当前位置:网站首页>【图像分类】2021-EfficientNetV2 CVPR
【图像分类】2021-EfficientNetV2 CVPR
2022-08-02 23:56:00 【說詤榢】
文章目录
【图像分类】2021-EfficientNetV2 CVPR
原论文名称:EfficientNetV2: Smaller Models and Faster Training
论文下载地址:https://arxiv.org/abs/2104.00298
原论文提供代码:https://github.com/google/automl/tree/master/efficientnetv2
1. 简介
1.1 简介
EfficientNetV2这篇文章是2021年4月份发布的,
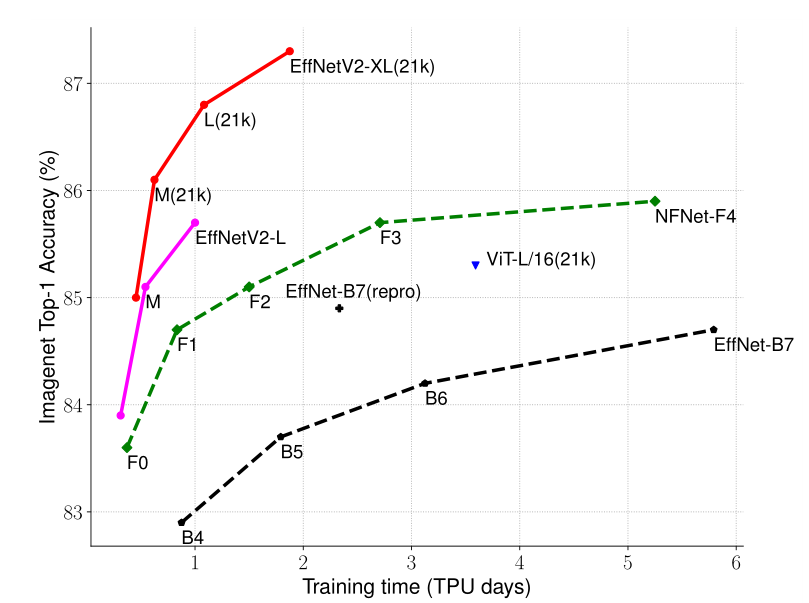
下图给出了EfficientNetV2 的性能,可其分为 S,M,L,XL 几个版本,在 ImageNet 21k 上进行预训练后,迁移参数到 ImageNet 1k 分类可见达到的正确率非常之高。相比而言 ViT 预训练后的性能也低了快两个点,训练速度也会更慢。
1.2 EfficientNetV1存在的问题
在论文的3.2 节中,作者系统性的研究了EfficientNet的训练过程,并总结出了三个问题:
训练图像的尺寸很大时,训练速度非常慢(Training with very large image sizes is slow)
在之前使用EfficientNet时发现当使用到B3(img_size=300)- B7(img_size=600)时基本训练不动,而且非常吃显存。通过下表可以看到,在Tesla V100上当训练的图像尺寸为380x380时,batch_size=24还能跑起来,当训练的图像尺寸为512x512时,batch_size=24时就报OOM(显存不够)了。针对这个问题一个比较好想到的办法就是降低训练图像的尺寸,之前也有一些文章这么干过。降低训练图像的尺寸不仅能够加快训练速度,还能使用更大的batch_size.

在网络浅层中使用Depthwise convolutions速度会很慢(Depthwise convolutions are slow in early layers but effective in later stages)
虽然Depthwise convolutions结构相比普通卷积拥有更少的参数以及更小的FLOPs,但通常无法充分利用现有的一些加速器(虽然理论上计算量很小,但实际使用起来并没有想象中那么快)。在近些年的研究中,有人提出了Fused-MBConv结构去更好的利用移动端或服务端的加速器。Fused-MBConv结构也非常简单,即将原来的MBConv结构(之前在将EfficientNetv1时有详细讲过)主分支中的expansion conv1x1和depthwise conv3x3替换成一个普通的conv3x3,如图2所示。
作者也在EfficientNet-B4上做了一些测试,发现将浅层MBConv结构替换成Fused-MBConv结构能够明显提升训练速度,如表3所示,将stage2,3,4都替换成Fused-MBConv结构后,在Tesla V100上从每秒训练155张图片提升到216张。但如果将所有stage都替换成Fused-MBConv结构会明显增加参数数量以及FLOPs,训练速度也会降低。所以作者使用NAS技术去搜索MBConv和Fused-MBConv的最佳组合。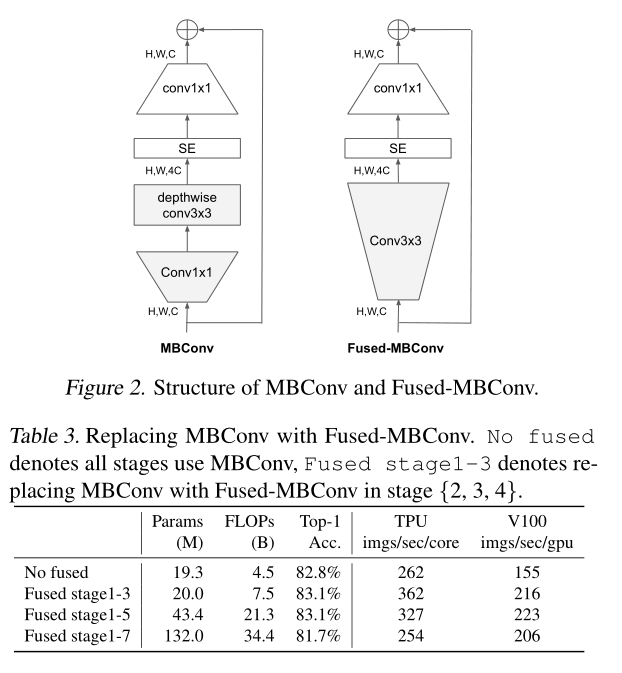
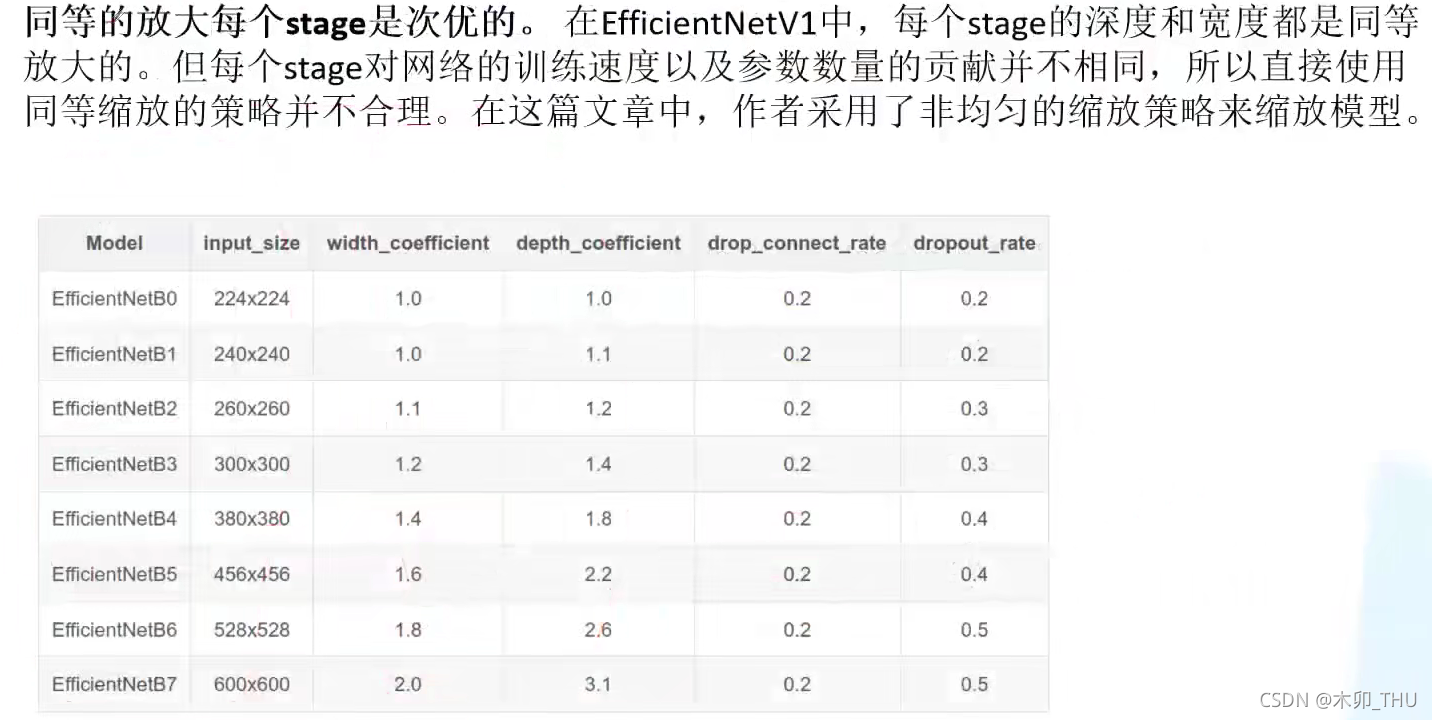
同等的放大每个stage是次优的(Equally scaling up every stage is sub-optimal)
在EfficientNetV1中,每个stage的深度和宽度都是同等放大的。但每个stage对网络的训练速度以及参数数量的贡献并不相同,所以直接使用同等缩放的策略并不合理。
1.3 结果
在 EfficientNetV1 中作者关注的是准确率,参数数量以及 FLOPs(理论计算量小不代表推理速度快),在 EfficientNetV2 中作者进一步关注模型的训练速度。(其实我们更关心准确率和推理速度)。在表中可见,V2 相比 V1 在训练时间和推理时间上都有较大的优势。
贡献如下
- 引入新的网络(EfficientNetV2),该网络在训练速度以及参数数量上都优于先前的一些网络。
- 提出了改进的渐进学习方法,该方法会根据训练图像的尺寸动态调节正则方法(例如dropout、data augmentation和mixup)。通过实验展示了该方法不仅能够提升训练速度,同时还能提升准确率。
- 通过实验与先前的一些网络相比,训练速度提升11倍,参数数量减少为 1 6.8 \frac{1}{6.8} 6.81
2. 网络
2.1 整体架构
整体架构如下
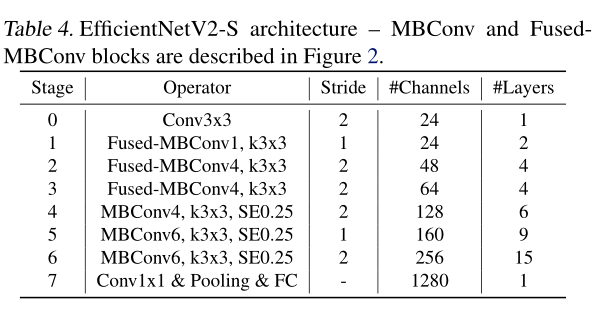
通过上表可以看到EfficientNetV2-S分为Stage0到Stage7(EfficientNetV1中是Stage1到Stage9)。Operator表示在当前Stage中使用的模块:
Conv3x3就是普通的3x3卷积 + 激活函数(SiLU)+ BN
Fused-MBConv模块上面再讲EfficientNetV1存在问题章节有讲到过,模块名称后跟的1,4表示expansion ratio,k3x3表示kenel_size为3x3,注意当expansion ratio等于1时是没有expand conv的,还有这里是没有使用到SE结构的(原论文图中有SE)。注意当stride=1且输入输出Channels相等时才有shortcut连接。还需要注意的是,当有shortcut连接时才有Dropout层,而且这里的Dropout层是Stochastic Depth,即会随机丢掉整个block的主分支(只剩捷径分支,相当于直接跳过了这个block)也可以理解为减少了网络的深度。具体可参考Deep Networks with Stochastic Depth这篇文章。MBConv模块和EfficientNetV1中是一样的,其中模块名称后跟的4,6表示expansion ratio,SE0.25表示使用了SE模块,0.25表示SE模块中第一个全连接层的节点个数是输入该MBConv模块特征矩阵channels的 1 4 \frac{1}{4} 41详情可查看我之前的文章,下面是我自己重绘的MBConv模块结构图。注意当stride=1且输入输出Channels相等时才有shortcut连接。同样这里的Dropout层是Stochastic Depth。
2.2 Fused-MBConv
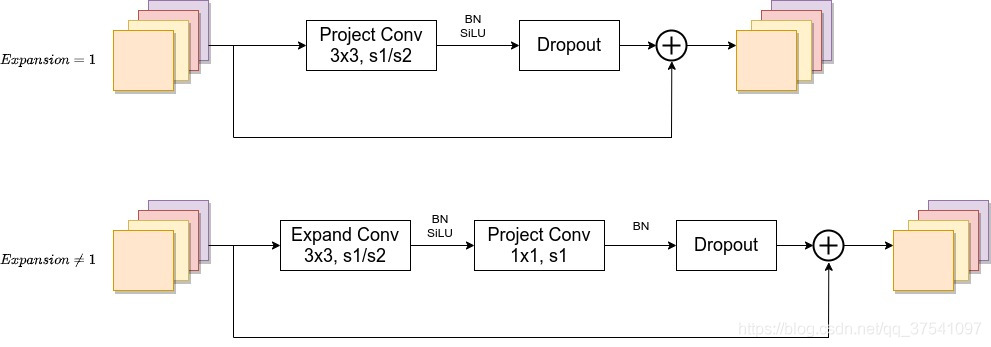
2.3 MBConv

3. 代码
""" Creates a EfficientNetV2 Model as defined in: Mingxing Tan, Quoc V. Le. (2021). EfficientNetV2: Smaller Models and Faster Training arXiv preprint arXiv:2104.00298. import from https://github.com/d-li14/mobilenetv2.pytorch """
import torch
import torch.nn as nn
import math
__all__ = ['effnetv2_s', 'effnetv2_m', 'effnetv2_l', 'effnetv2_xl']
def _make_divisible(v, divisor, min_value=None):
""" This function is taken from the original tf repo. It ensures that all layers have a channel number that is divisible by 8 It can be seen here: https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py :param v: :param divisor: :param min_value: :return: """
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_v < 0.9 * v:
new_v += divisor
return new_v
# SiLU (Swish) activation function
if hasattr(nn, 'SiLU'):
SiLU = nn.SiLU
else:
# For compatibility with old PyTorch versions
class SiLU(nn.Module):
def forward(self, x):
return x * torch.sigmoid(x)
class SELayer(nn.Module):
""" SE注意力模型 """
def __init__(self, inp, oup, reduction=4):
""" Args: inp: 输入通道数 oup: 输出通道数 reduction: 中间通道数的缩放倍数 ,中间通道数 channel =inp // reduction """
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(oup, _make_divisible(inp // reduction, 8)),
SiLU(),
nn.Linear(_make_divisible(inp // reduction, 8), oup),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y
def conv_3x3_bn(inp, oup, stride):
return nn.Sequential(
nn.Conv2d(inp, oup, 3, stride, 1, bias=False),
nn.BatchNorm2d(oup),
SiLU()
)
def conv_1x1_bn(inp, oup):
""" 点卷积 Args: inp: oup: Returns: """
return nn.Sequential(
nn.Conv2d(inp, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
SiLU()
)
class MBConv(nn.Module):
def __init__(self, inp, oup, stride, expand_ratio, use_se):
""" Fused_MBConv 模块和MB模块混合 Args: inp: 输入通道数 oup: 输出通道数 stride: 步长=2 就进行下采样 expand_ratio: 缩放倍数。就是中间dim= in_channel* expand_ratio(缩放倍数) use_se: 是否使用SE """
super(MBConv, self).__init__()
assert stride in [1, 2]
hidden_dim = round(inp * expand_ratio)
self.identity = stride == 1 and inp == oup
if use_se:
# MB模块
self.conv = nn.Sequential(
# pw 经过一个 点卷积 ,进行升维
nn.Conv2d(inp, hidden_dim, 1, 1, 0, bias=False),
nn.BatchNorm2d(hidden_dim),
SiLU(),
# dw 经过深度卷积,进行特征提取
nn.Conv2d(hidden_dim, hidden_dim, 3, stride, 1, groups=hidden_dim, bias=False),
nn.BatchNorm2d(hidden_dim),
SiLU(),
SELayer(inp, hidden_dim),
# pw-linear 经过一个点卷积 ,进行降维
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
else:
self.conv = nn.Sequential(
# fused 经过一个3*3的卷积,进行特征提取
nn.Conv2d(inp, hidden_dim, 3, stride, 1, bias=False),
nn.BatchNorm2d(hidden_dim),
SiLU(),
# pw-linear 经过一个1*1卷积,进行降维
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
def forward(self, x):
if self.identity:
return x + self.conv(x)
else:
return self.conv(x)
class EffNetV2(nn.Module):
def __init__(self, cfgs, num_classes=1000, width_mult=1.):
super(EffNetV2, self).__init__()
self.cfgs = cfgs
# building first layer
input_channel = _make_divisible(24 * width_mult, 8)
layers = [conv_3x3_bn(3, input_channel, 2)]
# building inverted residual blocks
block = MBConv
for t, c, n, s, use_se in self.cfgs:
""" t 缩放倍数 c 通道数 n 模块重复个数 s 步长 use_se 是否使用SE """
output_channel = _make_divisible(c * width_mult, 8)
for i in range(n):
layers.append(block(input_channel, output_channel, s if i == 0 else 1, t, use_se))
input_channel = output_channel
self.features = nn.Sequential(*layers)
# building last several layers
output_channel = _make_divisible(1792 * width_mult, 8) if width_mult > 1.0 else 1792
self.conv = conv_1x1_bn(input_channel, output_channel)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.classifier = nn.Linear(output_channel, num_classes)
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = self.conv(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
m.weight.data.normal_(0, 0.001)
m.bias.data.zero_()
def effnetv2_s(**kwargs):
""" Constructs a EfficientNetV2-S model 最小版本 """
cfgs = [
# t, c, n, s, SE
[1, 24, 2, 1, 0],
[4, 48, 4, 2, 0],
[4, 64, 4, 2, 0],
[4, 128, 6, 2, 1],
[6, 160, 9, 1, 1],
[6, 256, 15, 2, 1],
]
return EffNetV2(cfgs, **kwargs)
def effnetv2_m(**kwargs):
""" Constructs a EfficientNetV2-M model 中间版本 """
cfgs = [
# t, c, n, s, SE
[1, 24, 3, 1, 0],
[4, 48, 5, 2, 0],
[4, 80, 5, 2, 0],
[4, 160, 7, 2, 1],
[6, 176, 14, 1, 1],
[6, 304, 18, 2, 1],
[6, 512, 5, 1, 1],
]
return EffNetV2(cfgs, **kwargs)
def effnetv2_l(**kwargs):
""" Constructs a EfficientNetV2-L model Large 版本,大版本 """
cfgs = [
# t, c, n, s, SE
[1, 32, 4, 1, 0],
[4, 64, 7, 2, 0],
[4, 96, 7, 2, 0],
[4, 192, 10, 2, 1],
[6, 224, 19, 1, 1],
[6, 384, 25, 2, 1],
[6, 640, 7, 1, 1],
]
return EffNetV2(cfgs, **kwargs)
def effnetv2_xl(**kwargs):
""" Constructs a EfficientNetV2-XL model 超大版本 """
cfgs = [
# t, c, n, s, SE
[1, 32, 4, 1, 0],
[4, 64, 8, 2, 0],
[4, 96, 8, 2, 0],
[4, 192, 16, 2, 1],
[6, 256, 24, 1, 1],
[6, 512, 32, 2, 1],
[6, 640, 8, 1, 1],
]
return EffNetV2(cfgs, **kwargs)
if __name__ == '__main__':
x = torch.randn(1, 3, 224, 224)
model=effnetv2_m()
y=model(x)
print(y.shape)
参考资料
(1条消息) EfficientNetV2网络详解_太阳花的小绿豆的博客-CSDN博客_efficientnetv2
(1条消息) 深度学习之图像分类(十六)-- EfficientNetV2 网络结构_木卯_THU的博客-CSDN博客_efficientnetv2
边栏推荐
猜你喜欢





随机推荐
中科磁业IPO过会:年营收5.5亿 吴中平家族持股85%
Day117.尚医通:生成挂号订单模块
记一次sql优化Using temporary; Using filesort
定了!8月起,网易将为本号粉丝提供数据分析培训,费用全免!
IDEA多线程调试
用了TCP协议,就一定不会丢包吗?
有奖提问|《新程序员》专访“Apache之父”Brian Behlendorf
TensorFlow学习记录(一):基本介绍
CIO修炼手册:成功晋升CIO的七个秘诀
北路智控上市首日破发:公司市值59亿 募资15.6亿
服务间歇性停顿问题优化|得物技术
6、Powershell命令配置Citrix PVS云桌面桌面注销不关机
Jmeter二次开发实现rsa加密
Merge two excel spreadsheet tools
Speech Synthesis Model Cheat Sheet (1)
升级版的冒泡排序:鸡尾酒排序(快乐小时排序)
js显示隐藏手机号
minio 单机版安装
Nacos配置中心之事件订阅
FreeRTOS任务管理