feedforward neural network : Input layer neurons receive external input , Hidden layer and output layer neurons process signals , The final result is output by the output layer neurons
- The learning process of neural network is to adjust the relationship between neurons according to the training data “ Right of connection ” And the threshold of each functional neuron
Error back propagation algorithm (error BackPropagation, BP)
- BP The Internet : use BP Algorithm training of multilayer feedforward neural network
- Cumulative error back propagation algorithm : Error back propagation is carried out based on the update rule of minimizing cumulative error
Over fitting problem
Stop early : Divide the data into training set and verification set , The training set is used to calculate the gradient 、 Update connection rights and thresholds , At the same time, the connection weight and threshold with the minimum verification set error are returned
Regularization : Add a part to the error objective function to describe the complexity of the network
Global minimum and local minimum
- Local minima : A point in parameter space , The error function of the field point is not less than the function value of the point
- Global minimum solution : The error function value of all points in the parameter space shall not be less than the error function value of the point
“ Jump out of ” Local minimization strategy :
Initialize multiple neural networks with multiple sets of different parameter values , After training in the standard way , Take the solution with the least error as the final parameter
Use “ Simulated annealing ” technology
Use random gradient descent
Genetic algorithm (ga)
Other common neural networks
Plasticity : Neural network should have the ability to learn new knowledge
stability : Neural network should keep the memory of old knowledge when learning new knowledge
Radial basis function networks (RBF): A single hidden layer feedforward neural network , The radial basis function is used as the activation function of hidden layer neurons , The output layer is a linear combination of the output of hidden layer neurons
Adaptive resonance theory network (ART): An important representative of competitive learning , The network consists of a comparison layer 、 Identification layer 、 Identification threshold and reset module , The comparison layer is responsible for receiving input samples , And pass it to the recognition layer neurons , Each neuron in the recognition layer corresponds to a pattern class , The number of neurons can increase dynamically during training to add new pattern classes
Self organizing mapping networks (SOM): A competitive learning type unsupervised neural network , It can map high dimensional input data to low dimensional space , At the same time, the topology of input data in high-dimensional space is maintained , That is, similar sample points in high-dimensional space are mapped to adjacent neurons in the network output layer
Elman The Internet : One of the most common recurrent neural networks , The structure is similar to multilayer feedforward network , But the output of hidden layer neurons is fed back , Together with the signal provided by the neuron of the input layer at the next moment , As the input of hidden layer neurons at the next moment
Boltzmann machine : An energy based model , Its neurons are divided into two layers : Explicit layer and hidden layer , The explicit layer is used to represent the input and output of data , The hidden layer is understood as the internal expression of data . be limited to Boltzmann Only the connection between the visible layer and the hidden layer is reserved , So that Boltzmann The machine structure is simplified from a complete graph to a bipartite graph , It is commonly used “ Contrast divergence ” Algorithm
Deep learning
- Multi hidden layer neural networks are difficult to be trained directly by classical algorithms , Because when the error propagates inversely in multiple hidden layers , Tend to “ Divergence ” And can't converge to a steady state
- Unsupervised layer by layer training : Train one layer of hidden nodes at a time , During training, the output of the hidden node of the upper layer is used as the input , The output of the hidden node of this layer is used as the input of the hidden node of the next layer , This is called “ Preliminary training ”, After the pre training is completed , And then the whole network “ fine-tuning ” Training
Strategies to save training costs :
Preliminary training + fine-tuning : Group a large number of parameters , For each group, first find the setting that looks better locally , Then, based on these local optimization results, the global optimization is carried out
Power sharing : Let a group of neurons use the same connection weight
Support vector machine
Interval and support vector
- The partition hyperplane can be described by the following linear equation :w^T x+b=0
- w For the normal vector , It determines the direction of the hyperplane ,b Is the displacement term , Determines the distance between the hyperplane and the origin
- Support vector : The training sample points closest to the hyperplane on both sides
- interval : Sum of the distances between two heterogeneous support vectors and hyperplane
Kernel function

【 If both are kernel functions , Then the linear combination of the two 、 The direct product is also a kernel function 】
Soft interval and regularization
Soft space : It is allowed that some samples do not meet the constraint
Commonly used alternative loss functions :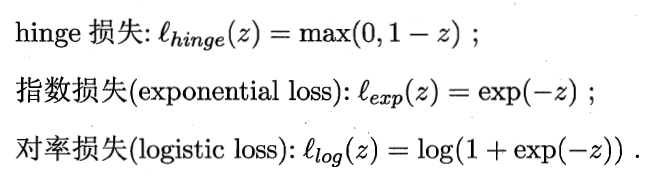
Support vector regression
Support vector regression (Support Vector Regression) Suppose you can tolerate f(x) And y There is at most ϵ The deviation of , That is, only if f(x) And y The absolute value of the difference is greater than ϵ The loss is calculated only when
Nuclear method
Kernel based learning method
The most common , It's through “ Nucleation ”( That is, the kernel function is introduced ) To expand the linear learner into a nonlinear learner
边栏推荐
- 小程序与工业互联网是怎样相辅相成的
- Unity network development (I)
- 二叉排序树
- windows sql server 如何卸载干净?
- 组件传值:兄弟间传值(非父子组件进行传值)
- 关于 国产麒麟Qt编译报错“xxx.pri has modification time xxxx s in the futrue“ 的解决方法
- discuz!论坛修复站帮网vip插件bug:VIP会员到期后,重新开通永久会员时,所属的用户组没有切换到永久会员分组
- Unity-网络开发(二)
- Layout roadmap, the perfect combination of spatial layout and data visualization
- QT document reading notes staticmetaobject parsing and instances
猜你喜欢

I was badly hurt by the eight part essay....

Voir la valeur des données, éclairer l'avenir numérique, le pouvoir numérique est sorti
布局路线图,空间布局与数据可视化的完美结合

路由器连接上但上不了网是什么故障

Win11 how to change the desktop file path to disk D
6月編程語言排行榜已出,這門語言要“封神”
![class path resource [classpath*:mapper/*.xml] cannot be opened because it does not exist](/img/1a/294eb0128285686ede415991f69be7.png)
class path resource [classpath*:mapper/*.xml] cannot be opened because it does not exist
洞见数据价值,启迪数字未来,《数字化的力量》问世

Component value transfer: child components transfer data to parent components

How to uninstall windows SQL Server cleanly?
随机推荐
Go语言学习教程(十二)
树莓派开发笔记(十五):树莓派4B+从源码编译安装mysql数据库
Win11热点连接成功但没网?Win11移动热点和网络冲突的解决方法
路由器连接上但上不了网是什么故障
QT document reading notes staticmetaobject parsing and instances
Enterprise wechat built-in application H5 development record-1
Hardware development notes (IV): basic process of hardware development, making a USB to RS232 module (III): design schematic diagram
Rk3568 Development Notes (II): introduction to the kit, backplane and peripheral test of rk3568 development board
Component value transfer: props are used for parent component and child component value transfer
Unity-网络开发(一)
Project change management
关于 安装Qt5.15.2启动QtCreator后“应用程序无法正常启动0xc0000022” 的解决方法
Must the database primary key be self incremented? What scenarios do not suggest self augmentation?
Taishan Office Technology Lecture: Microsoft YaHei font intentionally set the pit, bold error
无法定位程序输入点于动态链接库怎么办
Component value transfer: value transfer between siblings (value transfer by non parent and child components)
VB screen resolution setting and acquisition_ hawkol_ Sina blog
Jmter test command [note]
Layout roadmap, the perfect combination of spatial layout and data visualization
Rk3568 Development Notes (III): update source, installation of network tools, serial port debugging, network connection, file transfer, installation of vscode and Samba shared services for rk3568 virt