当前位置:网站首页>Google and Stanford jointly issued a document: why do we have to use large models?
Google and Stanford jointly issued a document: why do we have to use large models?
2022-07-28 07:53:00 【Xixiaoyao】

writing | Harris
Language models have profoundly changed the research and practice in the field of natural language processing . In recent years , Big models have made important breakthroughs in many fields . They do not need to be fine tuned on downstream tasks , Excellent performance can be achieved through appropriate instructions or prompts , Sometimes it even makes people marvel . for example ,GPT-3 [1] You can write love letters 、 Write scripts and solve complex data mathematical reasoning problems ,PaLM [2] Can explain jokes . The above example is just the tip of the iceberg of large model capability , Now many applications have been developed with the ability of large models , stay OpenAI Website [3] You can see many related demo, But these abilities are rarely reflected in small models .
In this paper introduced today , The abilities that small models don't have but large models have are called Emergent ability (Emergent Abilities), Signification The ability acquired suddenly when the scale of the model is large to a certain extent . This is a process of quantitative change and qualitative change .
The emergence of emergence ability is difficult to predict . Why with the increase of scale , The model will suddenly acquire certain abilities It is still an open question , Further research is needed to answer . In this paper , The author combed some recent progress in understanding large models , And gives some related thoughts , I look forward to discussing with you .
Related papers :
Emergent Abilities of Large Language Models.http://arxiv.org/abs/2206.07682
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models.https://arxiv.org/abs/2206.04615
The emergence ability of large models
What is a big model ? What size is it “ Big ”? There is no clear definition . Generally speaking , Model parameters may need to reach the level of onebillion to show significantly different from small models zero-shot and few-shot The ability of . In recent years, there have been many models with parameters of hundreds of billions and trillions , In a series of tasks have been achieved SOTA The performance of the . In some missions , The performance of the model improves reliably with the increase of scale , In other tasks , The model shows a sudden improvement in performance on a certain scale . Two indicators can be used to classify different tasks [4]:
Linearity: It aims to measure the extent to which the performance of the model on the task has been reliably improved with the increase of scale .
Breakthroughness: It aims to measure the extent to which the task can be learned when the scale of the model exceeds the critical value .
These two indicators are a function of model size and model performance , For specific calculation details, please refer to [4]. The figure below shows some high Linearity And high Breakthroughness Examples of tasks .
high Linearity Most of our tasks are knowledge-based , That is to say, they mainly rely on the information in the memory training data , For example, answer some factual questions . Larger models are usually trained with more data , Can also remember more knowledge , Therefore, with the increase of the scale, the model shows a stable improvement in this kind of tasks . high Breakthroughness Tasks include more complex tasks , They need to use several different abilities or perform multiple steps to get the right answer , For example, mathematical reasoning . It is difficult for smaller models to obtain all the capabilities needed to perform such tasks . The following figure further shows the different models in some high Breakthroughness Mission performance 
Before reaching a certain model scale , The performance of the model on these tasks is random , After reaching a certain scale , There is a significant improvement .
Is it smooth or sudden ?
What we saw earlier is that when the scale of the model increases to a certain extent, it suddenly obtains some capabilities , In terms of task specific indicators , These abilities are emergent , But from another point of view , Potential changes in model capabilities are smoother . This paper discusses the following two perspectives :(1) Use smoother metrics ;(2) Decompose complex tasks into multiple subtasks .
The figure below (a) Shows some high Breakthroughness The change curve of the logarithmic probability of the real target of the task , The logarithmic probability of the real target increases gradually with the increase of the model size .
chart (b) Explicitly for a multiple-choice task , As the scale of the model increases , The logarithmic probability of the correct answer gradually increases , The logarithmic probability of the wrong answer increases gradually before a certain scale , After that, it tends to be flat . After this scale , The gap between the probability of correct answer and the probability of wrong answer widens , Thus, the performance of the model has been significantly improved .
Besides , For a particular task , Suppose we can use Exact Match and BLEU To evaluate the performance of the model ,BLEU Compared with Exact Match Is a smoother indicator , There may be significant differences in the trends seen using different indicators .
For some tasks , The model may acquire part of the ability to do this task on different scales . The following figure is through a string emoji The task of guessing the name of the movie  We can see that the model starts to guess the movie name at some scale , Recognize the semantics of emoticons on a larger scale , Produce the right answer on the largest scale .
We can see that the model starts to guess the movie name at some scale , Recognize the semantics of emoticons on a larger scale , Produce the right answer on the largest scale .
Large models are sensitive to how to formalize tasks
The scale of the model reflects the sudden ability improvement also depends on how to formalize the task . for example , On complex mathematical reasoning tasks , standards-of-use prompting Think of it as a question and answer task , The performance improvement is very limited when the scale of the model increases , And if the following figure is used chain-of-thought prompting [5], Think of it as a multi-step reasoning task , You will see a significant performance improvement on a specific scale .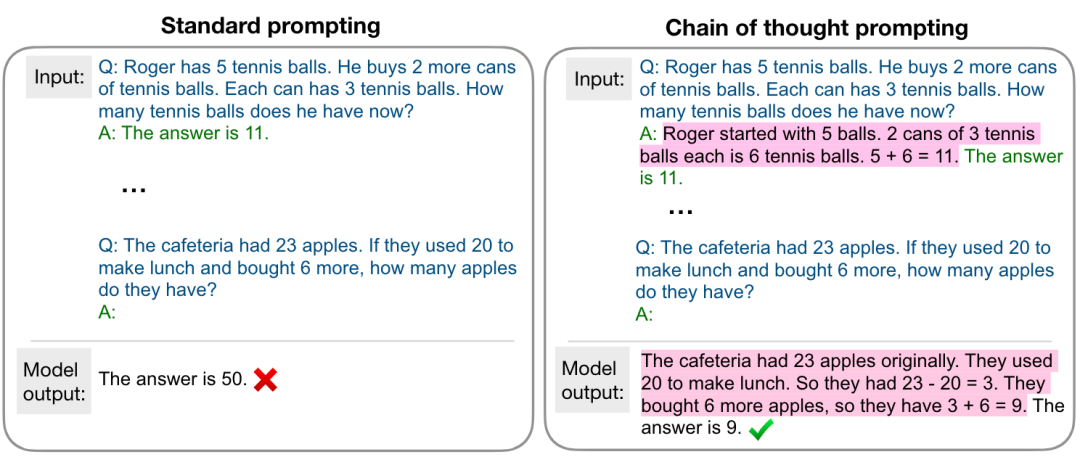

What is more , Researchers found that by adding a simple hint “Let’s think step by step”, Can greatly improve GPT-3 Of zero-shot Reasoning power [6], As shown in the figure below 
The inspiration for us is , Sometimes big models can't do a task well , Maybe it's not really bad , Instead, it needs appropriate ways to stimulate its ability .
Is the bigger the model, the stronger ?
The intuitive feeling given by the previous discussion is that the performance of the model must be improved when it becomes larger , But is it true ? actually , For some tasks , The performance may decline after the model becomes larger , As shown in the figure below 
Several researchers from New York University also organized a competition , It aims to find tasks that perform worse when the model gets bigger .
For example, in the question and answer task , If you add your faith to the question , Large models are more susceptible . Interested students can pay attention to .
Summary and reflection
On most tasks , As the scale of the model increases , The better the performance of the model , But there will also be some counter examples . More research is needed to better understand such behavior in the model .
The ability of large models needs appropriate ways to stimulate .
Is the big model really reasoning ? As we saw before , By adding hints “Let’s think step by step”, The large model can carry out multi-step reasoning on the mathematical reasoning task and achieve satisfactory results , It seems that the model already has human reasoning ability . however , This is shown below , If GPT-3 A meaningless question , Let it do multi-step reasoning ,GPT-3 It seems to be reasoning , In fact, it is some meaningless output . As the saying goes “garbage in, garbage out”. By comparison , Human beings can judge whether the problem is reasonable , That is to say, under given conditions , Is the current question answerable .“Let’s think step by step” Can play a role , I think the root cause is GPT-3 I have seen many similar data during the training , What it does is just based on the previous token To predict the next token only , It is still fundamentally different from the way humans think . Of course , If you give the appropriate prompt, let GPT-3 To judge whether the problem is reasonable, maybe it can do it to some extent , But distance “ reflection ” and “ Reasoning ” I'm afraid there is still a considerable distance , This cannot be solved simply by increasing the scale of the model . Models may not need to think like humans , But more research is urgently needed to explore ways other than increasing the scale of the model .

System 1 Or the system 2? The human brain has two systems that work together , System 1( intuition ) It's fast 、 Automated , And the system 2( rational ) It's slow 、 A controlled . A large number of experiments have proved , People prefer to use intuition to make judgments and decisions , And reason can correct the errors caused by it . Most current models are based on systems 1 Or the system 2 Design , Can we design future models based on dual systems ?
Query language in the age of big model . Previously, we stored knowledge and data in databases and knowledge maps , We can use SQL Query relational database , You can use SPARQL Go to the knowledge map , What query language do we use to call the knowledge and ability of the big model ?
Mr. Mei Yiqi once said “ The so-called University , It's not a building , There is a great master ”, The author ends this article with an inappropriate analogy : The so-called big model , It is said that there are parameters , It's called being able .
Backstage reply key words 【 The group of 】
Join selling cute house NLP、CV、 Search promotion and job search discussion groups
[1] Language Models are Few-Shot Learners. https://arxiv.org/abs/2005.14165
[2] PaLM: Scaling Language Modeling with Pathways. https://arxiv.org/abs/2204.02311
[3] https://gpt3demo.com/
[4] Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models. https://arxiv.org/abs/2206.04615
[5] Chain of Thought Prompting Elicits Reasoning in Large Language Models. https://arxiv.org/abs/2201.11903
[6] Large Language Models are Zero-Shot Reasoners. https://arxiv.org/abs/2205.11916

边栏推荐
- Retryer of guava
- How to understand the adjective prefix of socket: "connection oriented" and "connectionless"
- Dynamic memory management knowledge points
- User mode vs kernel mode, process vs thread
- DNA修饰金属铑Rh纳米颗粒RhNPS-DNA(DNA修饰贵金属纳米颗粒)
- Discrimination coverage index / index coverage / Samsung index
- Summary of RFID radiation test
- Analysis of collector principle
- 0727~ sorting out interview questions
- Synthesis of dna-ag2sqds DNA modified silver sulfide Ag2S quantum dots
猜你喜欢

Tutorial (7.0) 06. Zero trust network access ztna * forticlient EMS * Fortinet network security expert NSE 5

辨析覆盖索引/索引覆盖/三星索引

DNA修饰金属铑Rh纳米颗粒RhNPS-DNA(DNA修饰贵金属纳米颗粒)

和为s的两个数字——每日两题

5g commercial third year: driverless "going up the mountain" and "going to the sea"

Disassemble Huawei switches and learn Basic EMC operations

使用FFmpeg来批量生成单图+单音频的一图流视频
![[shaders realize negative anti color effect _shader effect Chapter 11]](/img/c5/70761374330eb4fb3915c335b7efb8.png)
[shaders realize negative anti color effect _shader effect Chapter 11]

ASP.NET Core 技术内幕与项目实战读后感

Copper indium sulfide CuInSe2 quantum dots modified DNA (deoxyribonucleic acid) DNA cuinse2qds (Qiyue)
随机推荐
[solution] visual full link log tracking - log tracking system
cdn.jsdelivr.net不可用,该怎么办
Introduction to magnetic ring selection and EMC rectification skills
RFID辐射测试小结
Disassemble Huawei switches and learn Basic EMC operations
Deeply analyze the implementation of singleton mode
2022/7/27 考试总结
mysql,可以使用多少列创建索引?
CLion调试redis6源码
ESD静电不用怕,本文告诉你一些解决方法
EMC rectification method set
Synthesis of dna-ag2sqds DNA modified silver sulfide Ag2S quantum dots
EMC问题的根源在哪?
Modify the conf file through sed
EMC design strategy - clock
Isolation level RR, gap lock, unreal reading
干货|分享一个EMC实际案例及整改过程
合并两个排序的链表——每日两题
ArcGIS JS customizes the accessor and uses the watchutils related method to view the attribute
Summary of project experience