当前位置:网站首页>Redis consistency hash and hash slot
Redis consistency hash and hash slot
2022-06-24 14:41:00 【Dream ~】
Reference resources :
- Confused by wechat again !
- redis Series of —— Uniformity hash Algorithm _ Zhuge little ape -CSDN Blog _redis Uniformity hash
- Redis The cache problem ( Cache penetration 、 Cache breakdown 、 Cache avalanche 、hash Consistency and data skew )_ Zhaoxinyu -CSDN Blog
The background :
frequently-used hash Although the algorithm can establish the mapping relationship between data and nodes , But every time the number of nodes changes , In the worst case, all data needs to be migrated , Therefore, it is not applicable to the distributed scenario where the number of nodes changes . In order to reduce the amount of data migrated , There is consistency hash Algorithm .
Application scenarios : Distributed cache system
1.Hash Ring :

Uniformity hash It means to be “ Storage nodes ” and “ data ” Are mapped to a connected hash On the ring . If you add or delete nodes , Only this node is affected in hash Clockwise adjacent successor nodes on the ring , Other data will not be affected .
First step : Hash the storage nodes , That is to do hash mapping for storage nodes , For example, according to the node IP Address hash ( use ip The address determines the number of nodes on the ring hash, such as ip The address is 1.2.3.4, Number of nodes N, Then it can be mapped to 1234%N Location );
The second step : When data is stored or accessed , Hash map the data ;
Uniformity Hash The algorithm uses “ Take the mold ”, And it's right 2^32 Power modulus , Its representable range is :0 ~ 2^32-1
How to determine if the data is located in hash Position on the ring ?
Put the data key Use Hash Function to calculate the hash value , And determine the position of this data on the ring , From this position along the ring Clockwise walk , The first server encountered is the server it should be located to !
such as :a、b、c Three key, After hashing , The position in the ring space is as follows :key-a Stored in node1,key-b Stored in node2,key-c Stored in node3.With the ordinary hash How are the algorithms different ?
ordinary hash The algorithm is to calculate the number of nodes hash, and Uniformity hash It's a fixed value 2^32 Take the mold
2. advantage :
Uniformity Hash The algorithm only needs to relocate a small part of the data in the ring space for the increase or decrease of nodes , Have a better Fault tolerance and scalability .
New server nodes / Delete server node : stay hash New servers in the ring , through hash The algorithm confirms the distribution , Just move a small part of the data ; The same goes for removal ( For example, you want to delete 4 node , Just put the original 1~4 Data between nodes is moved to 2 On the node ).

3. Prone to problems : Data skew
However, the consistent hash algorithm can not distribute the nodes evenly , A large number of requests will be concentrated on one node , In this case, disaster recovery and capacity expansion , Prone to avalanche chain reaction .
When the number of server nodes is too small , It is easy to cause data skew due to uneven distribution .
for example : There are only two servers in the system , At this time, a large number of data will be collected to Node 2 On , And only a very small number will be able to locate Node 1 On . The ring distribution is as follows :
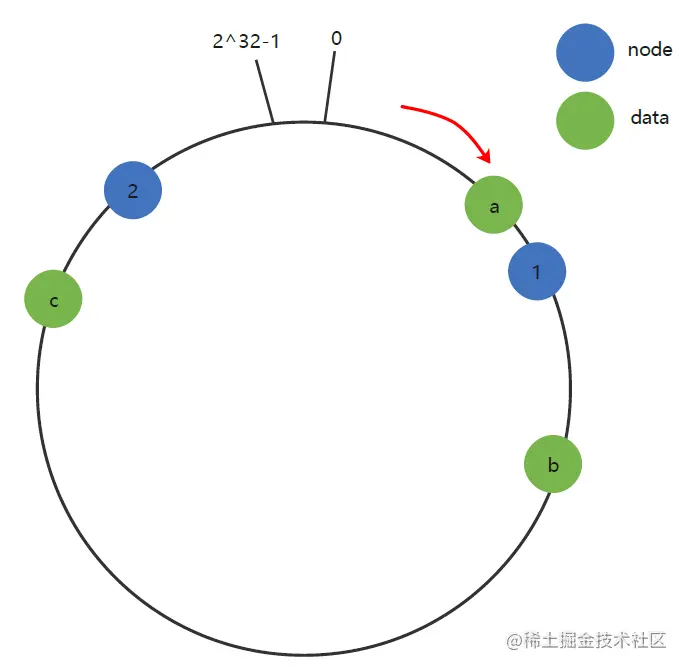
4. Data skew solutions : Virtual node mapping
In order to solve the problem that the consistent hash algorithm can not evenly distribute nodes , You need to introduce virtual nodes , Make multiple copies of a real node . No longer map real nodes to hash rings , Instead, map the virtual node to the hash ring , And map the virtual node to the actual node , So there's 「 Two layers of 」 The mapping relationship .
The mapping relationship : Cache data * Virtual node * Real nodes
- Virtual nodes map to physical nodes ,redis The number of hash slots is 16384 individual ,redis cluster It's using CRC16(key) % 16384 Algorithm ( See more at the end of the article ).
Personal understanding : In fact, by constructing a large number of virtual node mappings , Make when to redis Storage in the cluster k-v when ,hash The modulo value can be larger , In this way, the results of data modeling will be more scattered ( All data is interspersed and scattered on different real nodes )!
in application , The number of virtual nodes is usually set to 32 Even larger , Therefore, even a few service nodes can achieve relatively uniform data distribution .
specific working means : Can be on the server IP Or add a number after the host name to achieve , For example, the above situation , You can add three virtual nodes for each service node , So it can be divided into : RedisService1#1、 RedisService1#2、 RedisService1#3、 RedisService2#1、 RedisService2#2、 RedisService2#3
- about hash Ring for , More nodes , The smoother the data distribution . Therefore, virtual nodes are used , Virtualize a node into multiple nodes , Make sure there is... On the ring 1000~2000 Nodes are the best .
- commonly 10 individual Redis Cluster of servers , Each node can be virtualized 100-200 Nodes , Make sure there is... On the ring 1000-2000 Nodes
- commonly 5 individual Redis colony , Then each node is virtual 200-400 Nodes , Ensure that the number of nodes is 1000-2000 Between , In this way, the data distribution can be balanced
After introducing virtual nodes , It will improve the balance of nodes , It will also improve the stability of the system .
5. The above summary :
Uniformity Hash Algorithm , Mainly considering that each node of the distributed system may fail , And new nodes are likely to be added dynamically . How to ensure that when the number of nodes in the system changes ( newly added / Abridge ), Our system can still provide good service to the outside world ( Don't stop all redis service ), It's worth considering !
6.hash Slot
Basic concepts : Slots can be understood as partitions , Data is stored in partitions , Then the partition is dynamically bound to the machine .
redis-cluster Put all the “ Physical nodes ” Mapping to [0-16383] On the trough ( It doesn't have to be equal ),cluster Responsible for maintaining node ⇌ slot ⇌ value.
The reasons causing : If Redis Only the copy function is used as the master and slave , So when the amount of data is huge , In the case of a single machine, it may not be able to bear the next data , Not to mention that both the master and the slave should keep a complete copy of data . under these circumstances , Data fragmentation is a very good solution . So we can use hash The slot automatically slices the data , And distributed storage on each node . By assigning a different number of slots to each node , You can control the amount of data and requests that different nodes are responsible for .
hash The way : One redis The cluster contains 16384 Hash slot , Every data in the database belongs to this 16384 One of the hash slots . The cluster uses the formula CRC16(key) % 16384 To calculate the key key Which slot does it belong to . One redis The node contains N Slot , Data is passed through hash The algorithm hashes to a fixed slot , So the slot only determines where the data is stored , When multiple data hash When the results are the same , They are assigned to the same slot , That is, it will be mapped to the same service node .

Why? redis The cluster does not use a consistent hash algorithm ?
The node distribution of the consistent hash is based on the torus , The data distribution cannot be well controlled manually , For example, the hardware of some nodes is poor , I hope to save less data , This is very difficult to operate ( You have to use virtual node mapping , In a word, it is complicated ). and redis The slot space of the cluster can be allocated manually by users , Be similar to windows The concept of disk partition , You can control the size manually . Actually , Whether it is a consistent hash or a hash slot , When adding or removing nodes , Will affect part of the data , We need to migrate data , Of course ,redis The cluster also provides commands for manually migrating slot data .
边栏推荐
- Linux 安装 CenOS7 MySQL - 8.0.26
- Overview of SAP marketing cloud functions (III)
- 动作捕捉系统用于地下隧道移动机器人定位与建图
- Go language -init() function - package initialization
- 不要小看了积分商城,它的作用可以很大
- laravel下视图间共享数据
- 一个简单而功能强大的开发者工具箱Box3.cc
- R语言plotly可视化:可视化模型在整个数据空间的分类轮廓线(等高线)、meshgrid创建一个网格,其中每个点之间的距离由mesh_size变量表示、使用不同的形状标签表征、训练、测试及分类标签
- 港股上市公司公告 API 数据接口
- One article to get UDP and TCP high-frequency interview questions!
猜你喜欢
![[learn ZABBIX from scratch] I. Introduction and deployment of ZABBIX](/img/d1/4b21c8049f0377b54a18a9b267432e.png)
[learn ZABBIX from scratch] I. Introduction and deployment of ZABBIX

成功解决:selenium.common.exceptions.SessionNotCreatedException: Message: session not created: This versi

How to avoid placing duplicate orders
简谈企业Power BI CI /CD 实施框架
Successfully solved: selenium common. exceptions. SessionNotCreatedException: Message: session not created: This versi

leetcode.12 --- 整数转罗马数字

laravel8使用faker调用工厂填充数据
Wide measuring range of jishili electrometer

Don't underestimate the integral mall. It can play a great role

Linux 安装 CenOS7 MySQL - 8.0.26
随机推荐
Keras deep learning practice (11) -- visual neural network middle layer output
同样是初级测试工程师,为啥他薪资高?会这几点面试必定出彩
[learn ZABBIX from scratch] I. Introduction and deployment of ZABBIX
数据库注意事项
成功解决:selenium.common.exceptions.SessionNotCreatedException: Message: session not created: This versi
10_那些格調很高的個性簽名
Mots clés pour la cartographie es; Ajouter une requête par mot - clé à la requête term; Changer le type de mot - clé de cartographie
安防市场进入万亿时代,安防B2B网上商城系统精准对接深化企业发展路径
C language ---18 function (user-defined function)
Port conflict handling method for tongweb
MES在流程和离散制造企业的15个差别(下)
高薪程序员&面试题精讲系列115之Redis缓存如何实现?怎么发现热key?缓存时可能存在哪些问题?
Alibaba OSS object storage service
业务与技术双向结合构建银行数据安全管理体系
tongweb使用之端口冲突处理办法
50 practical applications of R language (23) - important concepts of Bayesian Theory: credibility, model models, and parameters
The security market has entered a trillion era, and the security B2B online mall system has been accurately connected to deepen the enterprise development path
Bert-whitening 向量降维及使用
Virtual machines on the same distributed port group but different hosts cannot communicate with each other
STM32F1与STM32CubeIDE编程实例-WS2812B全彩LED驱动(基于SPI+DMA)