当前位置:网站首页>2016Analyzing the Behavior of Visual Question Answering Models
2016Analyzing the Behavior of Visual Question Answering Models
2022-06-27 03:05:00 【weixin_42653320】
摘要
大多数模型性能大约在60-70%,本文,我们提出系统的方法来分析这些模型的行为,作为识别优缺点和识别最有成果的方向的第一步。我们分析两种模型,一种是有注意力和没有注意力,并显示了这些模型行为的相似性和差异,我们也分析了2016年VQA挑战赛的获奖项目。
我们的分析显示,尽管最近取得了进展,但今天的VQA是“短视的”(往往在足够新的例子中失败),经常“跳到结论”(在听一半的问题后收敛在预测的答案上),和“固执的”(不能根据图像改变它们的答案)。
一、介绍
大多数模型表现为60-70%,与2016VQA挑战的前9名的差距只有5%,而人类在开放式任务上性能在83%左右,在多选任务有91%。所以作为理解模型的第一步,是有意义的比较不同模型的优缺点,发展失败模型的模式,并确定最富有成果的进展方向,发展技术去理解VQA模型的行为是至关重要的。
本文中,我们发展了新的技术来描述VQA的行为,作为具体实例,我们分析了两种VQA模型。
二、相关工作
本论文致力于将行为分析作为诊断VQA错误的第一步,Yang等人将错误分为四类--模型关注错误区域;模型关注适当的区域但是预测了错误的答案;预测答案与标签不同但还可接受;标签是错误的。虽然这些是粗糙但有用的方式,但我们感兴趣的是理解VQA模型是否能推广到新的实例,是否听整个问题,是否看图像。
三、行为分析
我们沿三个维度分析VQA模型:
(1)推广到新的实例:我们调查回答不正确的测试实例是否是新的,测试实例的新可能有两种方式:1)测试问题-图像对是新的;2)测试QI对是相似的,但在测试集需要的答案是新的。
(2)完整的问题理解:我们分析模型是否听了问题的前几个词还是整个问题。
(3)完整的图像理解:我们研究模型的预测是否根据图像而变化。
基于没有注意力的模型CNN+LSTM:在VQA验证集上实现54.13%的准确率,一个双通道模型--一个通道用CNN处理图像,另一通道用LSTM处理问题,将这两个通道获得的图像和问题特征结合起来,并通过一个FC层获取在答案空间上的softmax分布。
基于有注意力(ATT)的模型CNN+LSTM:我们使用2016VQA挑战赛的模型,在VQA验证集上实现57.02%的准确率。模型以一种层次的方式共同解释图像和问题关注,从不同层次获得的参与图像和问题特征组合,并通过一个FC层来获得答案空间上的softmax分布。
VQA2016挑战赛获奖作品(MCB):多模态紧凑双线性池化模型(mcb)在VQA验证集上获得了60.36%的准确率。该模型中,多模态紧凑双线性池化被用来预测对图像特征的关注,并将所参与的图像特征与问题特征结合,结合的特征通过一个FC层来获得以获得答案空间上的softmax分布。
3.1 泛化到新实例
为分析第一种新,我们衡量了测试准确率和测试QI对与其k个最近邻(k-NN)训练对的距离之间的相关性。对于每个测试QI对,我们在训练集中找到它的k-NNs,并计算测试QI对与它的k-NNs之间的平均距离。k-NNs是在结合的图像+问题嵌入空间计算的(FC层之前),在CNN+LSTM模型上使用欧几里得距离度量,在ATT和MCB模型上使用余弦距离度量。
准确率和平均距离的相关性是重要的,(CNN+LSTM模型在k=50处为-0.41,ATT模型在k=15处为-0.42),高的负相关值表明,模型对于泛化到新的测试QI对上表现不好。精度和平均距离的相关性在MCB模型上并不显著在(k=1处为-0.14),表明MCB能更好推广到新的测试QI对上。
我们还发现,通过检查测试QI对与k-NN训练QI对的距离,可以成功预测CNN+LSTM模型(67.5%)所犯的错误(ATT模型为66.7%,MCB模型为55.08%)。因此,这种分析不仅揭示了VQA模型犯错误的原因,而且还允许我们构建类似人类的模型,这可以预测自己即将到来的失败,并可能拒绝回答与过去看到的“太不同”的问题。
为分析第二种新(测试集中的答案不相似),我们计算了测试精度与其k-NN训练QI对的GT答案与测试地面真值(GT)答案的平均距离之间的相关性。答案之间的距离是在平均Word2Vec向量的空间中计算出来的,对于CNN+LSTM和ATT模型,这种相关性都是相当高的(-0.62),而对于MCB模型,这些相关性都是显著的(-0.47)。高负相关值表明模型倾向于复述训练中看到的答案。
这种距离特征也很容易预测失败,通过使用CNN+LSTM模型的k-NN训练GT对的GT答案检查测试GT答案的距离,可以预测74.19%的故障(ATT模型为75.41%,MCB模型为70.17%)。请注意,与先前的分析不同,此分析仅解释故障,但不能用于预测故障(因为它使用GT标签)。详见下图1。

图1中第一行,看到测试QI对与它的k-NN训练QI对((第1,第2,第3)-NN距离是{15.05,15.13,15.17})是相当不同的,这高于所有成功情况下的平均距离{8.74,9.23,9.50},解释了这个错误。第二行显示了模型在训练集中看到了相同的问题(测试QI对在语义上与测试QI对高度相似),训练过程中看到的答案不同于测试时需要产生的答案,因此无法正确回答测试QI对。表明,现有的模型缺乏组合性:能够结合cone和green(两者都已在训练集中见过),以回答测试QI对中的green cone,这种组合是可取的,也是核心。
3.2 完整的问题理解
我们提供长度增加的部分问题(从左到右的0到100%)。然后,我们计算当输入越来越多的单词时,展示部分问题的回答与完整问题的VQA准确率相同的问题的百分比。

图2中显示,对于40%的问题,CNN+LSTM模型在听一半的问题后,似乎聚焦在一个预测的答案上,模型在基于问题的一半进行预测时,具有最终准确率(54%)的68%。当基于图像时,模型只有24%的精度。ATT模型似乎在更频繁地听了一半的问题(49%的时间)后就收敛于一个预测的答案上,达到了最终准确率(57%)的74%。MCB模型在45%的时间里只听了一半的问题后,就收敛于预测的答案,达到了最终准确率的67%(60%)。详见图3定性的例子。

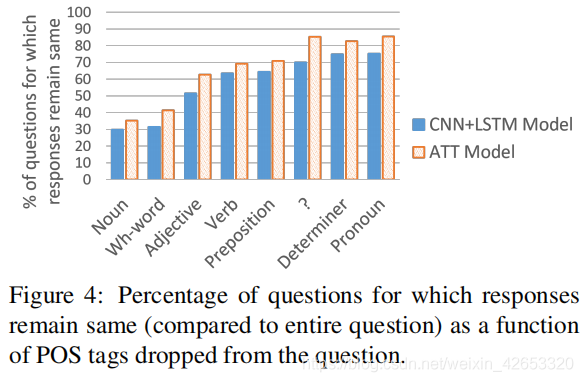
我们也分析了当特定语音部分(POS)标签的单词从问题中删除时,模型预测的响应的变化。实验结果表明,wh-words对模型决策的影响最大,代词对模型决策影响最小。
3.3 完整的图像理解

我们计算给定问题的时间百分比(X)响应不根据图像变化,并绘制X的直方图。我们对VQA验证集中至少25张图像出现的问题进行分析,总共产生263个问题。累积图表示,对于56%的问题,CNN+LSTM模型对至少一半的图像都输出相同答案。ATT和MCB模型(只关注图像中特定空间区域),有更少的问题对至少一半的图像产生相同的答案(ATT模型为42%,MCB模型为40%)。
在CNN+LSTM模型中,对于大于50%小于55%的图像产生的相同答案的问题的平均精度为56%(ATT为60%,MCB为73%),这比在整个VQA验证集的平均精度都高(CNN+LSTM为54.13%,ATT为57.02%,MCB为60.36%),因此,在图像上产生相同的答案似乎在统计上是有利的。

图6展示了CNN+LSTM模型预测给定问题的图像有相同的响应的例子。第一行显示了模型通过预测所有图像的相同答案而在多个图像上犯错误的例子。第二行显示了模型总是正确的例子,即使它预测了图像中相同的答案。这是因为诸如“What covers the ground?”只有当地面覆盖着积雪时,VQA数据集才会询问图像(因为研究对象在询问图像时正在查看图像)。因此,这种分析暴露了数据集中的标签偏差(特别是“是/否”问题)。
四、总结
我们开发了新的技术来描述VQA模型的行为,作为理解这些模型的第一步,有意义地比较不同模型的优缺点,发展对它们的失效模式的见解,并确定最富有成效的进展方向。我们的行为分析显示,尽管最近取得了进展,但今天的VQA模型是“短视的”(往往在足够新颖的实例上失败),往往“跳到结论”(听完一半问题后的预测答案),并且“固执”(不会根据图像改变答案),基于注意力的模型更少"固执的"比不使用注意力的模型。
作为最后一个想法,我们注意到,考虑到模型架构和正在训练的数据集,论文中暴露的一些病态行为在某种意义上是“正确的”。忽略优化误差,最大似然训练目标显然是为了捕获数据集的统计数据。我们的动机只是为了通过它们的行为更好地理解现有的泛化模型,并利用这些观察结果来指导未来的选择——我们需要新的模型类吗?还是有不同偏差的数据集?等等。
边栏推荐
- 平均风向风速计算(单位矢量法)
- 人群模拟
- servlet与JSP期末复习考点梳理 42问42答
- 栈溢出漏洞
- Svg drag dress Kitty Cat
- Mmdetection valueerror: need at least one array to concatenate solution
- Getting started with Scala_ Immutable list and variable list
- 455. distribute biscuits [distribution questions]
- PAT甲级 1024 Palindromic Number
- 学习太极创客 — MQTT 第二章(二)ESP8266 QoS 应用
猜你喜欢
Flink学习5:工作原理

PAT甲级 1024 Palindromic Number

一文教你Kali信息收集
Flink learning 5: how it works

How does source insight (SI) display the full path? (do not display omitted paths) (turn off trim long path names with ellipses)

pytorch_ grad_ Cam -- visual Library of class activation mapping (CAM) under pytorch
PAT甲级 1019 General Palindromic Number

学习太极创客 — MQTT(八)ESP8266订阅MQTT主题
Cvpr2022 | pointdistiller: structured knowledge distillation for efficient and compact 3D detection

C language -- Design of employee information management system
随机推荐
Record the method of reading excel provided by unity and the solution to some pits encountered
Test the respective roles of nohup and &
Parameter estimation -- Chapter 7 study report of probability theory and mathematical statistics (point estimation)
平均风向风速计算(单位矢量法)
发现一款 JSON 可视化工具神器,太爱了!
ESP8266
[Shangshui Shuo series] day 6
Detailed explanation of ThreadLocal
Learning Tai Chi Maker - mqtt Chapter 2 (II) esp8266 QoS application
What if asreml-r does not converge in operation?
Flink learning 3: data processing mode (stream batch)
Lodash get JS code implementation
The use and introduction of pytorch 23 hook and the implementation of plug and play dropblock based on hook
JWT certification process and use cases
I found a JSON visualization tool artifact. I love it!
我是怎样简化开源系统中的接口的开发的?
PAT甲级 1025 PAT Ranking
paddlepaddle 20 指数移动平均(ExponentialMovingAverage,EMA)的实现与使用(支持静态图与动态图)
docker部署redis集群
DAMA、DCMM等数据管理框架各个能力域的划分是否合理?有内在逻辑吗?