当前位置:网站首页>Point cloud perception algorithm interview knowledge points (I)
Point cloud perception algorithm interview knowledge points (I)
2022-06-12 01:33:00 【Like Rui's pig】
1. In a nutshell pointrcnn Based on the bin The return of the
answer :pointrcnn Is the first one based on pure point cloud anchor free Two stage approach , stay pointrcnn Previous papers used anchor base, It uses IOU Calculate whether it belongs to the positive sample . then pointrcnn in consideration of , For example, the distance between the point at the front of the car and the point at the door and the center is still very large , Direct regression is not good . Because classification is better than regression , therefore pointrcnn Just through bin The object center regression problem is transformed into a classification problem , The center of the object falls there bin Inside , And then we can go back to the central coordinates here bin The offset inside , So we can get the central coordinates of the object . In this way, the classification and regression method is more precise than the direct regression method , better .
2. Transformer Three vectors in Q、K、V Calculation method
answer : In the coding module , The self attention mechanism of the encoder first converts the input vector into three different vectors , Query vector 、 Key vector 、 Value vector , Then the vectors from different inputs are packed into three different matrices , Then the attention function between different input vectors is calculated by the following four steps :
The first step is to determine the degree of attention paid to other location data when encoding the current location data , Calculate the fraction between two different vectors S. The second step is to score S Standardize to Sn, Make it have a more stable gradient , In order to better train , The third step will use softmax The function divides the score Sn Convert to probability P. The fourth step is to obtain the weight matrix , Each value vector V Multiply by the probability P, A vector with a high probability will be paid more attention by subsequent layers . This process can be uniformly expressed as :
3. In the convolution layer BatcnNorm The role of
answer : Increasing the learning rate makes learning faster ; Less weight dependent 、 The initial value of the offset ; It can restrain the occurrence of over fitting phenomenon .
notes :BatchNorm, The average value of the input data is 0、 The variance of 1( Appropriate distribution ) Regularization of , Then we translate and rotate the regularized data .
4. How to solve the problem of imbalance between positive and negative samples , How to calculate the solution ?
answer : Usually use focal loss Loss function to solve the imbalance problem of positive and negative samples . The loss function reduces the weight of a large number of simple negative samples in training , It can also be understood as a kind of difficult sample mining .
Focal loss It is based on the cross entropy loss function , First, the binary cross entropy loss function is : y/ Is the output of the activation function , So in 0-1 Between . It can be seen that the common cross entropy loss function for positive samples , The greater the output probability, the smaller the loss . For negative samples , The smaller the output probability, the smaller the loss . At this time, the loss function is slow in the iterative process of a large number of simple samples and may not be optimized . therefore Focal loss Improved binary classification cross entropy :
y/ Is the output of the activation function , So in 0-1 Between . It can be seen that the common cross entropy loss function for positive samples , The greater the output probability, the smaller the loss . For negative samples , The smaller the output probability, the smaller the loss . At this time, the loss function is slow in the iterative process of a large number of simple samples and may not be optimized . therefore Focal loss Improved binary classification cross entropy :
The first is introduction gama factor , When gama=0 when , Is the binary cross entropy function , When gama>0 when , It will reduce the loss of easily classified samples , To focus more on the difficult 、 Misclassified samples .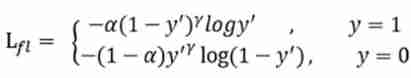
Then add the balance factor alpha, It is used to balance the uneven proportion of positive and negative samples . But if you just add alpha Although it can balance the importance of positive and negative samples , But it can't solve the problem of simple and difficult samples .
5. KITTI Data set easy、moderate、hard According to what definition ? P-R What is the curve , How to calculate ? AP_R40 What is it? ? threshold 0.7 What is it? ? How to calculate ?
answer : KITTI Data set easy、moderate、hard Depending on whether the dimension box is occluded 、 The degree of occlusion and the height of the box are defined , The specific data are as follows :
Simple :
Minimum bounding box height :40 Pixels , Maximum occlusion level : Completely visible , Maximum truncation :15%
secondary :
Minimum bounding box height :25 Pixels , Maximum occlusion level : Partial occlusion , Maximum truncation :30%
difficult :
Minimum bounding box height :25 Pixels , Maximum occlusion level : It's hard to see , Maximum truncation :50%
P-R In the curve P It stands for precision( Accuracy ),R It stands for recall( Recall rate ), It represents the relationship between accuracy and recall , In general , take recall Set to abscissa ,precision Set to ordinate . Every one of them P-R Each curve corresponds to a threshold ( Such as threshold 0.7 etc. , It's through IOU Calculated : The intersection of two boxes divided by the Union )
computing method :
AP_R40
KITTI The official ranking list used AP_R11, namely AP_R11 = {0,0.1,…,1}. However , Even if the tangents match , contain 0 It will also lead to an increase in average accuracy of about 9%. To avoid this apparent performance improvement ,kitti The government has adopted a new 40 spot AP(AP_R40) To revise metrics and leaderboards , Exclude “0” And quadruple dense interpolation prediction , To achieve better results Precision / Recall Approximate value of the area under the curve . Now more and more papers begin to use AP_R40 To compare the performance of the algorithm model .
边栏推荐
- Perceptron from 0 to 1
- 大厂测试员年薪30万到月薪8K,吐槽工资太低,反被网友群嘲?
- Kill, pkill, killall, next, what I brought to you in the last issue is how to end the process number and rush!
- Mise en œuvre de l'ombre de l'animation du Vertex de l'unit é
- Practice of Flink CDC + Hudi massive data entering the lake in SF
- “还是学一门技术更保险!”杭州校区小哥哥转行软件测试,喜提10K+双休!
- “還是學一門技術更保險!”杭州校區小哥哥轉行軟件測試,喜提10K+雙休!
- Yixin Huachen talks about how to do a good job in customer master data management
- Streaming data warehouse storage: requirements and architecture
- Matlab 基础应用02 wind 股票数据介绍和使用案例:
猜你喜欢

Defect detection, introduction to Halcon case.

Low code platform design exploration, how to better empower developers

中创专利|中国5G标准必要专利达1.8万项,尊重知识产权,共建知识产权强国

Data in the assembly cannot start with a letter! 0 before the beginning of a letter
In the field of enabling finance, the transformation of state secrets makes security compliance more solid

河南中创|从云到边,边缘计算如何赋能数据中心

"C'est plus sûr d'apprendre une technologie!" Hangzhou Campus Little Brother transfer software test, Hi - Ti 10K + double break!

打造Flutter高性能富文本编辑器——渲染篇

MySQL实训报告【带源码】
Henan Zhongchuang - from cloud to edge, how edge computing enables data centers
随机推荐
市场监管总局、国家网信办:开展数据安全管理认证工作
The annual salary of testers in large factories ranges from 300000 to 8K a month. Roast complained that the salary was too low, but he was ridiculed by netizens?
Given a project, how will you conduct performance testing?
Three times a day (in serial...)
【项目实训】微信公众号模板消息推送
Streaming data warehouse storage: requirements and architecture
jvm: 线程上下文类加载器(TheadContextClassLoader)
Unity顶点动画的阴影实现
Intel trimbert: tailor Bert for trade-offs
A knowledge map (super dry goods, recommended collection!)
Simulated 100 questions and simulated examination for safety management personnel of metal and nonmetal mines (small open pit quarries) in 2022
Data in the assembly cannot start with a letter! 0 before the beginning of a letter
Analysis report on operation trends and development strategies of global and Chinese plastic adhesive industry 2022-2028
Investment analysis and prospect forecast report of wearable biosensor industry for global and Chinese medical monitoring 2022 ~ 2028
博文推荐|BookKeeper - Apache Pulsar 高可用 / 强一致 / 低延迟的存储实现
Advanced data storage
[project training] verification notes
我在某大厂做软件测试工程师的《一天完整工作流程》
2022年重氮化工艺考试题库模拟考试平台操作
感知机从0到1