当前位置:网站首页>Machine learning algorithm for large factory interview (5) recommendation system algorithm
Machine learning algorithm for large factory interview (5) recommendation system algorithm
2022-07-23 11:44:00 【I'm a girl, I don't program yuan】
List of articles
In computing advertising and recommendation systems ,CTR forecast (click-through rate) It's a very important part , Based on CTR Estimated click through rate to determine whether to recommend .
It's going on CTR Estimated time , In addition to single features , Always combine features .FM Algorithm is one of the common methods of feature combination .
FM
Problem description : How to solve the problem of sparse matrix encountered in the use of multi-level features
The paper :Rendle S. Factorization machines[C]//2010 IEEE International conference on data mining. IEEE, 2010: 995-1000.
background
Take the problem of advertising classification as an example , According to some characteristics of users and advertising spaces , To predict whether users will click on advertisements :
clicked Is the classification value , Indicate whether the user has clicked the advertisement .1 It means to click ,0 Indicates that... Is not clicked . and country,day,ad_type Is the corresponding feature . For this kind of categorical features , It's usually for one-hot Encoding processing .
Carry out the above data one-hot After coding , It's like this :
Feature fields:Country=USA and Country=China yes Feature field1,Day=26/11/15、Day=1/7/14 and Day=19/2/15 yes Feature field2,Ad_type=Movie and Ad_type=Game yes Feature field3.
the reason being that categorical features , So after one-hot After coding , Inevitably, the sample data becomes very sparse . thus it can be seen , Data sparsity , It is a very common challenge and problem we face in practical application scenarios .
Let's see another typical example of movie scoring , In order to predict the rating of different movies by different users , We use the following 5 Kind of (5-filled) features
- Current user information , It can be understood as user ID, As shown in the blue box below .
- The rating information of the current forecast movie , It can be understood as a movie ID.
- The scoring characteristics of other movies by current users .
- Time , Date of corresponding score
- One step movie recently rated by users

Feature combination
Ordinary linear model , We all consider each feature independently , The interrelationship between features is not considered . But actually , A large number of features are related . The simplest example is e-commerce , Generally, female users watch advertisements such as cosmetics and clothing more , Men prefer all kinds of ball equipment . That's obvious , This feature of women is closely related to cosmetics and clothing products , This feature of men is more closely related to ball equipment . If we can find these related features , Obviously, it is very meaningful .
Compared with the linear model ,FM There are more parts of the later feature combination .
Challenge& Solution
Because the features are too sparse , Satisfy x i , x j x_i,x_j xi,xj At the same time not for 0 Very few cases , Lead to w i j w_{ij} wij It's impossible to train to .
To find out w i j w_{ij} wij, For each characteristic component x i x_i xi Introduce auxiliary vector v i = ( v i 1 , v i 2 . . . v i k ) v_i=(v_{i1},v_{i2}...v_{ik}) vi=(vi1,vi2...vik), Its dimension k<<n. And then use v i v j T v_iv_j^T vivjT Yes w i j w_{ij} wij To solve the .

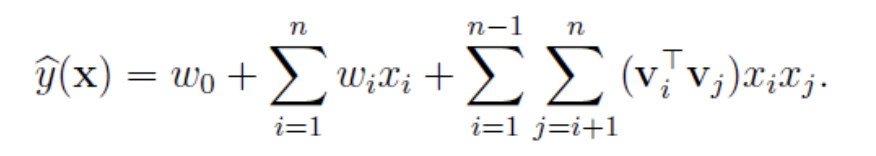
By simplifying , have access to SGD Solve the parameters .
Why split into v i v_i vi It works ?
- In terms of data volume, it turned out to be n ∗ n n*n n∗n Parameters of , Now it is n ∗ k n*k n∗k Parameters of ,k<<n.
- Features can interact , Even if there is no example of direct combination , You can also find potential relationships through iterative optimization .
- V and W The relationship between ?=> The origin of decomposition machine
Multi order features
Wide&Deep Model
Problem description : How to ensure the accuracy and generalization of hit in Recommendation System
The paper :Wide & Deep Learning for Recommender Systems
background
- wide The model is characterized by high dimensions ( First order + Second order equivalent ) As input , Using cross features can effectively achieve memory ability , achieve accurate Purpose . But the generalization ability of data that has never appeared is poor .
- DNN By integrating high-dimensional features embedding To low dimensional features , Ensure the Generalization ability ( Under the premise of losing certain expression ability ), Accuracy cannot be guaranteed .
Challenge: How to meet both the need and the problem ?
Solution

Wide part
Basic linear model , Expressed as y=WX+b.X The feature part includes basic features and cross features . Cross features in wide Part is important , It can capture the interaction between features , Play the role of adding nonlinearity . The cross feature can be expressed as :
Deep part
Feedforward network model . The feature is first transformed into a low dimensional dense vector , Dimension usually O(10)~O(100). Vector random initialization , After minimization function training model . The activation function uses Relu. The feedforward part is represented as follows :
among ,Deep The section contains a Embedding Layer: Due to the CTR The input is usually extremely sparse . So we need to redesign the network structure . The concrete implementation is , Before the first hidden layer , An embedding layer is introduced to compress high-dimensional sparse vectors into low dimensional dense vectors .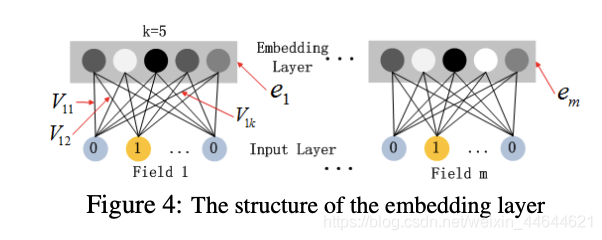
Suppose our k=5, First , For a record entered , The same field There is only one position 1, So the input gets dense vector In the process of , Only one neuron in the input layer works , Got dense vector In fact, it is the input layer to embedding The weight of the five lines connected to the neuron , namely vi1,vi2,vi3,vi4,vi5. The combination of these five values is that we are in FM As mentioned in Vi. stay FM Part and DNN part , This piece is shared weight , For the same feature , Got Vi It's the same .
Joint model
Wide and Deep Parts of the output are weighted together , And pass logistic loss function Perform final output .
test result 
DeepFM
Problem description : How to automatically fuse low-order and high-order features according to the original data
The paper :DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
background
- Wide&Deep The model needs manual design wide Part of the features to ensure the accuracy of the model , Can we learn this part of features automatically by machine =>FM
- On the basis of the above , We can make FM Layer And our DNN Some share the same feature input
Solution

FM The detailed structure of the part is as follows :
FM The output formula of :
Deep part :
advantage :
- DeepFM Model contains FM and DNN Two parts ,FM Models can be extracted low-order features ,DNN You can extract high-order features . There is no need to Wide&Deep Model artificial feature Engineering .
- Because the input is only the original feature , and FM and DNN Share input vector features ,DeepFM Model training is fast .
- Different field Different feature lengths , However, the output vector of the sub network must have the same dimension , namely dense embedding The output latitude of is the same ;
- utilize FM Implicit eigenvector of the model V Initializing as a network weight to obtain a sub network output vector ;
DeepCross
Problem description : If you use features bit High order cross multiplication between
The paper :Deep & Cross Network for Ad Click Predictions
background
Wide&Deep It is still necessary to manually design the feature cross multiplication . In the face of high-dimensional sparse feature space 、 A large number of composable ways , Based on artificial prior knowledge, although it can alleviate part of the pressure , But it still needs a lot of manpower and trial cost , And it is likely to miss some important cross features .FM Can automatically combine features , But also limited to the second-order cross product . Can we say goodbye to the manual combination features , And automatic learning of high-order feature combination ?Deep & Cross It is an attempt to do this .
Solution

cross:
- Finite higher order : The order of the cross product is determined by the depth of the network L c = > L c + 1 L_c=>L_c+1 Lc=>Lc+1
- Automatic cross multiplication :Cross The output contains the original features from the first order ( Namely itself ) To L c + 1 L_c+1 Lc+1 All cross product combinations of order , However, the number of model parameters only increases linearly with the input dimension 2 ∗ d ∗ L c 2*d*L_c 2∗d∗Lc
- Parameters of the Shared : Different cross products have different weights , But not every cross product combination corresponds to an independent weight ( Exponential order of magnitude ), Share through parameters ,Cross The parameter quantity is effectively reduced . Besides , Parameter sharing also makes the model more generalized and robust . for example , If you train weights independently , When training is focused x i ≠ 0 & x j ≠ 0 x_i \neq 0 \& x_j \neq 0 xi=0&xj=0 This cross multiplication feature does not appear , The corresponding weight must be zero , Parameter sharing does not , Similarly , Some noise in the data set can be corrected by most normal samples . Be similar to FM in V The design of the .
xDeepFM
Problem description : How to use features field High order cross multiplication between
The paper :xDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems
background
- Deep Cross The biggest problem is that he didn't field The concept of , In practice, our operation of feature fusion may be more concerned with field Level fusion and cross multiplication .
- stay DeepFM in , We will each field Mapped to the same dimension , The same is true in this article .
Solution
xDeepFM=Linear+CIN+Plain DNN
CIN:Compressed Interaction Network
For specific implementation, please refer to the following formula ,CIN The first k The output of the layer has H k H_k Hk The dimensions are D Eigenvector of . Each eigenvector represents the front k-1 Tier and tier 0 Layer vector between two Hadamard Product weighted sum .

What are the advantages ?CIN And DCN in Cross The design motivation of the layer is similar ,Cross Layer of input It is also the previous layer and the output layer . As for why ,CIN Keep it up DCN The advantages of : Finite higher order 、 Automatic cross multiplication 、 Parameters of the Shared .
CIN and DCN The difference between :
- Cross yes bit-wise Of , and CIN yes vector-wise Of ;
- CIN Take the characteristics of each order as the output
DeepFEFM
The paper :https://arxiv.org/abs/2009.09931
background
FM Model feature interactions = v i T v j x i x j =v_i^Tv_jx_ix_j =viTvjxixj, among v i 、 v j v_i、v_j vi、vj Corresponding to feature x i 、 x j x_i、x_j xi、xj, Without using field Information ;
FFM(Field-Awared Factorization Machine) Joined the field Consideration ,feature interactions = v i , F ( j ) T v j , F ( i ) x i x j =v^T_{i,F(j)}v_{j,F(i)}x_ix_j =vi,F(j)Tvj,F(i)xixj, But it causes a huge number of parameters ,complexity The disadvantage of being too high .
Solution
DeepFEFM(Field-Embedded Factorization Machine) structure feature interaction= v i T W F ( i ) , F ( j ) v j x i x j v^T_i W_{F(i),F(j)}v_jx_ix_j viTWF(i),F(j)vjxixj, among W F ( i ) , F ( j ) W_{F(i),F(j)} WF(i),F(j) It's a symmetric matrix , Study field i、j The relationship between .
Its model structure and DeepFM similar , The main difference is that DeepFM Of feature interaction= v i T v j x i x j v^T_i v_jx_ix_j viTvjxixj, among i、j To express directly field dimension ; in addition DeepFM Of DNN Input only uses a single feature embedding, and DeepFEFM take feature interaction Also joined DNN Of input, So as to improve the performance of the model . The original content is :
The DNN part of DeepFM takes input only the input feature embeddings, but we additionally also input FEFM generated interaction embeddings. Our ablation studies in Section 4 show that these FEFM interaction embeddings are key to the lift in performance achieved by DeepFEFM.

AutoInt
The paper :AutoInt: Automatic Feature Interaction Learning via Self-Attentive Neural Networks
background
DeepFM,Deep cross network,xDeepFM Equal depth learning recommendation algorithm aims to construct high-order cross features , But these methods have some flaws :
- fully-connected neural networks The extracted high-order features are learning multiplicative feature interactions On is inefficient Of ;
- The way of implicit learning feature intersection is lack of explicability .
The contribution of this paper lies in :
Proposed by Multi-head Self-Attention Mechanism Explicit learning of high-dimensional feature intersection One way , Improved Interpretability .
be based on self-attentive neural network Propose a new method , can Automatic learning High dimensional feature intersection , Effectively increasing the CTR Estimated Accuracy rate .
Solution
Model structure 
Input Layer
x = [x1; x2; …; xM], among M Means total feature fields Number of ,xi It means the first one i Features .
If xi Is discrete , Namely one-hot vector , If it's continuous , It's just one. scalar.
Embedding
Discrete characteristic embedding It's a matrix , And continuous type embedding It's a vector .
Interacting Layer
This layer uses multi-head attention, α m , k ( h ) \alpha_{m,k}^{(h)} αm,k(h) Express attention head h Next , features m And characteristics k Similar weight of :

Output Layer
Training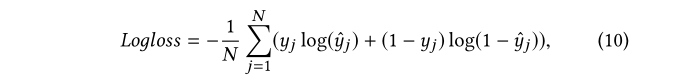
AutoDis
background
ctr The algorithm consists of two parts :feature embedding and feature interaction. So far, , The former algorithms focus on the feature interaction aspect , This paper focuses on the embedding The method has been improved .
Neural network input characteristics are divided into category The type and numerical type , Yes category Type features , In general use label coding( Map categories to integers ) after embedding look-up Methods ( Will be sparse one-hot A vector multiplied by a matrix is transformed into a dense vector ); about numerical features , There are several ways :
- no embedding: Directly use the value itself , problem :low capacity( In this paper, the capacity It can be understood that each feature is finally embedding Out of the dimension );
- field embedding: To belong to the same field Multiple numerical characteristics of , Use the same vector to embedding, problem :intra-field feature Linear correlation , Lose some expression , It's also low capacity Of ;
(On the contrary, A kind of naive Thought is the same field Set each feature in embedding vector , The problem lies in huge parameters and insufficient training for low-frequency features.) - discretization+embedding look-up: Use other methods first ( For example, separate boxes ) Discretize continuous features , Reuse category Type characteristic embedding Method , problem : The two parts are split , The rationality of the discrete method for this problem cannot be guaranteed ;
- The end-to-end AutoDis Method : Use meta-embedding, So that the discretization results can be adjusted according to the training objectives , End to end training .
Solution
AutoDis It can be divided into three modules :
One 、 Training meta-embedding
For each field Train one meta-embedding: M E ∈ R H × d ME\in{R^{H×d}} ME∈RH×d,field In all of the feature Share the M E ME ME,
The field The feature in can be discretized into H H H individual bucket, Each line is a embedding result , The ultimate goal is d Dimension vector .
Two 、Automatic Discretization
use first automatic discretization function d j A u t o ( ⋅ ) d_j^{Auto(·)} djAuto(⋅) take x Turn into x ~ \tilde{x} x~:
Reuse softmax take x ~ \tilde{x} x~ Turn into x ^ \hat{x} x^, here x ^ h \hat{x}^h x^h Express x Be discretized to the h individual bucket Probability :
3、 ... and 、Aggregation function
You can choose max、top-k sum、weighted-average Other methods , according to x ^ \hat{x} x^ and M E ME ME Calculate the final vector representation , If you choose x ^ h \hat{x}^h x^h The maximum value corresponds to M E ME ME The line of , Or right top-k Weighted sum of rows, etc .
Effect comparison
Set a field Yes m individual feature, The discretization method can be divided into 4 Categories , The target vector d dimension .
It can be seen that :
- field embedding and no embedding The minimum parameters required , but capacity be limited to ( The dimension of representation is small , or field There is a strong correlation inside );
- independent embedding and discretization+embedding The parameters of increase exponentially , and AutoDis Because of the whole field share ME, It won't be too big feature Quantity and sum embedding Dimension and parameter explosion ;
- discretization+embedding Discretization and DNN Training separation , The rationality of the discretization method and result to the problem itself cannot be guaranteed .
Reference material :
https://www.jianshu.com/p/152ae633fb00
https://www.jianshu.com/p/6f1c2643d31b
https://blog.csdn.net/weixin_45459911/article/details/106917001
边栏推荐
- Points for attention when using El table to lazy load tree tables
- Preliminary study on DC-1 shooting range
- Chinese interpretation of notepad++ background color adjustment options
- One of scala variables and data types
- MySQL functions & views & import and export
- Principle of file upload vulnerability
- 数字藏品开发/元宇宙数字藏品开发
- Accumulate SQL by date
- xtu-ctf Challenges-Reverse 1、2
- Custom MVC (Part 2)
猜你喜欢

数仓4.0笔记——数仓环境搭建—— Yarn配置

数仓4.0笔记——用户行为数据采集三

数仓4.0笔记——用户行为数据采集二

Vite x sigma creates designer specific I18N plug-ins

Compilation principle - detailed explanation of syntax analysis

NepCTF2022 Writeup
![[hudi]hudi compilation and simple use of Hudi & spark and Hudi & Flink](/img/6f/e6f5ef79c232d9b27a8334cd8ddaa5.png)
[hudi]hudi compilation and simple use of Hudi & spark and Hudi & Flink

Digital collection development / digital collection system development solution

Flex+js realizes that the height of the internal box follows the maximum height

NFT digital collection system development, development trend of Digital Collections
随机推荐
ES操作命令
Php+ code cloud code hook automatically updates online code
[metric] use Prometheus to monitor flink1.13org.apache.flink.metrics
Genesis曾向三箭资本提供23.6亿美元的贷款
Development of digital collection system: what are the main features of NFT?
编译原理-语法分析详解
laravel api接口+令牌认证登录
Mysqldump batch export MySQL table creation statement
mysql修改函数权限未生效
命令执行漏洞及防御
CTF-web 常用软件安装及环境搭建
Scala之二流程控制
NFT digital collection system development: the combination of music and NFT
xtu-ctf Challenges-Reverse 1、2
NFT digital collection development /dapp development
蚂蚁链NFT数字藏品DAPP商城系统定制开发
Pywinauto+ an application (learn to lesson 9) -- blocked
XML modeling
window下vmware使用无线网卡nat的方式上网
[hudi]hudi compilation and simple use of Hudi & spark and Hudi & Flink