当前位置:网站首页>BEVDetNet:Bird‘s Eye View LiDAR Point Cloud based Real-time 3D Object Detection for Autonomous Drivi
BEVDetNet:Bird‘s Eye View LiDAR Point Cloud based Real-time 3D Object Detection for Autonomous Drivi
2022-07-29 23:30:00 【byzy】
BEVDetNet: Bird's Eye View LiDAR Point Cloud based Real-time 3D Object Detection for Autonomous Driving 论文笔记
原文链接:https://arxiv.org/pdf/2104.10780.pdf
I 引言
目前的研究都关注检测精度,而忽略了延迟、存储空间和计算复杂度的要求。
传统检测方法将点云体素化,使用3D卷积处理。后来的改进如PointPillars虽使用2D卷积提高了速度,但仍引入了预处理操作。3D锚框的使用、以及非最大抑制操作的时间和空间要求都较高。
本文的方法性能仅比PointPillars低2%,但速度是其5倍。提出分割网络,输出物体的中心点(作为关键点)、边界框参数回归值,以及朝向角区间分类结果。网络混合了ResNet和膨胀卷积,并通过消融研究确定最优网络结构。
III 方法
A.BEV表达
手工编码,每个BEV网格的特征为其中包含点的最大高度、占用值(有点则为1,否则为0)和强度编码。
B.网络结构
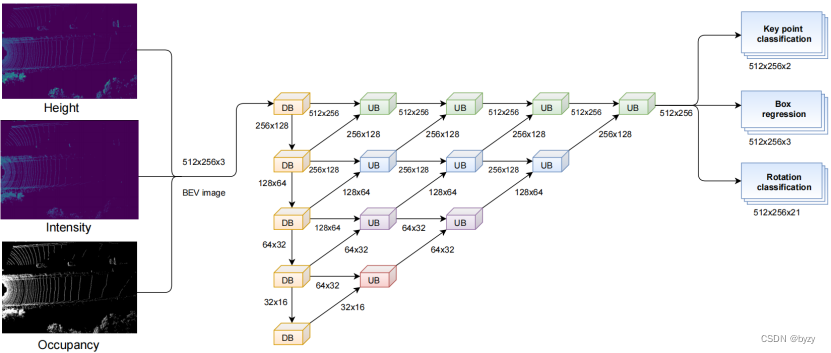
网络包含一个用于特征提取的分割网络以及3个预测头。
分割网络使用深层聚合(DLA)风格的网络(称为混合DLA结构)以提供不同空间分辨率和不同层级的特征图。其中,编码器由5个特征提取和下采样块(DB)组成;解码器包含相同数量的特征聚合和上采样块(UB)。
下采样块:
如下图所示,DB是修改的ResNet,有两个输出,一个与输入空间分辨率相同,而另一个是输入的一半,通过均值池化实现下采样,因为均值池化比最大池化更适合保留整体的上下文特征。

由于未占用的像素严重降低了初始卷积层的表达能力,本文使用SqueezesegV2网络中定义的上下文聚合模块(CAM),且将其中的最大池化替换为大核均值池化,减少遇到未占用窗口的可能性。仅在前3个DB中使用CAM,因为后面的DB有更大的感受野,未占用像素的影响较少。
使用更大的感受野核可提取更好的上下文感知特征,从而促进关键点检测。使用膨胀卷积可以在不增加参数量的情况下提高感受野,且对小而拥挤的物体的特征提取很有效。
上采样块:
如下图所示。UB使用转置卷积和常规的卷积+ReLU+BN结构,从不同层次收集低级和高级特征,通过拼接或相加进行融合。

3个预测头分别用于关键点分类(中心和类别)、对每个关键点组的边界框尺寸回归和旋转预测(作为区间分类任务)。
本文将关键点定义为地平面上的物体中心。KITTI中仅在图像上提供物体中心的标注,本文先将其转换到点云,然后投影到BEV下。
由于分割网络计算量大,需要进行改进。本文方法仅对物体关键点像素进行分类,且可以添加其他分割类别如道路和植被。
C.损失函数
总损失是关键点分类、边界框尺寸回归和旋转分类损失的加权和。
关键点分类:使用加权交叉熵损失以处理类别不平衡问题。即

其中 是类别
是类别 的出现频率,
的出现频率, 是像素的真实类别,
是像素的真实类别, 是预测类别(概率)。
是预测类别(概率)。
这里文章没说清楚,感觉总共应该是(类别数+1)个类别,表示关键点的各类别以及不是关键点的类别。
边界框尺寸回归:回归目标为对数值。使用下列SmoothL1损失:

其中 是预测值和真实值之差。
是预测值和真实值之差。
物体中心位置直接由关键点给出,其分辨率受BEV图像分辨率限制,可使用额外的中心偏移量回归头来细化。
旋转区间分类:考虑到分类任务更适合分割网络,故本文使用区间分类。使用和关键点分类损失相同的加权交叉熵损失。为减小区间数,忽略朝向,而将朝向角限制于0到180°之间(如45°和-135°均视为45°)。则该任务就是将每组关键点及其感受野分类到朝向区间(额外为背景点增加一个区间)。
D.后处理
根据边界框不重叠的假设,使用基于距离阈值的非最大抑制去除相邻区域的其余关键点。最后将关键点像素坐标 投影回3D空间
投影回3D空间 :
:

其中 为BEV分辨率。
为BEV分辨率。 坐标可通过关键点像素值得到(因为像素值包含高度信息,见III.A)。
坐标可通过关键点像素值得到(因为像素值包含高度信息,见III.A)。
IV.实验
A.实验设置
使用数据增广如水平翻转、全局旋转小角度,以及基于采样的物体增广。
B.指标和性能比较
本文使用基于 的AP指标,性能仅比PointPillars低2%但速度快很多。如使用
的AP指标,性能仅比PointPillars低2%但速度快很多。如使用 的AP指标,差的会更多,可能是精确定位所需的复杂度更高。
的AP指标,差的会更多,可能是精确定位所需的复杂度更高。
C.消融研究
(1)比较了不同的分割网络结构,证实了本文混合DLA结构在性能和速度上的优势。
(2)比较了分类任务的加权交叉熵损失和focal损失,以及回归任务的L1损失和SmoothL1损失。发现加权交叉熵损失和SmoothL1损失的组合最佳。
(3)与降低精度的量化模型进行了比较。量化精度越低,速度越快,但精度有所下降。可通过量化感知训练来减小精度下降。
D.失效情况
(1)当物体的点很稀疏而导致BEV图像中的像素很少时,会出现漏检。使用数据增广增加相应数据量进行训练会导致更多的错误检测。也许可使用深度补全方法预处理解决此问题。
(2)容易产生物体中心的错误估计。由于模型的简单性,物体中心从一组关键点中选择,有时候会选择到相邻像素上。这个误差在投影回3D空间时会加大。增加BEV分辨率可减轻这一问题,但会引入更多推断时间。
边栏推荐
猜你喜欢










随机推荐
SQL Server、MySQL主从搭建,EF Core读写分离代码实现
MySQL Interview Questions: Detailed Explanation of User Amount Recharge Interview Questions
y81.第四章 Prometheus大厂监控体系及实战 -- 监控扩展(十二)
MySQL主备切换
MySQL事务(transaction) (有这篇就足够了..)
高数下|三重积分的计算3|高数叔|手写笔记
In 2022, the latest Gansu construction staff (material staff) mock exam questions and answers
PyTorch笔记 - Attention Is All You Need (1)
Guidelines for the Release of New WeChat Mini Programs
[2023 School Recruitment Questions] Summary of knowledge points and hand-tear code in the written test and interview
全国双非院校考研信息汇总整理 Part.8
cv.copyMakeBorder(imwrite opencv)
Mysql8.0新特性之详细版本
Wincc报表教程(SQL数据库的建立,wincc在数据库中保存和查询数据,调用Excel模板把数据保存到指定的位置和打印功能)
437. The total path III low low
【leetcode】剑指 Offer II 006. 排序数组中两个数字之和(二分查找、双指针)
【leetcode】50. Pow(x, n)(中等)(快速幂)
Apache Doris 1.1 特性揭秘:Flink 实时写入如何兼顾高吞吐和低延时
彻底搞懂kubernetes调度框架与插件
Design for failure常见的12种设计思想