当前位置:网站首页>CNN的粗浅理解
CNN的粗浅理解
2022-07-30 00:09:00 【OPTree412】
1.CNN是怎么工作的
CNN最初是作者模仿人类视觉来创造出的模型。通过特殊的卷积来识别图片一部分的特征。比如,你区分鸟与猫就是看这些动物的特征,鸟的嘴与翅膀,猫的耳朵和爪子。通过这些特征来识别物体时十分有效的。
1.1 计算方式的基本理解
首先,设定一个卷积(下图中间较小的正方形),然后让这个卷积在图像上选取一块,对这一块的所有元素相乘后求和,算完一块图片后从左往右,从上往下这样去计算。9个元素变成1个元素,将大大图片变成小小的一块。
动态的计算方法的可以参考这个图CNN计算动态图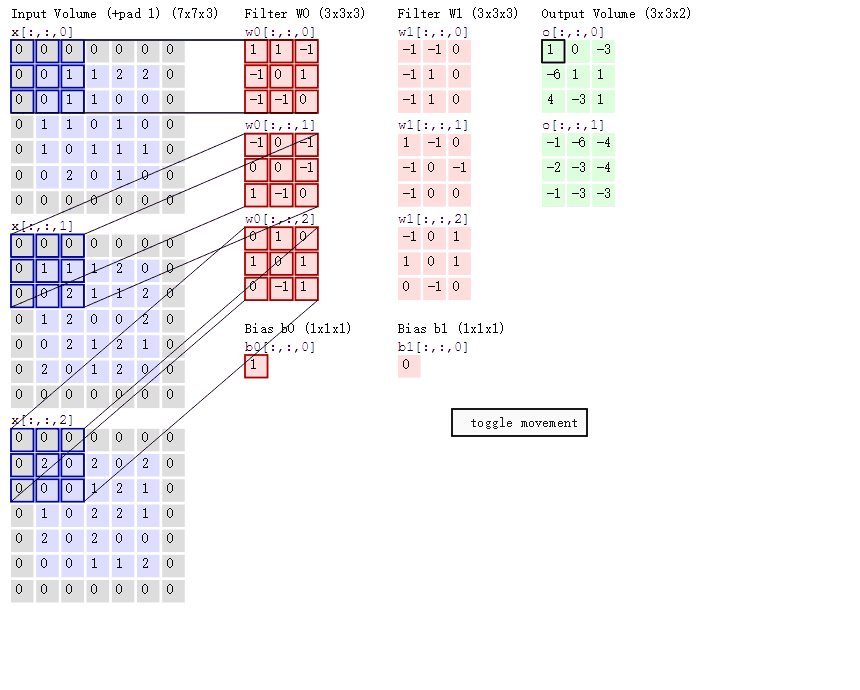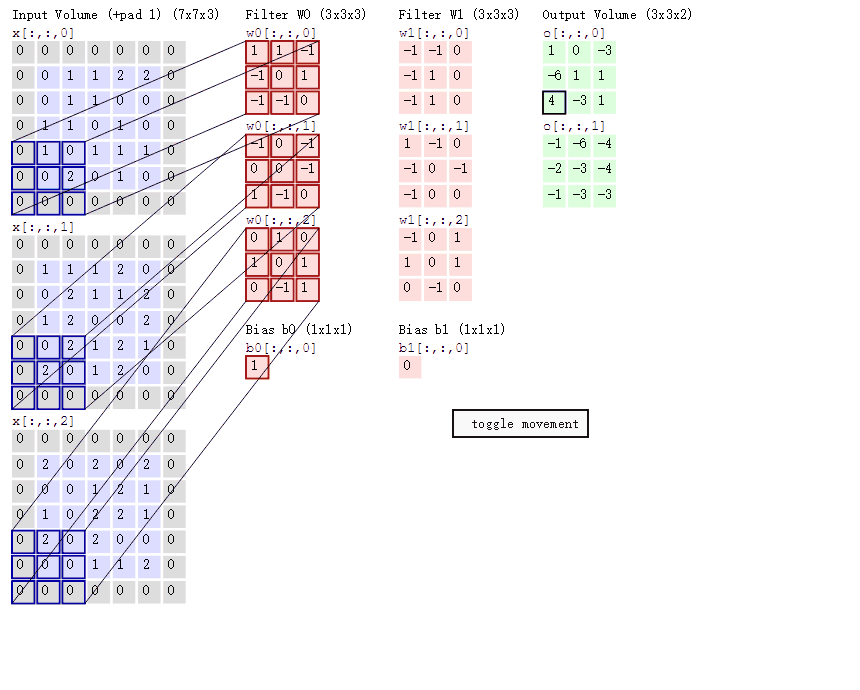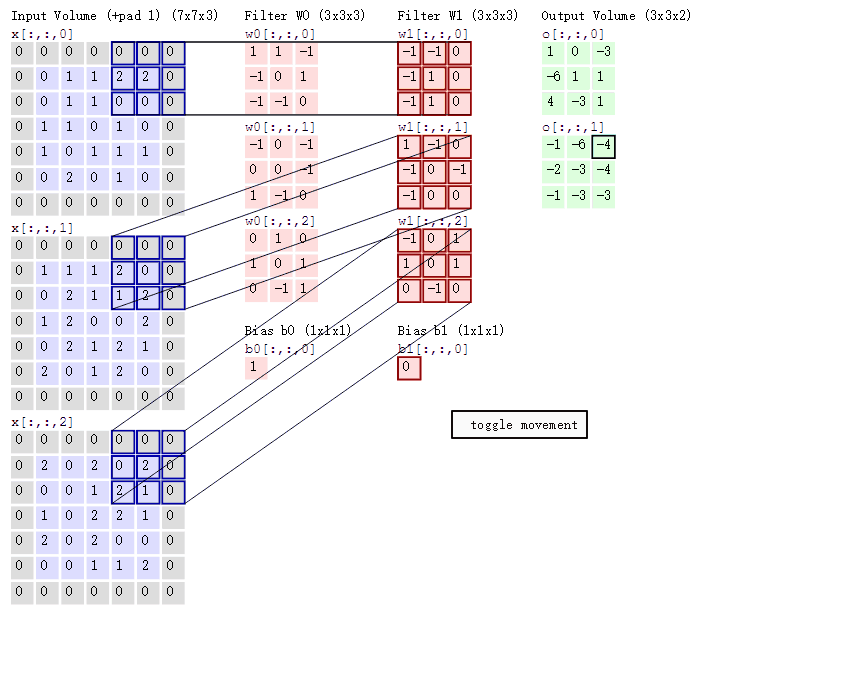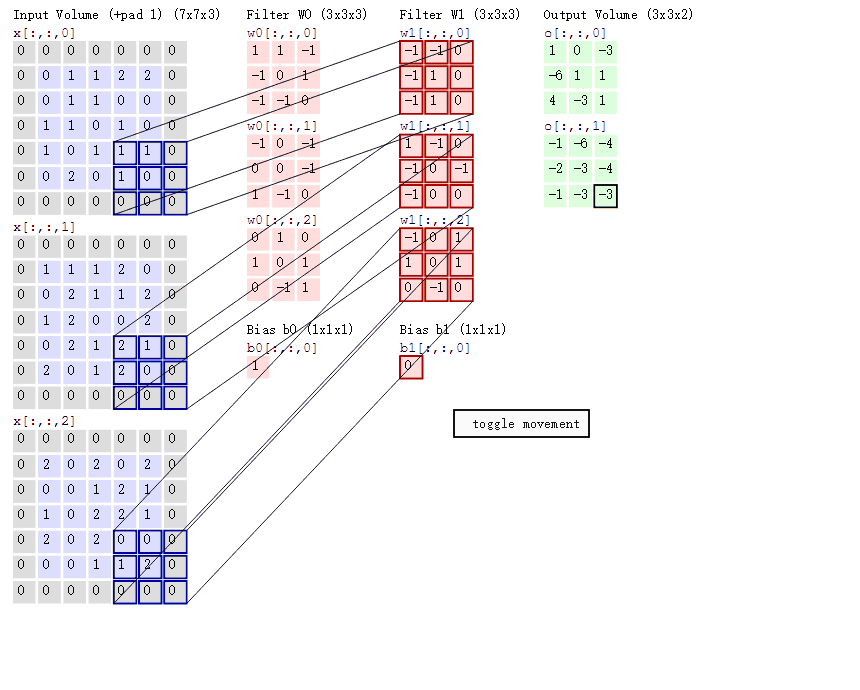
卷积提取特征的样子可以参考下图,把图片中的一些特征逐渐抽象成电脑明白的样子。
1.2 详细的CNN细节(基于Pytorch)
1.2.1 nn.Conv2d 主要结构
这了介绍一下常用的参数,其他详细的请去看看官网的解释
| 参数 | 参数类型 | 意义 |
|---|---|---|
| in_channels | int | 输入的四维张量[Batch_size, Channels, H, W]中的Channels输入(图像通道数)。这个形参是确定权重等可学习参数的shape所必需的。 |
| out_channels | int | 可以简单理解成输入一张图片进卷积,卷积能输出out_channels个小图片。 |
| kernel_size | int or tuple | 卷积核大小,如果要的是5x5、3x3这种左右两个数相同的卷积核输入一个数字即可。如果要3x5这种,则需要输入(3,5)。 |
| stride | int or tuple, optional | 卷积步长,默认为1。卷积在图像上跨几格移动。 |
| padding | int or tuple, optional | 填充操作,默认为0。Padding即所谓的图像填充,后面的int型常数代表填充的多少(行数、列数)。需要注意的是这里的填充包括图像的上下左右,以padding = 1为例,若原始图像大小为5x5,那么padding后的图像大小就变成了7x7,而不是6x6。(可以参考上面的动态图) |
1.2.2 经过卷积后的图像大小计算公式
2. 卷积神经网络
2.1 卷积神经网络的神经元
卷积在运算时,并不会像上面的动态图那样真的用一个卷积核一步一步的运动,那样太慢了。
实际上,每一个神经元(也就是一个卷积),负责一块区域。下一个区域(如动态图,经过步长移动后的区域),是另外一个神经元去负责计算的。
如下图,输入的图象是6x6x3,没有别的要求且步长就是1。那么神经元就有16个神经元,每一个卷积的大小是3x3x3。
注:每一个卷积在你设定好大小之后,深度是与你输入的图像一样的。例如,输入彩色图像,你的卷积的深度就是3层;输入灰度图像,卷积的深度就是1层。
2.2 卷积神经网络的特点
1、局部感知
这个特点从上面1.1中的第三个图就已经展现出来了。
优点:
对于一个 1000∗1000 的输入图像而言,如果下一个隐藏层的神经元数目为 106 个,采用全连接则有1000∗1000∗106=1012 个权值参数,如此数目巨大的参数几乎难以训练。
而采用局部连接,隐藏层的每个神经元仅与图像中 10∗10的局部图像相连接,那么此时的权值参数数量为 10∗10∗106=108,将直接减少4个数量级。相较于全连接神经网络,大大降低了运算量。
2、权重共享
如果一个特征在计算某个空间位置 (x1,y1)的时候有用,那么它在计算另一个不同位置 (x2,y2)(x2,y2) 的时候也有用。防止神经网络有很多重复的功能的神经元,就引出了共享参数。

3. 激活函数与池化层
3.1 激活函数
一般都是用ReLu,优点是收敛快,求梯度简单。
3.2 池化层
取某个区域的平均值或最大(最小)值。主要的目的是减少运算量,但是随着现在算力越来越高,池化层就不怎么用了。
4. 关于卷积神经网络
在自然语言处理领域,CNN的输入通常是将单词或者句子表示成向量矩阵。
卷积层是CNN中的重要组成部分,卷积层中的每一个节点输入是上一神经网络层的一部分,其目的是提取输入图片或者文本的不同特征。卷积层在处理文本序列问题时,通常使用不同大小的滤波器提取文本序列中不同特征。
池化层是为了降低网络模型的输入维度,从而降低网络模型复杂度,减少整个模型参数,使神经网络模型具有更高的鲁棒性,同时在一定程度上能有效防止模型过拟合问题。其中最常见的池化方式为 最大池化 ( Max - Pooling ) 和平均池化( Average Pooling)。
CNN一般会在卷积层和池化层之后加上全连接层,该层可以把高维度转换成低维度,同时把有用的信息保留下来。通常将卷积层、池化层的组成部分视为自动提取特征的过程,在特征提取完成之后,需要使用输出层来完成分类或者预测任务。
一般将学习到的高维度特征表示馈送到输出层,通过 Softmax 函数可以计算出当前样本属于不同类别的概率。
参考:
1.TextCNN 的 PyTorch 实现
2.什么是卷积神经网络中的-----“神经元”以及“连接数”
3. CNN笔记:通俗理解卷积神经网络
边栏推荐
- Unity Addressables
- 【云原生Kubernetes】二进制搭建Kubernetes集群(中)——部署node节点
- Worthington dissociating enzyme: detailed analysis of neutral protease (dispase)
- ZLMediaKit源码分析 - NotifyCenter
- Add, delete, modify and query the database
- 机器人的运动范围
- jenkins搭建部署详细步骤
- kubernets学习 -环境搭建
- call、apply 以及 bind 的区别和用法
- C陷阱与缺陷 第3章 语义“陷阱” 3.10 为函数main提供返回值
猜你喜欢

Low dropout linear regulator MPQ2013A-AEC1 brand MPS domestic replacement
『牛客|每日一题』走迷宫
Paper Intensive Reading - YOLOv3: An Incremental Improvement

From the perspective: the interviewer interview function test engineer mainly inspects what ability?

Go日志库——logrus

MySQL事务(transaction) (有这篇就足够了..)

shell编写规范和变量

Genesis与Axis Ventures互动密切

外包干了五年,废了...

机器人的运动范围
随机推荐
EA&UML日拱一卒-多任务编程超入门-(8)多任务安全的数据类
At the age of 29, I was fired from a functional test. Can't find a job after 2 months of interviews?
【集训DAY18】Welcome J and Z 【动态规划】
Worthington解离酶:胶原酶及四个基本概况
[Cloud native Kubernetes] Build a Kubernetes cluster in binary (middle) - deploy node nodes
C陷阱与缺陷 第3章 语义“陷阱” 3.10 为函数main提供返回值
vim相关介绍(二)
Worthington Papain & Chymotrypsin & DNase I
The difference and usage of call, apply and bind
抖音短视频流量获取攻略,掌握好这些一定可以出爆款
图论:二分图
全网最强 JVM 来袭!(至尊典藏版)
综合练习——三子棋小游戏
29岁从事功能测试被辞,面试2个月都找不到工作吗?
How to design and implement report collaboration system for instruction set data products——Development practice of industrial collaborative manufacturing project based on instruction set IoT operating
“ 我是一名阿里在职9年软件测试工程师,我的经历也许能帮到处于迷茫期的你 ”
4 hotspot inquiry networks necessary for new media operations
容器化 | 在 Rancher 中部署 MySQL 集群
Go日志库——logrus
C陷阱与缺陷 第4章 链接 4.2 声明与定义