当前位置:网站首页>Unity game optimization [Second Edition] learning record 6
Unity game optimization [Second Edition] learning record 6
2022-06-13 05:30:00 【Salted fish never turn over】
The following is based on Unity 2020.1.01f Version
Unity Game optimization [ The second edition ] Learning record 6
- The first 6 Chapter Dynamic graphics
- One 、 Pipeline rendering
- Two 、 Performance detection problems
- 3、 ... and 、 Rendering performance enhancements
- 1、 Enable / Ban GPU Skinning
- 2、 Reduce geometric complexity
- 3、 Reduce surface tessellation
- 4、 application GPU Instantiation
- 5、 Use grid based LOD
- 6、 Use occlusion culling
- 7、 Optimize the particle system
- 8、 Optimize Unity UI
- 9、 Shader optimization
- 10、 Use less texture data
- 11、 Test different GPU Texture compression format
- 12、 Minimize texture swapping
- 13、VRAM Limit
- 14、 Lighting optimization
- 15、 Optimize the rendering performance of mobile devices
The first 6 Chapter Dynamic graphics
One 、 Pipeline rendering
1、GPU front end
Front end refers to the rendering process GPU The part that handles vertex data . It is from CPU Receiving grid data in ( A lot of vertex information ) And issue Draw Call. then GPU Vertex information will be collected from mesh data , Transfer via vertex shader . Press for data 1:1 The scale is modified and output . after ,GPU Get a list of elements that need to be processed ( triangle ——3D The most basic shape in a graph ). Next, the rasterizer gets these elements , Determine which pixels of the final graph need to be drawn , And create an entity according to the vertex position and the current camera view . The list of pixels generated in this process is called "slice" , Will be processed on the back end .
2、GPU Back end
The back end describes the part dealing with slice elements in pipeline rendering . Each slice is passed through a slice shader ( Also known as pixel shader ) To deal with it . Compared with the slice shader , Slice shaders often involve more complex activities , For example, depth test 、alpha test 、 To color 、 Texture sampling 、 light 、 Shadows and some possible post effects . Then the data is drawn to the frame buffer , The frame buffer holds the current image , Once the rendering task of the current frame is completed , The image is sent to the display device ( For example, a display ).
Under normal circumstances , Images API Two framebuffers are used by default ( Although you can generate more framebuffers for custom rendering schemes ). At any time , A frame buffer contains the rendering into the frame 、 And display the data on the screen ; The other frame buffer is in GPU Activated after completing the command in the command buffer , Do image rendering . once GPU complete swap buffers command (GPU Request to complete the last instruction of the specified frame ), Just flip the frame buffer , To render a new frame .GPU Then use the old frame buffer to draw the next frame . Every time you render a new frame , Repeat this process , therefore ,GPU Only two framebuffers are needed to handle this task .
On the back end , Two indicators are often the root cause of bottlenecks —— Fill rate and memory bandwidth
1) Filling rate
Fill rate is a widely used term , It refers to GPU The speed of drawing slices . However , This includes only those slices that pass various conditional tests in a given slice shader . A slice is just a potential pixel , Only it fails any test , Will be discarded immediately . This can greatly improve performance , Because pipeline rendering can skip expensive drawing steps , Start processing the next slice .
One test that may cause a piece to be discarded is Z-Test, It checks whether the slices of the closer object have been drawn in the same slice position . If it has been drawn , Then discard the current slice . If you don't draw , Slices will be pushed through the slice shader , Draw on the target pixel , And consume a filling amount in the filling rate . Now? , Suppose you use this process for thousands of overlapping objects , Each object can generate hundreds of slices . This causes millions of slices to be processed per frame , Because from the perspective of the main camera , Slices may overlap . what's more , We are trying to repeat this process dozens of times per second . This is why it is important to perform many initialization settings in pipeline rendering , Obviously , Skipping these painting processes as much as possible will save a lot of rendering costs .
Fill rates are also consumed by other advanced rendering techniques , For example, shadow and post effect processing need to extract the same piece metadata , Perform your own processing in the frame buffer . even so , Because of the order in which the objects are rendered , We always redraw some of the same pixels , This is called overprinting , This is an important indicator to measure whether the filling rate is used effectively .
Over drawing :
Skip using overlay alpha Blend planar shading to render all objects , The amount of over drawing can be displayed intuitively . Areas that are redrawn more will appear brighter , Because the same pixels are superimposed and mixed many times . This is exactly Scene Window Overdraw Shading Mode shows how much the scene has been over drawn .
2) Memory bandwidth
GPU Another potential bottleneck in the back end is memory bandwidth . As long as GPU VRAM To pull the texture into a lower level of memory , It will consume memory bandwidth . This usually happens when sampling textures , Where the slice shader attempts to select matching texture pixels , To draw a given slice at a given location .GPU Contains multiple cores , Every kernel is accessible VRAM The same area of , There is also a much smaller local texture cache , To store GPU Recently used textures .
If you encounter a bottleneck in memory bandwidth ,GPU Will continue to get the necessary texture files , But the whole process will be limited , Because the texture cache will wait for the data to be acquired , Will process a given batch of slices .GPU Unable to push data back to the frame buffer in time , To render to the screen , The whole process is blocked , The frame rate will also decrease .
How to reasonably use the memory bandwidth needs to be estimated . for example : The memory bandwidth per kernel is per second 96GB, The target frame rate is... Per second 60 frame , Before reaching the bottleneck of memory bandwidth ,GPU Extractable per second 1.6GB(90/60) Texture data . Of course , This is not an exact estimate , Because there are still some cache losses , But it provides a rough estimate .
Please note that , This value is not what the game can do in the project 、CPU RAM or VRAM The maximum limit on the amount of texture data contained in . Actually , This metric limits the amount of texture swapping that can occur in a frame .
3、 Light and shadow
In all passes of pipeline rendering , Light and shadows tend to consume a lot of resources . Because the slice shader needs to pass information many times to complete the final rendering , So the back-end is at the fill rate ( A great deal needs to be drawn 、 Repaint 、 Merged pixels ) And memory bandwidth ( by Lightmap and Shadowmap Extra texture pulled in and out ) Aspect will be busy . This is why compared to most other rendering features , Real time shadows are extremely expensive , When enabled, it will significantly increase Draw Call Number of reasons .
1) Forward rendering
Forward rendering is the traditional way to render lights in a scene . In forward rendering , Each object is rendered multiple times with the same shader . The number of renderings depends on the number of lights 、 Distance and brightness .Unity Give priority to the directional light components that have the greatest impact on the object , And render the object in the reference channel , As a starting point . Then the same object is rendered repeatedly several times by using several powerful point light components nearby through the slice shader . Each point light source is processed on the basis of each vertex , All remaining light sources pass through “ Spherical harmonic function ” The technique is compressed into an average color .
To simplify these behaviors , The light can be Render Mode Adjusted for Not Important, And in Edit | Project Settings | Quality | Pixel Light Count Modify the parameters in . This parameter limits the number of lights collected by forward rendering , But when Render Mode Set to Important when , This value will be overwritten by any number of lights , therefore , This combination of settings should be used with caution .
It can be seen that , Use forward rendering to process scenes with a large number of point lights , Will lead to Draw Call The count increased explosively , Because there are a lot of rendering states to configure , Shader channels are also required .
2) Deferred Shading
Delayed rendering is sometimes called delayed shading , Is an item in GPU Technology that has been used for about ten years , But it has not completely replaced forward rendering , Because some procedures are involved , Mobile devices have limited support for it .
Deferred rendering works by creating a geometry buffer ( be called G-buffer), In this buffer , The scene is initially rendered without any lighting . I have this information , The delay shading system can generate lighting profiles in one process .
From a performance point of view , The results of delayed coloring are impressive , Because it can produce very good pixel by pixel illumination , And there's almost no need to Draw Call. One drawback of delayed shading is the inability to manage anti aliasing independently 、 Transparency and shadow application of animated characters ; Another problem is that it often requires high performance 、 Expensive hardware to support , And cannot be used on all platforms , So few users can use it .
3) Vertex lighting shading ( Tradition )
Vertex lighting shading is a large-scale simplification of lighting , Because lighting is processed by vertices, not pixels .
This technique is mainly used in some areas where shadows are not required 、 Simple for normal mapping and other lighting functions 2D game .
4) Global illumination
Global illumination , It's Baking Lightmapping An implementation of . Global illumination is in Lightmapping The latest generation of digital technology , It not only calculates how light affects a given object , It also calculates how light is emitted back from nearby surfaces , Allow an object to affect the lighting profile around it , This provides a very realistic shading effect . One such effect is called Enlighten Internal system to calculate . The system can create static Lightmap, You can also create precomputed real-time global illumination , It is a mixture of real-time and static shadows , Supports simulation of time of day effects without expensive real-time lighting effects ( The direction of sunlight changes with time ).
4、 Multithreaded rendering
Most systems turn on multi-threaded rendering by default , For example, desktop computers and terminal platforms CPU Have multiple cores to support multithreading .
Android The system can select Edit | Project Settings | Player | Other Settings | Multithreaded Rendering Check box to enable this function
IOS The multi-threaded rendering of the system can be used through program configuration Edit | Project Settings | Player | Other Settings | Graphics API Below Apple’s Metal API Turn on .
5、 Low level rendering API
Unity adopt CommandBuffer Class provides external rendering API. This allows the passage of C# The code issues advanced rendering commands , To directly control the rendering pipeline , For example, sampling specific materials , Render the specified object using the given shader , Or draw some procedural geometry N An example .
Two 、 Performance detection problems
1、 Analyze rendering problems
The performance analyzer can quickly locate the bottleneck in pipeline rendering to the two devices used :CPU perhaps GPU. You must use the... In the performance analyzer window CPU Utilization rate and sum GPU Use rate to check for problems , In this way, you can know which equipment is heavily loaded .
In order to perform accurate GPU Limited performance analysis tests , Should be in Edit | Project Settings | Quality | Other | V Sync Count disable Vertical Sync, Otherwise, the test data will be disturbed .
2、 Violence test
If the root cause of the problem cannot be determined after in-depth analysis of performance data , Or in GPU In case of constraints, it is necessary to determine the bottleneck of pipeline rendering , You should try to use the violence test , That is, remove the specified activities in the scene , And check whether the performance has been greatly improved . If a small adjustment results in a large increase in speed , It means that we have found an important clue where the bottleneck lies .
about CPU be limited to , The most obvious violence test is to reduce Draw Call To check if there is a sudden improvement in performance .
There are two good ways to test violence GPU Restricted applications , To determine whether the fill rate is limited or the memory bandwidth is limited , The two methods are reducing the screen resolution and reducing the texture resolution .
3、 ... and 、 Rendering performance enhancements
1、 Enable / Ban GPU Skinning
Through sacrifice GPU Skinning To reduce CPU or GPU Front end load .Skinning It is the process of transforming mesh vertices based on the current position of animated bones . stay CPU The animation system that works on converts the object's bones , Used to determine its current posture , But the next important step in the animation process is wrapping mesh vertices around these bones , To put the mesh in the final pose . So , Each vertex needs to be iterated , And perform a weighted average of the bones connected to these vertices .
The vertex processing task can be performed in CPU On the implementation , It can also be in GPU The front-end implementation of , Depending on whether or not GPU Skinning Options . This function can be used in Edit | Project Settings | Player Settings | Other Settings | GPU Skinning Next switch . After the function is turned on , Will Skinning Push activity to GPU in , But pay attention to ,CPU Data must still be transferred to GPU, And generate instructions for the task on the command buffer , Therefore, it will not be completely eliminated CPU The load of .
2、 Reduce geometric complexity
Chapter 4 introduces some grid optimization techniques , This helps reduce the vertex attributes of the mesh
3、 Reduce surface tessellation
Surface tessellation through product sum shaders is very interesting , Because surface subdivision is a relatively underused technique , Can really make graphic effects stand out in games that use the most common effects . however , It also greatly increases the workload of front-end processing .
In addition to improving the surface subdivision algorithm or reducing the load of other front-end tasks , Make the surface subdivision task have more free space , There are no other simple techniques to improve surface tessellation . Either way , If the front end encounters a bottleneck , But they are using surface subdivision technology , You should carefully check whether surface subdivision consumes a lot of resources at the front end .
4、 application GPU Instantiation
GPU Instantiation takes advantage of the fact that objects have the same render state , Quickly render multiple copies of the same mesh , Therefore, only a minimum of Draw Call. This is actually the same as dynamic batch processing , It's just not an automated process .
of GPU More about instantiation , see also Unity file , The website is :
https://docs.unity3d.com/Manual/GPUInstancing.html
5、 Use grid based LOD
LOD(Level Of Detail,LOD) It's a broad term , It refers to the distance between the object and the camera and / Or the space occupied by the object in the camera view , Dynamically replace objects . It is difficult to distinguish the difference between low-quality and high-quality objects at a long distance , Generally, objects are not rendered in a high-quality way , Therefore, it is possible to dynamically replace distant objects with a more simplified version .LOD The most common implementation is grid based LOD, As the camera gets farther and farther away , The mesh will be replaced with a less detailed version .
In order to use grid based LOD, You can place multiple objects in the scene , Make it have additional LODGroup Component's GameObject The children of .LOD The purpose of the group is to generate bounding boxes from these objects , And decide which object should be rendered according to the size of the bounding box in the camera's field of view . If the grid is too far away , You can configure it to hide all child objects . therefore , With the right settings , It can make Unity Replace the grid with simpler alternatives , Or eliminate the mesh completely , Lighten the burden of rendering .
however , This feature takes a lot of development time to fully implement ; Art must produce a less polygonal version of the same object , The level designer must generate LOD Group , And configure and test , To make sure they don't switch unharmoniously as the camera moves closer .
About grid based LOD More details about the functions , see also Unity file , The website is :
https://docs.unity3d.com/Manual/LevelOfDetail.html
Cull group (Culling Group) yes Unity API Part of , Allow creation of custom LOD System , As a way to dynamically replace certain game or rendering behaviors .
More about culling groups , see also Unity file , The website is :
https://docs.unity3d.com/Manual/CullingGroupAPI.html
6、 Use occlusion culling
One of the best ways to reduce fill rate consumption and over painting is to use Unity Occlusion removal system . The system works by dividing the world into a series of small units , And run a virtual camera in the scene , According to the size and location of the object , Record which cells are not visible to other cells ( Obscured ).
Be careful , This is different from the cone culling technique , The cone culls objects outside the current camera view . Cone culling is always active and automatic . Therefore, occlusion culling will automatically ignore the objects culled by the cone .
Only in StaticFlags The drop-down list is correctly marked as Occluder Static and / or Occludee Static To generate occlusion culling data .Occluder Static Is a general setting for static objects , They can block other objects , It can also be blocked by other objects .Occludee Static It's a special situation , For example, transparent objects always need to use other objects behind them to render , But if a large object obscures them , You need to hide it .
Because you must enable... For occlusion culling Static sign , Therefore, this function is not applicable to dynamic objects .
Enabling occlusion culling will consume additional disk space 、RAM and CPU Time . Additional disk space is required to store occlusion data , Need extra RAM To save the data structure , need CPU Process resources to determine which objects in each frame need to be occluded . If the scene is configured correctly , Occlusion culling can cull invisible objects , Reduce over drawing and Draw Call Count , To save fill rate .
7、 Optimize the particle system
1) Use the particle deletion system
Unity Technologies Posted an excellent blog post on this topic , Address the following :
https://blogs.unity3d.com/2016/12/20/unitytips-particlesystemperformance-culling/
( It's not available after trying )
2) Avoid recursive calls to particle systems
ParticalSystem Many methods in components are called recursively . The calls of these methods need to traverse each child node of the particle system , And call the... Of the child node GetComponent() Method to get component information .
There are several particle systems API Will be affected by recursive calls , for example Start()、Stop()、Pause()、Clear()、Simulate()、isAlive(). Each of these methods has a default of true Of withChildren Parameters . Pass this parameter false value ( for example : call Clear(false)) You can disable recursive behavior and child node calls . But this is not always ideal , Because usually we want all the child nodes of a particle system to be affected by method calls . therefore , Another way is to 2 The method adopted in Chapter : Cache particle system components , And iterate them manually ( Make sure to pass to each withChildren Parameters are false).
8、 Optimize Unity UI
1) Use more canvas
The main task of canvas component is to manage drawing in hierarchical window UI Grid of elements , And emit the... Required to render these elements Draw Call. Another important function of canvas is to merge meshes for batch processing ( The condition is that the materials of these meshes are the same ), To reduce Draw Call Count . However , When the canvas or its sub objects change , This is called “ Canvas pollution ”. When the canvas is contaminated , You need to work for all on the canvas UI Object regenerates the mesh , Before it can be issued Draw Call.
It is worth noting that , change UI The color attribute of the canvas element will not be polluted .
take UI Split into multiple canvases , The workload can be separated , Simplify the tasks required for a single canvas . under these circumstances , Even if a single element still changes , Fewer other elements need to be regenerated in response , This reduces performance costs . The disadvantage of this method is , Elements on different canvases will not be grouped together in batches , therefore , If possible , Try to combine similar elements with the same material in the same canvas .
2) Separate objects in static and dynamic canvas
You should try to generate a canvas , The method of grouping elements based on the time of element update . Elements can be divided into 3 Group : static state , Occasionally dynamic , Continuous dynamic . static state UI Elements never change , Typical examples are background drawings, etc . Dynamic elements can be changed , Occasionally, dynamic objects change only in response , for example UI Press or pause the button , Continuous objects are updated periodically , For example, animation elements .
3) Disable... For non interactive elements Raycast Target
4) Hide... By disabling the parent canvas component UI Elements
If you want to disable UI Part of , As long as its child nodes are disabled , You can avoid expensive re calls to the layout system . So , The canvas component can be enabled Property is set to false. The disadvantage of this method is , If any child object has Update()、FixedUpdate()、LateUpdate()、Coroutine() Method , You need to disable them manually , Otherwise, these methods will continue to run .
5) avoid Animator Components
Unity Of Animator The component was never intended for the latest version of UI System , The interaction between them is impractical . Each frame ,Animator Will change UI Attribute of element , Cause the layout to be polluted , Many internal regenerations UI Information . Should be completely avoided Animator, And make your own animation interpolation method or use a program that can realize this kind of operation .
6) by World Space The canvas explicitly defines Event Camera
Canvas can be used for 2D and 3D Medium UI Interaction , It depends on the canvas Render Mode The setting is configured as Screen Space(2D) still World Space(3D). Every time UI Interaction time , Canvas components will check their eventCamera Property to determine which camera to use . By default ,2D The canvas will set this property to Main Camera, but 3D The canvas will set it to null. Every time Event Camera when , All by calling FindObjectWithTag() Method to use Main Camera. Finding objects through tags is not like using Find() Other variations of the method are so bad , However, its performance cost is linear with the number of tags used in a given project . To make matters worse , stay World Space During a given frame of the canvas ,Event Camera The frequency of visits is quite high , This means setting this property to null, Will result in a huge loss of performance and no real benefit . therefore , For all World Space canvas , This property should be manually set to Main Camera.
7) Do not use alpha hide UI Elements
color Properties of the alpha The value is 0 Of UI The element will still emit Draw Call. Should change UI Elemental isActive attribute , To hide it if necessary . The other way is through CanvasGroup Components use canvas groups , This component can be used to control the of all child elements under it alpha transparency . Canvas group alpha Value is set to 0, The child objects will be known , So no... Will be sent Draw Call.
8) Optimize ScrollRect
· Make sure to use RectMask2D
· stay ScrollRect disable Pixel Perfect
· Manually deactivate ScrollRect Activities
Even if the moving speed is only a small part of pixels per frame , The canvas also needs to regenerate the whole ScrollRect Elements . Once the use ScrollRect.velocity and ScrollRect.StopMovement() Method detects that the moving speed of the frame is lower than a certain threshold . You can manually freeze its motion . This helps greatly reduce the probability of regeneration .
9) Use empty UIText Element for full screen interaction
majority UI A common implementation of is to activate a large 、 Transparent interactive elements to cover the entire entity screen , To force the player to process the pop-up window to go to the next step , But it still allows the player to see what happens behind the primary color . This is usually done by UI Image Component complete , Unfortunately, this may interrupt the batch operation , Transparency can be a problem on mobile devices .
An easy way to solve this problem is to use a UI Text Components . This creates an element that does not need to generate any renderable information , Only handle the interactive check of the bounding box .
10) see Unity UI Source code
Unity stay bitbucket Provided in the library UI The source code of the system , The specific website is :
https://bitbucket.org/Unity-Technologies/ui
After testing , The web address on the book is no longer available , have access to github Upper Unity Official source code :
https://github.com/Unity-Technologies/uGUI
If UI There are major problems with the performance of , You can look at the source code to determine the cause of the problem .
11) To view the document
Through the following page , You can learn more useful UI Optimization techniques , The website is :
https://unity3d.com/learn/tutorials/temas/best-practices/guide-optimizing-unity-ui
9、 Shader optimization
1) Consider using shaders for mobile platforms
Unity The built-in mobile shader in does not have any specific constraints on its use only in mobile devices . They are optimized for minimal resource usage .
These shaders can be used by desktop applications , But their graphic quality tends to decline . It is only a small problem whether the graphics quality can be accepted . therefore , Consider testing common shaders for mobile platforms , To check if they are suitable for the game .
2) Use small data types
GPU Use smaller data types to compute than use larger data types ( Especially on mobile platforms ) Often faster , So the first adjustment you can try is to use a smaller version (16 Bit floating point ) Or even a fixed length (12 Fixed position and fixed length ) Replace floating point data type (32 Bit floating point ). The size of the aforementioned data types will vary depending on the platform's preferred floating-point format . The sizes listed are the most common . Optimization comes from the relative size between formats , Because there are fewer bits to process .
Color values are a good choice to reduce accuracy , Because you can usually use low precision color values without significant shading loss . However , For graphic Computing , The effect of reducing accuracy is very unpredictable . therefore , Some tests are needed to verify whether reducing the accuracy will lose the fidelity of the graphics .
3) Avoid modifying precision during rearrangement
Rearrangement is a shader programming technique , It lists the components in the desired order and copies them into the new structure , Create a new vector from an existing vector . for example :
float4 input = float4(1.0,2.0,3.0,4.0);
float3 value = input.xyz;
have access to xyzw and rgba The notation references the same components in turn . Whether it's representing colors or vectors , They are just meant to make shader code easy to read . You can also list components in the desired order , To fill in the new data , And reuse them if necessary .
Converting one precision type to another in a shader is a time-consuming operation , Converting precision types during rearrangement is more difficult . If there are mathematical operations that use rearrangement , Make sure they do not convert precision types . It is wiser to use only high-precision data types from the beginning , Or reduce the accuracy completely , To avoid the need to change precision .
4) Use GPU Optimized auxiliary functions
Shader compilers are generally good at simplifying mathematical calculations to GPU Optimized version , But compiling custom code is unlikely to look like CG Library's built-in auxiliary functions and Unity CG Including other auxiliary functions provided by the file . Should be used as much as possible CG Library or Unity Auxiliary functions in the library , It can better complete the work of custom code .
5) Disable unwanted features
Just disable unimportant shader properties , You can save money .
6) Delete unnecessary input data
Shader code should be examined carefully , To ensure that all imported Geometry , Both vertex and slice metadata are actually used .
7) Just expose the variables you need
If you find that some variables always use the same value at the end of the project , You should replace them with constants in shaders , To remove excessive runtime load .
8) Reduce the complexity of digital computation
Complex mathematics can become a serious bottleneck in the rendering process , Therefore, its harm should be limited as far as possible . You can calculate complex mathematical functions in advance , And its output is stored in the texture file as floating-point data , A map as a complex mathematical function . After all , The texture file is just a huge block of floating-point data , Can pass x,y And color (rgba) These three dimensions are quickly indexed . This texture can be provided to shaders , And samples the table generated in advance in the shader at run time , Instead of doing complex calculations at runtime .
This technique requires additional graphics memory , Store textures and some memory bandwidth at runtime , But if the shader has received the texture but is not used alpha passageway , You can use the texture alpha Channels secretly import data into , Because the data has been transmitted , So there is no performance consumption at all .
9) Reduce texture sampling
Texture sampling is the core consumption of all memory bandwidth overhead . The less texture you use , The smaller the texture you make , The better .
What's worse is , Texture sampling out of sequence can give GPU Bring some very expensive cache loss . If you do , Textures need to be reordered , In order to sample in sequence . for example , use tex2D(y,x) replace tex2D(x,y), Then the texture lookup operation will traverse the texture vertically , Then traverse the texture horizontally , Almost every iteration causes cache loss . Simply rotate texture file data , And perform texture sampling in the correct order (tex2D(x,y)), It can save a lot of performance consumption .
10) Avoid conditional statements
modern CPU When running conditional statements , Will use many clever prediction techniques to take advantage of instruction level parallelism , This is a CPU A feature of , It attempts to predict the direction the condition will enter before the condition statement is actually parsed , And presumably start processing the most likely result of the condition with an idle kernel that is not used to parse the condition . If the decision is finally found to be wrong , Then discard the current result and select the correct path . As long as it is assumed that the cost of processing and discarding the wrong results is less than the time spent waiting for the correct path to be determined , And the correct times are more than the wrong times , This is it. CPU The net benefit of speed .
However , because GPU The parallelism of , This feature is for GPUS Architecture doesn't bring much benefit . therefore , You should avoid using branches and conditional statements in shader code .
11) Reduce data dependence
The compiler does its best to optimize the shader code without being more friendly GPU The underlying language , such , When dealing with other tasks , You don't have to wait for data . for example :
float sum = input.color1.r;
sum = input.color2.g;
sum = input.color3.b;
sum = input.color4.a;
This code has a data dependency , Due to sum Variable dependencies , Each calculation needs to wait for the end of the previous calculation before it can start . however , Shader compilers often detect this , And optimize it to use the version of instruction level parallelism :
float sum1,sum2,sum3,sum4;
sum1 = input.color1.r;
sum2 = input.color2.g;
cum3 = input.color3.b;
sum4 = input.color4.a;
In this case , The compiler will recognize and extract in parallel from memory 4 It's worth , And obtain all data independently through thread level parallelism operation 4 The sum is done after the values . Relative to serial execution 4 Value operations , Parallel operation can save a lot of time .
However, a long data dependency chain that cannot be compiled will definitely destroy the performance of the shader . for example :
float4 value1 = tex2D(_tex1, input.texcoord.xy);
float4 value2 = tex2D(_tex2, value1.yz);
float4 value3 = tex2D(_tex3, value2.zw);
anytime , Such strong data dependencies should be avoided .
12) Surface shaders
Unity The surface shader of is a simplified form of the slice shader , allow Unity Developers program shaders in a simpler way .
13) Use shader based LOD
You can force Unity Render remote objects with simpler shaders , This is an effective way to save filling rate , Especially when the game is deployed to multiple platforms or needs to support multiple hardware functions .LOD Keyword can be used in shaders to set screen size parameters supported by shaders . If at present LOD Level does not match this parameter value , It will go to the next fallback shader , And so on , Until you find a shader that supports the given size parameter .
About shader based LOD For more information , Please see the Unity file :
https://docs/unity3d.com/Manual/SL-ShaderLOD.html( I can't seem to get into this website )
10、 Use less texture data
This method is simple and direct , It is a good idea worth considering . Whether it is through the resolution or bit rate to reduce the texture quality , Can not achieve the desired quality of graphics , But sometimes you can use 16 Bit texture to get graphics without significant degradation in quality .
11、 Test different GPU Texture compression format
see Unity file , To learn about all available texture formats and Unity The default recommended texture format :
https://docs.unity3d.com/Manual/class-TextureImporterOverride.html
12、 Minimize texture swapping
If there is a problem with memory bandwidth , You need to reduce the amount of texture sampling in progress . There is no special technique here , Because memory bandwidth is only related to throughput , So the main indicator we consider is the amount of data pushed .
One way to reduce texture capacity is to directly reduce texture resolution , This reduces texture quality . But this is obviously not ideal , So another way is to reuse textures on different meshes using different materials and shader attributes . for example , Properly darkened brick textures can look like stone walls . Of course , This requires different render States , This method will not save Draw Call, But it can reduce the consumption of memory bandwidth .
There are also ways to combine textures into a set , To reduce the number of texture exchanges . If there is a set of textures that are always used together at the same time , Then they may merge , This can be avoided GPU Repeatedly pull different texture files in the same frame .
13、VRAM Limit
1) With hidden GameObject Preload texture
Blank textures used during asynchronous texture loading may affect the quality of the game . We want a way to control and force textures to be loaded from disk into memory , Then load into... Before you actually need it VRAM.
A common solution is to create a hide using textures GameObject, And put it somewhere in a path in the scene , Players will follow this path to where they really need it . Once the player sees the object , Copy texture data from memory to VRAM in , Render the pipeline . This method is a bit clumsy , But it's easy to achieve , For most cases .
You can also change the of materials through script code texture attribute , To control such behavior :
GetComponent()material.texture = textureToPreload;
2) Avoid texture jitter
In rare cases , If too much texture data is loaded into VRAM And the required texture does not exist , be GPU Texture data needs to be requested from memory , And overwrite one or more existing textures , Make room for it . Over time , Memory fragmentation will get worse , There is a risk , That is, just from VRAM The texture refreshed in needs to be taken out again in the same frame . This will lead to serious memory conflicts , Therefore, every effort should be made to avoid this situation .
14、 Lighting optimization
1) Use real-time shadows carefully
Shadows can easily become Draw Call And filling rate , So you should take the time to adjust these settings , Until the required performance and / Or graphic quality .
It is worth noting that , Because the only difference between hard shadows and soft shadows is that shaders are more complex , So relative to hard shadows , Soft shadows do not consume more memory or CPU. This means that an application with a sufficient fill rate can enable soft shadows , To improve the fidelity of graphics .
2) Use culling mask
Lighting components Culling Mask Attributes are layer based masks , Can be used to limit the objects affected by a given light .
Unmasked objects can only be part of a single layer , in the majority of cases , Reducing physical overhead may be more important than reducing lighting overhead . therefore , If there is a conflict between the two , Then this may not be the ideal method .
3) Use baked light textures
advantage : Low computational strength
shortcoming : Increased disk usage for applications 、 The possibility of memory consumption and memory bandwidth abuse .
15、 Optimize the rendering performance of mobile devices
1) avoid alpha test
2) To minimize the Draw Call
3) Minimize the number of materials
4) Minimize texture size
5) Make sure the texture is square and the size is 2 Power square
6) Use the lowest possible precision format in shaders
边栏推荐
- Celery understands
- 通过命令行创建harbor镜像库
- Mysql database crud operation
- Wang Dao Chapter II linear table exercises
- C language learning log 1.22
- Article 49: understanding the behavior of new handler
- Case - simulated landlords (upgraded version)
- 890. Find and Replace Pattern
- Web site learning and sorting
- Std:: Map initialization
猜你喜欢

How to Algorithm Evaluation Methods
Comment procéder à l'évaluation des algorithmes

Web site learning and sorting

KVM virtualization management tool
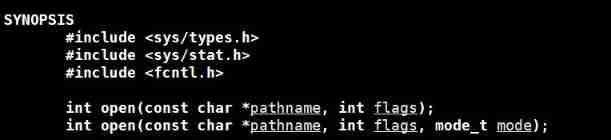
System file interface open

Database design

priority inversion problem

Pychart error resolution: process finished with exit code -1073741819 (0xc0000005)

Basic operations of MySQL auto correlation query

Dup2 use
随机推荐
【线程/多线程】线程的执行顺序
Web site learning and sorting
Create a harbor image library from the command line
Anaconda configuring the mirror source
C language learning log 1.2
行情绘图课程大纲1-基础知识
Django uses redis to store sessions starting from 0
Standard input dialog for pyqt5 qinputdialog
C language learning log 11.7
Simple sr: Best Buddy Gans for highly detailed image super resolution Paper Analysis
Dynamic and static libraries
metaRTC4.0稳定版发布
Agile conflicts and benefits
Luogu p1036 number selection
KVM virtualization management tool
Metartc4.0 integrated ffmpeg compilation
Jeffery0207 blog navigation
【多线程编程】Future接口获取线程执行结果数据
powershell优化之一:提示符美化
Information collection for network security (2)