当前位置:网站首页>This article sorts out the development of the main models of NLP
This article sorts out the development of the main models of NLP
2022-08-04 13:02:00 【JMXGODLZ】
欢迎大家访问个人博客:https://jmxgodlz.xyz
前言
This article is based on what the author has learned,对NLPThe development context of the main models is sorted out,The purpose is to understand the past and present of mainstream technology,如有理解错误的地方,麻烦指正~
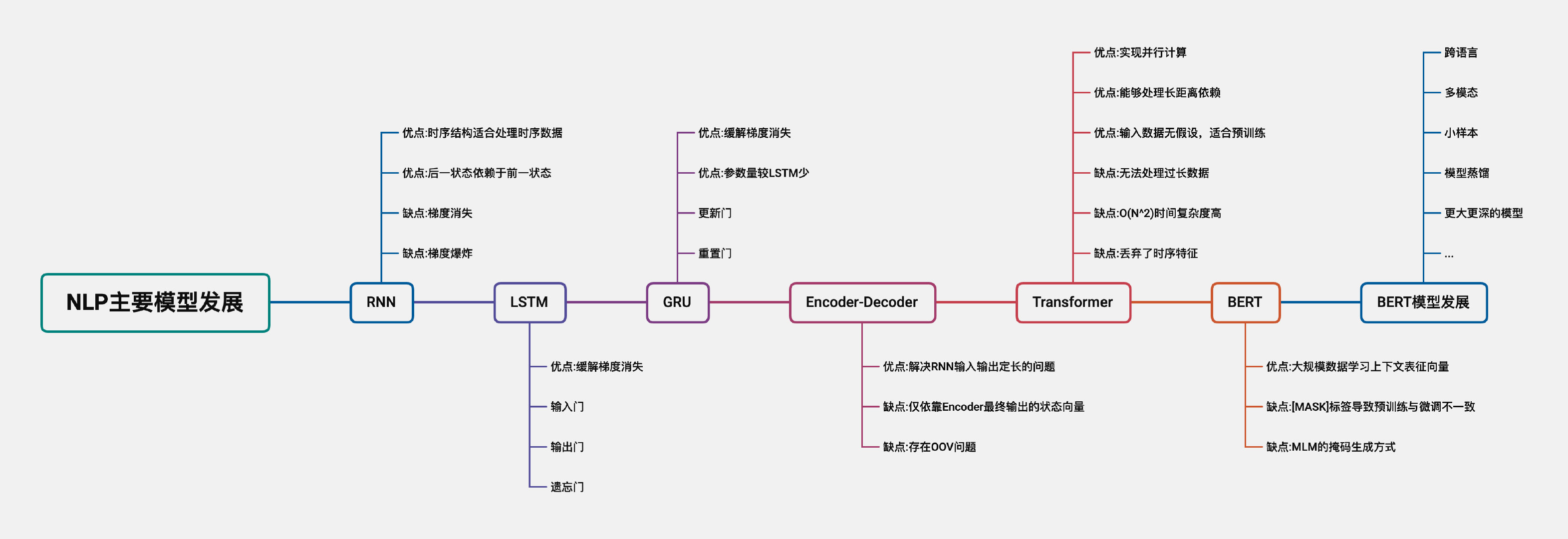
下面将依次介绍RNN、LSTM、GRU、Encoder-Deocder、Transformer、BERT设计的出发点,The model structure is not described in detail.
RNN
The data types of natural language processing are mostly text types,The contextual relationship of text data has strong sequence characteristics.同时,RNN模型具有“The output of the previous moment is used as the input of the next moment”的特征,This feature can handle sequence data well.因此,RNNmodel compared to other models,More suitable for handling natural language processing tasks.
When the length of the sequence to be processed is long,RNNThe model is in the process of backpropagation,Subject to the chain derivation rule,When the derivative of the derivation process is too small or too large,会导致梯度消失或梯度爆炸.
LSTM
RNNThe weight matrix of the model is shared in the time dimension.LSTM相较于RNN模型,通过引入门控机制,缓解梯度消失,那么LSTM如何避免梯度消失?
Several key conclusions are given here,A detailed analysis will follow in an introduction.
RNNModels share parameter matrices in the time dimension,因此RNNThe total gradient of the model is equal to the sum of the gradients at each time, g = ∑ g t g=\sum{g_t} g=∑gt.
RNNThe overall gradient does not disappear,It's just that the long-distance gradient disappears,梯度被近距离梯度主导,Unable to capture distant features.
The essence of vanishing gradients:由于RNNModels share parameter matrices in the time dimension,results in a hidden stateh求导时,The loop computes the matrix multiplication,Cumulative multiplication of parameter matrices occurs on the final gradient.
LSTMAlleviate the nature of gradient vanishing:引入门控机制,Convert matrix multiplication to element-wise Hadamard product: c t = f t ⊙ c t − 1 + i t ⊙ tanh ( W c [ h t − 1 , x t ] + b c ) c_{t}=f_{t} \odot c_{t-1}+i_{t} \odot \tanh \left(W_{c}\left[h_{t-1}, x_{t}\right]+b_{c}\right) ct=ft⊙ct−1+it⊙tanh(Wc[ht−1,xt]+bc)
GRU
GRU与LSTM模型相同,引入门控机制,避免梯度消失.区别在于,GRUOnly two gate structures, reset gate and update gate, are used,parameter comparisonLSTM少,训练速度更快.
Encoder-Decoder
RNN模型“The output of the previous moment is used as the input of the next moment”的特征,There is also the problem that the input and output of the model are always the same length.Encoder-DecoderThe model has two parts: encoder and decoder,Solved the problem of fixed input and output length.其中EncoderThe terminal is responsible for the feature representation acquisition of the text sequence,DecoderThe terminal decodes the output sequence according to the feature vector.
但Encoder-DecoderThe model still has the following problems:
Feature representation vector selection for text sequences
The feature representation vector contains the finiteness of the feature
OOV问题
The first and second questions pass注意力机制解决,The attention mechanism is used to selectively focus on the important features of the text sequence.
The third question is passed拷贝机制以及Subword编码解决.
Transformer
TransformerThe model mainly contains a multi-head self-attention module、前馈神经网络、Residual structure vsDropout,其中核心模块为多头自注意力模块,The functions of each component are as follows:
自注意力机制The encoder side selectively focuses on important features of the text sequence,Solve the problem of the feature representation vector selection of text sequence and the limited feature that the vector contains.
多头机制Each header is mapped to a different space,Obtain feature representations with different emphasis,make the feature representation more adequate.
残差结构Effectively avoid gradient disappearance.
Dropout有效避免过拟合.
前馈神经网络Complete the mapping of the hidden layer to the output space
接下来将重点介绍Transformer模型的优点.
1. TransformerAble to achieve long-distance dependencies
在自注意力机制中,Each character is able to calculate the attention score with all other characters.This calculation method does not take timing characteristics into account,Capable of capturing long-range dependencies.
But this method has the disadvantage,The time complexity of attention score calculation is O ( n 2 ) O(n^2) O(n2),When the input sequence is long,时间复杂度过高,Therefore, it is not suitable for processing too long data.
2. TransformerParallelization is possible
假设输入序列为(a,b,c,d)
传统RNN需要计算a的embedding向量得到 e a e_a ea,Then through feature extraction h a h_a ha,Then calculate in the same wayb,c,d.
Transformer通过self-attention机制,Each word can interact with the entire sequence,The model should be able to process the entire sequence at the same time,得到 e a , e b , e c , e d e_a,e_b,e_c,e_d ea,eb,ec,ed,Then calculate together h a , h b , h c , h d h_a,h_b,h_c,h_d ha,hb,hc,hd.
3. TransformerSuitable for pre-training
RNNThe model makes the assumption that the input data is temporal,Use the output of the previous moment as the input of the next moment.
CNNThe model is based on the assumption that the input data is an image,Add some traits to the structure【Such as convolution to generate features】,Make forward propagation more efficient,降低网络的参数量.
与CNN、RNN模型不同, Transformer A model is a flexible architecture,There is no restriction on the structure of the input data,Therefore, it is suitable for pre-training on large-scale data,But that point also bringsTransformerThe problem of poor model generalization on small datasets.改进方法包括引入结构偏差或正则化,对大规模未标记数据进行预训练等.
BERT
模型结构
首先,BERT模型参照GPT模型,Sample pretraining-Fine-tune the two-stage training approach.但是,与GPT使用TransformerThe decoder part is different,BERT为了充分利用上下文信息,使用TransformerThe encoder part serves as the model structure.
训练任务
如果BERT与GPTAlso use a language model as a learning task,Then the model has the problem of label leakage【The context of one word contains the predicted target of another word】.So in order to take advantage of contextual information,BERT提出MLM掩码语言模型任务,Predict cover words by context,MLMSee the introduction-不要停止预训练实战(二)-一日看尽MLM.
改进点
针对TransformerStructure and pre-training method,BERTThe model still has the following improvement points:
训练方式:Improve the mask method and multi-task training method,调整NSPThe way of training tasks and masks
模型结构调整:针对Transformer O ( n 2 ) O(n^2) O(n2)The time complexity of , and the two points that the input structure has no assumptions,调整模型结构
架构调整:轻量化结构、Strengthen cross-block connections、自适应计算时间、分治策略的Transformer
预训练:使用完整Encoder模型,如T5,BART模型
Multimodal and other downstream task applications
BERTThe future development direction of the model mainly includes:Larger and deeper models、多模态、跨语言、小样本、模型蒸馏,See the discussion-2022预训练的下一步是什么
参考文献
https://arxiv.org/pdf/2106.04554.pdf
https://www.zhihu.com/question/34878706
边栏推荐
猜你喜欢
双目立体视觉学习笔记(一)

SCA兼容性分析工具(ORACLE/MySQL/DB2--->MogDB/openGauss/PostgreSQL)
rpm安装提示error: XXX: not an rpm package (or package manifest):

封装、继承、多态的联合使用实现不同等级学生分数信息的统计
5 cloud security management strategies enterprises should implement
03 多线程与高并发 - ReentrantLock 源码解析
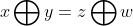
ShanDong Multi-University Training #4 A、B、C、G
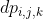
“蔚来杯“2022牛客暑期多校训练营2 G、J、K
GeoAO:一种快速的环境光遮蔽方案

Cool and efficient data visualization big screen, it's really not that difficult to do!丨Geek Planet
随机推荐
redisTemplate存取List遇到的坑
FHQ-Treap 简介
代码越写越乱?那是因为你没用责任链!
封装、继承、多态的联合使用实现不同等级学生分数信息的统计
MySQL性能指标TPS\QPS\IOPS如何压测?
密码设置有关方法:不能相同字母,不能为连续字符
用过Apifox这个API接口工具后,确实感觉postman有点鸡肋......
【黑马早报】尚乘数科上市13天,市值超阿里;北大终止陈春花聘用合同;新东方花近200亿退学费和遣散费;张小泉75%产品贴牌代工...
Valentine's Day Romantic 3D Photo Wall [with source code]
企业应当实施的5个云安全管理策略
【PHP实现微信公众平台开发—基础篇】第1章 课程介绍
Systemui qsSetting添加新图标
8/3 训练日志 (树状数组+区间覆盖+思维+01字典树)
GeoAO:一种快速的环境光遮蔽方案
【VSCode】一文详解vscode下安装vim后无法使用Ctrl+CV复制粘贴 使用Vim插件的配置记录
Chinese valentine's day of young people crazy to make money, earn 140000 a week
【牛客刷题-SQL大厂面试真题】NO5.某宝店铺分析(电商模式)
Hit the interview!The latest interview booklet of Ali Jin, nine silver and ten is stable!
做项目管理有且有必要了解并学习的重要知识--PMP项目管理
“蔚来杯“2022牛客暑期多校训练营2 G、J、K