当前位置:网站首页>[nlp] - brief introduction to the latest work of spark neural network
[nlp] - brief introduction to the latest work of spark neural network
2022-07-03 04:10:00 【Muasci】
Preface
ICLR 2019 best paper《THE LOTTERY TICKET HYPOTHESIS: FINDING SPARSE, TRAINABLE NEURAL NETWORKS》 Put forward the lottery Hypothesis (lottery ticket hypothesis):“dense, randomly-initialized, feed-forward networks contain subnetworks (winning tickets) that—when trained in isolationreach test accuracy comparable to the original network in a similar number of iterations.”
And the author is in [ Literature reading ] Sparsity in Deep Learning: Pruning and growth for efficient inference and training in NN also ( Ragged ground ) The work in this field is recorded .
This paper intends to further outline the latest work in this field . in addition , according to “when to sparsify”, This work can be divided into :Sparsify after training、Sparsify during training、Sparse training, The author pays more attention to the latter two ( the reason being that end2end Of ), So this article ( Probably ) We will pay more attention to the work of these two subcategories .
《THE LOTTERY TICKET HYPOTHESIS: FINDING SPARSE, TRAINABLE NEURAL NETWORKS》ICLR 19

step :
- Initialize a fully connected neural network θ, And determine the cutting rate p
- Train a certain number of steps , obtain θ1
- from θ1 According to the order of magnitude of the parameter weight , Cut out p Small weight of order of magnitude , And reset the remaining weights to the original initialization weights
- Keep training
Code :
- tf:https://github.com/google-research/lottery-ticket-hypothesis
- pt:https://github.com/rahulvigneswaran/Lottery-Ticket-Hypothesis-in-Pytorch
《Rigging the Lottery: Making All Tickets Winners》ICML 20

step :
- Initialize the neural network , And cut in advance . Consider the way of pre cutting :
- uniform: The sparsity rate of each layer is the same ;
- Other ways : The more parameters in the layer , The higher the degree of sparsity , Make the remaining parameters of different layers generally balanced ;
- In the process of training , Every time ΔT Step , Update the distribution of sparse parameters . consider drop and grow Two update operations :
- drop: Cut out a certain proportion of the weight of small orders of magnitude
- grow: From the trimmed weights , Restore the weight with the same scale gradient order of magnitude
- drop\grow Proportion change strategy :
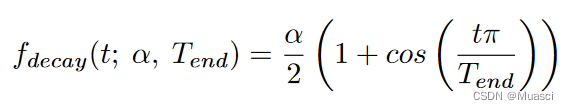
among ,α Is the initial update ratio , General set to 0.3.
characteristic :
- End to end
- Support grow
Code :
- tf:https://github.com/google-research/rigl
- pt:https://github.com/varun19299/rigl-reproducibility
《Do We Actually Need Dense Over-Parameterization? In-Time Over-Parameterization in Sparse Training》ICML 21
Put forward In-Time Over-Parameterization indicators :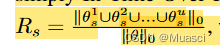
Think , Under the premise of reliable exploration , The higher the above indicators , That is, the model explores more parameters in the training process , The better the final performance .
So the training steps should be the same as 《Rigging the Lottery: Making All Tickets Winners》 similar , But the specific use Sparse Evolutionary Training (SET)——《A. Scalable training of artificial neural networks with adaptive sparse connectivity inspired by network science》, its grow Is random . This choice is because :
SET activates new weights in a random fashion which naturally considers all possible parameters to explore. It also helps to avoid the dense over-parameterization bias introduced by the gradient-based methods e.g., The Rigged Lottery (RigL) (Evci et al., 2020a) and Sparse Networks from Scratch (SNFS) (Dettmers & Zettlemoyer, 2019), as the latter utilize dense gradients in the backward pass to explore new weights
characteristic :
- Exploration
Code :https://github.com/Shiweiliuiiiiiii/In-Time-Over-Parameterization
《EFFECTIVE MODEL SPARSIFICATION BY SCHEDULED GROW-AND-PRUNE METHODS》ICLR 2022
practice :
CYCLIC GAP:

- Divide the model into k Share , Every one (?) All in accordance with r Proportional random sparseness .
- At the beginning , Make one of them dense
- continued k Step , The step interval is T individual epoch. Each step thins out the dense portion (magnitude-based), Turn the next one of that one into dense .
- k Step back , Sparse the remaining dense portion , And then fine tune .
PARALLEL GAP:k Share ,k node , Each copy is dense on different nodes .
characteristic :
- Expand the exploration space
- Did wmt14 de-en translation The experiment of
Code :https://github.com/Shiweiliuiiiiiii/In-Time-Over-Parameterization
《Learning to Win Lottery Tickets in BERT Transfer via Task-agnostic Mask Training》 NAACL 2022
practice :
characteristic :
- mask Can be trained , Instead of magnitude-based
- Task-Agnostic Mask Training( Next, let's take a look task-specific Of ?)
Code :https://github.com/llyx97/TAMT
《How fine can fine-tuning be? Learning efficient language models》AISTATS 2020
Method :
- L0-close fine-tuning: Through pre experiment , Found some layers 、 Some modules , On downstream tasks finetune after , Its parameters are not much different from the original pre training parameters , Therefore, it is excluded from this kind of finetune In the process
- Sparsification as fine-tuning: For every one task Train one 0\1mask
characteristic :
- Training mask, In order to achieve finetune pretrained model The effect of
Code : nothing
But there are https://github.com/llyx97/TAMT There is also something about mask-training Code for , You can refer to ?
边栏推荐
猜你喜欢

Mutex and rwmutex in golang

300+ documents! This article explains the latest progress of multimodal learning based on transformer

深潜Kotlin协程(十九):Flow 概述
Mila, University of Ottawa | molecular geometry pre training with Se (3) invariant denoising distance matching

Supervised pre training! Another exploration of text generation!
[NLP]—sparse neural network最新工作简述
Wechat applet + Alibaba IOT platform + Hezhou air724ug built with server version system analysis

【刷题篇】接雨水(一维)

【刷题篇】多数元素(超级水王问题)

pytorch开源吗?
随机推荐
[brush questions] find the number pair distance with the smallest K
eth入门之简介
[mathematical logic] predicate logic (toe normal form | toe normal form conversion method | basic equivalence of predicate logic | name changing rules | predicate logic reasoning law)
Is it better to speculate in the short term or the medium and long term? Comparative analysis of differences
The latest analysis of the main principals of hazardous chemical business units in 2022 and the simulated examination questions of the main principals of hazardous chemical business units
105. SAP UI5 Master-Detail 布局模式的联动效果实现明细介绍
Xrandr modifier la résolution et le taux de rafraîchissement
[home push IMessage] software installation virtual host rental tothebuddy delay
[graduation season · aggressive technology Er] Confessions of workers
DAPP for getting started with eth
Pdf editing tool movavi pdfchef 2022 direct download
ZIP文件的导出
[Yu Yue education] reference materials of political communication science of Communication University of China
MySQL field userid comma separated save by userid query
[mathematical logic] predicate logic (first-order predicate logic formula | example)
2022deepbrainchain biweekly report no. 104 (01.16-02.15)
Sklearn data preprocessing
[untitled] 2022 safety production supervisor examination question bank and simulated safety production supervisor examination questions
Deep dive kotlin synergy (19): flow overview
xrandr修改分辨率與刷新率