当前位置:网站首页>14.实例-多分类问题
14.实例-多分类问题
2022-07-27 05:13:00 【派大星的最爱海绵宝宝】
使用交叉熵求loss来优化多分类问题
Network Architecture
输出是10层,代表着10分类。
因为还没有学习线性层知识,所以采用一些底层操作来代替。
新建三个线性层,每个线性层都有w和btensor
注意在pytorch中,第一个维度是out,第二个维度才是in
w1,b1 = torch.randn(200,784,requires_grad=True),torch.zeros(200,requires_grad=True)
w2,b2 = torch.randn(200,200,requires_grad=True),torch.zeros(200,requires_grad=True)
w3,b3 = torch.randn(10,200,requires_grad=True),torch.zeros(10,requires_grad=True)
第一个线性层可以理解为把784(28×28)降维成200。我们必须指定requires_grad为true,否则会报错。
第二个隐藏层从200到200,就是一个feature转变的过程,没有降维。
第三个输出层,最后输出10个类。
def forward(x):
x = x @ w1.t() + b1
x = F.relu(x)
x = x @ w2.t() + b2
x = F.relu(x)
x = x @ w3.t() + b3
x = F.relu(x)
return x
最后一层也可以不使用relu,不能使用sigmod或者softmax,因为后面还会使用softmax
这个就是网络tensor和forward过程,
Train
接下来定义一个优化器,优化的目标是3组全连接层的变量[w1,b1,w2,b2,w3,b3]
optimizer=optim.SGD([w1,b1,w2,b2,w3,b3],lr=learning_rate)
criteon=nn.CrossEntropyLoss()
crossEntropyLoss和F.crossEntropyLoss功能一样,都是softmax+log+nll_loss
for epoch in range(epochs):
for batch_idx,(data,target) in enumerate(train_loader):
data=data.view(-1,28*28)
logits=forward(data)
loss=criteon(logits,target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print('Train epoch:{}[{}/{} ({:.0f}%)]\tLoss:{:.6f}'.format(
epoch,batch_idx*len(data),len(train_loader.dataset),
100.*batch_idx/len(train_loader),loss.item()))
step是指一个batch,而eopch是整个数据集。
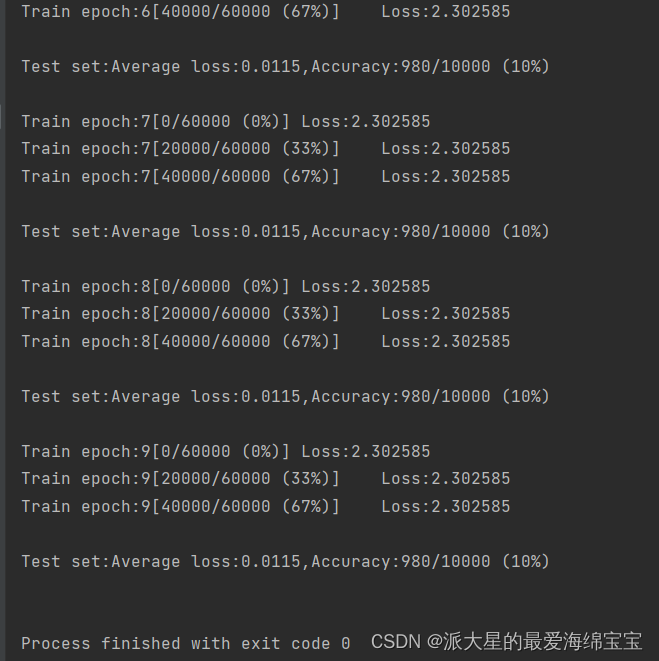
loss保持10%不变,是因为初始化问题
当我们对w1,w2,w3初始化后,b是直接torch.zeros初始化过了。
torch.nn.init.kaiming_normal(w1)
torch.nn.init.kaiming_normal(w2)
torch.nn.init.kaiming_normal(w3)
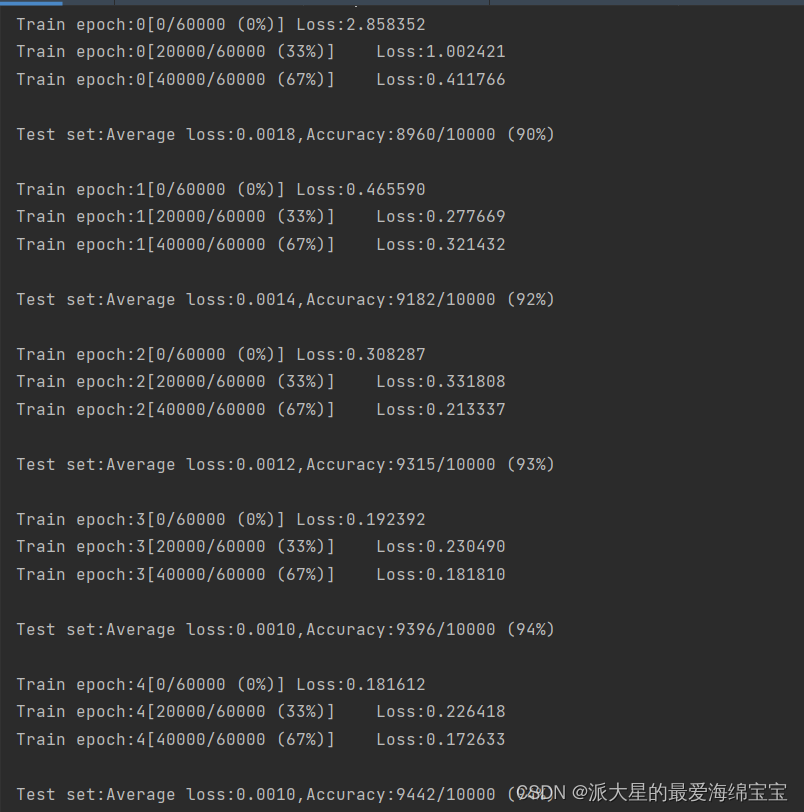
完整代码
import torch
import torch.nn.functional as F
from torch import optim
from torch import nn
import torchvision
batch_size = 200
learning_rate=0.01
epochs=10
train_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('mnist_data', train=True, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
# 把numpy格式转换成tensor
# 正则化,在0附近,可提升性能
test_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('mnist_data/', train=False, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=False)
w1,b1 = torch.randn(200,784,requires_grad=True),torch.zeros(200,requires_grad=True)
w2,b2 = torch.randn(200,200,requires_grad=True),torch.zeros(200,requires_grad=True)
w3,b3 = torch.randn(10,200,requires_grad=True),torch.zeros(10,requires_grad=True)
torch.nn.init.kaiming_normal(w1)
torch.nn.init.kaiming_normal(w2)
torch.nn.init.kaiming_normal(w3)
def forward(x):
x = x @ w1.t() + b1
x = F.relu(x)
x = x @ w2.t() + b2
x = F.relu(x)
x = x @ w3.t() + b3
x = F.relu(x)
return x
optimizer=optim.SGD([w1,b1,w2,b2,w3,b3],lr=learning_rate)
criteon=nn.CrossEntropyLoss()
for epoch in range(epochs):
for batch_idx,(data,target) in enumerate(train_loader):
data=data.view(-1,28*28)
logits=forward(data)
loss=criteon(logits,target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print('Train epoch:{}[{}/{} ({:.0f}%)]\tLoss:{:.6f}'.format(
epoch,batch_idx*len(data),len(train_loader.dataset),
100.*batch_idx/len(train_loader),loss.item()))
test_loss=0
correct=0
for data,target in test_loader:
data=data.view(-1,28*28)
logits=forward(data)
test_loss+=criteon(logits,target).item()
pred =logits.data.max(1)[1]
correct+=pred.eq(target.data).sum()
test_loss/=len(test_loader.dataset)
print('\nTest set:Average loss:{:.4f},Accuracy:{}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
边栏推荐
- 刷脸支付永远不会过时只会不断的变革
- Day 15. Deep learning radiomics can predict axillary lymphnode status in early-stage breast cancer
- Minio8.x version setting policy bucket policy
- NFT new opportunity, multimedia NFT aggregation platform okaleido will be launched soon
- 舆情&传染病时空分析文献阅读笔记
- 【mysql学习】8
- Amazon evaluation autotrophic number, how to carry out systematic learning?
- Move protocol launched a beta version, and you can "0" participate in p2e
- 新冠时空分析——Global evidence of expressed sentiment alterations during the COVID-19 pandemic
- Web3 traffic aggregation platform starfish OS interprets the "p2e" ecosystem of real business
猜你喜欢

How to apply for the return of futures account opening company?

How to choose a good futures company for futures account opening?

Choose futures companies with state-owned enterprise background to open accounts

你真的了解 Session 和 Cookie 吗?

Rating and inquiry details of futures companies

What are the conditions and procedures for opening crude oil futures accounts?

Mysql5.7版本如何实现主从同步
Do you really know session and cookies?

根据文本自动生成UML时序图(draw.io格式)

Okaleido launched the fusion mining mode, which is the only way for Oka to verify the current output
随机推荐
GBASE 8C——SQL参考6 sql语法(5)
How to open a general commodity futures account
Es time query error - "caused_by": {"type": "illegal_argument_exception", "reason": "failed to parse date field
【mysql学习】8
php 定义数组使用逗号,
Personal collection code cannot be used for business collection
Inno setup package jar + H5 + MySQL + redis into exe
Analyze the maker education DNA needed in the new era
When opening futures accounts, you should discuss the policy in detail with the customer manager
NFT new opportunity, multimedia NFT aggregation platform okaleido will be launched soon
Minio8.x version setting policy bucket policy
The LAF protocol elephant of defi 2.0 may be one of the few profit-making means in your bear market
Build a complete system in the maker education movement
Graph node deployment
Day14. 用可解释机器学习方法鉴别肠结核和克罗恩病
Day 6.重大医疗伤害事件网络舆情能量传播过程分析*———以“魏则西事件”为例
GBASE 8C——SQL参考6 sql语法(15)
Mysql分组后时并行统计数量
Sealem Finance - a new decentralized financial platform based on Web3
GBASE 8C——SQL参考6 sql语法(2)