当前位置:网站首页>postgresql 范围查询比索引查询快吗?
postgresql 范围查询比索引查询快吗?
2022-07-31 08:59:00 【MonkeyKing_sunyuhua】
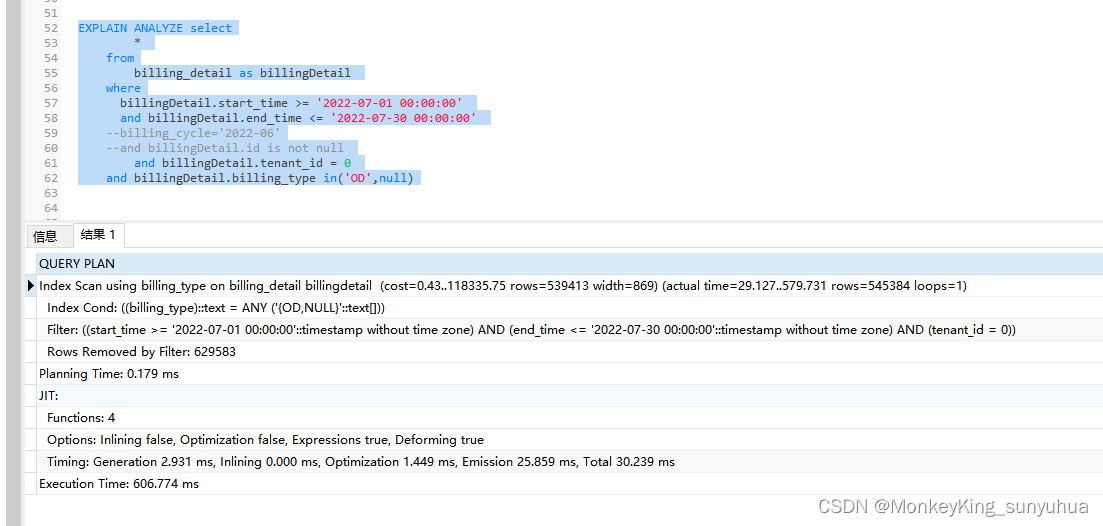
EXPLAIN ANALYZE select
*
from
billing_detail as billingDetail
where
billingDetail.start_time >= '2022-06-01 00:00:00'
and billingDetail.end_time <= '2022-07-01 00:00:00'
--billing_cycle='2022-06'
--and billingDetail.id is not null
and billingDetail.tenant_id = 0
and billingDetail.billing_type in('OD',null)

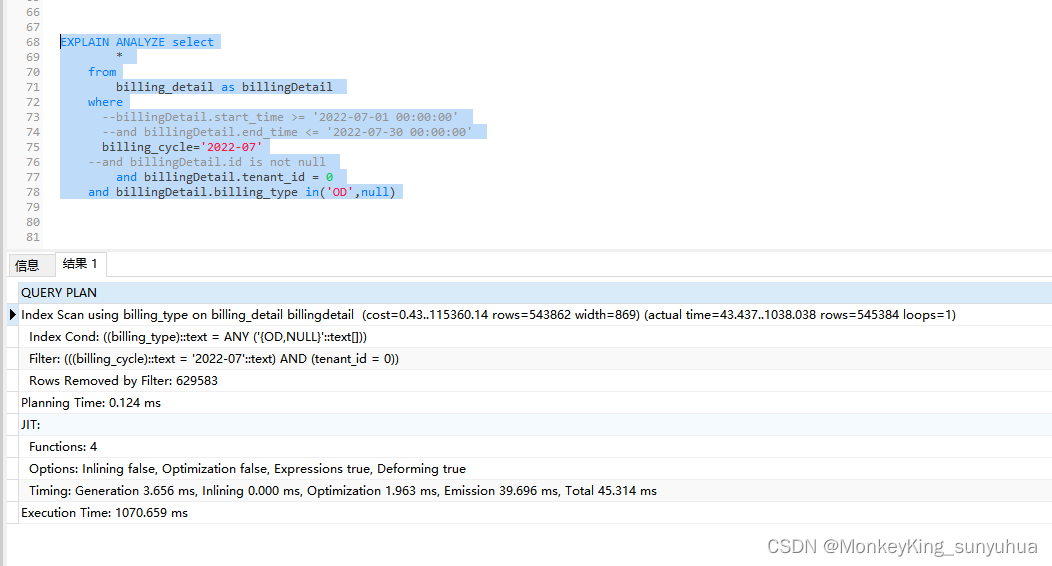
EXPLAIN ANALYZE select
*
from
billing_detail as billingDetail
where
--billingDetail.start_time >= '2022-06-01 00:00:00'
--and billingDetail.end_time <= '2022-07-01 00:00:00'
billing_cycle='2022-06'
--and billingDetail.id is not null
and billingDetail.tenant_id = 0
and billingDetail.billing_type in('OD',null)

表中共有126万行数据,表的数据的索引创建:
验证下来的确范围查询更快一些。很奇怪
再次添加104万行数据,时间格式不重复,随机生成的值,区分度很大,之前的126行区分度底
数据如图所示:
再次进行比较:


再次比较:还是发现范围查询比直接走索引还是快一些。
这里postgresql对范围查询做了优化,但是具体怎么做优化的还需要继续学习调研一下,
有已经参透的同学,可以留言回复。
边栏推荐
猜你喜欢

WLAN部署(AC+AP)配置及常见问题记录
MySQL安装教程

如何升级nodejs版本
![[Yellow ah code] Introduction to MySQL - 3. I use select, the boss directly drives me to take the train home, and I still buy a station ticket](/img/7b/f50c5f4b16a376273ba8cd27543676.png)
[Yellow ah code] Introduction to MySQL - 3. I use select, the boss directly drives me to take the train home, and I still buy a station ticket

全国中职网络安全B模块之国赛题远程代码执行渗透测试 PHPstudy的后门漏洞分析
I advise those juniors and juniors who have just started working: If you want to enter a big factory, you must master these core skills!Complete Learning Route!

【Redis高手修炼之路】Jedis——Jedis的基本使用
Doraemon teach you forwarded and redirect page

SQL连接表(内连接、左连接、右连接、交叉连接、全外连接)
Vulkan与OpenGL对比——Vulkan的全新渲染架构

随机推荐
0730~Mysql优化
JSP session的生命周期简介说明
文件的逻辑结构与物理结构的对比与区别
【Redis高手修炼之路】Jedis——Jedis的基本使用
重装系统后,hosts文件配置后不生效
如何在一台机器上(windows)安装两个MYSQL数据库
各位大佬,sqlserver 支持表名正则匹配吗
状态机动态规划之股票问题总结
2019 NeurIPS | Graph Convolutional Policy Network for Goal-Directed Molecular Graph Generation
【MySQL功法】第4话 · 和kiko一起探索MySQL中的运算符
SSM框架讲解(史上最详细的文章)
Vulkan与OpenGL对比——Vulkan的全新渲染架构
Aleo Testnet3规划大纲
【Unity】编辑器扩展-02-拓展Hierarchy视图
【Unity】编辑器扩展-01-拓展Project视图
免安装版的Mysql安装与配置——详细教程
SQL 嵌套 N 层太长太难写怎么办?
高并发高可用高性能的解决方案
日志导致线程Block的这些坑,你不得不防
I advise those juniors and juniors who have just started working: If you want to enter a big factory, you must master these core skills!Complete Learning Route!