当前位置:网站首页>10 Convolutional Neural Networks for Deep Learning 3
10 Convolutional Neural Networks for Deep Learning 3
2022-08-04 04:06:00 【Water w】
本文是接着上一篇深度学习之 10 卷积神经网络2_水w的博客-CSDN博客
目录
A neural network design and the study:
4 Introduction of typical network
1 参数学习
A neural network design and the study:
Step 1:The structure of the design of network:卷积层,池化层,全连接层Step 2:设定超参数 hyper-paramenters卷积层的层数,The size of each convolution convolution kernels in layer、卷积核的个数、卷积操作的步长、 是否padding、训练时的学习率、batch size等If super parameter setting is ignored in fitting or owe fitting!!* Super and defines the concept about the model of a higher level of,如复杂度或学习能力(容量)* 超参数是Before starting the learning process Settings,而Not through trainingThe parameter data* 通常情况下,需要对超参数进行优化,选择一组最优超参数,以提高学习的性能和效果. (Through validation set configuration parameters)Step 3:参数学习 Based on a large number of sample data,Learn by error back propagation algorithm parameters (有监督学习)* 在卷积神经网络中,There are mainly two different function of the nerve layer:卷积层和池化层* Parameters for convolution kernels and offset,因此Only need to compute convolutionThe gradient layer parameters* 在全连接前馈神经网络中,Gradient mainly through each layer of the error term𝛿进行反向传播,Each layer parameters can be calculated by gradient* Similar to all connected feedforward network,Convolution network through误差反向传播算法For parameter learning
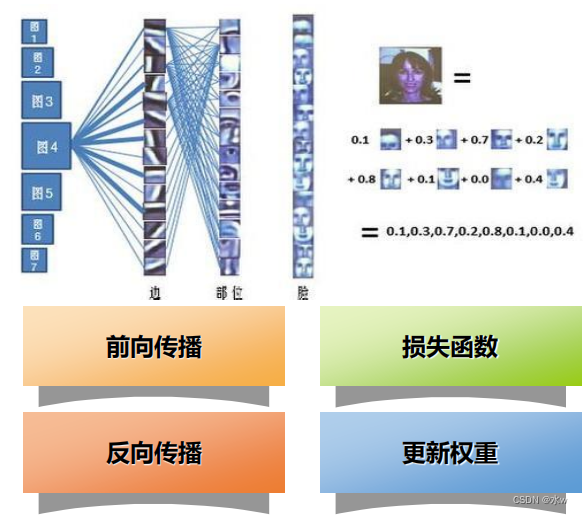
2 回顾:卷积神经网络

3 其他卷积方式
(1)普通卷积
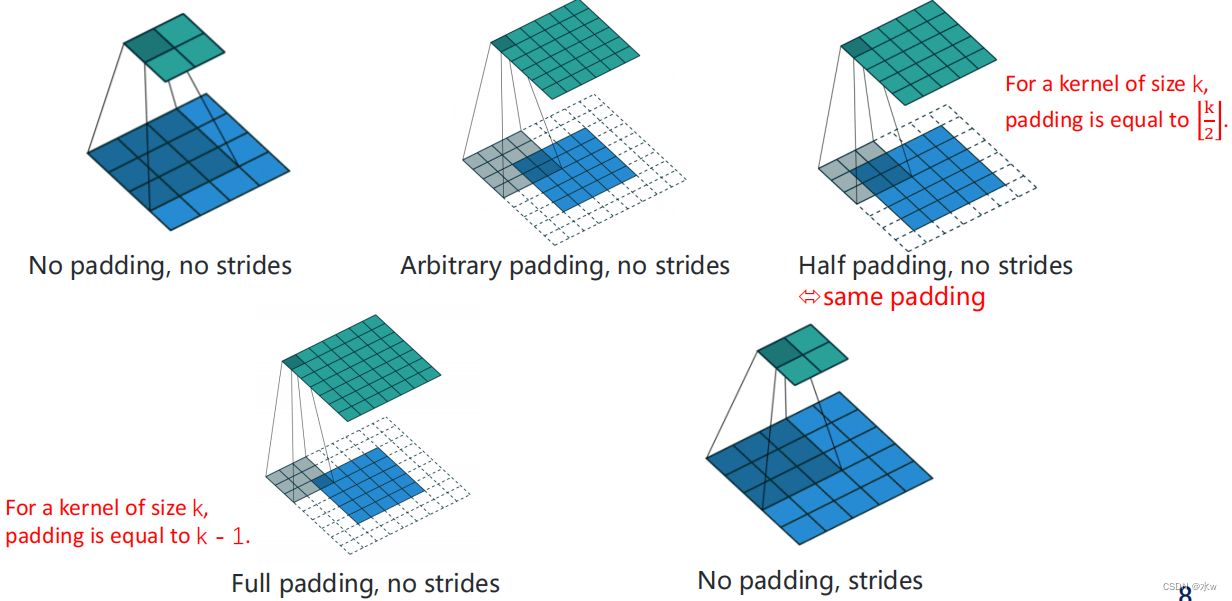
(2)转置卷积
一般可通过卷积操作来实现High-dimensional features to the low dimension conversion* As in a one-dimensional convolution,一个5维的输入特征,经过一个大小为3 的卷积核,其输出为3维特征* 如果设置步长大于1,可以进一步降低输出特征的维数.但在一些任务中,我们需要将低维特征映射到高维特征,并且依然希望通过卷积操作来实现 * 转置卷积A convolution can actually write for affine transformation in the form of仿射变换(Affine Transformation)Can achieve high dimensionality to low conversion,Also can achieve low dimension to high dimension conversion:
Convolution operation can also be written as affine transformation in the form of


From the point of view of affine transformation two convolution operationIs transposed in the form of the relationship between
We will lower dimensional mapped to high-dimensional feature characteristics of the convolution operation called转置卷积, 也称为反卷积(Deconvolution).在卷积网络中,卷积层的前向计算和反向传播也是一种转置关系.
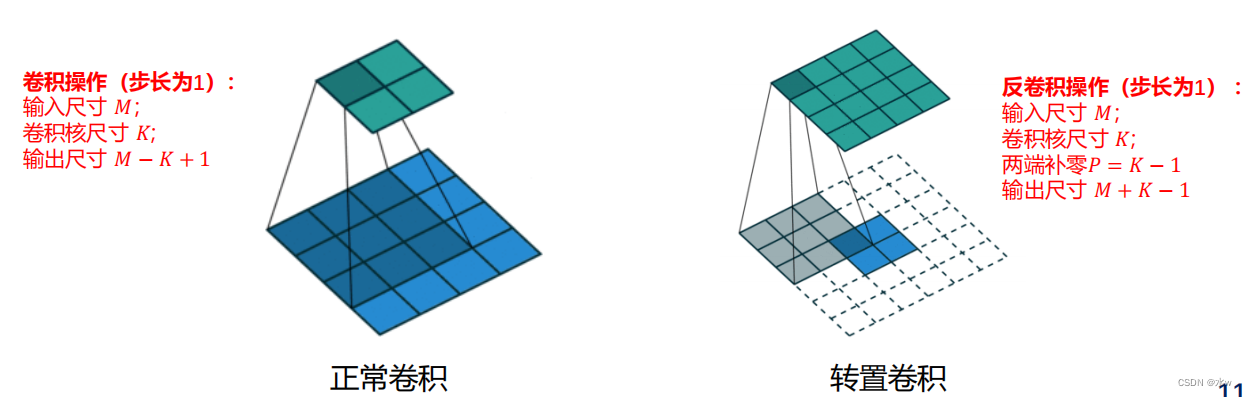
我们可以通过增加卷积操作的步长𝑆>1 来实现对输入特征的下采样操作,大幅降低特征维数We can also by reducing the step size of transposed convolution𝑆<1来实现上采样操作,大幅提高特征维数步长𝑆<1 的转置卷积也称为微步卷积(Fractionally-Strided Convolution)Convolution operation step for𝑆,Its corresponding transposed convolution step for1𝑆为了实现微步卷积,我们可以In the input features inserted between 𝑆 − 1 个0To make its movement speed indirectly slow
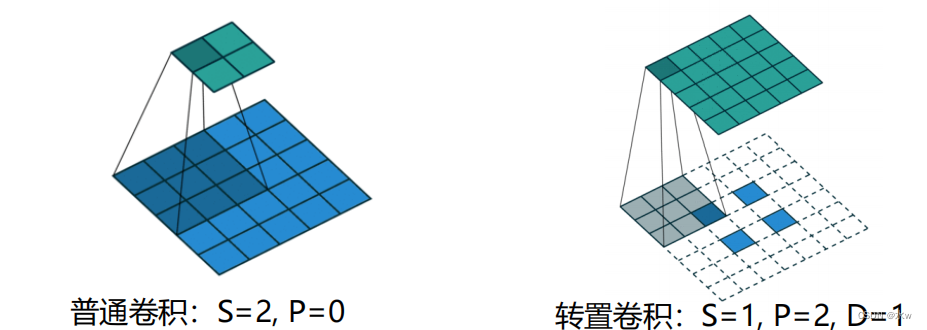
(3)空洞卷积
Q : Is how to increase the output of unit in the transmission of feeling wild?① 增加卷积核的大小;② 增加卷积层数;比如两层3 × 3 的卷积可以近似一层5 × 5 卷积的效果;③ Join the pooling operation;Q : These actions will bring what problem?① 前两种方式会增加参数数量② 第三种方式会丢失一些信息
空洞卷积(Atrous Convolution)是一种不增加参数数量,At the same time, increase output unit receptive field method也称为膨胀卷积(Dilated Convolution)空洞卷积通过给卷积核插入“空洞”To increase the scope of the receptive field如果Every two elements of the convolution kernels is inserted between 𝐷 − 1 个空洞,卷积核的有效大小为其中𝐷 称为膨胀率(Dilation Rate).当𝐷 = 1 时卷积核为普通的卷积核.
eg:左图中,原有的数据7x7是不变的,把一个3x3The convolution of check should be to5x5的区域上,那么我的这个3x3卷积核中 的9个参数,The formation of such a spacing,使得这9Data points are spaced.----膨胀率
3x3Convolution kernel coverage bigger,但是9个参数(信息)没变.Play with3x3The convolution kernel covering7x7The role of regional.
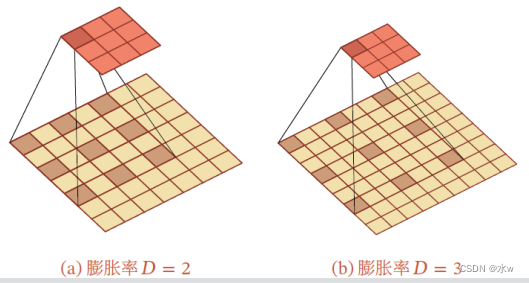
When an image contains information is not so much, 这种情况下,We can to reduce ginseng by hollow convolution number,达到相同的效果.
4 Introduction of typical network
Evolutionary context
(1)LeNet 1998
LeNet-5 [LeCun et al., 1998] Although the time is early,But it was a very successful neural network mode型.基于LeNet-5 的手写数字识别系统在20世纪90年代被美国很多银行使用,用来识别支票上面的手写数字.LeNet-5 的网络结构如图所示.As early as the depth of the convolutional neural network model,用于字符识别.网络具有如下特点:* 卷积神经网络使用三个层作为一个系列: 卷积,池化,非线性* 使用卷积提取空间特征* Using a mapping to the next sampling space average(subsampling)* 双曲线(tanh)或S型(sigmoid)In the form of a nonlinear activation* 多层神经网络(MLP)作为最后的分类器LeNetProvides the framework of the feature extraction by using the convolution layer stack,Open the development of the depth of convolution neural network.
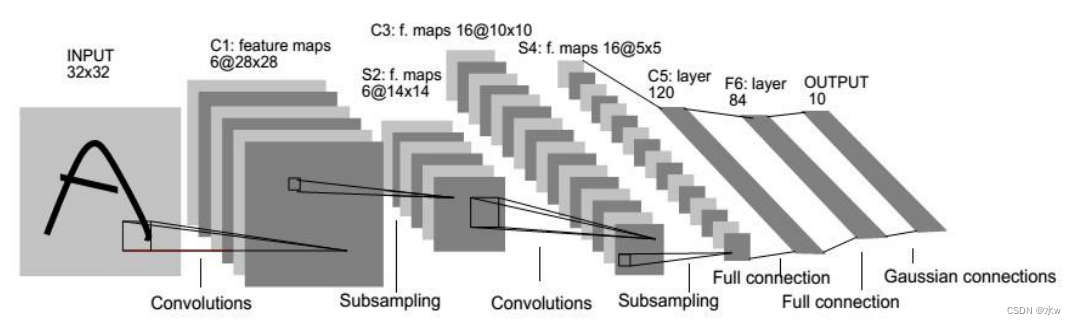 解释:
解释:
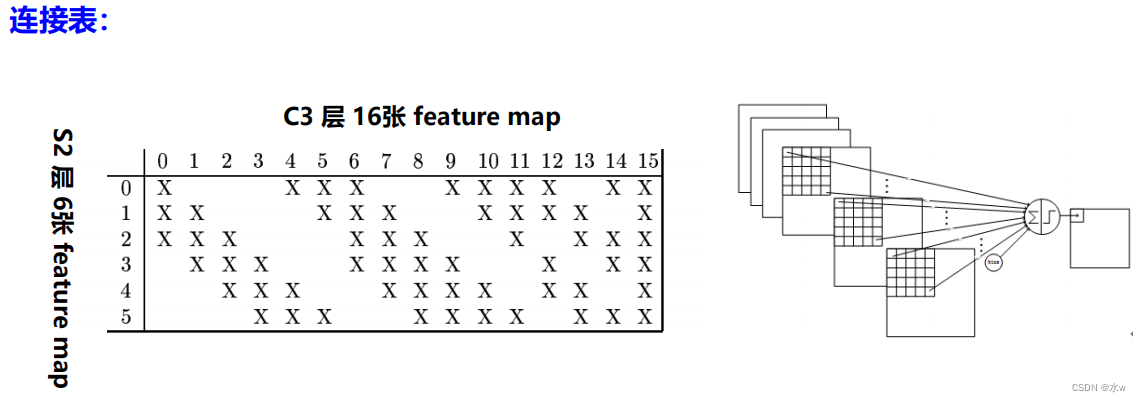
简单来说,例如对于C3层第0张特征图,Its every node and theS2层的第0、1、2共3A map of characteristics of5x5个节点相连接.对于C3层第1张特征图,Its every node and theS2层的第1、2、3共3A map of characteristics of5x5个节点相连接.
对于C3层第10张特征图,Its every node and theS2层的第0、1、4、5共4A map of characteristics of5x5个节点相连接.
In the end only a convolution kernel coverage in all6个通道.(2)AlexNet 2012
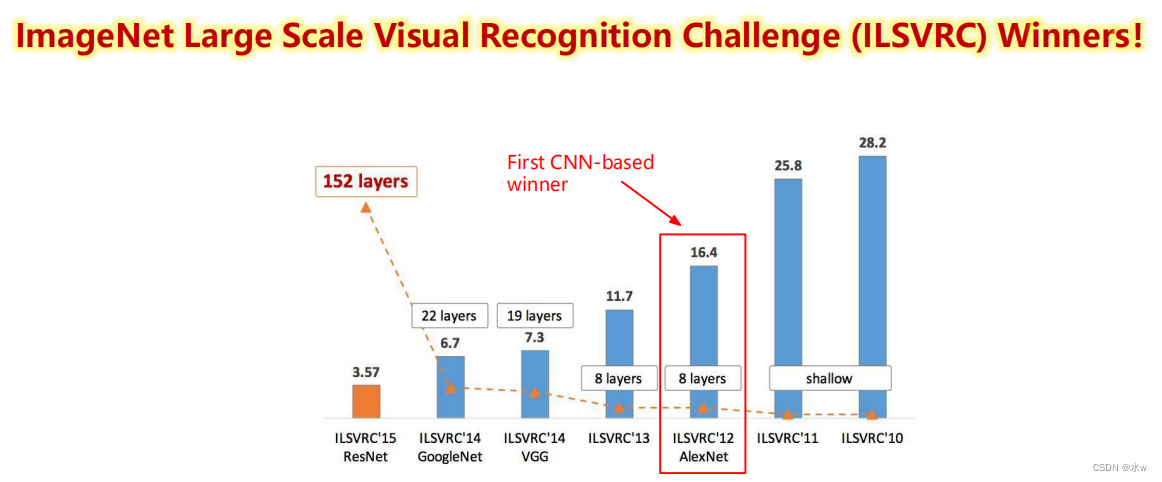
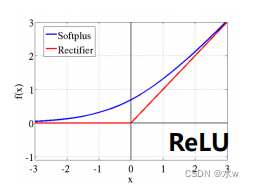
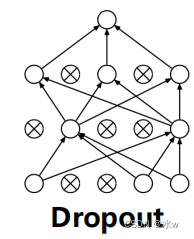
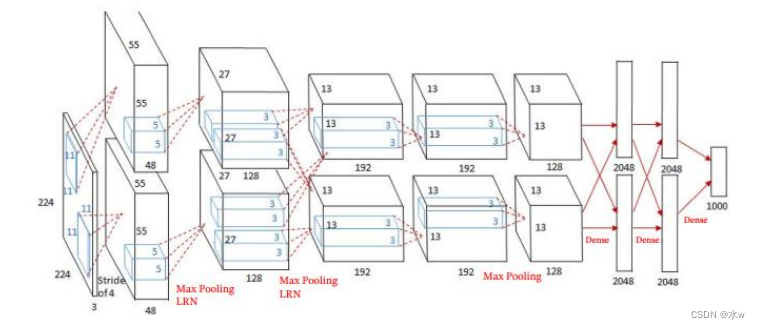
* 大数据训练:百万级ImageNet图像数据* 防止过拟合:Dropout, 数据增强* 分Group实现双GPU并行,局部响应归一化(LRN)层* 包括5个卷积层、3个池化层、3个全连接层* 非线性激活函数:ReLUAlexNet在LeNetBased on the deeper and wider network design,首次在CNN中引入了ReLU、Dropout 和Local Response Norm (LRN)等技巧.Technical characteristics of the network is as follows:*使用ReLU(Rectified Linear Units)作为CNN的激活函数,并验证其效果在较深的网络超过了Sigmoid,成功解决了Sigmoid在网络较深时的梯度消失问题,To improve the network training speed.*为避免过拟合,训练时使用Dropout随机忽略一部分神经元.*Use the overlap最大池化(max pooling).Biggest pooling can avoid average pooling blur effect,With overlapping technique can improve the characteristics of the richness.* 提出了LRN(局部响应归一化)层,在ReLUAfter the normalization processing,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力.* 利用GPUPowerful parallel computing ability to speed up network training过程,并采用GPUChunking memory to solve network scale for the limitations of the training of.* 数据增强:The random cutting and flip mirror operation increase the amount of training data,降低过拟合.

(3)Inception网络
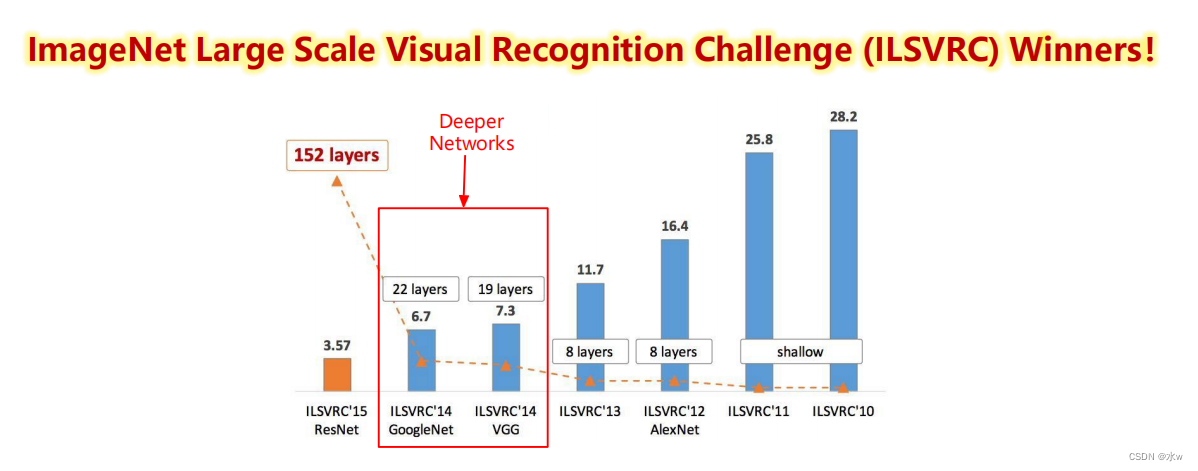
2014 ILSVRC winner (22层)• 参数:GoogLeNet (4M) vs AlexNet (60M)• 错误率:6.7%• InceptionNetwork is composed of have more than oneInception模块And a small amount of convergence layer stack.• Inception 网络有多个版本,Which one of the earliestInception v1 Version is very famousGoogLeNet [Szegedy et al., 2015].GoogLeNet 不写为GoogleNet,是为了向LeNet 致敬.GoogLeNet 赢得了2014 年ImageNet 图像分类竞赛的冠军.
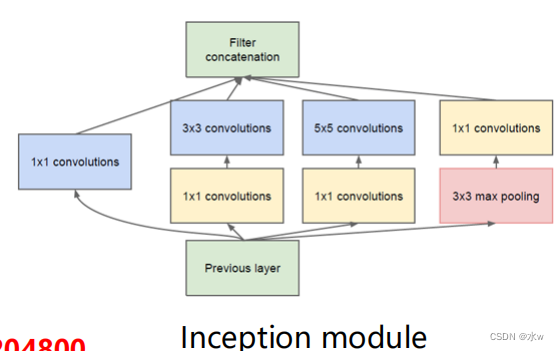
Inception module 包含四个分支:
* ShortcutA short branch connection:Before a layer of input through1×1卷积,Biggest role is to reduce the number of dimensions(降维),The original data fusion;* Multi-scale filtering branch:输入通过1×1Convolution respectively connected convolution kernels after to dimension reduction of size3和5的卷积;* 池化分支:Successively connected3×3 pooling和1×1卷积;改变通道数: 𝑾 × 𝑯 × 𝑪 → 𝑾 × 𝑯 × 𝑪′
Inception module 优点:
*减少网络参数,降低运算量上一层的输出为100x100x128,经过具有256个通道的5x5卷积层之后(stride=1,pad=2),输出数据为100x100x256,其中,卷积层的参数为(不考虑偏置):128x5x5x256= 819200而假如上一层输出先经过具有32个通道的1x1卷积层,再经过具有256个输出的5x5卷积层,那么输出数据仍为100x100x256,But the convolution number has reduce about4倍:128x1x1x32 + 32x5x5x256= 204800因此,1×1Convolution by dimension reduction is one of the role of network overhead.*多尺度、多层次滤波* 多尺度:Characteristics of input image, respectively, in3×3和5×5On the convolution kernels of filtering,Improve the learning characteristic of diversity,To enhance the network to the different scales of robustness.* 多层次:通过1×1Convolution has a high degree of correlation between different channel combinations of the filtering results of,构建出The reasonable structure of thin.因此,1×1Another function of convolution is the result of the lower filter for effective combination.
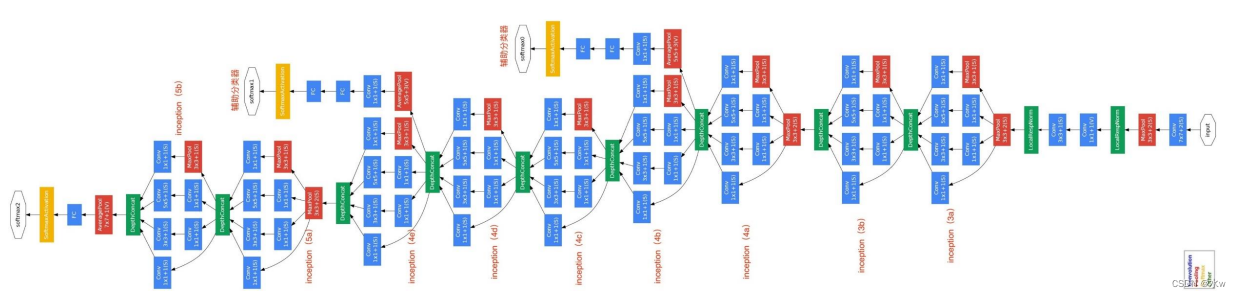
Inception模块 v1:GoogLeNet
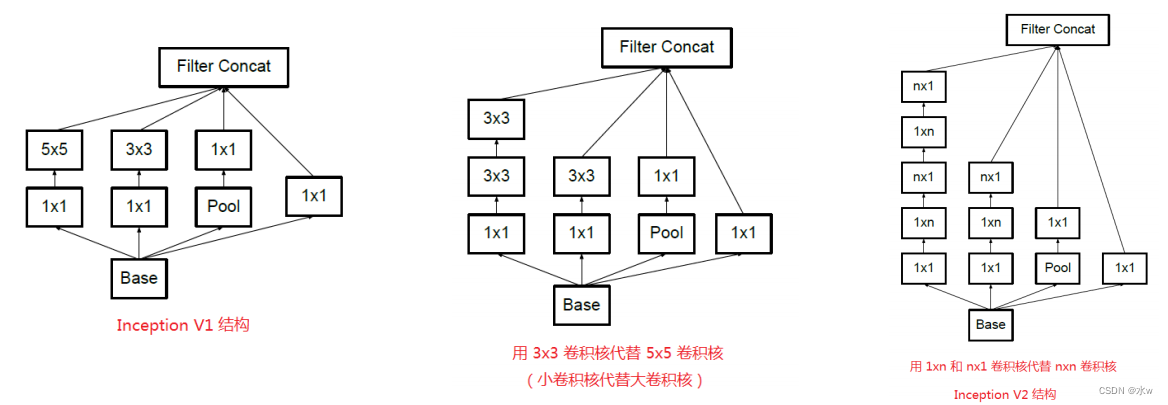
Inception模块 v3
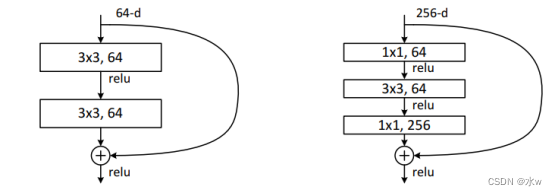
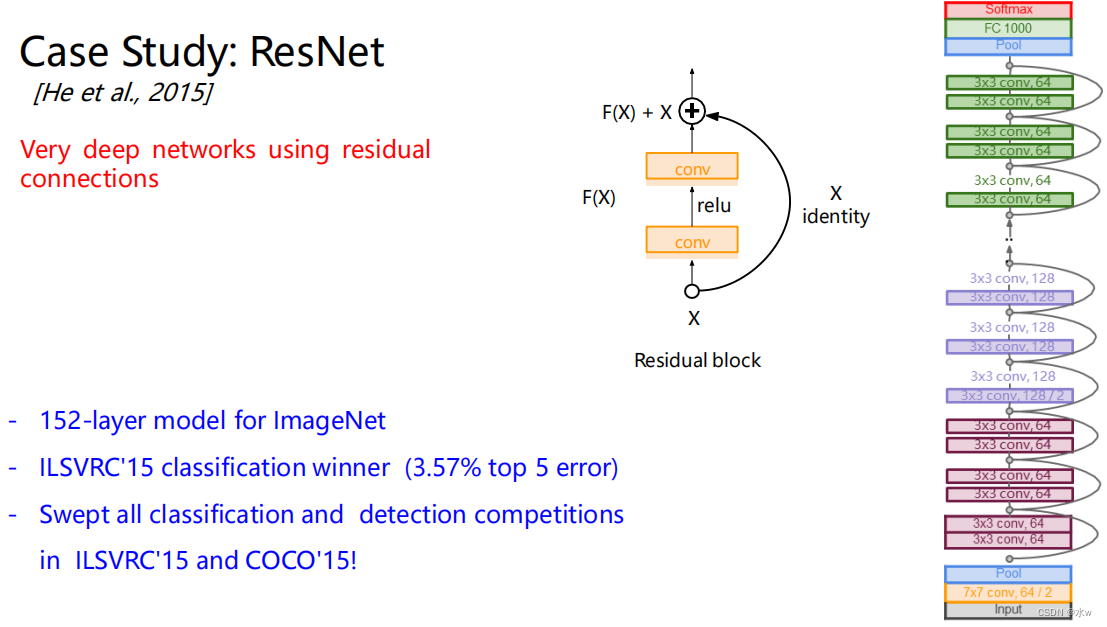
(4)残差网络
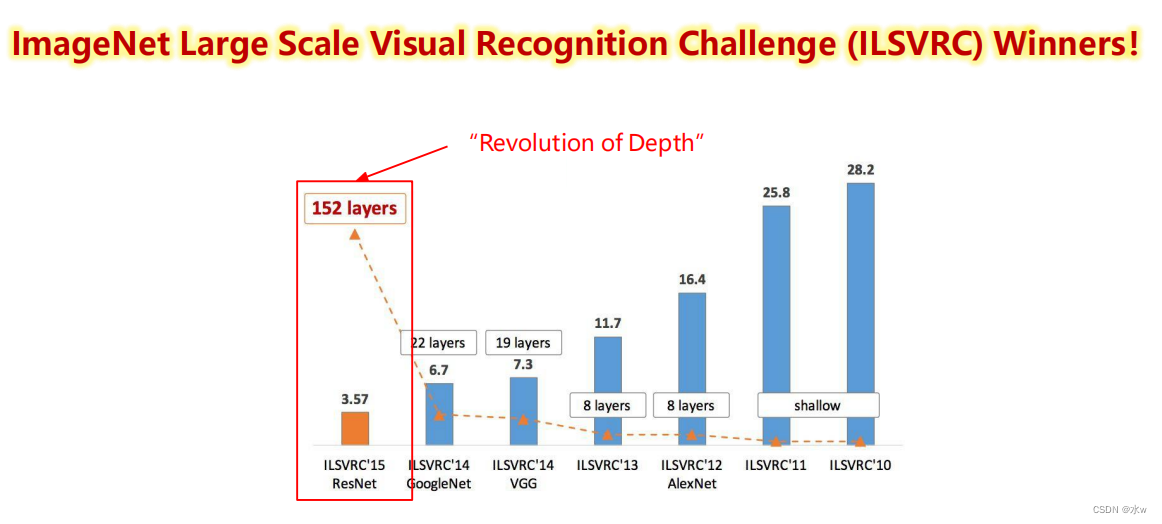
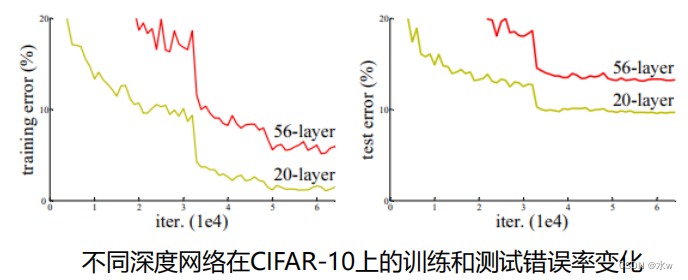
问题:Whether can learn better by simple layer stack network?* 梯度消失和爆炸:随着网络的加深,In the network will reverse the spread of the gradient as LianCheng becomes unstable定,变得特别大或者特别小. => 通过Normalized initialization 和 Batch normalization得到解决.* 网络退化(degradation): 随着网络的加深,First saturated accuracy,然后快速退化. => In the training set error rate also increased,So the effect of not been fitting.56Layer of the network is no than20Layer of the network is good,因为50Layer network hard training.
Simple layer stack can improve network performance,How to use the network to deepen the benefits of?
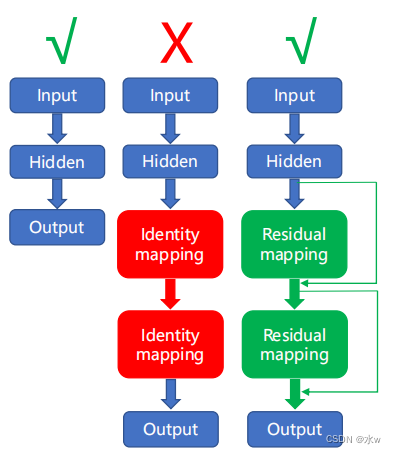
引入残差学习
* 实验表明,通过添加恒等映射Can't improve network accuracy,因此,Network of identity mapping approach is difficult.* Compared with the identity map,Network disturbance near to identity mapping learning easier.-->残差学习
Why is the residual?
* Very deep residual network can easily optimization.
* The depth of the residual network can easily from increasing the depth of the accuracy of earnings,At the same time network has a better effect than the former.
残差映射
优点:* No additional parameters and the computational overhead.* Easily and have the same structure“平常”网络进行对比.
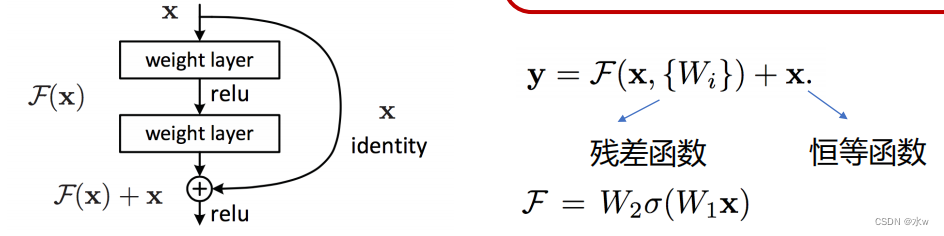
3)Deeper residual structure
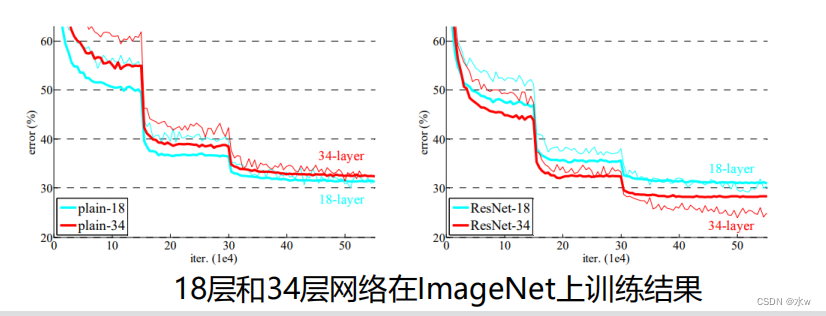
普通的网络,18层比34Layer of the network to be a bit better.34Layer less,And more throbbing,Instability is very high.Add residual after,34Layer of the network error will further reduce the,The result is better.
边栏推荐
- PL/SQL Some Advanced Fundamental
- 《nlp入门+实战:第八章:使用Pytorch实现手写数字识别》
- MySQL查询优化与调优
- How class only static allocation and dynamic allocation
- 如果禁用了安全启动,GNOME 就会发出警告
- mq应用场景介绍
- 类如何只能静态分配和只能动态分配
- This Thursday evening at 19:00, the fourth live broadcast of knowledge empowerment丨The realization of equipment control of OpenHarmony smart home project
- Senior PHP development case (1) : use MYSQL statement across the table query cannot export all records of the solution
- [Ryerson emotional speaking/singing audiovisual dataset (RAVDESS)]
猜你喜欢
系统设计.秒杀系统

This Thursday evening at 19:00, the fourth live broadcast of knowledge empowerment丨The realization of equipment control of OpenHarmony smart home project
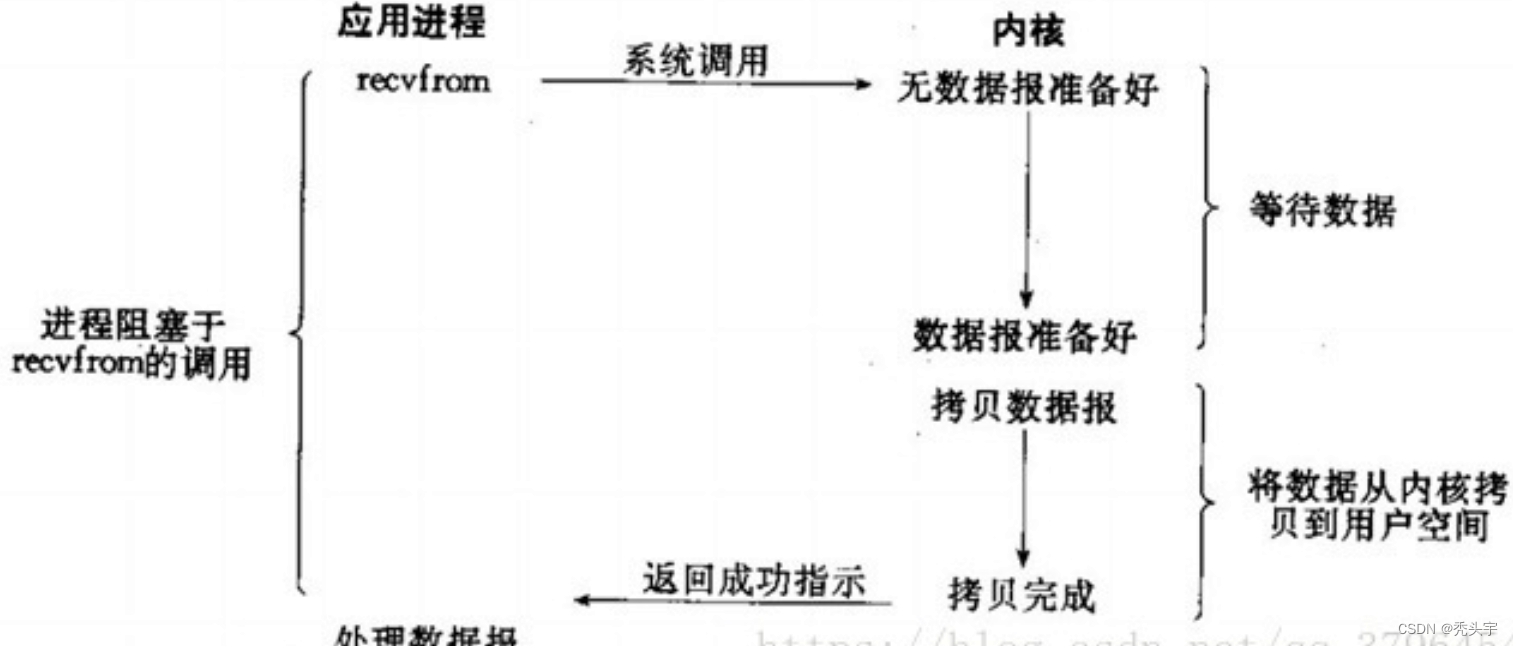
高效IO模型
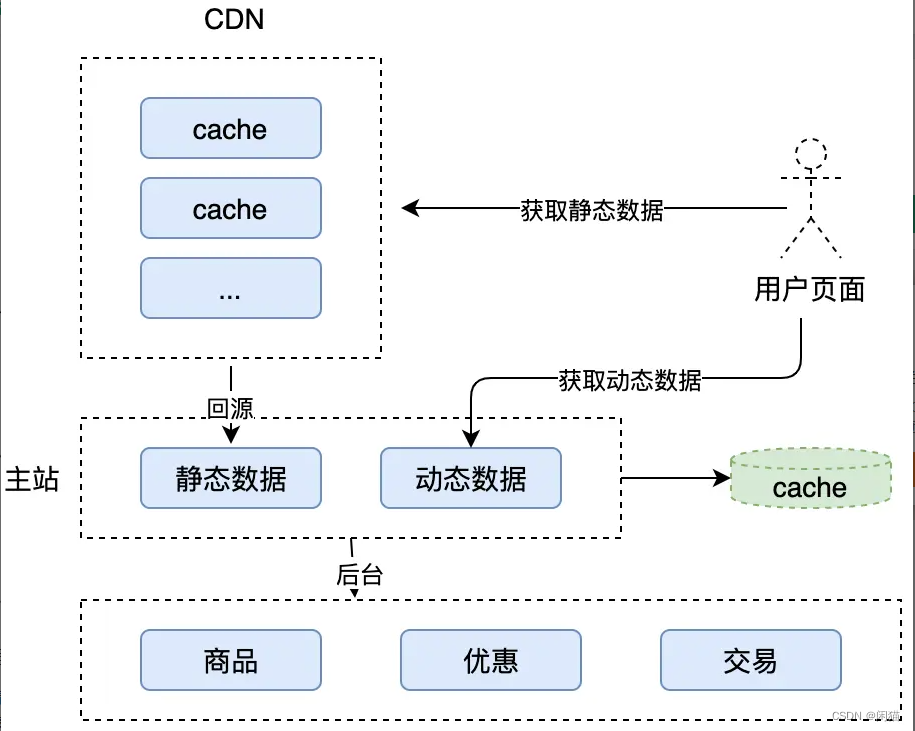
系统设计.如何设计一个秒杀系统(完整版 转)
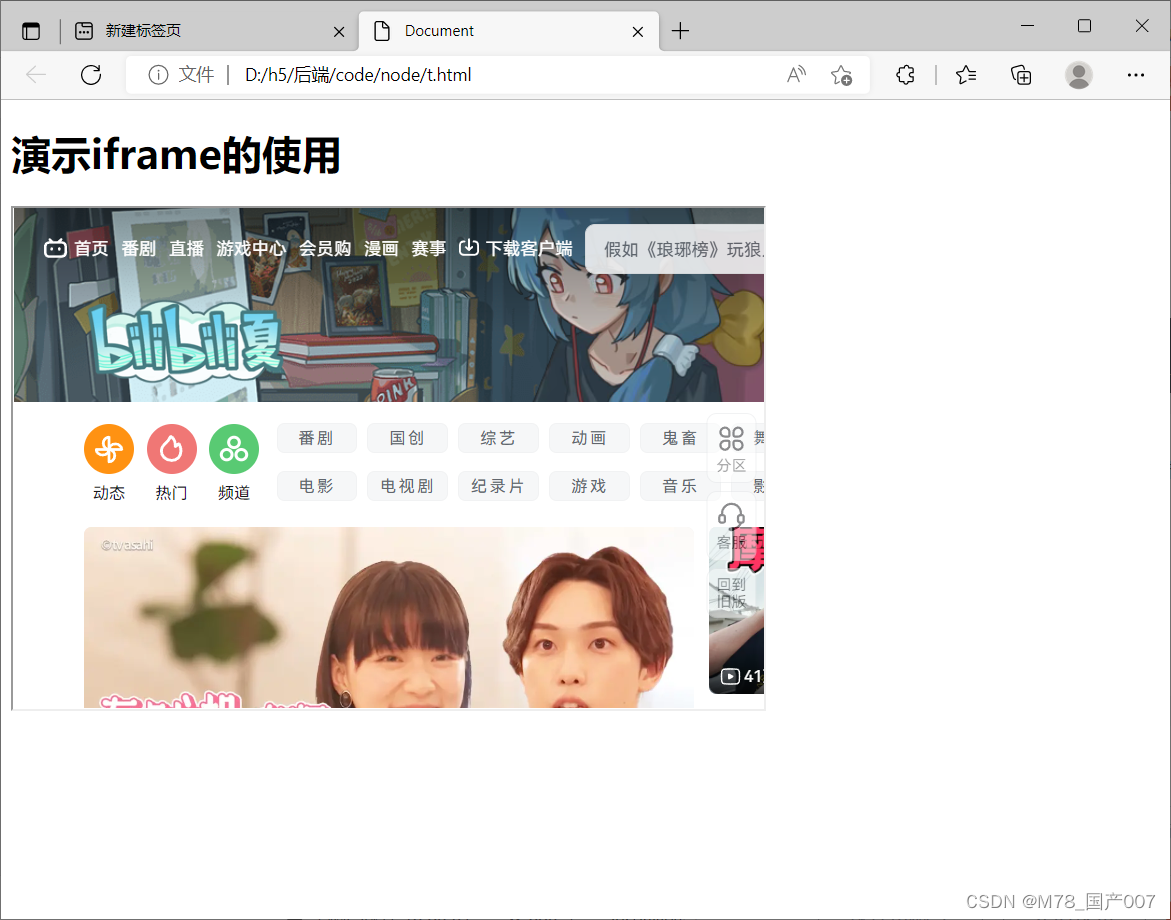
Learn iframes and use them to solve cross-domain problems

2022 Hangzhou Electric Power Multi-School League Game 5 Solution

网络工程师入门必懂华为认证体系,附系统学习路线分享

企业直播风起:目睹聚焦产品,微赞拥抱生态
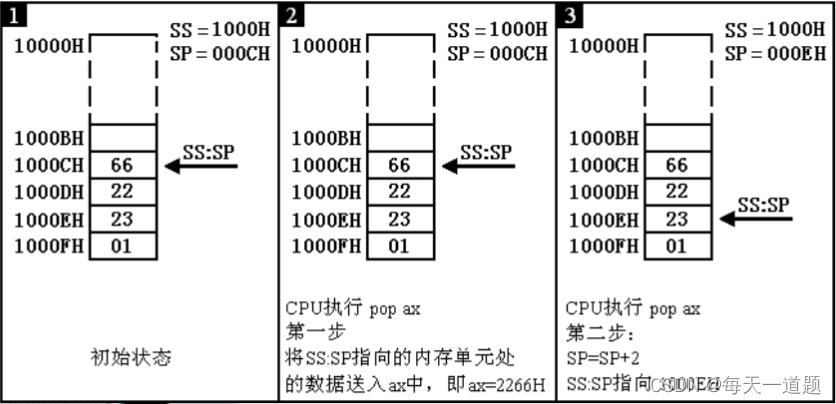
汇编语言之栈
base address: environment variable
随机推荐
千兆2光8电管理型工业以太网交换机WEB管理X-Ring一键环网交换机
《nlp入门+实战:第八章:使用Pytorch实现手写数字识别》
Hey, I had another fight with HR in the small group!
软件测试如何系统规划学习呢?
FPGA解析B码----连载3
八年软件测试工程师带你了解-测试岗进阶之路
Mobile payment online and offline payment scenarios
系统设计.秒杀系统
4-way two-way HDMI integrated business high-definition video optical transceiver 8-way HDMI high-definition video optical transceiver
PHP高级开发案例(1):使用MYSQL语句跨表查询无法导出全部记录的解决方案
Mockito单元测试
drools从下载到postman请求成功
7-2 LVS+DR概述与部署
mq应用场景介绍
汇编语言之栈
[Medical Insurance Science] To maintain the safety of medical insurance funds, we can do this
Deep learning -- CNN clothing image classification, for example, discussed how to evaluate neural network model
【 observe 】 super fusion: the first mention of "calculate net nine order" evaluation model, build open prosperity of power network
企业直播风起:目睹聚焦产品,微赞拥抱生态
Postgresql source code (66) insert on conflict grammar introduction and kernel execution process analysis