当前位置:网站首页>Spark Bucket Table Join
Spark Bucket Table Join
2022-07-27 15:38:00 【wankunde】
Generate Bucket surface
establish Bucket surface
- Mode one
spark.sql("DROP TABLE IF EXISTS user1_bucket")
spark.sql("DROP TABLE IF EXISTS user2_bucket")
val r = new scala.util.Random()
val df = spark.range(1, 100).map(i => (i, s"wankun-${r.nextInt(100)}")).toDF("id", "name")
df.write.
bucketBy(10, "name").
sortBy("name").
mode("overwrite").
saveAsTable("user1_bucket")
scala> spark.sql("show create table user1_bucket").show(false)
+------------------------------------------------------------------------------------------------------------------------------------+
|createtab_stmt |
+------------------------------------------------------------------------------------------------------------------------------------+
|CREATE TABLE `default`.`users` (
`id` BIGINT,
`name` STRING)
USING parquet
CLUSTERED BY (name)
SORTED BY (name)
INTO 10 BUCKETS
|
+------------------------------------------------------------------------------------------------------------------------------------+
- Mode two
CREATE TABLE user2_bucket (
`id` BIGINT,
`name` STRING)
USING parquet
CLUSTERED BY (name)
INTO 10 BUCKETS;
INSERT OVERWRITE TABLE user2_bucket
SELECT id, concat("wankun-",cast(rand()*100 as int)) as name
FROM range(1, 100);
Generated result file
[1] $ hdfs dfs -ls /user/hive/warehouse/user1_bucket
21/05/12 17:11:19 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 21 items
-rw-r--r-- 1 wakun supergroup 0 2021-05-12 17:05 /user/hive/warehouse/user1_bucket/_SUCCESS
-rw-r--r-- 1 wakun supergroup 812 2021-05-12 17:05 /user/hive/warehouse/user1_bucket/part-00000-b657899a-401b-406b-b45d-ac4df1d72e14_00000.c000.snappy.parquet
-rw-r--r-- 1 wakun supergroup 815 2021-05-12 17:05 /user/hive/warehouse/user1_bucket/part-00000-b657899a-401b-406b-b45d-ac4df1d72e14_00001.c000.snappy.parquet
-rw-r--r-- 1 wakun supergroup 833 2021-05-12 17:05 /user/hive/warehouse/user1_bucket/part-00000-b657899a-401b-406b-b45d-ac4df1d72e14_00002.c000.snappy.parquet
-rw-r--r-- 1 wakun supergroup 797 2021-05-12 17:05 /user/hive/warehouse/user1_bucket/part-00000-b657899a-401b-406b-b45d-ac4df1d72e14_00003.c000.snappy.parquet
...
-rw-r--r-- 1 wakun supergroup 817 2021-05-12 17:05 /user/hive/warehouse/user1_bucket/part-00000-b657899a-401b-406b-b45d-ac4df1d72e14_00009.c000.snappy.parquet
-rw-r--r-- 1 wakun supergroup 812 2021-05-12 17:05 /user/hive/warehouse/user1_bucket/part-00001-b657899a-401b-406b-b45d-ac4df1d72e14_00000.c000.snappy.parquet
-rw-r--r-- 1 wakun supergroup 815 2021-05-12 17:05 /user/hive/warehouse/user1_bucket/part-00001-b657899a-401b-406b-b45d-ac4df1d72e14_00001.c000.snappy.parquet
-rw-r--r-- 1 wakun supergroup 833 2021-05-12 17:05 /user/hive/warehouse/user1_bucket/part-00001-b657899a-401b-406b-b45d-ac4df1d72e14_00002.c000.snappy.parquet
-rw-r--r-- 1 wakun supergroup 831 2021-05-12 17:05 /user/hive/warehouse/user1_bucket/part-00001-b657899a-401b-406b-b45d-ac4df1d72e14_00003.c000.snappy.parquet
....
-rw-r--r-- 1 wakun supergroup 788 2021-05-12 17:05 /user/hive/warehouse/user1_bucket/part-00001-b657899a-401b-406b-b45d-ac4df1d72e14_00008.c000.snappy.parquet
-rw-r--r-- 1 wakun supergroup 817 2021-05-12 17:05 /user/hive/warehouse/user1_bucket/part-00001-b657899a-401b-406b-b45d-ac4df1d72e14_00009.c000.snappy.parquet
Same data Key It must be in the same Bucket
scala> spark.read.parquet("/user/hive/warehouse/user1_bucket/part-00000-b657899a-401b-406b-b45d-ac4df1d72e14_00000.c000.snappy.parquet").show(false)
+---+---------+
|id |name |
+---+---------+
|21 |wankun-57|
|12 |wankun-73|
|37 |wankun-73|
|10 |wankun-89|
|17 |wankun-89|
|35 |wankun-89|
+---+---------+
scala> spark.read.parquet("/user/hive/warehouse/user1_bucket/part-00001-b657899a-401b-406b-b45d-ac4df1d72e14_00000.c000.snappy.parquet").show(false)
+---+---------+
|id |name |
+---+---------+
|70 |wankun-57|
|61 |wankun-73|
|86 |wankun-73|
|59 |wankun-89|
|66 |wankun-89|
|84 |wankun-89|
+---+---------+
scala> spark.read.parquet("/user/hive/warehouse/user1_bucket/part-00000-b657899a-401b-406b-b45d-ac4df1d72e14_00001.c000.snappy.parquet").show(false)
+---+---------+
|id |name |
+---+---------+
|1 |wankun-0 |
|8 |wankun-12|
|13 |wankun-12|
|16 |wankun-29|
|27 |wankun-85|
|34 |wankun-85|
+---+---------+
test bucket table join VS nonbucket table join
set spark.sql.autoBroadcastJoinThreshold=-1;
-- bucket table join
SELECT t1.id, t1.name, t2.id as id2, t2.name as name2
FROM user1_bucket t1
JOIN user2_bucket t2
ON t1.name = t2.name;
-- non bucket table join
SELECT t1.id, t1.name, t2.id as id2, t2.name as name2
FROM user1 t1
JOIN user2 t2
ON t1.name = t2.name;
Bucket Join The process 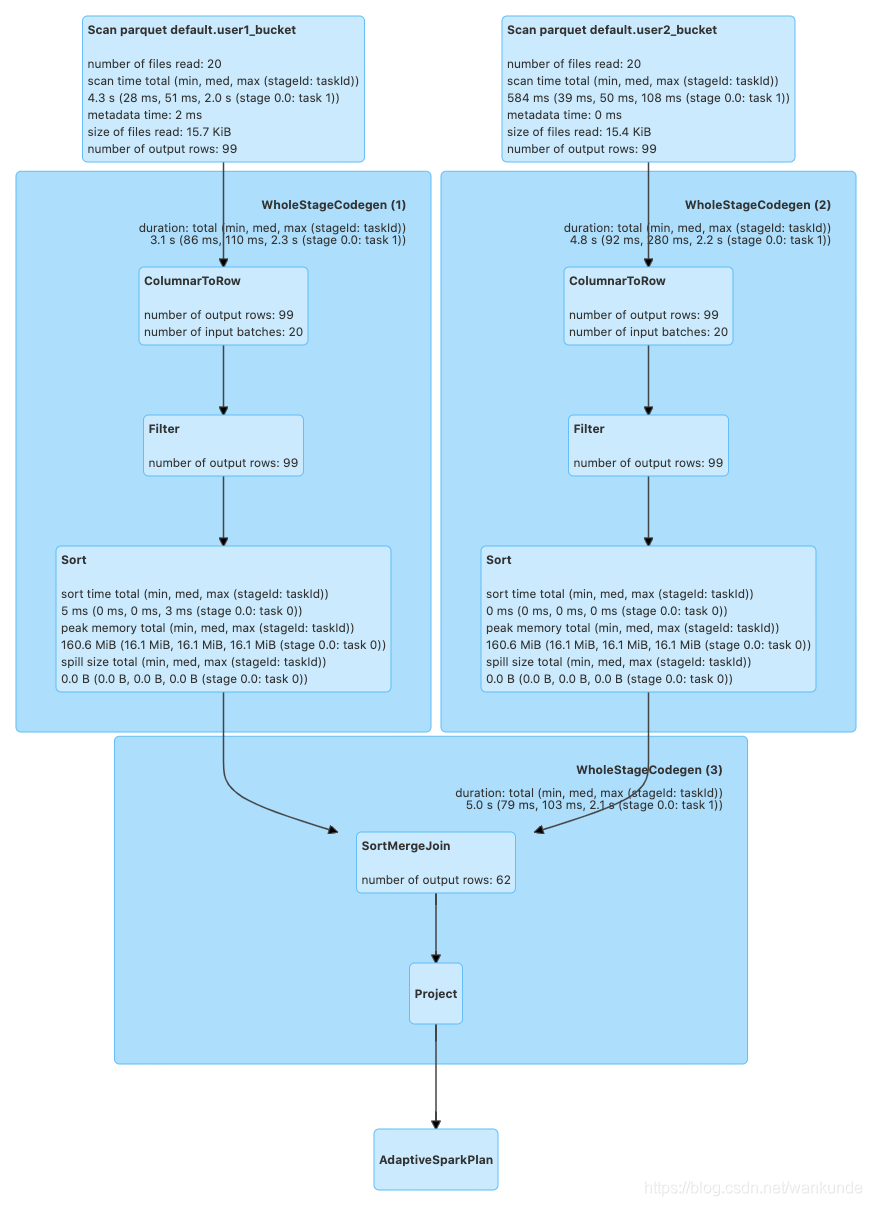
NonBucket Join The process 
by force of contrast ,Bucket Table Of Join One less time Shuffle The process of .
边栏推荐
- C语言:三子棋游戏
- Watermelon book machine learning reading notes Chapter 1 Introduction
- Distributed lock
- js使用for in和for of来简化普通for循环
- 使用Prometheus监控Spark任务
- C语言:数据的存储
- Spark TroubleShooting整理
- 2022-07-27 Daily: IJCAI 2022 outstanding papers were published, and 298 Chinese mainland authors won the first place in two items
- C语言:字符串函数与内存函数
- 使用解构交换两个变量的值
猜你喜欢
![[daily question 1] 558. Intersection of quadtrees](/img/96/16ec3031161a2efdb4ac69b882a681.png)
[daily question 1] 558. Intersection of quadtrees

实体类(VO,DO,DTO)的划分
/dev/loop1占用100%问题

QT (IV) mixed development using code and UI files

Spark 3.0 adaptive execution code implementation and data skew optimization

C语言:动态内存函数
C语言:数据的存储
Troubleshooting the slow startup of spark local programs

Spark 3.0 DPP实现逻辑

Leetcode interview question 17.21. water volume double pointer of histogram, monotonic stack /hard
随机推荐
Cap theory and base theory
【剑指offer】面试题39:数组中出现次数超过一半的数字
扩展Log4j支持日志文件根据时间分割文件和过期文件自动删除功能
实现自定义Spark优化规则
Network equipment hard core technology insider router Chapter 5 tompkinson roaming the network world (Part 1)
JS uses extension operators (...) to simplify code and simplify array merging
2022-07-27 Daily: IJCAI 2022 outstanding papers were published, and 298 Chinese mainland authors won the first place in two items
Network equipment hard core technology insider router chapter Cisco asr9900 disassembly (I)
[正则表达式] 匹配开头和结尾
Alibaba's latest summary 2022 big factory interview real questions + comprehensive coverage of core knowledge points + detailed answers
Leetcode 1143. dynamic programming of the longest common subsequence /medium
【剑指offer】面试题53-Ⅱ:0~n-1中缺失的数字——二分查找
【剑指offer】面试题42:连续子数组的最大和——附0x80000000与INT_MIN
Network equipment hard core technology insider router Chapter 10 Cisco asr9900 disassembly (III)
【剑指offer】面试题56-Ⅰ:数组中数字出现的次数Ⅰ
C语言:字符串函数与内存函数
C语言:函数栈帧
Spark 3.0 testing and use
Push down of spark filter operator on parquet file
股票开户佣金优惠,炒股开户哪家证券公司好网上开户安全吗