当前位置:网站首页>16. Over fitting and under fitting
16. Over fitting and under fitting
2022-07-27 06:00:00 【Pie star's favorite spongebob】
Catalog
Over fitting and under fitting
We don't know the model function , Sometimes there are errors in observation ,, Combine all errors into one factor ,y = w * x + b + ε,~N(0.01,1)
One . Measure different types of models
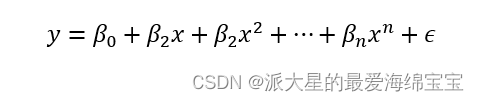
For constant polynomials 、 Polynomial of first degree , and n Power polynomial , Add to n Inferior time , The distribution of expression is more complex , For a very complex and abstract mapping, we can learn , That is, the ability to express (model capacity) It's getting stronger
Two .under-fitting Under fitting
situation 1:estimated<Ground-truth
under-fitting, The complexity of the model we use will be less than that of the real data , It will make the expression ability of the model insufficient .
train accuracy and loss Unsatisfactory , ideal acc and loss As shown in the figure , After over fitting , Probably acc No more rise ,loss Will not go down .
test accuracy Will also be dissatisfied .
3、 ... and .over-fitting Over fitting
situation 2:estimated>Ground-truth
over-fitting: The complexity of the model we use will be greater than that of the real data , Will try to lower each point loss, Our model will be closer to every point . Change to another word generalization performance Generalization ability .
in real life , Is more of a over-fitting,
Can make train The situation is particularly good , When test And train Different time , Can cause test Of accuracy Very low .
Four . How to detect over-fitting
train-test
Put one dataset Divide into train set and test set. stay test Also make one on acc and loss Detection of , If train Very good test Very bad , Is over fitting phenomenon .
The purpose of testing is to see if there is any fitting , I want to choose the parameters of the best model before fitting ,test Is to prevent over fitting .
train_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('mnist_data', train=True, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('mnist_data/', train=False, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=False)
there train It's all data sets , We have test Not really test, and validation set, Are used to select model parameters . If the three occur at the same time , There are different functions .
data and target Is used to do backward Of , Every epoch Metropolis test once ,test The purpose of is to know in advance whether overfitting 了 , If already overfitting, Will choose the best state , Usually choose test accuracy The highest point is the final state .
Parameters train The value of is ture It means training set ,false Test set .
train-val-test
Fixed partition
train_db yes 60k, hold train_db From front to back, it is divided into 50k and 10k, Get three set
print('train:',len(train_db),'test:',len(test_db))
train_db,val_db=torch.utils.data.random_split(train_db,[50000,10000])
print('db1:',len(train_db),'db2:',len(val_db))
train_loader=torch.utils.data.DataLoader(
train_db,
batch_size=batch_size,
shuffle=True
)
val_loader=torch.utils.data.DataLoader(
val_db,
batch_size=batch_size,
shuffle=True
)

k-fold cross validation
hold 60k Divide into n Share , Every time (n-1)/n To do it train, Take the rest 1/n do validation set.
validation set Used to select model parameters ,test set Of performance Just for evaluation . in total 60k,50k yes train set,10k yes validation set, the second epoch Cut it randomly again , Then choose 50k yes train set,10k yes validation set. The advantage of this is that every data set may participate in backbroke in , Every data can be validation set or train set, Prevent model memory .
adopt validation set Find the best parameters , Bring this parameter into test set in . The difference between the two is that the data set is different .
5、 ... and . How to reduce over-fitting
1.more data Add more data
The most expensive
2.constraint model complexity Reduce model complexity
shallow
Selection is not deep , A model with weak expressive ability
regularization
Make the weight very small, close to 0, But not equal to 0. Given the network structure , You don't know the complexity of the model , I don't know the size of the data set , At this time, the model with high expression ability will be preferred ,
brackets [ ] The formula in , Make the predicted value pred And real value y Closer to .θ It's network parameters , for example w1,b1 etc. , bring θ The universal number of is closer to 0, It can reduce the complexity of the model .λ It's a super parameter. , It needs to be adjusted manually , Function like learning-rate.
L2-regularization:
device=torch.device('cuda:0')
net=MLP().to(device)
optimizer=optim.SGD(net.parameters(),lr=learning_rate,weight_decay=0.01)
criteon=nn.CrossEntropyLoss().to(device)
L1-regularization:
It needs people to complete .
regularization_loss=0
for param in model.parames():
regularization_loss+=torch.sum(torch,abs(param))
classify_loss=criton(lohits,target)
loss=classify_loss+0.01*regularization_loss
optimizer.zero_gard()
loss.backward()
optimizer.step()
Iterate all parameters of the network ,0.01 yes λ. final loss Output .
3.dropout
Force effective w The smaller the better. , In the process of forward propagation , There is a certain probability of breaking one of the roads , If there is 10k The connection of , Maybe I only use it every time 5k, The next time 7k, every time train The amount of parameters used will be reduced .
Add dropout Add dropout.
net_dropped=nn.Sequential(
torch.nn.Linear(784, 200),
torch.nn.Dropout(0.5),
torch.nn.ReLU(),
torch.nn.Linear(200, 200),
torch.nn.Dropout(0.5),
torch.nn.ReLU(),
torch. nn.Linear(200, 10),
)
Two 200 The whole connection layer is dropout, broken 50%.
stay pytorch and tf The difference between
torch.nn.Dropout(p=dropout_prob)
p=1, It means that the line may break ,p=0.1, It means that the probability of line breaking is relatively small
tf.nn.dropout(keep_prob)
p=1, It means that all connections remain ,p=0.1, It means that the probability of breaking is 0.99
train and test in
stay test Not at the time dropout This behavior , All connections will use , stay validation It needs to be artificially dropout Cancel it , otherwise performance Will be small .
4.data argumention Do data enhancement
5.early stopping
Use validati set Make an early end .
training set accuracy Will keep rising ,test set accuracy It will fall after reaching the critical point , adopt validati set Get the best parameters , Stop directly at this critical point and don't continue , This can be seen as a early stopping.
Judge according to my experience and the estimated value of the model
step :
adopt validati set Select parameters
monitor validati Performance of performance
stay val performance The highest point of stops
边栏推荐
- 14.实例-多分类问题
- Day 9. Graduate survey: A love–hurt relationship
- GBase 8c核心技术
- MySQL索引分析除了EXPLAIN还有什么方法
- How MySQL and redis ensure data consistency
- 8. Mathematical operation and attribute statistics
- go通过channel获取goroutine的处理结果
- Public opinion & spatio-temporal analysis of infectious diseases literature reading notes
- Gbase 8C - SQL reference 6 SQL syntax (1)
- Only one looper may be created per thread
猜你喜欢









随机推荐
Gbase 8C - SQL reference 6 SQL syntax (5)
什么是okr,和kpi的区别在哪里
难道Redis真的变慢了吗?
Count the quantity in parallel after MySQL grouping
leetcode系列(一):买卖股票
Jenkins build image automatic deployment
2020年PHP中级面试知识点及答案
9. High order operation
GBASE 8C——SQL参考6 sql语法(9)
golang怎么给空结构体赋值
5.索引和切片
DSGAN退化网络
DDD领域驱动设计笔记
数字图像处理——第六章 彩色图像处理
Global evidence of expressed sentimental alterations during the covid-19 pandemics
西瓜书学习笔记---第四章 决策树
2021中大厂php+go面试题(2)
Brief analysis of application process creation process of activity
GBASE 8C——SQL参考6 sql语法(10)
Day 17.The role of news sentiment in oil futures returns and volatility forecasting