当前位置:网站首页>Flink1.15源码阅读flink-clients——flink命令行帮助命令
Flink1.15源码阅读flink-clients——flink命令行帮助命令
2022-07-31 08:56:00 【京河小蚁】
flink 命令行详解
[[email protected] bin]# ./flink --help
run
./flink <ACTION> [OPTIONS] [ARGUMENTS]
The following actions are available:
Action "run" compiles and runs a program.
# 这里可以看到run后面跟着的参数
Syntax: run [OPTIONS] <jar-file> <arguments>
"run" action options:
# -c 后面跟用户代码的主类名,后面描述说的也非常清楚了,使用程序入口点("main()"方法)初始化。只有当JAR文件没有在其清单中指定类时才需要(也就是说你打包的时候如果主类没指定)。
-c,--class <classname> Class with the program entry
point ("main()" method). Only
needed if the JAR file does not
specify the class in its
manifest.
# -C 向集群中所有节点上的每个用户代码类加载器添加一个URL。路径必须指定一个协议(例如file://),并且在所有节点上都可以访问(例如通过NFS共享)。您可以多次使用此选项来指定多个URL。协议必须由{@link支持java.net.URLClassLoader}。
-C,--classpath <url> Adds a URL to each user code
classloader on all nodes in the
cluster. The paths must specify
a protocol (e.g. file://) and be
accessible on all nodes (e.g. by
means of a NFS share). You can
use this option multiple times
for specifying more than one
URL. The protocol must be
supported by the {
@link
java.net.URLClassLoader}.
# -d 分离模式,如果不指定分离模式,客户端会在提交作业的节点启动一个程序客户端进程并与集群交互,生产上一般都是分离模式
-d,--detached If present, runs the job in
detached mode
# -n 允许跳过无法恢复的保存点状态。如果您从程序中删除了一个在触发保存点时是程序一部分的operator即算子,则需要允许这样做。
-n,--allowNonRestoredState Allow to skip savepoint state
that cannot be restored. You
need to allow this if you
removed an operator from your
program that was part of the
program when the savepoint was
triggered.
# -p 运行程序的并行度。可选标志,用来覆盖配置中指定的默认值。
-p,--parallelism <parallelism> The parallelism with which to
run the program. Optional flag
to override the default value
specified in the configuration.
# -py 带有程序入口点的Python脚本。依赖的资源可以使用'--pyFiles '选项配置。
-py,--python <pythonFile> Python script with the program
entry point. The dependent
resources can be configured with
the `--pyFiles` option.
# -pyarch 为job添加python存档文件。存档文件将被解压缩到python UDF worker的工作目录。对于每个存档文件,都要指定一个目标目录。如果指定了目标目录名,则归档文件将被解压缩到具有指定名称的目录中。否则,归档文件将被解压缩到与归档文件同名的目录中。通过该选项上传的文件可以通过相对路径访问。'#'可以用作存档文件路径和目标目录名的分隔符。逗号(',')可以用作分隔符来指定多个归档文件。这个选项可以用来上传虚拟环境,Python UDF中使用的数据文件(例如 --pyArchives file:///tmp/py37.zip,file:///tmp /data.zip#data --pyExecutable py37.zip/py37/bin/ Python)。数据文件可以在Python UDF中访问,例如:f = open('data/data.txt', 'r')。
-pyarch,--pyArchives <arg> Add python archive files for
job. The archive files will be
extracted to the working
directory of python UDF worker.
For each archive file, a target
directory be specified. If the
target directory name is
specified, the archive file will
be extracted to a directory with
the specified name. Otherwise,
the archive file will be
extracted to a directory with
the same name of the archive
file. The files uploaded via
this option are accessible via
relative path. '#' could be used
as the separator of the archive
file path and the target
directory name. Comma (',')
could be used as the separator
to specify multiple archive
files. This option can be used
to upload the virtual
environment, the data files used
in Python UDF (e.g.,
--pyArchives
file:///tmp/py37.zip,file:///tmp
/data.zip#data --pyExecutable
py37.zip/py37/bin/python). The
data files could be accessed in
Python UDF, e.g.: f =
open('data/data.txt', 'r').
# -pyclientexec 通过“flink run”提交Python任务或编译包含Python udf的Java/Scala任务时,Python解释器用于启动Python进程的路径。
-pyclientexec,--pyClientExecutable <arg> The path of the Python
interpreter used to launch the
Python process when submitting
the Python jobs via "flink run"
or compiling the Java/Scala jobs
containing Python UDFs.
# -pyexec 指定用于执行python UDF工作器的python解释器的路径(例如:--pyExecutable /usr/local/bin/python3)。python UDF工作程序依赖于python 3.6+、Apache Beam(版本== 2.27.0)、Pip(版本>= 7.1.0)和SetupTools(版本>= 37.0.0)。请确保指定的环境符合上述要求。
-pyexec,--pyExecutable <arg> Specify the path of the python
interpreter used to execute the
python UDF worker (e.g.:
--pyExecutable
/usr/local/bin/python3). The
python UDF worker depends on
Python 3.6+, Apache Beam
(version == 2.27.0), Pip
(version >= 7.1.0) and
SetupTools (version >= 37.0.0).
Please ensure that the specified
environment meets the above
requirements.
# -pyfs 附加作业的自定义文件。标准资源文件的后缀是.py/.egg/.zip/。支持WHL或目录。这些文件将被添加到本地客户端和远程python UDF worker的PYTHONPATH中。以.zip后缀的文件将被提取并添加到PYTHONPATH中。逗号(',')可以作为分隔符来指定多个文件(例如--pyFiles file:///tmp/myresource.zip,hdfs: ///$namenode_address/myresource2 .zip)。
-pyfs,--pyFiles <pythonFiles> Attach custom files for job. The
standard resource file suffixes
such as .py/.egg/.zip/.whl or
directory are all supported.
These files will be added to the
PYTHONPATH of both the local
client and the remote python UDF
worker. Files suffixed with .zip
will be extracted and added to
PYTHONPATH. Comma (',') could be
used as the separator to specify
multiple files (e.g., --pyFiles
file:///tmp/myresource.zip,hdfs:
///$namenode_address/myresource2
.zip).
# -pym 带有程序入口点的Python模块。此选项必须与'——pyFiles '一起使用。
-pym,--pyModule <pythonModule> Python module with the program
entry point. This option must be
used in conjunction with
`--pyFiles`.
# -pyreq 指定一个requirements.txt文件,它定义了第三方的依赖关系。这些依赖项将被安装并添加到python UDF worker的PYTHONPATH中。可以有选择地指定包含这些依赖项的安装包的目录。如果可选参数存在,使用'#'作为分隔符(例如--pyRequirements file:///tmp/requirements.txt#fil e:///tmp/cached_dir)。
-pyreq,--pyRequirements <arg> Specify a requirements.txt file
which defines the third-party
dependencies. These dependencies
will be installed and added to
the PYTHONPATH of the python UDF
worker. A directory which
contains the installation
packages of these dependencies
could be specified optionally.
Use '#' as the separator if the
optional parameter exists (e.g.,
--pyRequirements
file:///tmp/requirements.txt#fil
e:///tmp/cached_dir).
# -rm 定义如何从给定的保存点进行恢复。支持的选项:[claim -声明保存点的所有权,一旦它被包含就删除,no_claim(默认)-不声明所有权,第一个检查点不会重用恢复的任何文件,legacy -旧的行为,不承担保存点文件的所有权,但可以重用一些共享文件。
-rm,--restoreMode <arg> Defines how should we restore
from the given savepoint.
Supported options: [claim -
claim ownership of the savepoint
and delete once it is subsumed,
no_claim (default) - do not
claim ownership, the first
checkpoint will not reuse any
files from the restored one,
legacy - the old behaviour, do
not assume ownership of the
savepoint files, but can reuse
some shared files.
# -s 恢复任务的保存点路径(例如hdfs:///flink/savepoint-1537)。
-s,--fromSavepoint <savepointPath> Path to a savepoint to restore
the job from (for example
hdfs:///flink/savepoint-1537).
# -sae 如果作业是在附加模式下提交的,那么当CLI突然终止时,执行最大努力的集群关闭,例如,响应用户中断,例如输入Ctrl + C。
-sae,--shutdownOnAttachedExit If the job is submitted in
attached mode, perform a
best-effort cluster shutdown
when the CLI is terminated
abruptly, e.g., in response to a
user interrupt, such as typing
Ctrl + C.
上面介绍了flink run相关的命令,下面是客户端模式,分为三种GenericCLI 、FlinkYarnSessionCLI和DefaultCLI。
GenericCLI
Options for Generic CLI mode:
# -D 允许指定多个通用配置选项。可以在https://nightlies.apache.org/flink/flink-docs-stable/ ops/config.html上找到可用的选项
-D <property=value> Allows specifying multiple generic configuration
options. The available options can be found at
https://nightlies.apache.org/flink/flink-docs-stable/
ops/config.html
# -e 已弃用:请使用-t选项,该选项在"Application Mode"中也可用。用于执行给定作业的执行程序的名称,相当于"execution.target"配置选项。当前可用的执行器有:"remote", "local", "kubernetes-session", "yarn-per-job"(已弃用),"yarn-session"。
-e,--executor <arg> DEPRECATED: Please use the -t option instead which is
also available with the "Application Mode".
The name of the executor to be used for executing the
given job, which is equivalent to the
"execution.target" config option. The currently
available executors are: "remote", "local",
"kubernetes-session", "yarn-per-job" (deprecated),
"yarn-session".
# -t 给定应用程序的部署目标,相当于"execution.target"配置选项。对于"run"操作,当前可用的目标是:“remote”,“local”,“kubernetes-session”,“yarn-per-job”(已弃用),“yarn-session”。对于“run-application”操作,当前可用的目标是:“kubernetes-application”。
-t,--target <arg> The deployment target for the given application,
which is equivalent to the "execution.target" config
option. For the "run" action the currently available
targets are: "remote", "local", "kubernetes-session",
"yarn-per-job" (deprecated), "yarn-session". For the
"run-application" action the currently available
targets are: "kubernetes-application".
FlinkYarnSessionCLI
Options for yarn-cluster mode:
# -m 设置为YARN -cluster使用YARN执行模式。
-m,--jobmanager <arg> Set to yarn-cluster to use YARN execution
mode.
# -yid 附加到正在运行的YARN会话
-yid,--yarnapplicationId <arg> Attach to running YARN session
# -z 高可用模式下,创建Zookeeper子路径
-z,--zookeeperNamespace <arg> Namespace to create the Zookeeper
sub-paths for high availability mode
DefaultCLI
Options for default mode:
# -D 允许指定多个通用配置选项。可以在https://nightlies.apache.org/flink/flink-do cs-stable/ops/config.html找到可用的选项
-D <property=value> Allows specifying multiple generic
configuration options. The available
options can be found at
https://nightlies.apache.org/flink/flink-do
cs-stable/ops/config.html
# -m 连接到的JobManager的地址。使用这个标志可以连接到配置中指定的不同的JobManager。注意:只有在高可用性配置为NONE时才会考虑此选项。
-m,--jobmanager <arg> Address of the JobManager to which to
connect. Use this flag to connect to a
different JobManager than the one specified
in the configuration. Attention: This
option is respected only if the
high-availability configuration is NONE.
# -z 高可用模式下,创建Zookeeper子路径
-z,--zookeeperNamespace <arg> Namespace to create the Zookeeper sub-paths
for high availability mode
run-application
Action "run-application" runs an application in Application Mode.
Syntax: run-application [OPTIONS] <jar-file> <arguments>
Options for Generic CLI mode:
-D <property=value> Allows specifying multiple generic configuration
options. The available options can be found at
https://nightlies.apache.org/flink/flink-docs-stable/
ops/config.html
-e,--executor <arg> DEPRECATED: Please use the -t option instead which is
also available with the "Application Mode".
The name of the executor to be used for executing the
given job, which is equivalent to the
"execution.target" config option. The currently
available executors are: "remote", "local",
"kubernetes-session", "yarn-per-job" (deprecated),
"yarn-session".
# 给定应用程序的部署目标,相当于"execution.target"配置选项。对于“run”操作,当前可用的目标是:“remote”,“local”,“kubernetes-session”,“yarn-per-job”(已弃用),“yarn-session”。对于“run-application”操作,当前可用的目标是:“kubernetes-application”。
-t,--target <arg> The deployment target for the given application,
which is equivalent to the "execution.target" config
option. For the "run" action the currently available
targets are: "remote", "local", "kubernetes-session",
"yarn-per-job" (deprecated), "yarn-session". For the
"run-application" action the currently available
targets are: "kubernetes-application".
info
# 操作"info"显示了程序的优化执行计划(JSON)。
Action "info" shows the optimized execution plan of the program (JSON).
Syntax: info [OPTIONS] <jar-file> <arguments>
"info" action options:
-c,--class <classname> Class with the program entry point
("main()" method). Only needed if the JAR
file does not specify the class in its
manifest.
-p,--parallelism <parallelism> The parallelism with which to run the
program. Optional flag to override the
default value specified in the
configuration.
list
# 操作"list"列出正在运行和计划的程序.
Action "list" lists running and scheduled programs.
Syntax: list [OPTIONS]
"list" action options:
-a,--all Show all programs and their JobIDs
-r,--running Show only running programs and their JobIDs
-s,--scheduled Show only scheduled programs and their JobIDs
Options for Generic CLI mode:
-D <property=value> Allows specifying multiple generic configuration
options. The available options can be found at
https://nightlies.apache.org/flink/flink-docs-stable/
ops/config.html
-e,--executor <arg> DEPRECATED: Please use the -t option instead which is
also available with the "Application Mode".
The name of the executor to be used for executing the
given job, which is equivalent to the
"execution.target" config option. The currently
available executors are: "remote", "local",
"kubernetes-session", "yarn-per-job" (deprecated),
"yarn-session".
-t,--target <arg> The deployment target for the given application,
which is equivalent to the "execution.target" config
option. For the "run" action the currently available
targets are: "remote", "local", "kubernetes-session",
"yarn-per-job" (deprecated), "yarn-session". For the
"run-application" action the currently available
targets are: "kubernetes-application".
Options for yarn-cluster mode:
-m,--jobmanager <arg> Set to yarn-cluster to use YARN execution
mode.
-yid,--yarnapplicationId <arg> Attach to running YARN session
-z,--zookeeperNamespace <arg> Namespace to create the Zookeeper
sub-paths for high availability mode
Options for default mode:
-D <property=value> Allows specifying multiple generic
configuration options. The available
options can be found at
https://nightlies.apache.org/flink/flink-do
cs-stable/ops/config.html
-m,--jobmanager <arg> Address of the JobManager to which to
connect. Use this flag to connect to a
different JobManager than the one specified
in the configuration. Attention: This
option is respected only if the
high-availability configuration is NONE.
-z,--zookeeperNamespace <arg> Namespace to create the Zookeeper sub-paths
for high availability mode
stop
# 动作"stop"用一个保存点(仅流作业)停止正在运行的程序。
Action "stop" stops a running program with a savepoint (streaming jobs only).
Syntax: stop [OPTIONS] <Job ID>
"stop" action options:
-d,--drain Send MAX_WATERMARK before taking the
savepoint and stopping the pipelne.
-p,--savepointPath <savepointPath> Path to the savepoint (for example
hdfs:///flink/savepoint-1537). If no
directory is specified, the configured
default will be used
("state.savepoints.dir").
-type,--type <arg> Describes the binary format in which a
savepoint should be taken. Supported
options: [canonical - a common format
for all state backends, allow for
changing state backends, native = a
specific format for the chosen state
backend, might be faster to take and
restore from.
Options for Generic CLI mode:
-D <property=value> Allows specifying multiple generic configuration
options. The available options can be found at
https://nightlies.apache.org/flink/flink-docs-stable/
ops/config.html
-e,--executor <arg> DEPRECATED: Please use the -t option instead which is
also available with the "Application Mode".
The name of the executor to be used for executing the
given job, which is equivalent to the
"execution.target" config option. The currently
available executors are: "remote", "local",
"kubernetes-session", "yarn-per-job" (deprecated),
"yarn-session".
-t,--target <arg> The deployment target for the given application,
which is equivalent to the "execution.target" config
option. For the "run" action the currently available
targets are: "remote", "local", "kubernetes-session",
"yarn-per-job" (deprecated), "yarn-session". For the
"run-application" action the currently available
targets are: "kubernetes-application".
Options for yarn-cluster mode:
-m,--jobmanager <arg> Set to yarn-cluster to use YARN execution
mode.
-yid,--yarnapplicationId <arg> Attach to running YARN session
-z,--zookeeperNamespace <arg> Namespace to create the Zookeeper
sub-paths for high availability mode
Options for default mode:
-D <property=value> Allows specifying multiple generic
configuration options. The available
options can be found at
https://nightlies.apache.org/flink/flink-do
cs-stable/ops/config.html
-m,--jobmanager <arg> Address of the JobManager to which to
connect. Use this flag to connect to a
different JobManager than the one specified
in the configuration. Attention: This
option is respected only if the
high-availability configuration is NONE.
-z,--zookeeperNamespace <arg> Namespace to create the Zookeeper sub-paths
for high availability mode
cancel
Action "cancel" cancels a running program.
Syntax: cancel [OPTIONS] <Job ID>
"cancel" action options:
-s,--withSavepoint <targetDirectory> **DEPRECATION WARNING**: Cancelling
a job with savepoint is deprecated.
Use "stop" instead.
Trigger savepoint and cancel job.
The target directory is optional. If
no directory is specified, the
configured default directory
(state.savepoints.dir) is used.
Options for Generic CLI mode:
-D <property=value> Allows specifying multiple generic configuration
options. The available options can be found at
https://nightlies.apache.org/flink/flink-docs-stable/
ops/config.html
-e,--executor <arg> DEPRECATED: Please use the -t option instead which is
also available with the "Application Mode".
The name of the executor to be used for executing the
given job, which is equivalent to the
"execution.target" config option. The currently
available executors are: "remote", "local",
"kubernetes-session", "yarn-per-job" (deprecated),
"yarn-session".
-t,--target <arg> The deployment target for the given application,
which is equivalent to the "execution.target" config
option. For the "run" action the currently available
targets are: "remote", "local", "kubernetes-session",
"yarn-per-job" (deprecated), "yarn-session". For the
"run-application" action the currently available
targets are: "kubernetes-application".
Options for yarn-cluster mode:
-m,--jobmanager <arg> Set to yarn-cluster to use YARN execution
mode.
-yid,--yarnapplicationId <arg> Attach to running YARN session
-z,--zookeeperNamespace <arg> Namespace to create the Zookeeper
sub-paths for high availability mode
Options for default mode:
-D <property=value> Allows specifying multiple generic
configuration options. The available
options can be found at
https://nightlies.apache.org/flink/flink-do
cs-stable/ops/config.html
-m,--jobmanager <arg> Address of the JobManager to which to
connect. Use this flag to connect to a
different JobManager than the one specified
in the configuration. Attention: This
option is respected only if the
high-availability configuration is NONE.
-z,--zookeeperNamespace <arg> Namespace to create the Zookeeper sub-paths
for high availability mode
savepoint
# 动作"savepoint"为正在运行的作业触发保存点或清除现有的保存点。
Action "savepoint" triggers savepoints for a running job or disposes existing ones.
Syntax: savepoint [OPTIONS] <Job ID> [<target directory>]
"savepoint" action options:
# -d 要销毁的保存点路径。
-d,--dispose <arg> Path of savepoint to dispose.
-j,--jarfile <jarfile> Flink program JAR file.
# -type 描述应采用的保存点的二进制格式。支持的选项:[canonical -用于所有状态后端的通用格式,允许更改状态后端,native =用于所选状态后端的特定格式,可能更快地获取和恢复。
-type,--type <arg> Describes the binary format in which a savepoint
should be taken. Supported options: [canonical - a
common format for all state backends, allow for
changing state backends, native = a specific
format for the chosen state backend, might be
faster to take and restore from.
Options for Generic CLI mode:
-D <property=value> Allows specifying multiple generic configuration
options. The available options can be found at
https://nightlies.apache.org/flink/flink-docs-stable/
ops/config.html
-e,--executor <arg> DEPRECATED: Please use the -t option instead which is
also available with the "Application Mode".
The name of the executor to be used for executing the
given job, which is equivalent to the
"execution.target" config option. The currently
available executors are: "remote", "local",
"kubernetes-session", "yarn-per-job" (deprecated),
"yarn-session".
-t,--target <arg> The deployment target for the given application,
which is equivalent to the "execution.target" config
option. For the "run" action the currently available
targets are: "remote", "local", "kubernetes-session",
"yarn-per-job" (deprecated), "yarn-session". For the
"run-application" action the currently available
targets are: "kubernetes-application".
Options for yarn-cluster mode:
-m,--jobmanager <arg> Set to yarn-cluster to use YARN execution
mode.
-yid,--yarnapplicationId <arg> Attach to running YARN session
-z,--zookeeperNamespace <arg> Namespace to create the Zookeeper
sub-paths for high availability mode
Options for default mode:
-D <property=value> Allows specifying multiple generic
configuration options. The available
options can be found at
https://nightlies.apache.org/flink/flink-do
cs-stable/ops/config.html
-m,--jobmanager <arg> Address of the JobManager to which to
connect. Use this flag to connect to a
different JobManager than the one specified
in the configuration. Attention: This
option is respected only if the
high-availability configuration is NONE.
-z,--zookeeperNamespace <arg> Namespace to create the Zookeeper sub-paths
for high availability mode
边栏推荐
- MySQL 日期时间类型精确到毫秒
- 哆啦a梦教你页面的转发与重定向
- 【Unity】编辑器扩展-01-拓展Project视图
- Hematemesis summarizes thirteen experiences to help you create more suitable MySQL indexes
- @RequestBody和@RequestParam区别
- [Mini Program Project Development--Jingdong Mall] Custom Search Component of uni-app (Middle)--Search Suggestions
- 状态机动态规划之股票问题总结
- 【黄啊码】MySQL入门—3、我用select ,老板直接赶我坐火车回家去,买的还是站票
- 【MySQL功法】第3话 · MySQL中常见的数据类型
- ecshop安装的时候提示不支持JPEG格式
猜你喜欢

MySQL----多表查询
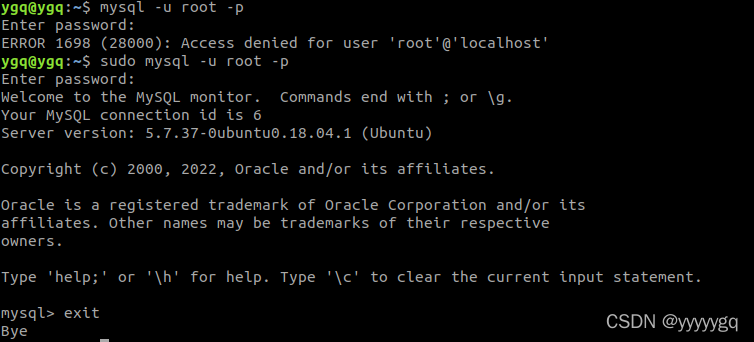
Ubuntu安装Mysql5.7

【云原生】微服务之Feign的介绍与使用
[Cloud native] Introduction and use of Feign of microservices

SSM integration case study (detailed)

Small application project development, jingdong mall 】 【 uni - app custom search component (below) - search history
Docker-compose安装mysql
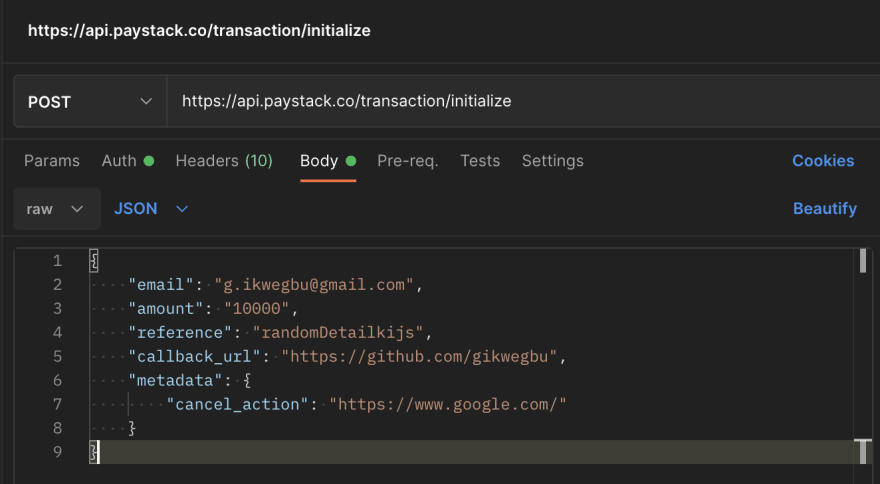
Flutter Paystack implements all options
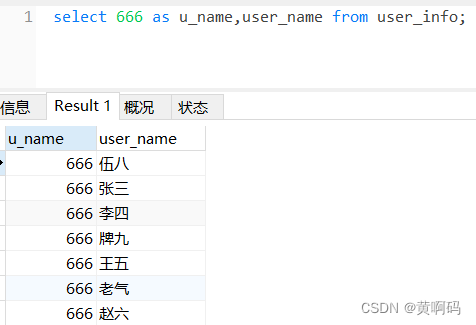
【黄啊码】MySQL入门—3、我用select ,老板直接赶我坐火车回家去,买的还是站票

35-Jenkins-Shared library application
随机推荐
蚂蚁核心科技产品亮相数字中国建设峰会 持续助力企业数字化转型
各位大佬,sqlserver 支持表名正则匹配吗
【小程序项目开发-- 京东商城】uni-app之自定义搜索组件(下) -- 搜索历史
JSP application对象简介说明
MySQL 数据库基础知识(系统化一篇入门)
[What is the role of auto_increment in MySQL?】
Flutter Paystack 所有选项实现
【黄啊码】MySQL入门—3、我用select ,老板直接赶我坐火车回家去,买的还是站票
[MySQL exercises] Chapter 5 · SQL single table query
奉劝那些刚参加工作的学弟学妹们:要想进大厂,这些核心技能是你必须要掌握的!完整学习路线!
JSP config对象的简介说明
怎样修改MySQL数据库的密码
控制文本保留几行,末尾省略
[MySQL exercises] Chapter 2 Basic operations of databases and data tables
Splunk Workflow action 给我们带来的好处
关于挂载EXfat文件格式U盘失败的问题
【小程序项目开发-- 京东商城】uni-app之自定义搜索组件(中)-- 搜索建议
Doraemon teach you forwarded and redirect page
JSP session的生命周期简介说明
35-Jenkins-Shared library application