当前位置:网站首页>Go zero micro service practical series (VIII. How to handle tens of thousands of order requests per second)
Go zero micro service practical series (VIII. How to handle tens of thousands of order requests per second)
2022-07-02 16:48:00 【Microservice practice】
In previous articles , We spent a lot of time on how to use cache to optimize the read performance of the system , The reason is that most of our products are read more than write , Especially at the beginning of the product , Maybe most users just come to check the products , Very few users actually place orders . But as the business grows , We will encounter some scenarios with high concurrent write requests , Spike buying is the most typical scenario with high concurrency . After the second kill rush purchase starts, users will frantically refresh the page so that they can see the goods as soon as possible , So the seckill scenario is also a high concurrency read scenario . So how do we optimize for high concurrency read / write scenarios ?
Processing hot data
Seckill data is usually hot data , There are several ways to deal with hot data : First, optimization , Second, restrictions , Third, isolation .
Optimize
The most effective way to optimize hotspot data is to cache hotspot data , We can cache hot data into memory cache .
Limit
Restriction is more a protection mechanism , When the second kill starts, users will constantly refresh the page to obtain data , At this time, we can limit the number of requests for a single user , For example, you can only request once a second , If the limit is exceeded, an error is returned directly , The error returned should be as user-friendly as possible , such as " The waiter is busy " And other friendly tips .
Isolation
The first principle of seckill system design is to isolate such hot data , Don't let 1% Your request affects another 99%, It's more convenient to isolate this 1% Make targeted optimization for the request of . Specifically to the realization , We need to do service isolation , That is, the seckill function is an independent service , Notify to do data isolation , Most of what seckill calls are hot data , We need to use separate Redis Cluster and individual Mysql, The purpose is not to let 1% Your data has an opportunity to influence 99% The data of .
Traffic peak clipping
For the second kill scenario , It is characterized by an influx of requests at the moment when the second kill begins , This leads to a particularly high traffic peak . But the number of people who can finally grab the goods is fixed , That is, no matter what 100 People or 10000000 The results of people's requests are the same , Higher concurrency , The more invalid requests . But from a business perspective , We hope that more people will participate in the seckill activity , That is to say, at the beginning of the second kill, I hope more people will refresh the page , But when you actually start ordering , The more requests, the better . So we can design some rules , Make concurrent requests more deferred , You can even filter out some invalid requests .
The essence of peak shaving is to delay the sending of user requests , In order to reduce and filter out some invalid requests , It follows the principle of minimizing the number of requests . The easiest solution we can think of is to use message queues to buffer transient traffic , Convert synchronous direct calls to asynchronous indirect push , In the middle, it receives the instantaneous flow peak at one end through a queue , Push messages smoothly at the other end , As shown in the figure below :

After asynchronous processing with message queue , Then the result of the second kill is not easy to return synchronously , So our idea is that when the user initiates a seckill request , Synchronous return response user " The second kill result is being calculated ..." A reminder of , How do we return the result to the user after the calculation ? In fact, there are many schemes .
One is to take the initiative to query the results of the server by polling the page , For example, a request is made to the server every second to see if there is any processing result , The disadvantage of this method is that the number of requests on the server side will increase a lot . Second, take the initiative push The way , This requires the server and client to maintain a long connection , The server takes the initiative after processing the request push To the client , The disadvantage of this method is that the number of connections on the server side will be large .
Another question is what to do if an asynchronous request fails ? I think for the second kill scene , If you fail, just throw it away , The worst result is that the user didn't grab it . If you want to ensure fairness as much as possible , You can try again after the failure .
How to ensure that messages are consumed only once
kafka Is able to guarantee "At Least Once" The mechanism of , That is, the message will not be lost , But it may lead to repeated consumption , Once a message is consumed repeatedly, it will cause errors in business logic processing , So how can we avoid the repeated consumption of messages ?
We just need to ensure that even if we consume repeated messages , From the perspective of the final result of consumption, it would be good if it was the same as the result of consumption only once , That is to ensure that the production and consumption of messages are idempotent . What is idempotent ? If we consume a message , To reduce the quantity of stock on hand 1, Then, if you consume two identical messages, the inventory quantity will be reduced 2, This is not idempotent . If a message is consumed, the post-processing logic is to set the inventory quantity to 0, Or if the current inventory quantity is 10 Time will decrease 1, In this way, when consuming multiple messages, the result is the same , This is idempotent . To put it bluntly, no matter how many times you do one thing, the result will be the same , So this is idempotency .
We can consume messages after they are consumed , Put the only id Stored in a database , The only one here id You can use the user id And commodities id The combination of , Query the database for this before processing the next message id See if it has been consumed , Give up if you spend too much . The pseudocode is as follows :
isConsume := getByID(id)
if isConsume {
return
}
process(message)
save(id)
Another way is to ensure idempotency through the unique index in the database , But this depends on the specific business , I won't repeat it here .
Code implementation
The whole seckill flow chart is as follows :
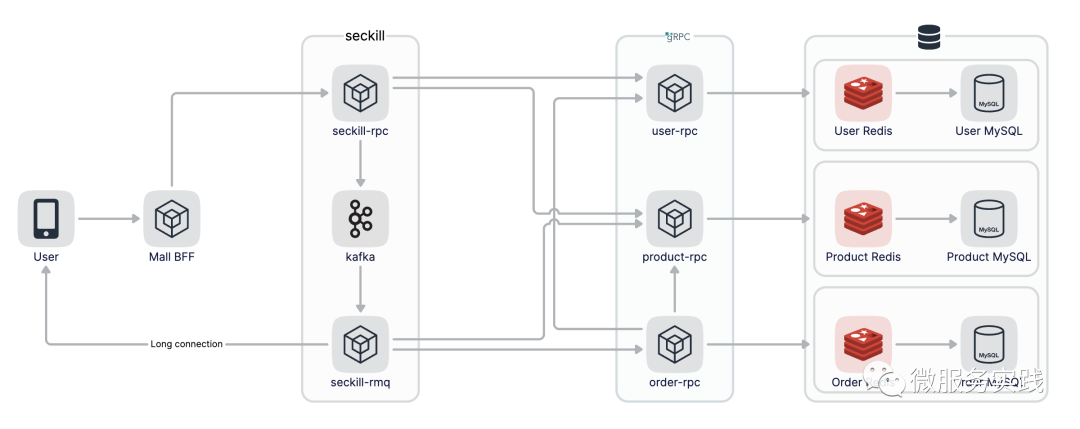
Use kafka As message queue , So you need to install it locally first kafka, I'm using mac It can be used homebrew Direct installation ,kafka rely on zookeeper It will also install automatically
brew install kafka
Pass after installation brew services start start-up zookeeper and kafka,kafka Default listening is on 9092 port
brew services start zookeeper
brew services start kafka
seckill-rpc Of SeckillOrder Method to implement the second kill logic , Let's first limit the number of user requests , For example, users can only request once per second , Use here go-zero Provided PeriodLimit Function realization , If the limit is exceeded, return directly
code, _ := l.limiter.Take(strconv.FormatInt(in.UserId, 10))
if code == limit.OverQuota {
return nil, status.Errorf(codes.OutOfRange, "Number of requests exceeded the limit")
}
Then view the inventory of the current snap up items , If the inventory is insufficient, it will be returned directly , If the inventory is sufficient, it is considered that the order placing process can be started , Send a message to kafka, here kafka Use go-zero Provided kq library , It's very easy to use , Create a new... For seckill Topic, The configuration initialization and logic are as follows :
Kafka:
Addrs:
- 127.0.0.1:9092
SeckillTopic: seckill-topic
KafkaPusher: kq.NewPusher(c.Kafka.Addrs, c.Kafka.SeckillTopic)
p, err := l.svcCtx.ProductRPC.Product(l.ctx, &product.ProductItemRequest{ProductId: in.ProductId})
if err != nil {
return nil, err
}
if p.Stock <= 0 {
return nil, status.Errorf(codes.OutOfRange, "Insufficient stock")
}
kd, err := json.Marshal(&KafkaData{Uid: in.UserId, Pid: in.ProductId})
if err != nil {
return nil, err
}
if err := l.svcCtx.KafkaPusher.Push(string(kd)); err != nil {
return nil, err
}
seckill-rmq consumption seckill-rpc Order the production data , We build new seckill-rmq service , The structure is as follows :
tree ./rmq
./rmq
├── etc
│ └── seckill.yaml
├── internal
│ ├── config
│ │ └── config.go
│ └── service
│ └── service.go
└── seckill.go
4 directories, 4 files
Still in use kq Initialize startup service , Here we need to register a ConsumeHand Method , This method is used to consume kafka data
srv := service.NewService(c)
queue := kq.MustNewQueue(c.Kafka, kq.WithHandle(srv.Consume))
defer queue.Stop()
fmt.Println("seckill started!!!")
queue.Start()
stay Consume In the method , Deserialize the data after consumption , And then call product-rpc View the inventory of the current item , If the stock is enough, we think we can place an order , call order-rpc Create an order , Finally, update the inventory
func (s *Service) Consume(_ string, value string) error {
logx.Infof("Consume value: %s\n", value)
var data KafkaData
if err := json.Unmarshal([]byte(value), &data); err != nil {
return err
}
p, err := s.ProductRPC.Product(context.Background(), &product.ProductItemRequest{ProductId: data.Pid})
if err != nil {
return err
}
if p.Stock <= 0 {
return nil
}
_, err = s.OrderRPC.CreateOrder(context.Background(), &order.CreateOrderRequest{Uid: data.Uid, Pid: data.Pid})
if err != nil {
logx.Errorf("CreateOrder uid: %d pid: %d error: %v", data.Uid, data.Pid, err)
return err
}
_, err = s.ProductRPC.UpdateProductStock(context.Background(), &product.UpdateProductStockRequest{ProductId: data.Pid, Num: 1})
if err != nil {
logx.Errorf("UpdateProductStock uid: %d pid: %d error: %v", data.Uid, data.Pid, err)
return err
}
// TODO notify user of successful order placement
return nil
}
Two tables are involved in creating the order orders and orderitem, So we use local transactions to insert , The code is as follows :
func (m *customOrdersModel) CreateOrder(ctx context.Context, oid string, uid, pid int64) error {
_, err := m.ExecCtx(ctx, func(ctx context.Context, conn sqlx.SqlConn) (sql.Result, error) {
err := conn.TransactCtx(ctx, func(ctx context.Context, session sqlx.Session) error {
_, err := session.ExecCtx(ctx, "INSERT INTO orders(id, userid) VALUES(?,?)", oid, uid)
if err != nil {
return err
}
_, err = session.ExecCtx(ctx, "INSERT INTO orderitem(orderid, userid, proid) VALUES(?,?,?)", "", uid, pid)
return err
})
return nil, err
})
return err
}
The order number generation logic is as follows , Here, you use time plus auto increment to generate orders
var num int64
func genOrderID(t time.Time) string {
s := t.Format("20060102150405")
m := t.UnixNano()/1e6 - t.UnixNano()/1e9*1e3
ms := sup(m, 3)
p := os.Getpid() % 1000
ps := sup(int64(p), 3)
i := atomic.AddInt64(&num, 1)
r := i % 10000
rs := sup(r, 4)
n := fmt.Sprintf("%s%s%s%s", s, ms, ps, rs)
return n
}
func sup(i int64, n int) string {
m := fmt.Sprintf("%d", i)
for len(m) < n {
m = fmt.Sprintf("0%s", m)
}
return m
}
Finally, start... Respectively product-rpc、order-rpc、seckill-rpc and seckill-rmq Service and zookeeper、kafka、mysql and redis, After startup, we call seckill-rpc Make a second kill order
grpcurl -plaintext -d '{"user_id": 111, "product_id": 10}' 127.0.0.1:9889 seckill.Seckill.SeckillOrder
stay seckill-rmq Consumption records are printed in , Output is as follows
{"@timestamp":"2022-06-26T10:11:42.997+08:00","caller":"service/service.go:35","content":"Consume value: {\"uid\":111,\"pid\":10}\n","level":"info"}
Look at orders The order has been created in the table , At the same time, the inventory of commodities shall be reduced by one

Conclusion
In essence, seckill is a high concurrency read and write scenario , Above, we introduced the precautions and optimization points of seckill , Our second kill scenario is relatively simple , But in fact, there is no general framework for seckill , We need to optimize according to the actual business scenarios , Different levels of request optimization methods are also different . Here we only show the relevant optimization of the server , But for the seckill scenario, the entire request link needs to be optimized , For example, for static data, we can use CDN Speed up , In order to prevent the flow peak, we can set the question answering function in the front end .
I hope this article can help you , thank you .
Every Monday 、 Thursday update
Code warehouse : https://github.com/zhoushuguang/lebron
Project address
https://github.com/zeromicro/go-zero
Welcome to use go-zero and star Support us !
WeChat ac group
Focus on 『 Microservice practice 』 Official account and click Communication group Get community group QR code .
边栏推荐
- MySQL port
- 台积电全球员工薪酬中位数约46万,CEO约899万;苹果上调日本的 iPhone 售价 ;Vim 9.0 发布|极客头条...
- Routing mode: hash and history mode
- Global and Chinese markets for airport baggage claim conveyors 2022-2028: technology, participants, trends, market size and share Research Report
- Yyds dry goods inventory # look up at the sky | talk about the way and principle of capturing packets on the mobile terminal and how to prevent mitm
- Seal Library - installation and introduction
- What is the difference between self attention mechanism and fully connected graph convolution network (GCN)?
- [North Asia data recovery] data recovery case of raid crash caused by hard disk disconnection during data synchronization of hot spare disk of RAID5 disk array
- sql解决连续登录问题变形-节假日过滤
- LeetCode 1. Sum of two numbers
猜你喜欢

TypeScript数组乱序输出

Foreign enterprise executives, continuous entrepreneurs, yoga and skiing masters, and a program life of continuous iteration and reconstruction
How to use stustr function in Oracle view
PWM控制舵机

SSM整合-异常处理器及项目异常处理方案

TCP server communication process (important)

Yolov5 practice: teach object detection by hand

数据安全产业系列沙龙(三)| 数据安全产业标准体系建设主题沙龙
![[Yu Yue education] reference materials of sensing and intelligent control technology of Nanjing University of Technology](/img/5c/5f835c286548907f3f09ecb66b2068.jpg)
[Yu Yue education] reference materials of sensing and intelligent control technology of Nanjing University of Technology

Rock PI Development Notes (II): start with rock PI 4B plus (based on Ruixing micro rk3399) board and make system operation
随机推荐
ROW_ NUMBER()、RANK()、DENSE_ Rank difference
A week of short video platform 30W exposure, small magic push helps physical businesses turn losses into profits
Bib | graph representation based on heterogeneous information network learning to predict drug disease association
TCP congestion control details | 2 background
Yyds dry goods inventory # look up at the sky | talk about the way and principle of capturing packets on the mobile terminal and how to prevent mitm
unity Hub 登录框变得很窄 无法登录
LeetCode 1. 两数之和
Summary of monthly report | list of major events of moonbeam in June
自注意力机制和全连接的图卷积网络(GCN)有什么区别联系?
Understand the key technology of AGV -- the difference between laser slam and visual slam
基于多元时间序列对高考预测分析案例
Résumé de l'entrevue de Dachang Daquan
Win11应用商店无法加载页面怎么办?Win11商店无法加载页面
Global and Chinese market of switching valves 2022-2028: Research Report on technology, participants, trends, market size and share
数字IC手撕代码--投票表决器
LeetCode 2. 两数相加
Global and Chinese markets for slotting milling machines 2022-2028: Research Report on technology, participants, trends, market size and share
串口控制舵机转动
Download blender on Alibaba cloud image station
电脑设备打印机驱动安装失败如何解决