当前位置:网站首页>Speech Synthesis Model Cheat Sheet (1)
Speech Synthesis Model Cheat Sheet (1)
2022-08-03 01:32:00 【Andy Dennis】
Foreword
Voice is also an increasingly popular industry.Given a piece of text, we want it to be read. We need to use speech synthesis technology, which is Text-to-Speech, or TTS for short.Here are some interesting models I saw.
One-stage speech synthesis is generally called end-to-end
Two-stage speech synthesis step, usually stage1:
Text-(FFT)-> Spectrogram-(filtering)-> 梅尔谱/线性谱
stage 2: 将梅尔谱/线性谱生成波形(音频)
Thesis
VITS
Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech
ICML 2021
Paper: https://arxiv.org/abs/2106.06103
Code: https://github.com/jaywalnut310/vits
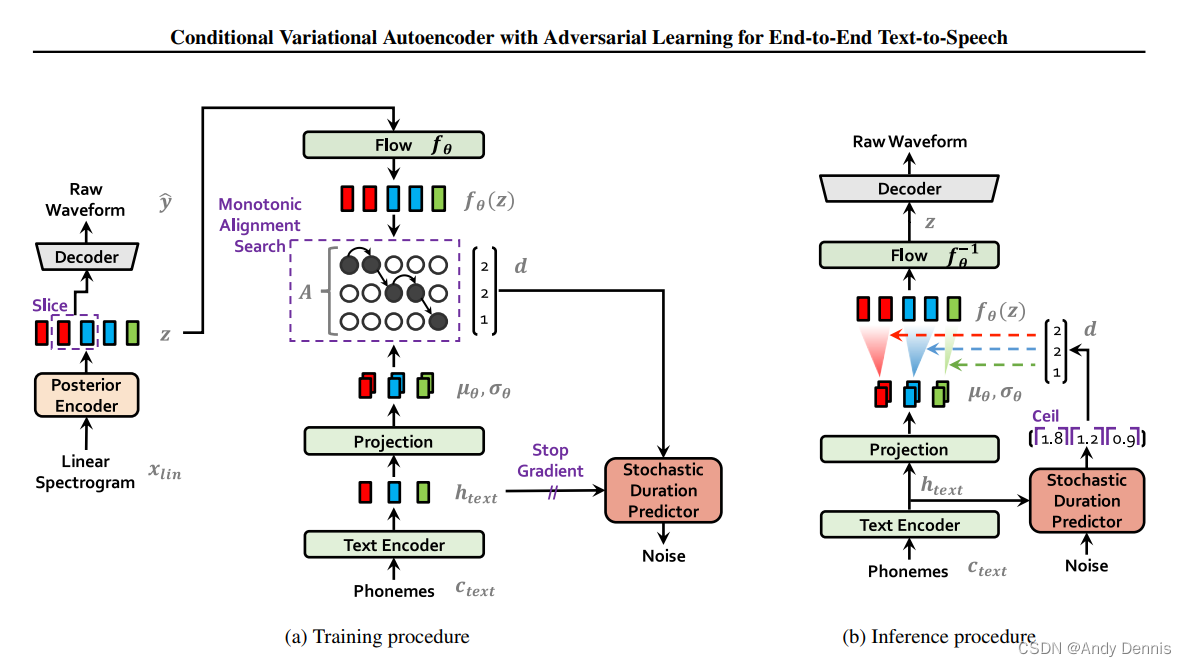
condition VAE + flow + GAN
flow can look at the two articles v-flow and flow++.
I saw two paper notes on Zhihu:
More detailed Read the classic: VITS, for speech synthesis tapeConditional Variational Autoencoders with Adversarial Learning
Short [Paper Notes] VITS_OlaWod
边栏推荐
猜你喜欢

Image recognition from zero to write DNF script key points
最近公共祖先(LCA)学习笔记 | P3379 【模板】最近公共祖先(LCA)题解
HCIP(16)

Jmeter secondary development to realize rsa encryption
Day117.尚医通:生成挂号订单模块

AcWing 2983. 玩具

B站回应“HR 称核心用户都是 Loser”:该面试官去年底已被劝退,会吸取教训加强管理

记一次mysql查询慢的优化历程
The latest real software test interview questions are shared. Are you afraid that you will not be able to enter the big factory after collecting them?
数据库主键一定要自增吗?有哪些场景不建议自增?
随机推荐
【C语言】带头双向循环链表(list)详解(定义、增、删、查、改)
学习Autodock分子对接
HCIP(17)
CWE4.8:2022年危害最大的25种软件安全问题
Cholesterol-PEG-Acid,胆固醇-聚乙二醇-羧基保持在干燥、低温环境下
Based on two levels of decomposition and the length of the memory network multi-step combined forecasting model of short-term wind speed
聚乙二醇衍生物4-Arm PEG-DSPE,四臂-聚乙二醇-磷脂
用了 TCP 协议,数据一定不会丢吗?
技术分享 | 接口自动化测试中如何对xml 格式做断言验证?
Kubernetes 进阶训练营 网络
WAF WebShell Trojan free to kill
centos7安装mysql5.7步骤(图解版)
Cholesterol-PEG-Amine,CLS-PEG-NH2,胆固醇-聚乙二醇-氨基脂两亲性脂质衍生物
雷克萨斯lm的安全性如何?
【斯坦福计网CS144项目】Lab5: NetworkInterface
IDO代币预售合约系统开发技术详细
分库分表索引设计:二级索引、全局索引的最佳设计实践
CKAN教程之将 Snowflake 连接到 CKAN 以发布到开放数据门户
Mock工具之Moco使用教程
mysql根据多字段分组——group by带两个或多个参数