当前位置:网站首页>News classification based on LSTM model
News classification based on LSTM model
2022-07-01 21:36:00 【Desperately_ petty thief】
1、 sketch LSTM Model
LSTM It's short-term and long-term memory neural network , According to the paper, most of the retrieved data are used for classification 、 Machine translation 、 Emotion recognition and other scenes , In text , The main use of tensorflow And keras, build LSTM The model realizes news classification cases .( Only discuss and implement the application case of its model , Don't describe the implementation principle )
2、 Data processing
News data and stop word documents are needed to prepare the data in the early stage , Use jieba Participle and pandas Preprocess the initial data , The total amount of data is 12000. The initial data set is shown in the figure below :

First read the list of stop words , Next use pandas Read the data file , Use jieba The database processes word segmentation and stop words for each line of data , The processing code is shown in the figure below :
def get_custom_stopwords(stop_words_file):
with open(stop_words_file,encoding='utf-8') as f:
stopwords = f.read()
stopwords_list = stopwords.split('\n')
custom_stopwords_list = [i for i in stopwords_list]
return custom_stopwords_list
cachedStopWords = get_custom_stopwords("stopwords.txt")
import pandas as np
import jieba
data = np.read_csv("sohu_test.txt", sep="\t",header=None)
lable_dict = {v:k for k,v in enumerate(data[0].unique())}
data[0] = data[0].map(lable_dict)
def chinese_word_cut(mytext):
return " ".join([word for word in jieba.cut(mytext) if word not in cachedStopWords])
data[1] = data[1].apply(chinese_word_cut)
data3、 Text data vectorization
Set the initial parameters of the model batch_size: Data batch of each round ,class_size: Category ,epochs: Number of training rounds ,num_words: The number of words that appear most often ( This variable is in progress Embeding You need to fill in the size of the vocabulary +1),max_len : The dimension of the text vector , Use Tokenizer Realize vector construction and make padding
batch_size = 32
class_size = 12
epochs = 300
num_words = 5000
max_len = 600
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing import sequence
tokenizer = Tokenizer(num_words=num_words)
tokenizer.fit_on_texts(data[1])
# print(tokenizer.word_index)
# train = tokenizer.texts_to_matrix(data[1])
train = tokenizer.texts_to_sequences(data[1])
train = sequence.pad_sequences(train,maxlen=max_len)4、 Model structures,
Use train_test_split Split the data set , And build a model
from tensorflow.keras.layers import *
from tensorflow.keras import Sequential
from tensorflow.keras.models import load_model
from tensorflow.keras import optimizers
from keras.utils import np_utils
from sklearn.model_selection import train_test_split
from tensorflow.keras.callbacks import ModelCheckpoint
import numpy as np
lable = np_utils.to_categorical(data[0], num_classes=12)
X_train, X_test, y_train, y_test = train_test_split(train, lable, test_size=0.1, random_state=200)
model = Sequential()
model.add(Embedding(num_words+1, 128, input_length=max_len))
model.add(LSTM(128,dropout=0.2, recurrent_dropout=0.2))
# model.add(Dense(64,activation="relu"))
# model.add(Dropout(0.2))
# model.add(Dense(32,activation="relu"))
# model.add(Dropout(0.2))
model.add(Dense(class_size,activation="softmax"))
# Load model
# model = load_model('my_model2.h5')
model.compile(optimizer = 'adam', loss='categorical_crossentropy',metrics=['accuracy'])
checkpointer = ModelCheckpoint("./model/model_{epoch:03d}.h5", verbose=0, save_best_only=False, save_weights_only=False, period=2)
model.fit(X_train, y_train, validation_data = (X_test, y_test), epochs=epochs, batch_size=batch_size, callbacks=[checkpointer])
# model.fit(X_train, y_train, validation_split = 0.2, shuffle=True, epochs=epochs, batch_size=batch_size, callbacks=[checkpointer])
model.save('my_model4.h5')
# print(model.summary())The training process is shown in the figure below :

5、 Visualization of model training results
import matplotlib.pyplot as plt
# Drawing training & Verified accuracy value
plt.plot(model.history.history['accuracy'])
plt.plot(model.history.history['val_accuracy'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
# Drawing training & Verified loss value
plt.plot(model.history.history['loss'])
plt.plot(model.history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()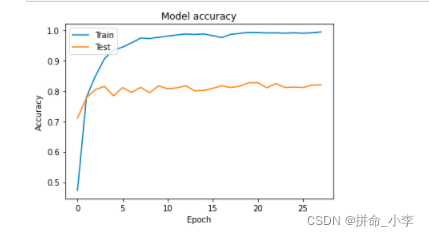
6、 Model to predict
text = " an exclusive news report Zhang ziyi The airport go ballistic Ben lover chart summary 6 month star Enrich On one side dedication love actively participate in Disaster relief The reconstruction Activities "
text = [" ".join([word for word in jieba.cut(text) if word not in cachedStopWords])]
# tokenizer = Tokenizer(num_words=num_words)
# tokenizer.fit_on_texts(text)
seq = tokenizer.texts_to_sequences(text)
padded = sequence.pad_sequences(seq, maxlen=max_len)
# np.expand_dims(padded,axis=0)
test_pre = test_model.predict(padded)
test_pre.argmax(axis=1)
7、 The code download
边栏推荐
- PLC模拟量输入 模拟量转换FB S_ITR(三菱FX3U)
- Uniapp uses Tencent map to select points without window monitoring to return users' location information. How to deal with it
- 杰理之蓝牙耳机品控和生产技巧【篇】
- 中通笔试题:翻转字符串,例如abcd打印出dcba
- ngnix基础知识
- TOPS,处理器运算能力单位、每秒钟可进行一万亿次
- vscode的使用
- Customize the insertion of page labels and realize the initial search of similar address books
- 《软件工程导论(第六版)》 张海藩 复习笔记
- 多个张量与多个卷积核做卷积运算的输出结果
猜你喜欢





随机推荐
Detailed explanation and code example of affinity propagation clustering calculation formula based on graph
功利点没啥!
matlab遍历图像、字符串数组等基本操作
深度学习 常见的损失函数
十三届蓝桥杯B组国赛
EMC-电路保护器件-防浪涌及冲击电流用
杰理之烧录上层版物料需要【篇】
2022年低压电工考试试题及答案
leetcode刷题:栈与队列03(有效的括号)
宅男壁纸大全微信小程序源码-带动态壁纸支持多种流量主
图片拼图微信小程序源码_支持多模板制作和流量主
三菱PLC FX3U脉冲轴点动功能块(MC_Jog)
How to connect the two nodes of the flow chart
小鸟逃票登机,如何反思,应如何解决,飞机为何怕小鸟?
An operation tool used by we media professionals who earn 1w+ a month
burpsuite简单抓包教程[通俗易懂]
测试撤销1
杰理之烧录都使用 VBAT 供电,供电电压 4.2V【篇】
TOPS,处理器运算能力单位、每秒钟可进行一万亿次
目標檢測——Yolo系列