当前位置:网站首页>时间序列的数据分析(二):数据趋势的计算
时间序列的数据分析(二):数据趋势的计算
2022-07-23 05:43:00 【-派神-】
四,时间序列的分解
由于季节性成份分为加法季节性和乘法季节性,加法季节性和时间没有关系,乘法季节性和时间存在线性关系,因此在分解时间序列数据时就分为加法分解和乘法分解两种方式,假如时间序列数据呈现出加法季节性特征,那么数据中任意时刻t的值可以由季节性,趋势和残差相加得到:

在上式中 y(t)表示时间序列数据,S(t)表示季节项,T(t)表示趋势项-周期项,R(t)表示残差项。
假如时间序列数据呈现出乘法季节性特征,那么数据中任意时刻t的值可以由季节性,趋势和残差相乘得到:

4.1, 趋势的计算
我们希望时间序列数据的趋势曲线尽量呈现为一条平滑的曲线,传统的时间序列分解方法的第一步是用移动平均的方法估计趋势-周期项
4.1.1简单移动平均
m 阶移动平均可以定义为:

其中,m=2k+1。也就是说,时间点 t 的趋势的估计值是通过求 t 时刻的值±k个时刻周期内的平均值得到的。时间邻近的情况下,观测值也很可能接近。由此,平均值消除了数据中的一些随机性,从而我们可以得到较为平滑的趋势周期项,我们称它为“m-MA”,也就是m阶移动平均。下面我们看一下澳大利亚历年货物出口总量数据的趋势图,然后来分析一下不同阶数的移动平均的趋势变化。
import pandas as pd
df = pd.read_csv("Australia_economy.csv")
df = df[['Year','Exports']].set_index('Year')
df.plot(xlabel='Year',
ylabel='% of GDP',
title='Total Australian exports',
figsize=(10,6));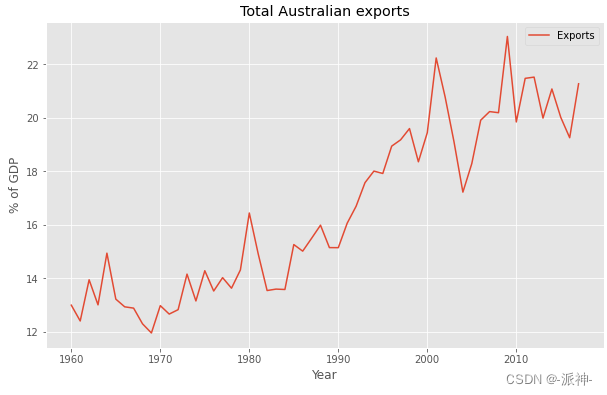
下面我们观察一下5阶移动平均线:
df = pd.read_csv("Australia_economy.csv")
df = df[['Year','Exports']].set_index('Year')
#产生5阶移动平均
order1=5
df[str(order1)+'-MA']=df['Exports'].rolling(window=order1).mean().shift(-int((order1-1)/2))
#可视化
df.plot(xlabel='Year',
ylabel='% of GDP',
title='5-MA',
figsize=(6,5));
我们观察到在5-MA这一列在1960和1961这两年的值为空,这是因为m=2k+1,为了保持数据的对称性,我们让数据集的头和尾都保留了k条空值数据,这里m等于5所以k=2,因此数据集的头和尾都有2条空值数据(尾部空值数据没有展示出来)。python在实现移动平均的对称效果时使用的是pandas的rolling和shift方法,首先通过rolling和mean来实现移动平均,然后使用shift来实现数据对称。同样我们可以画出3-MA,5-MA,7-MA,9-MA的移动平均线来进行对比它们直接的趋势变化:


从上图中我们观察到当m越来越大时,移动平均线越来越趋于平滑, 移动平均的阶数决定了趋势-周期项的平滑程度。一般情况下,阶数越大曲线越平滑。简单移动平均的阶数常常是奇数阶(例如3,5,7等),这样可以确保对称性。在阶数为m=2k+1的移动平均中,中心观测值和两侧各有k个观测值可以被平均。但是如果 m是偶数,那么它就不再具备对称性。
4.1.2偶数阶移动平均
当时间序列数据呈现出偶数阶趋势变化时(如季度:4,月度:12),简单移动平均“m-MA”无法保持数据的对称性,为了实现数据对称性我们需要在m-MA的基础上再做一次2阶移动平均,该方法称为"2×m-MA",下面我们看一下澳大利亚历年啤酒产量的数据,该数据集记录了澳大利亚历年每季度啤酒的产量,因为一年有4个季度,所以在这里我们要实现一个偶数阶的移动平均,具体步骤是首先实现一个偶数阶(4)的移动平均,因为偶数阶的移动平均的结果是不对称的,为了让数据实现对称性我们需要在偶数阶移动平均的基础上再做一次2阶的移动平均即2×m-MA,下面我们首先查看一下该数据的趋势图,然后我们再来实现2×m-MA的移动平均:
df=pd.read_csv('ausbeer2.csv')
df = df[df.date>='1992-01-01']
df.plot(x='date',y='Production',figsize=(10,6),ylabel='Production');
#实现4-MA移动平均
order=4
df[str(order)+'-MA']=df['Production'].rolling(window=order).mean().shift(-int(order/2))
#实现2×4-MA"移动平均
df['2×4-MA']=df['4-MA'].rolling(window=2).mean()
从上图结果中可以看出4-MA结果是不对称的(头部有1条空值数据,尾部有2条空值数据),而2×4-MA的结果是对称的(头部尾部各有2条空值数据)。数据的最后一列2×4 -MA的作用是在进行4-MA后再进行2-MA。最后一列的值是由前一列数据进行2阶移动平均后得到的。4-MA列中最前面两个值为: 451.25=(443+410+420+532)/4 和 448.75=(410+420+532+433)/4. 而2x4-MA列的第一个值是这两者的平均: 450.00=(451.25+448.75)/2.我们可以将 2×4-MA写为如下形式:

一般来讲,进行偶数阶的移动平均后应该再进行一个偶数阶移动平均使其对称。这里我们观察到 2×4-MA的结果:

在之前奇数阶(m-MA)的移动平均的方法中各个观测值的权重都是相等的它们都是1/m, 然而在偶数阶(2×m-MA)移动平均方法中除了收尾测值的权重是 1/(2m),其他观测值的权重都是 1/m,以上面2×4-MA例子来说,各个观测值的权重为:[1/8,1/4,1/4,1/4,1/8]它们对应5个观测值。由此可知偶数阶的移动平均可以转换为加权的奇数阶的移动平均即2×m-MA<==>(m+1)-MA。一般来讲,加权 m-MA 可以写为:
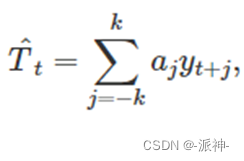
在上式中k=(m-1)/2,其权重为: [1/(2m), 1/m……1/m, 1/(2m)] 且所有权重之和为1,并且它们是对称的。
4.1.3 为什么要加权
这里的加权是指一组观测值被加了不相等的权重值,那为什么要给各观测值添加不同的权重值呢?在上面澳大利亚啤酒产量的数据集中,数据的时间刻度是季度,一年有4个季度,因此要通过偶数阶的移动平均来得到趋势-周期项,然而2×4-MA却要对连续的5个观测值进行加权,前4个观测值被认为是同一年中的4个季度,第5个观测值对于第二年的第一个季度,在5个权重值中首尾两个权重值较小为1/(2m),其他权重值为1/m, 收尾权重值较小这样可以减小连续年份内数据出现的波动在这里可以理解为防止第二年第一季度出现较大的数据波动,这样较小的权重值可以使趋势曲线更加平滑。
4.2 总结
在这一章里我们了解了时间序列分解方法有加法分解和乘法分解,可以通过移动平均来计算数据的趋势,移动平均又可以分为简单移动平均(奇数阶)和偶数阶移动平均,简单移动平均的结果是对称的,偶数阶移动平均的结果是不对称的,为此还要再进行一次偶数阶移动平均才能让数据对称,同样偶数阶移动平均2×m-MA可以转换成奇数阶移动平均(m+1)-MA,并且权重为: [1/(2m), 1/m……1/m, 1/(2m)],其中首尾权重值较小是为了克服连续年份内数据波动对趋势带来影响,并使趋势曲线更加平滑。
边栏推荐
- Hard disk partition of obsessive-compulsive disorder
- 抽象类和接口有什么区别?
- Mysql database
- Rondom总结
- 分治与递归(练习题)
- Solution to schema verification failure in saving substantive examination request
- Nt68661 screen parameter upgrade-rk3128-start up and upgrade screen parameters yourself
- 3D image classification of lung CT scan using propeller
- Linked list related interview questions
- MySQL user management
猜你喜欢

Build "green computing" and interpret "Intelligent Computing Center"

可能逃不了课了!如何使用paddleX来点人头?

High level API of propeller to realize face key point detection

The green data center "counting from the east to the west" was fully launched

数字经济“双碳”目标下,“东数西算”数据中心为何依靠液冷散热技术节能减排?

“东数西算”下数据中心的液冷GPU服务器如何发展?

论文解读:《功能基因组学transformer模型的可解释性》

时间序列的数据分析(三):经典时间序列分解

Necessary mathematical knowledge for machine learning / deep learning

Definition and application of method
随机推荐
Linked list related interview questions
使用飞桨实现肺部 CT 扫描的 3D 图像分类
循环队列
双端队列
二叉树
论文解读:《Deep-4mcw2v: 基于序列的预测器用于识别大肠桿菌中的 N4- 甲基胞嘧啶(4mC)位点》
Chaoslibrary · UE4 pit opening notes
使用pycaret来进行数据挖掘:关联规则挖掘
使用makefile编译ninja
Pytoch personal record (do not open)
Iterative display of.H5 files, h5py data operation
MySQL backup
笔记 | 百度飞浆AI达人创造营:数据获取与处理(以CV任务为主)
opencv库安装路径(别打开这个了)
链栈
机器学习/深度学习必备数学知识
How to develop the computing power and AI intelligent chips in the data center of "digital computing in the East and digital computing in the west"?
利用pycaret:低代码,自动化机器学习框架解决分类问题
Chain stack
Build "green computing" and interpret "Intelligent Computing Center"