当前位置:网站首页>Task 4 Machine Learning Library Scikit-learn
Task 4 Machine Learning Library Scikit-learn
2022-08-03 00:35:00 【Heihei_study】
目录
Train and test this model and get a normalized dataset
四、Network search for tuning parameters
处理分类数据 (Convert it to a numeric feature)
Convert processed categorical and numerical features into sparse matrices
一、训练和测试分类器
我们使用digits数据集,这是一个手写数字的数据集.
手写数字集

from sklearn.datasets import load_digits
X, y = load_digits(return_X_y=True)
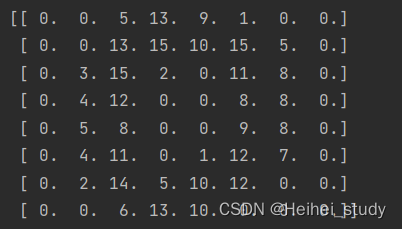
查看X[0]的数据
print(X[0].reshape(8,8))
打印出X[0]的图像
plt.imshow(X[0].reshape(8, 8), cmap='gray');# 下面完成灰度图的绘制
# 灰度显示图像
plt.axis('off')# 关闭坐标轴
print('The digit in the image is {}'.format(y[0]))# 格式化打印
#The digit in the image is 0

可以推测X是8*8(64个像素点)The value of each pixel of the graph,y则是X所对应的数字
划分数据集和训练集
train_test_split(X, y, stratify=y)_Brickworker's blog-CSDN博客_stratify=y
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, stratify=y, test_size=0.25, random_state=42)
# 划分数据为训练集与测试集,添加stratify参数,以使得训练和测试数据集的类分布与整个数据集的类分布相同.模型和预测
一旦我们拥有独立的培训和测试集,我们就可以使用fit方法学习机器学习模型. 我们将使用score方法to test this method,依赖于默认的准确度指标.
Python机器学习sklearn里的score()方法,It is mainly used to measure how good or bad the prediction effect of a given test set is.
LogisticRegression分类器
from sklearn.linear_model import LogisticRegression # 求出Logistic回归的精确度得分
clf = LogisticRegression(
solver='lbfgs', multi_class='ovr', max_iter=5000, random_state=42)
clf.fit(X_train, y_train)
accuracy = clf.score(X_test, y_test)
print('Accuracy score of the {} is {:.4f}'.format(clf.__class__.__name__,
accuracy))
LogisticRegression - 参数说明_Jark_的博客-CSDN博客_logisticregression函数
The accuracy of the regression model is approximately 0.9622
![]()
RandomForestClassifier
scikit-learn的API在分类器中是一致的.因此,我们可以通过RandomForestClassifier轻松替换LogisticRegression分类器.这些更改很小,仅与分类器实例的创建有关.
from sklearn.ensemble import RandomForestClassifier
# RandomForestClassifier轻松替换LogisticRegression分类器
clf = RandomForestClassifier(n_estimators=1000, n_jobs=-1, random_state=42)
clf.fit(X_train, y_train)
accuracy = clf.score(X_test, y_test)
print('Accuracy score of the {} is {:.2f}'.format(clf.__class__.__name__, accuracy))![]()
XGBClassifier
from xgboost import XGBClassifier
clf = XGBClassifier(n_estimators=1000)
clf.fit(X_train, y_train)
accuracy = clf.score(X_test, y_test)
print('Accuracy score of the {} is {:.2f}'.format(clf.__class__.__name__, accuracy))![]()
GradientBoostingClassifier
from sklearn.ensemble import GradientBoostingClassifier
clf = GradientBoostingClassifier(n_estimators=100, random_state=0)
clf.fit(X_train, y_train)
accuracy = clf.score(X_test, y_test)
print('Accuracy score of the {} is {:.2f}'.format(clf.__class__.__name__,
accuracy))Accuracy score of the GradientBoostingClassifier is 0.96
balanced_accuracy_score
from sklearn.metrics import balanced_accuracy_score
y_pred = clf.predict(X_test)
accuracy = balanced_accuracy_score(y_pred, y_test)
print('Accuracy score of the {} is {:.2f}'.format(clf.__class__.__name__,
accuracy))![]()
SVC
from sklearn.svm import SVC, LinearSVC
clf = SVC()
clf.fit(X_train, y_train)
accuracy = clf.score(X_test, y_test)
print('Accuracy score of the {} is {:.2f}'.format(clf.__class__.__name__,
accuracy))![]()
LinearSVC
clf = LinearSVC()
clf.fit(X_train, y_train)
accuracy = clf.score(X_test, y_test)
print('Accuracy score of the {} is {:.2f}'.format(clf.__class__.__name__,
accuracy))![]()
二、标准化数据
归一化

【机器学习】数据归一化——MinMaxScaler理解_GentleCP的博客-CSDN博客_minmaxscaler
from sklearn.preprocessing import MinMaxScaler,StandardScaler
scaler = MinMaxScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
clf = LinearSVC()
clf.fit(X_train_scaled, y_train)
accuracy = clf.score(X_test_scaled, y_test)
print('Accuracy score of the {} is {:.2f}'.format(clf.__class__.__name__,
accuracy))![]()
It can be seen after normalizationlinearSVC的准确度从0.93提升到0.97
数据标准化
- StandardScaler:确保每个特征的平均值为0,方差为1.
sklearn中StandardScaler()_Soda with spicy strips blog-CSDN博客_standardscaler
from sklearn.preprocessing import MinMaxScaler,StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
clf = LinearSVC()
clf.fit(X_train_scaled, y_train)
accuracy = clf.score(X_test_scaled, y_test)
print('Accuracy score of the {} is {:.2f}'.format(clf.__class__.__name__,
accuracy))![]()
预测
sklearn中predict()与predict_proba()用法区别 - pantaQ - 博客园
predict是训练后返回预测结果,是标签值.
from sklearn.metrics import confusion_matrix, classification_report
y_pred = clf.predict(X_test_scaled)sklearnin the confusion matrix(confusion_matrix函数)的理解与使用_Bald Cub's blog-CSDN博客_sklearn 混淆矩阵
Train and test this model and get a normalized dataset
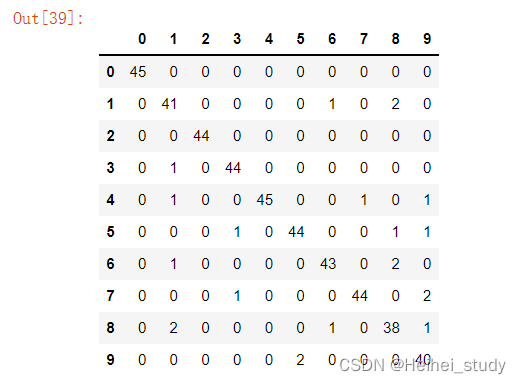
import pandas as pd
pd.DataFrame(
(confusion_matrix(y_pred, y_test)),
columns=range(10),
index=range(10))
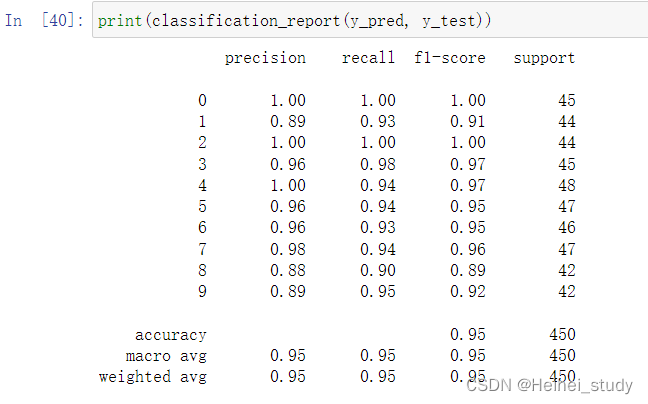
【sklearn】详解classification_reportclassification report calculation_XINFINFZ的博客-CSDN博客_sklearn分类报告
精准率precision:意思为 预测为x的样本中,有多少被正确预测为x.
召回率recall:实际为x的类别中,有多少预测为x
F1分数=2 * precision * recall /(precision+recall)
准确率(accuracy):即全部样本里被分类正确的比例.
macro avg :上面类别各分数的直接平均
weighted avg:上面类别各分数的加权(权值为support)平均
三、交叉验证
交叉验证:It is to select a part of the samples in the training set to test the model.A portion of the training set data is reserved as a validation set/评估集,对训练集生成的参数进行测试,相对客观的判断这些参数对训练集之外的数据的符合程度.
Summary of cross-validation methods【附代码】(留一法、K折交叉验证、分层交叉验证、对抗验证、时间序列交叉验证)_Avasla的博客-CSDN博客_交叉验证代码
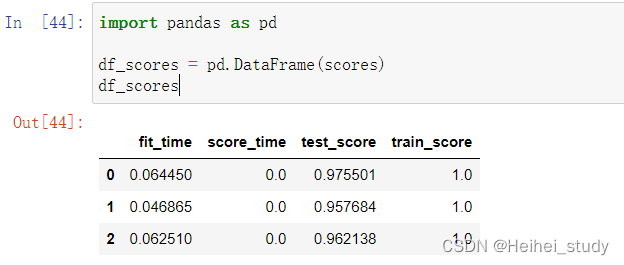
from sklearn.model_selection import cross_validate
clf = LogisticRegression(
solver='lbfgs', multi_class='auto', max_iter=1000, random_state=42)
scores = cross_validate(
clf, X_train_scaled, y_train, cv=3, return_train_score=True)cv:代表的就是不同的cross validation的方法了.如果cv是一个int数字的话,那么默认使用的是KFold或者StratifiedKFold交叉,Yes is used if a category label is specifiedStratifiedKFold.
四、Network search for tuning parameters
Python机器学习:Grid SearchCV(网格搜索)_元神のAssistant's Blog-CSDN博客_gridsearchcv
可以通过穷举搜索来优化超参数.`GridSearchCV`提供此类实用程序,并通过参数网格进行交叉验证的网格搜索.
Grid Search:一种调参手段;
穷举搜索:在所有候选的参数选择中,通过循环遍历,尝试每一种可能性,表现最好的参数就是最终的结果.其原理就像是在数组里找到最大值.这种方法的主要缺点是比较耗时!
如下例子,我们希望优化`LogisticRegression`分类器的`C`和`penalty`参数.
l2
df_grid = pd.DataFrame(grid.cv_results_)
df_grid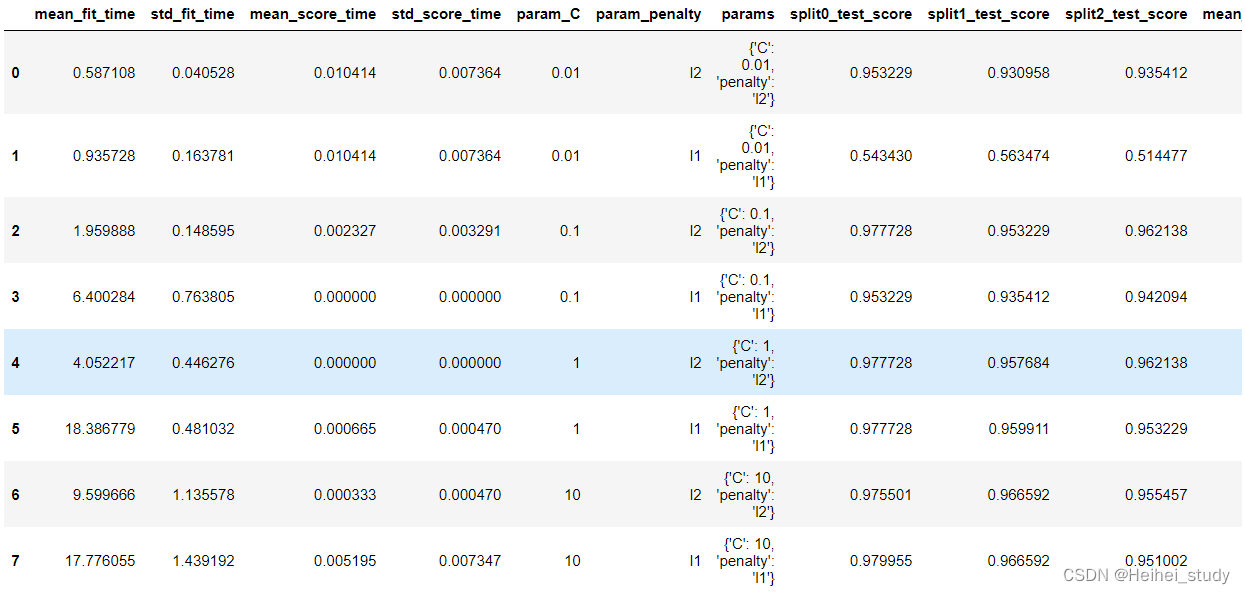
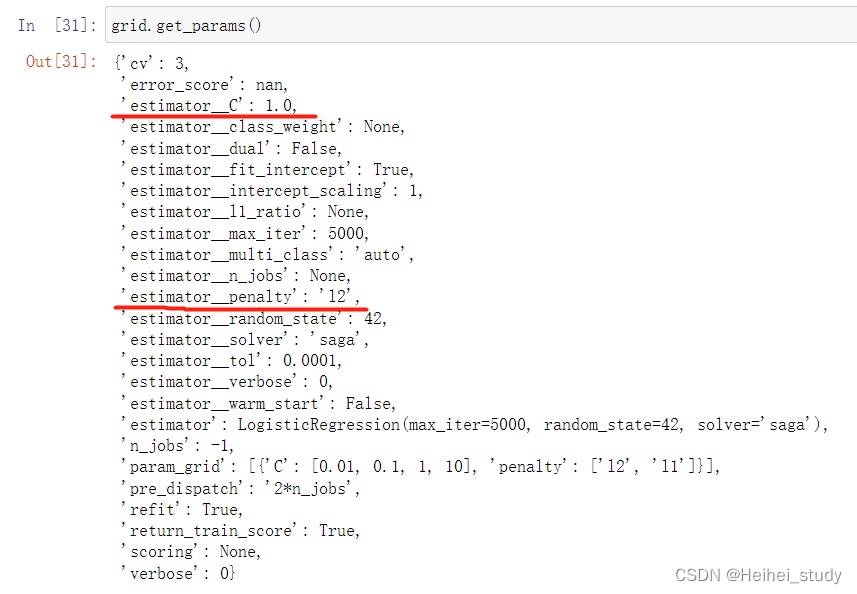
It can be seen that the network search parameter adjustment is selectedC为1.0和penalty为l2.
五、流水线操作
scikit-learn引入了Pipeline对象.It connects multiple transformers and classifiers in turn(或回归器).我们可以创建一个如下管道:
pipelineCombined with data normalized sumLogisticRegressionClassifier for this model
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import cross_validate
X = X_train
y = y_train
pipe = make_pipeline(
MinMaxScaler(),
LogisticRegression(
solver='saga', multi_class='auto', random_state=42, max_iter=5000))
param_grid = {
'logisticregression__C': [0.1, 1.0, 10],
'logisticregression__penalty': ['l2', 'l1']
}
grid = GridSearchCV(pipe, param_grid=param_grid, cv=3, n_jobs=-1)
scores = pd.DataFrame(
cross_validate(grid, X, y, cv=3, n_jobs=-1, return_train_score=True))
scores[['train_score', 'test_score']].boxplot()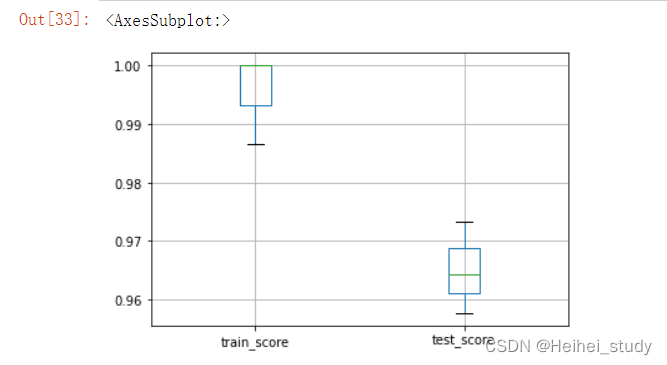
pipe.fit(X_train, y_train)
accuracy = pipe.score(X_test, y_test)
print('Accuracy score of the {} is {:.2f}'.format(pipe.__class__.__name__, accuracy))![]()
六、练习 异构数据:当您使用数字以外的数据时
导入数据
import os
data = pd.read_csv('data/titanic_openml.csv', na_values='?')
data.head()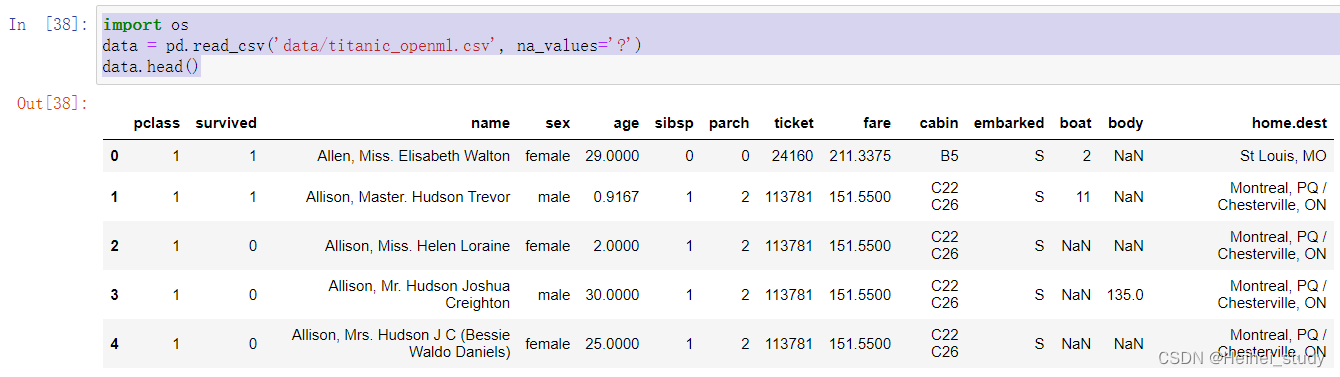
将数据集转换为x,y
drop掉“survived”这个字段,Use this field as the basis for judging survival
y = data['survived']
X = data.drop(columns='survived')处理分类数据 (Convert it to a numeric feature)
不能直接用LogisticRegression分类器,会报错.
Because most classifiers are designed to work with numerical data.
因此,我们需要Convert categorical data to numeric features.
最简单的方法是使用OneHotEncoder对每个分类特征进行读热编码. 让我们以sex与embarked列为例. 请注意,我们还会遇到一些缺失的数据. 我们将使用SimpleImputer用常量值替换缺失值.
缺失值处理:SimpleImputer(简单易懂 + 超详细)_Dream丶Killer的博客-CSDN博客_simpleimputer
strategy:空值填充的策略,共四种选择(默认)mean、median、most_frequent、constant.mean表示该列的缺失值由该列的均值填充.median为中位数,most_frequent为众数.constant表示将空值填充为自定义的值,但这个自定义的值要通过fill_value来定义.
fill_value:str或数值,默认为Zone.当strategy == "constant"时,fill_value被用来替换所有出现的缺失值(missing_values).fill_value为Zone,当处理的是数值数据时,缺失值(missing_values)会替换为0,对于字符串或对象数据类型则替换为"missing_value" 这一字符串.
OneHotEncoder简单用法_长命百岁️的博客-CSDN博客_onehotencoder
The input to this converter should be a numeric array or a string array(二维的),表示分类(离散)特征所取的值.这些特征被使用 one-hot 策略编码.这将为每个类别创建二进制列.每一列认为是一个 feature.默认情况下,encoder 根据每个特征中的唯一值生成类别.We can also specify categories manually categories.针对每个 feature 的二进制列,只有一个位置为1,其余位置都是 0.

在此代码中strategy='constant',We chose to use a custom value that fills in the nulls,fill_value使用默认值,因为sex和embarked都是字符串类型,So the empty value will be replaced with "missing_value"
之后就使用OneHotEncoder函数进行编码
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OneHotEncoder
ohe = make_pipeline(SimpleImputer(strategy='constant'), OneHotEncoder())
X_encoded = ohe.fit_transform(X_train[['sex', 'embarked']])
X_encoded.toarray()这样,可以对分类特征进行编码. 但是,我们也希望标准化数字特征. 因此,我们需要将原始数据分成2个子组并应用不同的预处理:
(i)分类数据的独热编;
(ii)数值数据的标准缩放(归一化).
我们还需要处理两种情况下的缺失值:
对于分类列,我们将字符串'missing_values'替换为缺失值,该字符串将自行解释为类别.
对于数值数据,我们将用感兴趣的特征的The mean replaces missing data.
col_cat = ['sex', 'embarked']
col_num = ['age', 'sibsp', 'parch', 'fare']
X_train_cat = X_train[col_cat]
X_train_num = X_train[col_num]
X_test_cat = X_test[col_cat]
X_test_num = X_test[col_num]scaler_catis an operation performed on categorical features,先将字符串'missing_values'替换缺失值,Then do one hot encoding
scaler_numis an operation performed on numerical features,The mean replaces missing data,Standardize again.
from sklearn.preprocessing import StandardScaler
scaler_cat = make_pipeline(SimpleImputer(strategy='constant'), OneHotEncoder())
X_train_cat_enc = scaler_cat.fit_transform(X_train_cat)
X_test_cat_enc = scaler_cat.transform(X_test_cat)
scaler_num = make_pipeline(SimpleImputer(strategy='mean'), StandardScaler())
X_train_num_scaled = scaler_num.fit_transform(X_train_num)
X_test_num_scaled = scaler_num.transform(X_test_num)Convert processed categorical and numerical features into sparse matrices
scipy.sparse.hstack vstack_蓝鲸123的博客-CSDN博客
hstack :将矩阵按照列进行拼接


import numpy as np
from scipy import sparse
#转为稀疏矩阵
X_train_scaled = sparse.hstack((X_train_cat_enc,
sparse.csr_matrix(X_train_num_scaled)))
X_test_scaled = sparse.hstack((X_test_cat_enc,
sparse.csr_matrix(X_test_num_scaled)))建模预测
转换完成后,我们现在可以组合所有数值的信息.最后,我们使用LogisticRegression分类器作为模型.
clf = LogisticRegression(solver='lbfgs')
clf.fit(X_train_scaled, y_train)
accuracy = clf.score(X_test_scaled, y_test)
print('Accuracy score of the {} is {:.4f}'.format(clf.__class__.__name__, accuracy))![]()
边栏推荐
猜你喜欢





随机推荐
golang刷leetcode:按位与结果大于零的最长组合
YARN资源调度系统介绍
主成分分析(PCA)
golang 刷leetcode:Morris 遍历
Auto.js实现朋友圈自动点赞
golang刷leetcode: 在每个树行中找最大值
You and I will meet the needs of: how to export the data in a MySQL simple ~!Practical!
Swin Transformer 论文精读,并解析其模型结构
圆锥折射作为偏振计量工具的模拟
微软SQL服务器被黑客入侵以窃取代理服务的带宽
wallys/new product/WiFi6 MiniPCIe Module 2T2R 2×2.4GHz 2x5GHz MT7915 MT7975
【Unity】Unity开发进阶(七)双刃剑:扩展方法
[c] Detailed explanation of operators (1)
牛客刷题:手动实现数组filter方法
SublimeText3 安装、配置项、包管理、常用必备插件、常用快捷键以及修改
What is the core business model of the "advertising e-commerce" that has recently become popular in the circle of friends, and is the advertising revenue really reliable?
How does Redis easily achieve system instant kill?
面试官居然问我:删库后,除了跑路还能干什么?
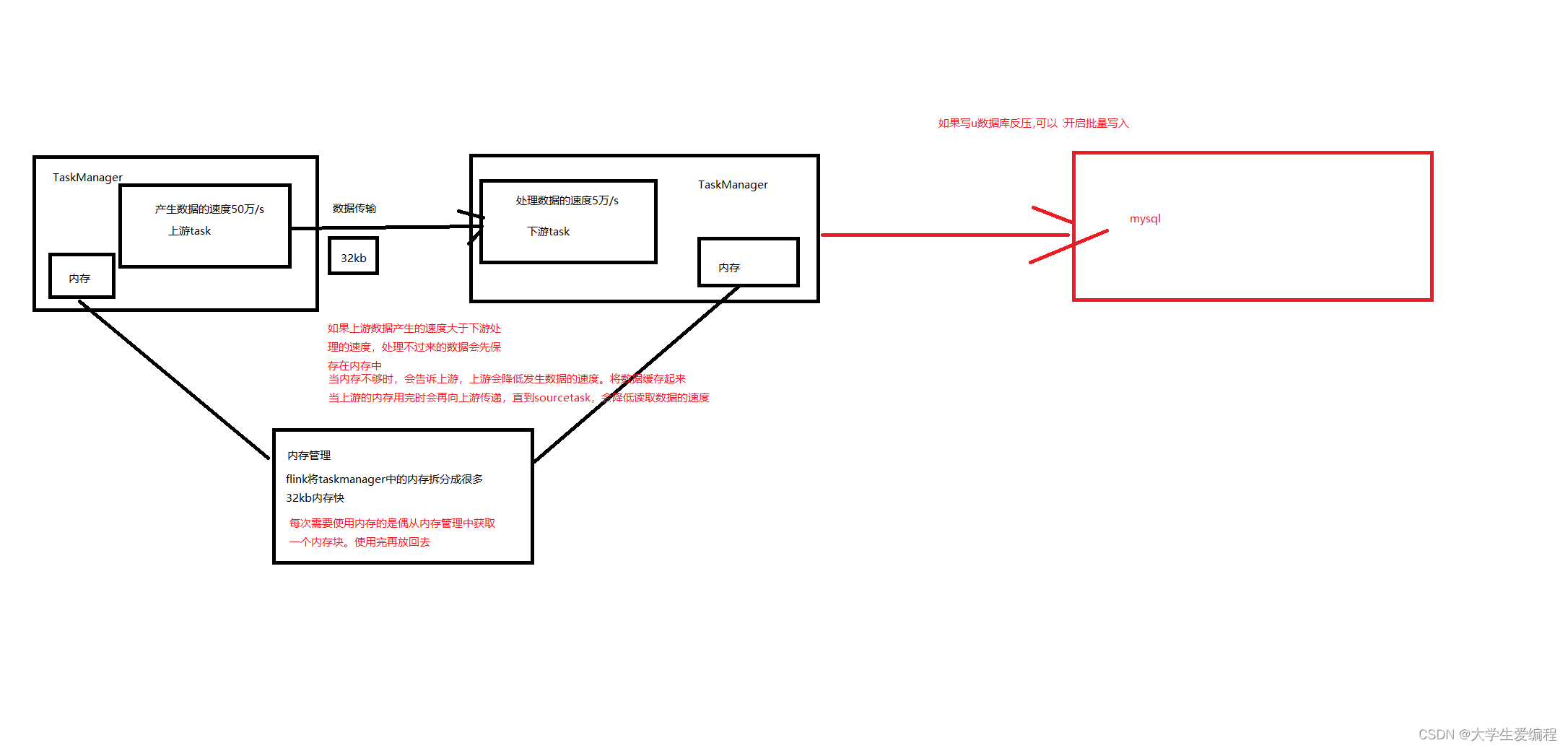
Flink优化的方方面面
Win10怎么开启自带的游戏录屏功能?