当前位置:网站首页>Influxdb optimization configuration item
Influxdb optimization configuration item
2022-06-21 20:27:00 【51CTO】
Time series database InfluxDB
InfluxDB Is an open source database for storing and analyzing time series data . It is also the most used time series database .
Default configuration for common options (influxdb.conf)
#
Disable reporting switch , Default
Every time
24
Hours go by
usage
.
influxdata
.
com
Send report
reporting
-
disabled
=
false
#
For backup and recovery
RPC
Binding address of the service
bind
-
address
=
"127.0.0.1:8088"
[
meta]
#
Metadata storage directory
dir
=
"/var/lib/influxdb/meta"
#
retention
policy
Auto create switch
retention
-
autocreate
=
true
#
Metadata service log switch
logging
-
enabled
=
true
[
data]
#
Data directory
dir
=
"/var/lib/influxdb/data"
#
Pre - write log directory (write
ahead
log)
wal
-
dir
=
"/var/lib/influxdb/wal"
#
fsync
Write wait time before call , The default is
0
s,SSD
Set to
0
s, Not
SSD
Recommended setting as
0
ms
-
100
ms
wal
-
fsync
-
delay
=
"0s"
#
inmem
Memory index ( Need a lot of memory ),tsi1
Disk based timing index
index
-
version
=
"inmem"
#
Query log switch
query
-
log
-
enabled
=
true
#
Fragment cache in reject
/
write
The maximum memory size that can be written before the request , The default is
1
g
cache
-
max
-
memory
-
size
=
"1g"
#
tsm
The engine caches the snapshot and writes it to
tsm
Cache size of the file , Free memory when finished
cache
-
snapshot
-
memory
-
size
=
"25m"
#
After a while , If the partition does not receive write or delete ,tsm
The engine will take a snapshot of the cache and write it to the new
TSM
file
cache
-
snapshot
-
write
-
cold
-
duration
=
"10m"
#
After a while , If
tsm
The engine did not receive a write or delete ,tsm
The engine will compress all in the shard
TSM
file
compact
-
full
-
write
-
cold
-
duration
=
"4h"
#
tsm
Compress the maximum amount of data written to the disk per second , The short burst period can be set to
compact
-
throughput
-
burst
compact
-
throughput
=
"48m"
#
tsm
Compress the maximum amount of data written to disk per second during a short burst
compact
-
throughput
-
burst
=
"48m"
#
Maximum concurrent compression , The default value is
0
Will
50
%
Of
CPU
The number of cores is used to compress
max
-
concurrent
-
compactions
=
0
#
inmem
Set item : Allowed for each database before deleting writes
series
Maximum number of , Set up
0
There is no limit to
max
-
series
-
per
-
database
=
1000000
#
inmem
Set item : Every
tag
Key allowed
tag
Maximum number of values , Set up
0
There is no limit to
max
-
values
-
per
-
tag
=
100000
#
tsi1
Set item : Prewrite log
wal
Threshold size when the file will be compressed into an indexed file
#
Smaller thresholds will result in faster compression of log files , And result in lower heap memory usage , But at the cost of write throughput
#
Larger thresholds will not compress frequently , Store more... In memory
series, And provide higher write throughput
max
-
index
-
log
-
file
-
size
=
"1m"
#
tsi1
Set item :tsi
The index is used to store the previously calculated
series
The internal cache size of the result
#
Cache results will be quickly returned from the cache , Without matching
tag
Subsequent queries of key values are recalculated
#
Set this value to
0
Caching will be disabled , This can cause query performance problems
series
-
id
-
set
-
cache
-
size
=
100
[
coordinator]
#
Write request timeout
write
-
timeout
=
"10s"
#
Maximum number of concurrent queries , The default value is
0
Means unrestricted
max
-
concurrent
-
queries
=
0
#
The maximum duration that a query is allowed to execute before it is terminated , The default value is
0
Means unrestricted
query
-
timeout
=
"0s"
#
Maximum duration of slow queries , A query beyond this time will print
Detected
slow
query
journal
#
The default value is
0
s
Indicates that slow queries are not recorded
log
-
queries
-
after
=
"0s"
[
retention]
#
Enforce retention policies and retire old data switches
enabled
=
true
#
Check interval for executing retention policy
check
-
interval
=
"30m0s"
[
monitor]
#
Internal record statistics switch , If there is a large amount of data in the production environment , Proposed closure
store
-
enabled
=
true
#
A database that records statistics
store
-
database
=
"_internal"
#
Time interval for recording statistics
store
-
interval
=
"10s"
[
http]
#
http
switch
enabled
=
true
#
http
Binding address
bind
-
address
=
":8086"
#
Certification switch
auth
-
enabled
=
false
#
http
Request log
log
-
enabled
=
true
#
Detailed write log switch
write
-
tracing
=
false
#
flux
Query switch
flux
-
enabled
=
false
#
flux
Query log switch
flux
-
log
-
enabled
=
false
#
pprof
http
switch , For troubleshooting and monitoring
pprof
-
enabled
=
true
#
Enable
/
pprof
Endpoint and bound to
localhost:
6060
, Used to debug startup performance problems
debug
-
pprof
-
enabled
=
false
#
https
switch
https
-
enabled
=
false
#
https
certificate
https
-
certificate
=
"/etc/ssl/influxdb.pem"
#
https
Private key
https
-
private
-
key
=
""
#
The maximum number of rows returned by the query , The default value is
0
Allow unlimited
max
-
row
-
limit
=
0
#
maximum connection , New connections that exceed the limit will be discarded , The default value is
0
Disable restrictions
max
-
connection
-
limit
=
0
#
Client request
body
Maximum size of ( In bytes ), Set to
0
Then disable restrictions
max
-
body
-
size
=
25000000
#
Access log path , If set and when
log
-
enabled
When enabled , The request log will be written to this file
#
By default, write
stderr, And
influxdb
Logs are mixed together
access
-
log
-
path
=
""
#
Request record status filtering , for example [
"4xx",
"5xx"]
, Default []
Indicates no filter , All requests are logged and printed
access
-
log
-
status
-
filters
= []
#
Maximum number of concurrent writes , Set to
0
Then disable restrictions
max
-
concurrent
-
write
-
limit
=
0
#
Maximum number of writes queued for processing , Set to
0
Then disable restrictions
max
-
enqueued
-
write
-
limit
=
0
#
The maximum duration of a write waiting in the pending queue
#
Set to
0
Or will
max
-
concurrent
-
write
-
limit
Set to
0
Then disable restrictions
enqueued
-
write
-
timeout
=
"30s"
[
logging]
#
The log level ,error、warn、info(
Default )
、debug
level
=
"info"
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
- 67.
- 68.
- 69.
- 70.
- 71.
- 72.
- 73.
- 74.
- 75.
- 76.
- 77.
- 78.
- 79.
- 80.
- 81.
- 82.
- 83.
- 84.
- 85.
- 86.
- 87.
- 88.
- 89.
- 90.
- 91.
- 92.
- 93.
- 94.
- 95.
- 96.
- 97.
- 98.
- 99.
- 100.
- 101.
- 102.
- 103.
- 104.
- 105.
- 106.
- 107.
- 108.
- 109.
- 110.
- 111.
- 112.
- 113.
- 114.
- 115.
- 116.
- 117.
- 118.
- 119.
- 120.
- 121.
- 122.
- 123.
Key configuration (cpu/ Memory / disk io/ Overtime / journal )
#
Disable reporting , The default is
false
reporting
-
disabled
=
true
[
meta]
#
Metadata storage directory
dir
=
"/var/lib/influxdb/meta"
[
data]
#
Data directory
dir
=
"/var/lib/influxdb/data"
#
Pre - write log directory (write
ahead
log)
wal
-
dir
=
"/var/lib/influxdb/wal"
#
fsync
Write wait time before call , The default is
0
s,SSD
Set to
0
s, Not
SSD
Recommended setting as
0
ms
-
100
ms
#
To lower the disk
io, Then increase it appropriately
wal
-
fsync
-
delay
=
"20ms"
#
inmem
Memory index ( Need a lot of memory ),tsi1
Disk based timing index , The default is
inmem
index
-
version
=
"tsi1"
#
Query log switch , Turn off as appropriate
query
-
log
-
enabled
=
true
#
Fragment cache in reject
/
write
The maximum memory size that can be written before the request , The default is
1
g
#
If the server memory is small , It should be adjusted down properly ; To lower the disk
io, Then increase it appropriately
cache
-
max
-
memory
-
size
=
"1g"
#
tsm
The engine caches the snapshot and writes it to
tsm
Cache size of the file , Free memory when finished , The default is
25
m
#
If the server memory is small , It should be adjusted down properly ; To lower the disk
io, Then increase it appropriately
cache
-
snapshot
-
memory
-
size
=
"25m"
#
After a while , If the partition does not receive write or delete ,tsm
The engine will take a snapshot of the cache and write it to the new
TSM
file , The default is
10
m
#
To reduce
cpu
Compress computing and disk
io, Then increase it appropriately , But avoid using memory for too long
cache
-
snapshot
-
write
-
cold
-
duration
=
"10m"
#
After a while , If
tsm
The engine did not receive a write or delete ,tsm
The engine will compress all in the shard
TSM
file , The default is
4
h
#
To reduce
cpu
Compress computing and disk
io, Then increase it appropriately , for example
24
h
compact
-
full
-
write
-
cold
-
duration
=
"24h"
#
tsm
Compress the maximum amount of data written to the disk per second , The default is
48
m
#
To lower the disk
io, Then increase it appropriately
compact
-
throughput
=
"48m"
#
tsm
Compress the maximum amount of data written to disk per second during a short burst , The default is
48
m
#
To lower the disk
io, Then increase it appropriately
compact
-
throughput
-
burst
=
"48m"
#
Maximum concurrent compression , The default value is
0
Will
50
%
Of
CPU
The number of cores is used to compress
#
To reduce
cpu
Compress computing and disk
io, It should be adjusted down properly , But avoid too small to cause the compression cycle to become longer
max
-
concurrent
-
compactions
=
0
#
tsi1
Set item : Prewrite log
wal
Threshold size when the file will be compressed into an indexed file
#
Smaller thresholds will result in faster compression of log files , And result in lower heap memory usage , But at the cost of write throughput
#
Larger thresholds will not compress frequently , Store more... In memory
series, And provide higher write throughput
#
To reduce
cpu
Compress computing and disk
io, Then increase it appropriately , But avoid being too large to occupy memory all the time
#
If the server memory is small , It should be adjusted down or kept unchanged
max
-
index
-
log
-
file
-
size
=
"1m"
#
tsi1
Set item :tsi
The index is used to store the previously calculated
series
The internal cache size of the result
#
Cache results will be quickly returned from the cache , Without matching
tag
Subsequent queries of key values are recalculated
#
Set this value to
0
Caching will be disabled , This can cause query performance problems
#
If the server memory is small , It should be adjusted down properly
series
-
id
-
set
-
cache
-
size
=
100
[
coordinator]
#
Write request timeout , The default is
10
s
write
-
timeout
=
"20s"
[
monitor]
#
Internal record statistics switch , If there is a large amount of data in the production environment , Will affect memory and cpu, Proposed closure
store
-
enabled
=
true
#
Time interval for recording statistics , If there is a large amount of data in the production environment , But monitoring needs to be turned on , Then increase the interval
store
-
interval
=
"10s"
[
http]
#
http
Request log , Turn off as appropriate
log
-
enabled
=
true
[
logging]
#
The log level ,error、warn、info(
Default )
、debug, Adjust the grade as appropriate
level
=
"info"
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
- 67.
- 68.
- 69.
边栏推荐
- break和continue的区别
- How to redeem financial products after the opening date?
- Inno setup installation path box learning
- 机器学习和模式识别怎么区分?
- 【微信小程序更改appid失败】微信小程序修改appid一直失败报错tourist appid解决办法
- Rough reading of targeted supervised contractual learning for long tailed recognition
- Point cloud to depth map: conversion, saving, visualization
- 深度学习图像数据增强
- 金鱼哥RHCA回忆录:DO447Ansible Tower导航
- Cloudcompare & PCL point cloud AABB bounding box
猜你喜欢

京东39岁“毕业生”被裁一周就找到新工作,涨薪20%!
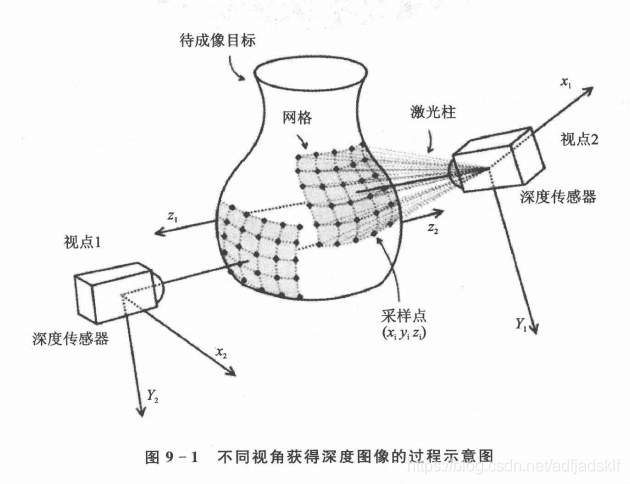
Points cloud to Depth maps: conversion, Save, Visualization
2022-06-20
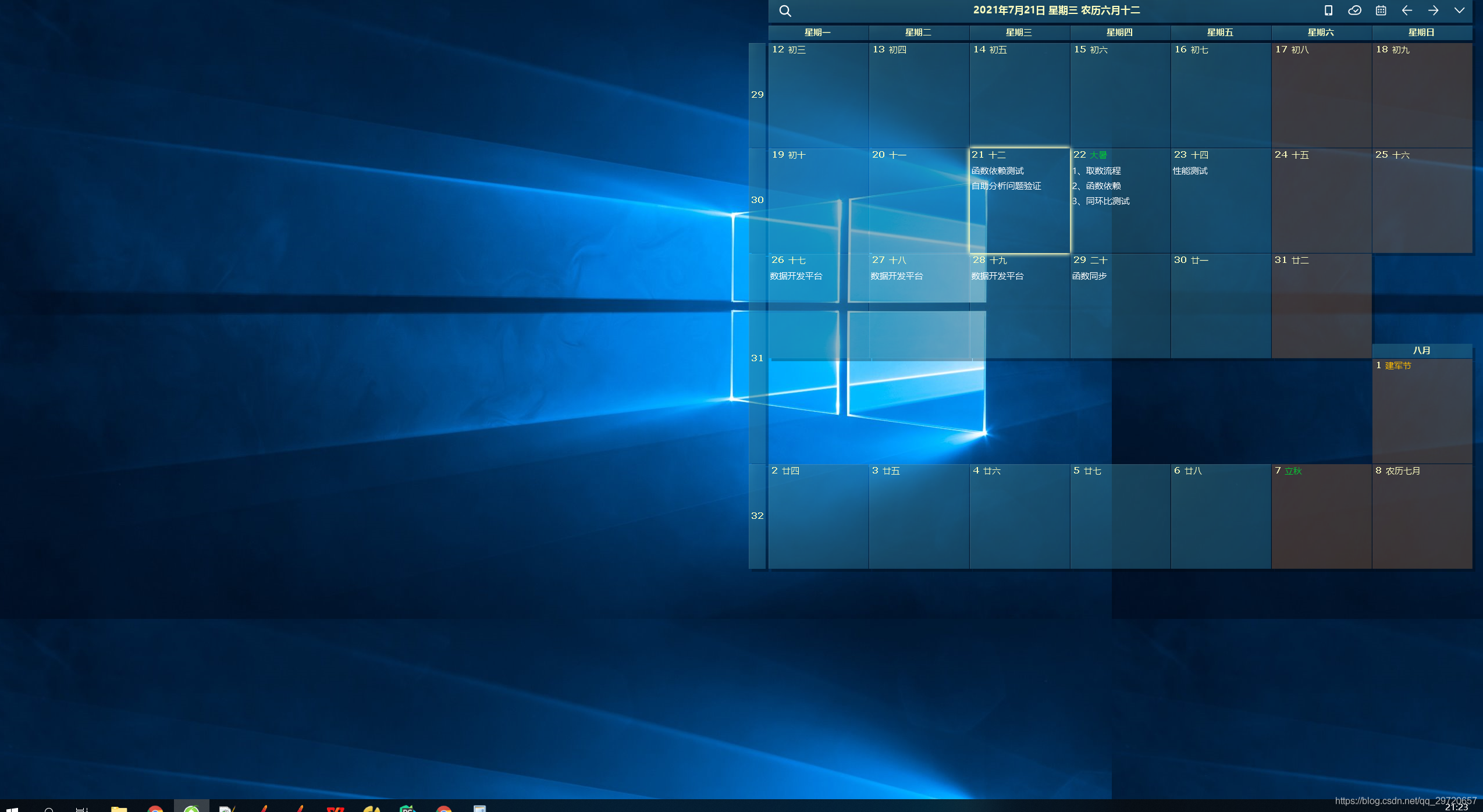
软件测试办公工具推荐-桌面日历

汇编语言贪吃蛇、俄罗斯方块双任务设计实现详解(一)——整体系统设计

Netcore3.1 Ping whether the network is unblocked and obtaining the CPU and memory utilization of the server
![[wechat applet] collaboration and publishing data binding](/img/9a/a986fe169cf9bee0bb109750590a22.png)
[wechat applet] collaboration and publishing data binding
Learn from the old guard on the development of harmonyos: in the name of the father, code force is fully open! Write a section of harmonyos wishing father's Day
Resttemplate multiple authentication information authorization

自然语言处理如何实现聊天机器人?

随机推荐
Excuse me, the exclusive resources in data integration can not connect to some databases normally. The following reasons do not seem to be true. Public funds
张至顺道长自述
粗读Targeted Supervised Contrastive Learning for Long-Tailed Recognition
How to query the maximum ID value in MySQL
Simple use of JS
Now CDC supports MySQL 5 What time is it? Previously, it seemed that it was 5.7. Today, it is found that the MySQL data source of 5.6 can also be updated in real time
Daily development of common tools to improve efficiency
贪吃蛇游戏项目完整版
【ICML2022】CtrlFormer: 通过Transformer学习视觉控制的可迁移状态表示
散户买基金哪个平台最好最安全
Big fish eat small fish games full version
汇编语言贪吃蛇、俄罗斯方块双任务设计实现详解(三)——俄罗斯方块详细设计
Anfulai embedded weekly report (issue 270): June 13, 2022 to June 19, 2022
mysql如何查询最大id值
大鱼吃小鱼小游戏完整版
ArrayList源码解析
Netcore3.1 Ping whether the network is unblocked and obtaining the CPU and memory utilization of the server
Model evaluation and selection of machine learning
Uniapp obtains login authorization and mobile number authorization (sorting)
Big Fish eating Little Fish Games version complète