当前位置:网站首页>【多模态】《TransRec: Learning Transferable Recommendation from Mixture-of-Modality Feedback》 Arxiv‘22
【多模态】《TransRec: Learning Transferable Recommendation from Mixture-of-Modality Feedback》 Arxiv‘22
2022-07-25 11:11:00 【chad_lee】
《TransRec: Learning Transferable Recommendation from Mixture-of-Modality Feedback》 Arxiv’22
NLP和CV领域预训练与大模型已经非常流行,涌现出BERT、GPT-3、ViT等,实现了one4all范式,也就是一个通用大模型服务于几乎所有下游任务。但是推荐系统在该方向发展缓慢,模型的可迁移性范围有限,通常只适用于一个公司内部的业务场景,无法实现广义上的可迁移性和通用性。
文章首先指出了:这主要是因为RS过度依赖用户ID与物品ID信息,基于ID的协同过滤范式使得RS脱离复杂的内容建模,并且DL+GCN又使得CF的性能经历了一段提升期,已经主导了推荐系统领域。但是基于ID的RS的性能已经出现了严重瓶颈,逼近天花板了,而且ID本身的不可共享性导致几乎没有迁移性。
因此提出从ID回到基于内容的推荐,实现大规模混合模态的通用推荐系统。
混合模态场景

通用推荐的实现是基于一个常见的推荐场景,即用户的物品交互行为由**混合模态(MoM: Mixture-of-modality)**的物品组成,用户交互的物品可以是文本(text)形式,视觉(vision)(图像/视频等)形式,或两种模态形式都存在。本文先在MoM的source domain下预训练模型,这样可以迁移到任何domain的下游任务。
数据集是QQ浏览器的新闻推荐场景,7天的记录。
TransRec

Item Encoder
首先item encoder是预训练的BERT和ResNet-18,即上图黄绿色块。
对于文本item i,将word token序列 t = [ t 1 , t 2 , … , t k ] \boldsymbol{t}=\left[t_{1}, t_{2}, \ldots, t_{k}\right] t=[t1,t2,…,tk]输入BERT,然后经过self- attention pooling得到文本item的最终表征:
Z i , t = SelfAtt ( BERT ( t ) ) Z_{i, t}=\operatorname{SelfAtt}(\operatorname{BERT}(\boldsymbol{t})) Zi,t=SelfAtt(BERT(t))
对于图片item i,将ResNet的输出的feature map过一个MLP,得到图片item的最终表征:
Z i , v = MLP ( ResNet ( v ) ) . \boldsymbol{Z}_{\boldsymbol{i}, \boldsymbol{v}}=\operatorname{MLP}(\operatorname{ResNet}(\boldsymbol{v})) \text {. } Zi,v=MLP(ResNet(v)).
User Encoder
用户则由他的物品交互序列来表示,所以User Encoder的输入是用户交互过item的embedding,然后用BERT(记为 B E R T u BERT_u BERTu)获得用户交互序列的表征,作为用户的embedding,从而和item embedding计算相似度,这里的BERT是单向的,采用最后一个item的输出作为序列的表征:
S u = Z u + P u U u = E u ( S u ) = BERT u ( S u ) \begin{aligned} &\boldsymbol{S}^{u}=\boldsymbol{Z}^{u}+\boldsymbol{P}^{u} \\ &\boldsymbol{U}^{u}=E_{u}\left(\boldsymbol{S}^{u}\right)=\operatorname{BERT}_{\mathrm{u}}\left(\boldsymbol{S}^{u}\right) \end{aligned} Su=Zu+PuUu=Eu(Su)=BERTu(Su)
训练方法
两阶段预训练
User Encoder 预训练
以自监督的方式对user encoder进行预训练。具体来说,采用从左到右的生成预训练来预测用户交互序列中的下一个item,即预训练单向BERT使用 softmax 交叉熵损失作为目标函数
y ~ t = Softmax ( RELU ( S ′ t W U + b U ) ) L UEP = − ∑ u ∈ U ∑ t ∈ [ 1 , … , n ] ( y t log ( y ~ t ) ) \begin{aligned} &\tilde{\boldsymbol{y}}_{t}=\operatorname{Softmax}\left(\operatorname{RELU}\left(\boldsymbol{S}^{\prime}{ }_{t} \boldsymbol{W}^{\boldsymbol{U}}+\boldsymbol{b}^{\boldsymbol{U}}\right)\right) \\ &\mathcal{L}_{\text {UEP }}=-\sum_{u \in U} \sum_{t \in[1, \ldots, n]}\left(\boldsymbol{y}_{\boldsymbol{t}} \log \left(\tilde{\boldsymbol{y}}_{\boldsymbol{t}}\right)\right) \end{aligned} y~t=Softmax(RELU(S′tWU+bU))LUEP =−u∈U∑t∈[1,…,n]∑(ytlog(y~t))
这里的 W U , b U W^U, b^U WU,bU 之后是丢弃的,因为是用内积作为相似度匹配的。 S ′ t S^{\prime}{ }_{t} S′t 是序列的表征。
End-to-End双塔训练
同时训练item encoder和user encoder,目的和之前的混合专家类似,为了让文本和图片的特征encoder尽快适应当前domain。利用 Contrastive Predictive Coding (CPC) 方法训练,思想如上图所示,将一条序列分成两段,根据前一段预测后一段所有item,因此和协同过滤的任务场景一样:
L C P C = − ∑ u ∈ U [ ∑ t = n + 1 n + l log ( σ ( r u , t ) ) + ∑ g = 1 j log ( 1 − σ ( r u , g ) ) ] \mathcal{L}_{\mathbf{C P C}}=-\sum_{u \in U}\left[\sum_{t=n+1}^{n+l} \log \left(\sigma\left(\boldsymbol{r}_{\boldsymbol{u}, \boldsymbol{t}}\right)\right)+\sum_{g=1}^{j} \log \left(1-\sigma\left(\boldsymbol{r}_{\boldsymbol{u}, \boldsymbol{g}}\right)\right)\right] LCPC=−u∈U∑[t=n+1∑n+llog(σ(ru,t))+g=1∑jlog(1−σ(ru,g))]
g g g是随机采的负样本。
实验
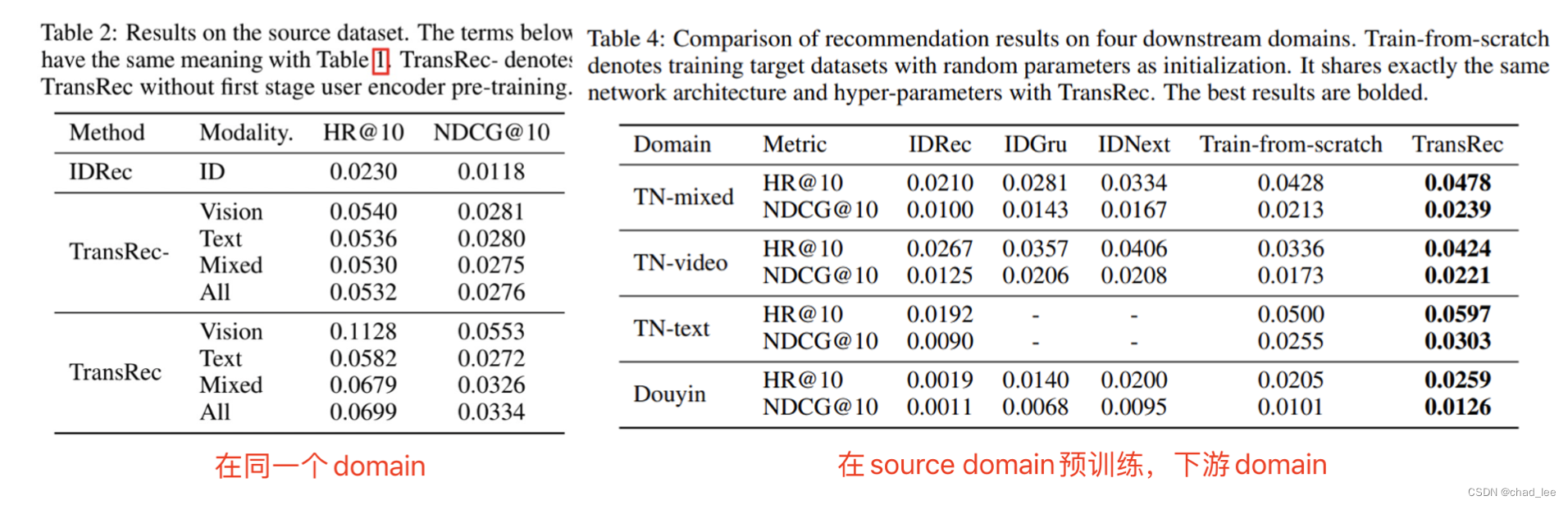
基于ID的方法在各个domain上效果都不如基于模态内容的方法,预训练也要比直接训练的好。
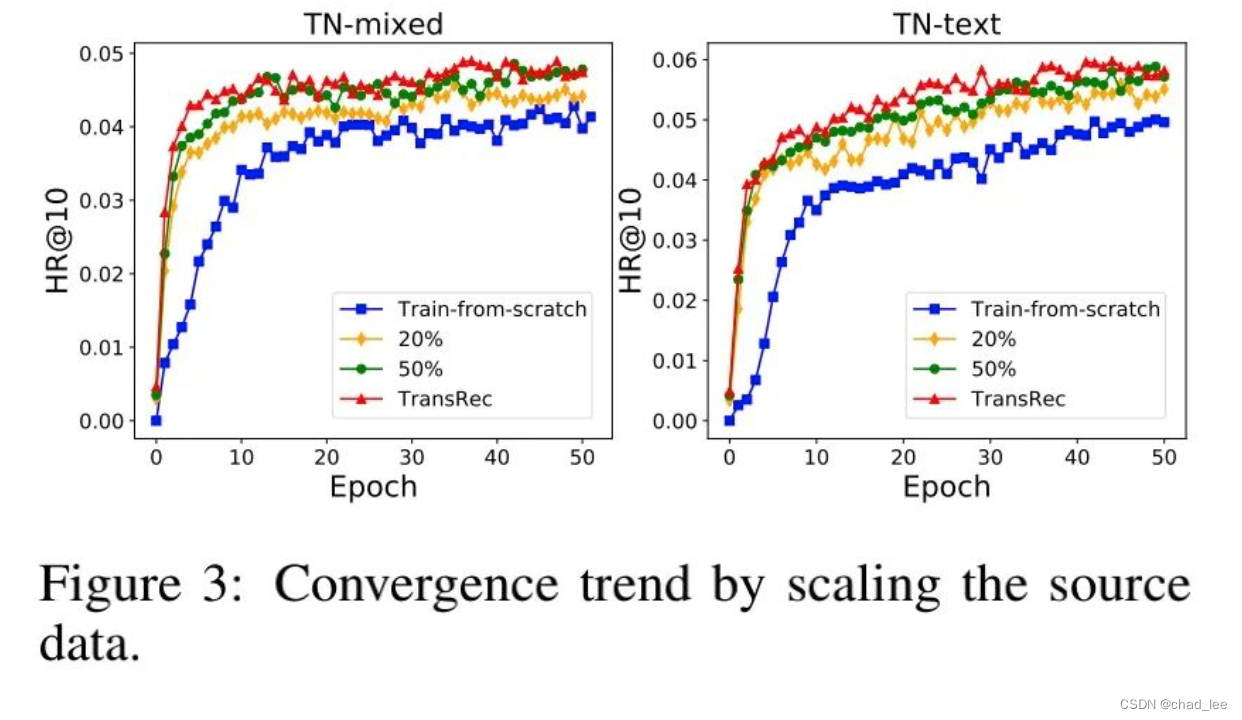
文章还验证了数据对于模型的上限,越多的预训练数据对于TransRec的性能提升越大,在工业界中有源源不断的数据可以扩充。
边栏推荐
- The JSP specification requires that an attribute name is preceded by whitespace
- Video Caption(跨模态视频摘要/字幕生成)
- JVM performance tuning methods
- [leetcode brush questions]
- Brpc source code analysis (VIII) -- detailed explanation of the basic class eventdispatcher
- 小程序image 无法显示base64 图片 解决办法 有效
- OSPF综合实验
- Experimental reproduction of image classification (reasoning only) based on caffe resnet-50 network
- Differences in usage between tostring() and new string()
- Onenet platform control w5500 development board LED light
猜你喜欢

Teach you how to configure S2E as the working mode of TCP client through MCU

Learning to Pre-train Graph Neural Networks(图预训练与微调差异)
图神经网络用于推荐系统问题(IMP-GCN,LR-GCN)
![[electronic device notes 5] diode parameters and selection](/img/4d/05c60641dbdbfbfa6c3cc19a24fa03.png)
[electronic device notes 5] diode parameters and selection

PHP curl post x-www-form-urlencoded
![[leetcode brush questions]](/img/86/5f33a48f2164452bc1e14581b92d69.png)
[leetcode brush questions]

Meta-learning(元学习与少样本学习)

软件缺陷的管理

brpc源码解析(一)—— rpc服务添加以及服务器启动主要过程

MySQL historical data supplement new data
随机推荐
Varest blueprint settings JSON
Intelligent information retrieval(智能信息检索综述)
Menu bar + status bar + toolbar ==pyqt5
第4章线性方程组
brpc源码解析(五)—— 基础类resource pool详解
pycharm连接远程服务器ssh -u 报错:No such file or directory
Eigenvalues and eigenvectors of matrices
PHP curl post x-www-form-urlencoded
教你如何通过MCU配置S2E为TCP Server的工作模式
[MySQL 17] installation exception: could not open file '/var/log/mysql/mysqld log‘ for error logging: Permission denied
JaveScript循环
GPT plus money (OpenAI CLIP,DALL-E)
教你如何通过MCU将S2E配置为UDP的工作模式
What is the global event bus?
Common linear modulation methods based on MATLAB
LeetCode 50. Pow(x,n)
【无标题】
brpc源码解析(三)—— 请求其他服务器以及往socket写数据的机制
软件缺陷的管理
布局管理==PYQT5