当前位置:网站首页>Database query optimization: master-slave read-write separation and common problems
Database query optimization: master-slave read-write separation and common problems
2022-06-28 01:39:00 【pbrong】
1. Basic principle of master-slave read-write separation
The access model of most systems is to read more and write less , The gap in the number of read and write requests can be several orders of magnitude .
According to some cloud vendors Benchmark Result , stay 4 nucleus 8G Running on the machine MySQL 5.7 when , Probably support 500 Of TPS and 10000 Of QPS.
When a single machine MySQL Unable to withstand excessive QPS when , Can form MySQL The master-slave read-write cluster is separated to allocate read requests to multiple slave nodes , To achieve horizontal expansion .
1.1. Master slave replication process
- Main library db Update event for (update、insert、delete) Written to binlog
- Initiate connection from library , Connect to the main library
- At this time, the main library creates a binlog dump thread, hold binlog Content sent from library
- After starting from the library , Create a I/O Threads , Read from the main library binlog Content and write to the relay log (relay log)
- And create a SQL Threads , from relay log Read the contents inside , from Exec_Master_Log_Pos The location starts executing the read update event , Write the update to slave Of db
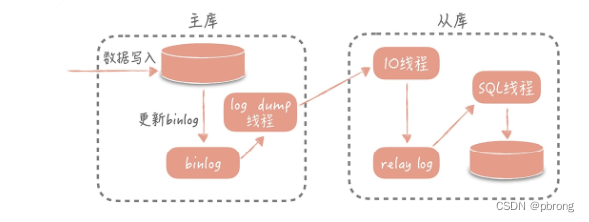
After master-slave replication , We can write only to the main library when writing , Read only when reading data from the library , In this way, even if the write request will lock the table or lock the record , Nor will it affect the execution of read requests . At the same time , In the case of large read traffic , We can deploy multiple slave libraries to share the read traffic , This is what is said “ One master, many followers ” Deployment way .
1.2. Whether the slave node can be expanded infinitely
To cope with higher database reads QPS, Is it possible to expand the slave nodes infinitely to resist a large number of concurrency ? The answer is no .
Because as the number of slave libraries increases , Connected from the library IO More threads , The main library needs to create as many log dump Thread to handle the copy request , For the main database, the resource consumption is relatively high , At the same time, it is limited by the network bandwidth of the main database , So in practice , Generally, a main library can hang up to 3~5 A slave .
2. Master slave read / write separation mode -SDK And independence Proxy Deploy
The master-slave replication technology is used to replicate data to multiple nodes , It also realizes the separation of database reading and writing , At this time , The use of databases has changed . In the past, only one database address was needed , Now you need to use one master address and multiple slave addresses , And you need to distinguish between write operations and query operations , The complexity will increase more . In order to reduce the complexity of implementation , Many database middleware have emerged in the industry to solve the problem of database access , These middleware can be divided into two categories :SDK Class and independent Proxy Deployment class .
2.1.SDK class
Taobao TDDL( Taobao Distributed Data Layer) For and Sharding—JDBC As a representative , Embedded in the form of code running inside the application . You can think of it as a proxy for a data source , Its configuration manages multiple data sources , Each data source corresponds to a database , Maybe the main library , Maybe from the library .
When there is a database request , Middleware will SQL Statement to a specified data source to process , Then return the processing result to .SDK The advantage is that it is easy to use , No extra deployment costs , The disadvantage is that it is highly bound to the programming language , such as TDDL and Sharding-JDBC Only in Java Use in , It is also difficult to upgrade the version .
2.2.Proxy class
The other is the separately deployed agent layer scheme , This kind of scheme represents more , Such as the early Alibaba open source Cobar, be based on Cobar Developed Mycat,360 Open source Atlas, Meituan's open source is based on Atlas Developed DBProxy wait .
This kind of middleware is deployed on a separate server , Business code uses it as if it were using a single database , In fact, it manages many data sources internally , When there is a database request , It will be right SQL Make necessary rewriting of the statement , Then send it to the specified data source .
It generally uses standard MySQL Communication protocol , So it can support multiple languages . Because it is deployed independently , Therefore, it is more convenient to maintain and upgrade , It is suitable for large and medium-sized teams with certain operation and maintenance ability . Its flaws are all SQL Statements need to cross the network twice : From application to agent layer and from agent layer to data source , So there will be some loss in performance .
3. Problems and solutions of master-slave read-write separation
The master-slave read-write separation can make the database bear more reading pressure , But problems will follow : The master-slave replication is asynchronous , There are delays : The slave database consumes transit logs faster than the master database produces logs binlog It's slow .
Generally speaking , You can try to improve the slave library specification (CPU、 Memory ) To reduce the delay time , But objectively speaking, the master-slave delay will certainly exist , Especially when there is a large amount of writing , There is a problem at this time :
Read data from the library immediately after the data is written to the main library , At this point, the data may not have been copied , Cause data acquisition failure or data inconsistency .
The main idea of the solution to the inconsistency of master-slave delayed reading :
- The first scheme is data redundancy : In a scenario where you need to read and write data immediately , Do not pass data ID Database search , Instead, it directly transmits the whole latest data .
- The second option is to use caching : When writing to the main library , Write this data into Redis in , When you need to query immediately, first look up the cache to get the latest data .
- The third scheme is to query the main database : When inconsistent data is not allowed , It can be directly routed to the main database query , But this practice will put a lot of pressure on the main database , Current limiting shall be done well , Avoid hanging on to the main database .
边栏推荐
- Set集合用法
- LMSOC:一种对社会敏感的预训练方法
- Supervised, unsupervised and semi supervised learning
- Some habits of making money in foreign lead
- 零基础多图详解图神经网络
- The practice of dual process guard and keeping alive in IM instant messaging development
- Zhang Fan: the attribution of flying pig after advertising based on causal inference technology
- What are the requirements for customizing the slip ring for UAV
- Ten thousand words long article understanding business intelligence (BI) | recommended collection
- Evaluation - grey correlation analysis
猜你喜欢

评价——灰色关联分析

How to add live chat in your Shopify store?

The practice of dual process guard and keeping alive in IM instant messaging development

LMSOC:一种对社会敏感的预训练方法
Deep parsing of kubernetes controller runtime
Ten MySQL locks, one article will give you full analysis

面试官问:JS的继承

What is digitalization? What is digital transformation? Why do enterprises choose digital transformation?

Neural network of zero basis multi map detailed map

.mp4视频测试地址
随机推荐
联想拯救者R720如何组建双通道内存
Web mouse click special effects case collection (red heart in live broadcast room)
Lodash realizes anti shake and throttling functions and native implementation
Is it safe for Xiaobai in the stock market to open an account on the Internet?
什么是过孔式导电滑环?
How to build dual channel memory for Lenovo Savior r720
[open source] open source system sorting - Examination Questionnaire, etc
攻击队攻击方式复盘总结
界面组件Telerik UI for WPF入门指南 - 如何使用主题切换自定义样式
Electron window background transparent borderless (can be used to start the page)
Neural network of zero basis multi map detailed map
Ten thousand words long article understanding business intelligence (BI) | recommended collection
DeepMind | 通过去噪来进行分子性质预测的预训练
章凡:飞猪基于因果推断技术的广告投后归因
How to optimize the "message" list of IM
I/O限制进程与CPU限制进程
lodash实现防抖和节流功能及原生实现
万字长文看懂商业智能(BI)|推荐收藏
Zhang Fan: the attribution of flying pig after advertising based on causal inference technology
为什么要选择不锈钢旋转接头