当前位置:网站首页>Fastcorrect: speech recognition fast error correction model RTC dev Meetup
Fastcorrect: speech recognition fast error correction model RTC dev Meetup
2022-06-22 08:19:00 【Acoustic network】
Preface
「 Voice Processing 」 It is a very important scene in the field of real-time interaction , Launched on the sound network 「RTC Dev Meetup Technical practice and application of voice processing in the field of real-time interaction 」 In the activity , From Baidu 、 Technical experts of Huanyu technology and Yitu , Relevant sharing was conducted around this topic .
This article is based on Tan Xu, the research director of Microsoft Asia Research Institute, who shared the content in the activity . Official account 「 Sound network developer 」, Reply key words 「DM0428」 You can download activity related PPT Information .
Speech recognition error correction is to detect and correct errors in speech recognition results , Further improve the recognition accuracy . at present , Most error correction models adopt autoregressive structure based on attention mechanism , High latency , Affect the online deployment of the model .
This article will introduce a low latency 、 High precision error correction model FastCorrect, By using edit alignment and multiple candidate results , Acquire 10% While the word error rate of , Accelerate model 6-9 times , Relevant research papers have been published by NeurIPS 2021 and EMNLP 2021 Included .

01 Background information
1、ASR(Automatic Speech Recognition Automatic speech recognition )
The accuracy of speech recognition is the most critical factor affecting the wide application of speech recognition , How to reduce the error rate of speech recognition in the process of recognition ASR It's very important . Improve the accuracy of speech recognition 、 There are many different ways to reduce the error rate , The traditional way is to improve the core model of speech recognition . In the course of previous studies , The main concern is how to improve the training model modeling paradigm and training data of speech recognition . Actually , In addition to improving the accuracy of the speech recognition model itself , It can also post process the recognition result of speech recognition , Further reduce the recognition error rate .
2、ASR post-processing
What can be done in the speech recognition post-processing scenario ? First of all reranking, That's reordering , Usually, when speech recognition generates characters, multiple candidates will be generated , We can sort the models , Select a better result from multiple candidates as the final recognition result to improve the accuracy . The second method is to correct the error of speech recognition results , This will further reduce the error rate . These two methods are both optional methods for speech recognition post-processing , It is also a widely used method to reduce the error rate , Today's sharing mainly focuses on error correction methods .
3、 Why choose error correction
The reason for choosing error correction means is , We believe that error correction is based on the results of existing speech recognition , It can produce better speech recognition results . and reranking Is to generate a better candidate from the results returned by the existing speech recognition , If the error correction effect is good enough , It's better than reranking Have more advantages .
02 ASR The form of error correction task
The technical scheme selection is introduced above , Why choose error correction means . So let's define ASR Error correction task (error correction) In the form of . First, a training data set is given (S,T), among S Represents the input speech of speech recognition ,T Is the corresponding text annotation . then ASR The model will recognize speech as text , The resulting M(S).M(S) and T The two data pairs form a training set ,error correction The model is mainly trained in this training set . After training , We give ASR The result of recognition , That is to say M(S), Return the correct result .
Error correction The task of the model is a typical sequence to sequence learning task , Input is the result of a speech recognition , The output is the correct result after error correction . Since it is a sequence to sequence model , Previous work will naturally regard it as a task of sequence modeling , adopt encoder- attention-decoder Error correction by autoregressive decoding , The input is the wrong sentence , The output is the correct sentence .
In the process of decoding, autoregressive method is used , For example, generate A, Then generate the next word B, And then generate C and D. There is a problem with this approach , The decoding speed will be slow . We have measured , Like online ASR Model in CPU On average latency yes 500 millisecond , If we add an autoregressive error correction model , Will bring additional 660 Millisecond delay , Reduce the online recognition speed by more than twice , Pictured 1 Shown .

■ chart 1
This kind of scheme is obviously not desirable in actual deployment , Therefore, our goal is to reduce the delay and maintain the accuracy of error correction . We use the non autoregressive method to accelerate , The above mentioned method is autoregressive , Instead of autoregressive, not one at a time token, Instead, generate all at once token, It can improve the decoding speed .
Because non autoregressive decoding model is widely used in machinetranslation , So we directly use the typical non autoregressive model in machinetranslation to try , It is found that it can not reduce the error rate of speech recognition , On the contrary, it will increase , Why is this so ? First of all, we found that , The non autoregressive training task of text error correction in speech recognition is different from that in machinetranslation . For example, the input of machinetranslation is Chinese , And the output is in English , Then all... In the sequence are entered token All need to be modified , Translate Chinese into English . But in the error correction task , Most of the sentences entered are correct , in other words , Most of the words in the input sentences do not need to be modified .
If you still use the traditional method , It is easy to cause two problems : Omissions and mistakes . This brings challenges to the task of error correction , How to detect errors , And how to correct errors , Become the key to improve accuracy .
03 Naive NAR solution fails
We have made a detailed analysis of this problem , It is expected to find features from the task to design specific non self regressive modeling methods . First , Machinetranslation of different languages ( For example, from Chinese to English ) It has the characteristics of word order exchange , Because the Chinese expression is different from the English expression in word order , But in the error correction task , Recognize the text generated by speech recognition and the last correct text , In fact, there is no word exchange error , It's a monotonous alignment .
secondly , There are many possibilities for the word itself to be wrong , For example, insertion errors 、 Delete and replace errors . Based on these two prior knowledge , It can provide a more detailed error pattern for the error correction process , To guide error detection and error correction operations , We analyze this problem to inspire the design of the corresponding model .
04 FastCorrect Series model introduction
Microsoft aims at FastCorrect The model has carried out a series of work , Include FastCorrect 1、FastCorrect 2 and FastCorrect 3. Each work is aimed at different problems and scenarios .FastCorrect 1 stay NeurIPS 2021 Give a speech at the meeting , It is mainly based on the prior knowledge of the task analyzed above , Provide guidance signals for addition, deletion and modification through text editing distance , To correct the result of speech recognition . The error correction only aims at the best result of speech recognition , Because speech recognition can get a result , It can also be done through beam search Decoding yields multiple results .FastCorrect 1 It can be realized 7~9 Double acceleration , At the same time, it can achieve 8% Of WERR, That is, the reduction of word error rate .WERR Although it looks small , But at present, the accuracy of speech recognition has been very high , It can be realized 8% Of WERR In fact, it is not easy .
Although usually speech recognition will eventually return a candidate, But in the process of speech recognition decoding , There will also be multiple candidate. If multiple candidates can provide mutually verified information , Can help us better achieve error correction . So we designed FastCorrect 2, It is published in EMNLP 2021 findings, Using multiple candidate Synergy , Further reduce the word error rate . comparison FastCorrect 1, The error rate can be further reduced , While maintaining a good acceleration ratio .
These two jobs are currently in Microsoft Of GitHub( https://github.com/microsoft/NeuralSpeech ) Open source , If you are interested, you can try to use . Next, the technical implementation details of the two works will be introduced in detail .
1、FastCorrect
FastCorrect The core of is to use the prior knowledge in text error correction , That is, information about adding, deleting, and modifying operations , So we first aligned the wrong text with the correct text , The logic of alignment is guided by the edit distance of the text , By aligning, you can know which words to delete 、 Which words to add 、 Which words to replace, etc . With these fine-grained monitoring signals , The modeling of the model will be easier . For example, in the delete operation, we use duration The concept of ,duration Refer to , Give information in advance for each input word , Indicate change to target In the correct sentence , This word will become several words , For example, if it becomes zero, it means it is deleted , To become a word that means to remain unchanged or to be replaced , To change to more than two words means to insert or replace .
With such fine-grained supervision signals , The effect of the model will be improved , Not like machinetranslation , It is an end-to-end means of data learning . meanwhile , The non - autoregressive model design is also divided into three parts ,encoder Take the wrong text as input to extract information ;duration The predictor predicts each source token How many should be changed target token; and decoder The resulting target token.
(1) Edit alignment
Next up FastCorrect Edit alignment in , chart 2 The sequence on the left in is the result of speech recognition output BBDEF,Target The sequence is actually the correct result ABCDF, This indicates that speech recognition is wrong , We edit it to align the distance , An upward arrow indicates deletion , To the left means to insert , Pointing diagonally indicates substitution .

■ chart 2
After editing the distance alignment, you can get several different paths , The edit distance is the same for each path , For each path , We can know source Each token and target Each token Alignment of . after , You can choose some match High degree path . such as path a and path b Of two paths match To a greater extent than path c higher , So we are based on path a and path b Select the appropriate alignment relationship between the two paths . From these two path You can get three different alignments , For example Align a in B Of token Corresponding A and B, and B Corresponding C etc. . meanwhile path There are different possibilities , For example Align b1 in B It may also correspond to B and C, stay Align b2 in D It may also correspond to C and D. Next, we can find out which combination is common from the text corpus , Then we choose a reasonable alignment relationship through the collocation frequency of words .
From the picture 2 At the bottom of the BBDEF and ABCDF Can know every source token It should be changed into several token, such as Align b1 First of all B It will be changed to 2 individual , the second B Change to 1 individual ,D Change to 1 individual ,E Change to 0 individual ,F Change to 1 individual . With these signals , You can clearly know every source token It should be changed into several token.
(2) NAR model
Pictured 3 Shown ,Encoder The input is the wrong sentence , Predict how many words each sentence will be changed into , Then spread out the sentence according to this . For example, if you look at the first B It will be changed into two words , We will take B Spread twice . And this B It's a word , Let's put it here . So if it's going to be deleted , Let's delete it . And finally as Decoder The input of , Then decode it in parallel . This is the design of the core method of the model .

■ chart 3
(3) Pre-training
In error correction model training , because ASR The word error rate is relatively low , FALSE case commonly Less , Insufficient effective training data , The training effect of the model will also be reduced , So we constructed some wrong pairing data , That is, input wrong sentences but output correct sentences . Because in the past, it is not enough to rely on the model of speech recognition to provide data , So we forged such data on a large scale for pre training , Fine tune to the real speech recognition data set . We simulated deletion when forging data 、 Insert and replace operations , Because these operations should be close to the pattern of real speech recognition to produce error rate , Therefore, the probability of addition, deletion and modification is close to the existing speech recognition models . meanwhile , We will give priority to homonyms when making replacement , Because speech recognition is generally homophone errors , After finding such data , It can help the model to train well .
(4) Experiments
Next, some experimental details are introduced , We are in some academic data and Microsoft's internal speech recognition data set , Focus on Chinese speech recognition and error correction , At the same time, about 400million sentences from the pre training model were selected .
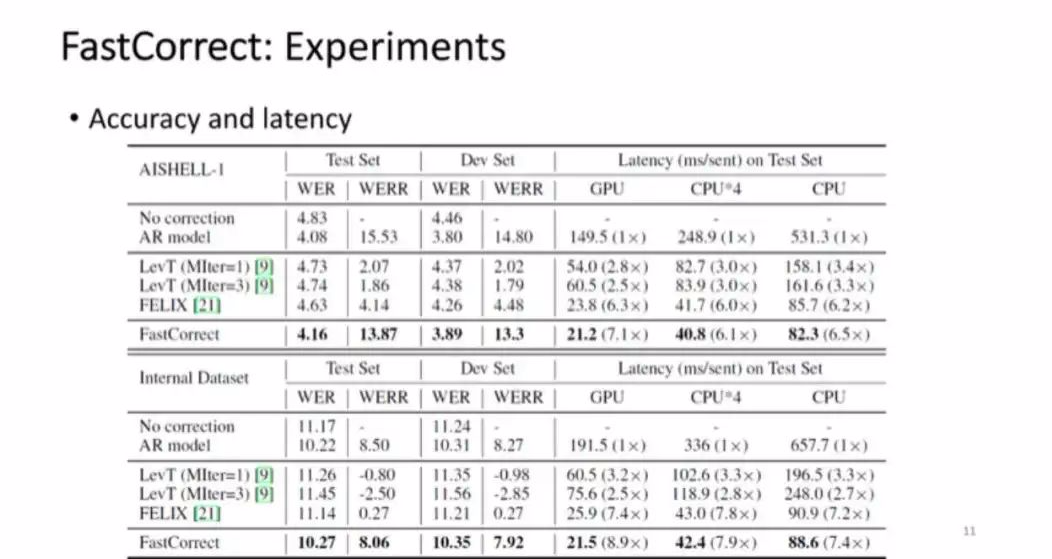
■ chart 4
The experimental results are shown in the figure 4 Shown , It can be seen that the original speech recognition probably got 4.83 The word error rate of , And if we use the autoregressive model just mentioned , That is to say encoder attention decoder, It can be realized 15% The decline of word error rate , But it's latency Relatively high . This is the method used in the past , Including the non - Auto - returning method in machinetranslation and some methods of text editing . Compared with the original speech recognition error , Can achieve 13% ~14% The decline of word error rate , Close to the autoregressive model , That is to say, there is almost no loss of error correction capability . however latency Compared with autoregressive model, it accelerates 7 times . It can be seen that FastCorrect This method can keep the word error rate down , Increase speed at the same time , Realize the standard of online deployment .
We also study Each module pre trains the method of constructing data , And by editing the distance alignment The effectiveness of the method . From the picture 5 The two datasets shown in can be seen , If you remove FastCorrect Related modules of , Or it will lead to the decrease of accuracy , indicate FastCorrect These modules are useful .

■ chart 5
The autoregressive model is a encoder decoder,decoder More time-consuming , It needs to decode a word of autoregression . Maybe you have questions , To speed up the autoregressive model , Is it possible to make encoder deepen ,decoder Lighten up , Achieve the same speedup ratio and maintain accuracy ? In this regard, we will FastCorrect And different variants of autoregressive model , Pictured 6 Shown ,AR 6-6 representative 6 layer encoder and 6 layer decoder, and AR 11 -1 representative 11 layer encoder and 1 layer decoder. You can see ,FastCorrect Better method , Or the word error rate is about the same , But the acceleration is more obvious than the effect improvement , This also dispels the question just now .

■ chart 6
As mentioned above , How to detect and correct errors in text error correction is very important , We also compared the detected precision and recall, And error correction ability . Through comparison, we found that ,FastCorrect The effect of this method is really better than the previous methods , This also verifies some previous conjectures : Provide some fine-grained addition, deletion and modification guidance signals through prior knowledge , It can help us better detect and correct errors .
2 FastCorrect 2
(1) Multiple candidates
FastCorrect 2 yes FastCorrect 1 The extended version of , because ASR The result of speech recognition model is usually multiple sentences , It will provide some additional information , called voting effect. Suppose a segment of speech gets three possible sentences through the recognition model , Namely “I have cat”“I have hat”“I have bat”, These three sentences can provide us with additional information . First , Generally speaking, the recognition of the first two words is correct , Because all three results identify I have, But the last three words are different , Explain that many of them may be wrong or both . But in general , This word is based on at End of pronunciation . After getting this information , The difficulty of error correction and correction will be greatly reduced . When revising, you can choose a more reasonable word , Help us narrow the problem space . This is it. FastCorrect 2 Design idea .
(2) Model structure
The results of the design model are shown in Figure 7 Shown , First , Align multiple candidate sentences of speech recognition before input , Because only after alignment can mutual confirmation information be provided . For example, in the previous example , We need to get cat、hat and bat alignment , Align the input sentences according to this idea , then encoder These sentences will be linked as input to the model , And predict the... Of each sentence duration, That is, it will be changed into several words after modification . A selector is also used to select a better candidate , adopt loss Monitor which candidate better , Then based on better candidate Make changes . chart 7 The third one in candidate good , Let's take it as decoder Input . This is the whole FastCorrect 2 Of high level The design method of .

■ chart 7
(3) Align multiple candidates
Here's a detail , It is how to make multiple sentences Align get up , Make it have a more accurate corresponding relationship , Let's find any one of them anchor Of candidate, Then align the other sentences with the sentence , The details here are not enough . This alignment method is actually the same as FastCorrect 1 As described in , First, calculate the editing distance , Then get the edited path And from this path Select a more reasonable alignment relationship . in other words , Make every sentence equal to anchor The sentence align Up to then , You'll get all the sentences and this anchor Alignment of sentences , Finally put this candidate merge get up , A multi-channel alignment is formed . After alignment, it can be used as the input of the model .
There's a contrast , If you don't use FastCorrect 2 Alignment method , instead Naive Padding, You will see the picture 8(b) The situation of , here B All gathered together , however C and D Is mixed . This is strange , Because in terms of models C and D It doesn't really matter . But because we used a very simple method , Put them in the same position , The model will not be able to get signals of mutual verification , This will happen D、E and F Also mixed together , Lead to cat、hat and bat Can't confirm each other to help us correct .

■ chart 8
(4) Results
Next, let's show the results , Pictured 9 Shown , The first line is the error rate of speech recognition results , The second line is the error rate after the autoregressive model is used to correct the error , The third line is FastCorrect 1 Result . At the same time, we also made some settings , As mentioned earlier, there are two ways to post process speech recognition , One is reranking, The other is error correction . Since there are many candidate, and reranking Is based on multiple candidate Make a selection , So we put the two methods together , Start with multiple candidate Pass through reranking Make a selection , recycling FastCorrect 1 Error correction . Suppose there is 4 individual candidate, Just for everyone candidate Correct errors separately , And choose the better one as the final result .FastCorrect 2 Method to put multiple candidate adopt align Later, align with each other as input .

■ chart 9
Finally, you can see ,FastCorrect 2 It's better than FastCorrect 1 good , Because it uses more information , In terms of word error rate ,FastCorrect 2 Can continue to drop more than two WERR, At the same time, the speed can be well maintained . From the picture 9 It can be seen that ,R+FC Our method has more advantages , But it's expensive , Because to many candidate Correct errors separately , Proceed again reranking, So you can't use this method , And ultimately choose FastCorrect 2 The strategy of .
In the data set Align In the process of , Consider using words that sound close together Align together , For example, in the example mentioned earlier , How to integrate I have hat and I have cat Medium cat and hat Align Together ? There is a very important element here , Is the similarity of phonetic symbols .hat and cat The pronunciation of is very close , Give priority to words with similar pronunciation , Can better structure Align Relationship . If the pronunciation similarity is not considered ,WER Will it fall ? Pictured 10 Shown , It is found that after removing the pronunciation similarity ,WER It did drop slightly . so , If the words in the language model are easy to match , Put these words together first Align, in addition , Notice the use of Naive padding The way is unreasonable at this time .

■ chart 10
We will have more than one candidate Error correction as input , So is it used candidate The more, the better ? Experimental proof candidate The more , The delay will be worse . From the picture 9 You can see ,candidate An increase in , Will eventually face accuracy and latency Of trade off.
Some people may question whether this is caused by more data ? Because compared to the previous one best correction Additional use of multiple candidate Sentence input as model training . So , We made a comparison , Is to break up sentences , Like four candidate Corresponding to a correct sentence , Split it into four pair, Every pair There's always one candidate Correspond to the correct sentence , This increases the amount of data by four times . But it is found that this method can not reduce the error rate , It will increase the error rate . It shows that the increase of data is not the cause of this result , But through reasonable alignment The error correction effect is better after the signal is provided .
Aiming at the problem of how to reduce the error rate and improve the accuracy in speech recognition , When the online delay is acceptable , We have developed FastCorrect Series of work , Pictured 11 Shown ,FastCorrect 1 and FastCorrect 2 In the academic data set and Microsoft's internal product data set , Good results have been achieved , At the same time, the error rate of the relative autoregressive error correction model is reduced . If you are interested, you can pay attention to our GitHub, We are still doing some analysis and design based on this problem , Use method related insight structure FastCorrect 3 Model , Achieve better error detection and error correction capabilities .

■ chart 11
05 Microsoft's research achievements and projects in the field of voice
Microsoft has also carried out a series of research on the whole voice , Pictured 12 Shown , Including front-end text analysis of speech synthesis 、 Modeling of low resource data in speech synthesis , And how to improve when deploying online inference The speed of 、 How to improve the robustness of speech synthesis 、 How to promote the ability of speech synthesis .

■ chart 12
Besides , We also extended the speech synthesis scenario , such as talking face generation, Input voice , The output is video of talking faces and gestures ; We also do vocal and instrumental sound synthesis , And in TTS The field has carried out detailed survey Work , At the same time tutorial Lecture course . In the near future , We have developed a speech synthesis system NaturalSpeech, The generated speech can reach the human level , If you are interested in speech synthesis , Communicate more .
Microsoft is in AI Some work has also been carried out in music , For example, the traditional music information retrieval and understanding task , And music generation tasks ( Including the creation of lyrics and songs 、 Style generation 、 Arranger 、 Voice synthesis and mixing ) etc. . If you're right AI I'm interested in music , You can also focus on our open source projects , See the picture for details 13 Shown . Microsoft is in voice Azure Aspect provides speech synthesis 、 speech recognition 、 Voice translation and other services , If you're interested , You can also use figure 14 The website shown in .
■ chart 13

■ chart 14
The machine learning group of Microsoft Research Asia is currently recruiting formal researchers and research interns , The recruitment direction includes voice 、NLP、 Machine learning and generating models , Welcome to join us !

06 Q & A
1、FastCorrect And BART Relationship and difference of
BART yes NLP Pre training model in , For sequence to sequence tasks , It can perform machinetranslation , Apply to any sequence to sequence learning task related to text . Text error correction task itself also belongs to sequence to sequence learning , It is a traditional autoregressive method . In the field of traditional methods ,BART You can use it directly , Because it is also decoded by autoregression . and FastCorrect The problem of slow decoding speed of autoregressive method is solved , It is a non autoregressive model , Unlike BART Read word for word , Instead, read the entire sentence at once , In this way, the online inference Speed , This is also the core of our design , So from this point of view, the two are quite different .
2、 Is there a targeted design for error correction ?
In addition to the general speech recognition model , We still have a lot of customized scenes , For these scenes , The data contains a large number of professional words . In order to achieve better recognition effect , Enhanced knowledge base or adaptive operation can be introduced in error correction . Suppose that the general speech recognition model should be applied to the law 、 Medical and other scenes , The technical terms contained in these fields are rare , Then the topic can be provided for the speech recognition model , Tell the Related words of the topic involved in the scene of the current recognition paragraph , For model reference for identification . This mechanism can be used for error correction . in addition , In the Chinese error correction scenario , Alignment is relatively easy , But in English or other languages , One word may correspond to some characters of another word , How to design methods for these languages is a problem to be considered in the adaptation process .
About the voice network cloud market
The voice network cloud market is a real-time interactive one-stop solution launched by the voice network , By integrating the capabilities of technology partners , Provide developers with a one-stop development experience , Solve the selection of real-time interaction module 、 Price match 、 Integrate 、 Account opening and purchase , Help developers quickly add all kinds of RTE function , Quickly bring applications to market , save 95% Integrate RTE Function time .
Microsoft real time speech recognition ( Multilingual ) The service has been launched in the voice network cloud market . With this service , The audio stream can be recorded as text in real time , And it can translate with voice services and text to voice products / Services work seamlessly together .
You can click here Experience now .
边栏推荐
- 中断中为何不能使用信号量,中断上下文为何不能睡眠
- Three characteristics of concurrency 2-orderliness
- Three concurrent features 1- visibility
- Detailed explanation of the underlying principle of concurrent thread pool and source code analysis
- PostgreSQL source code (56) extensible type analysis expandedobject/expandedrecord
- MySQL transactions
- 解读创客教育中的技术一族
- QT combox的使用示例
- MySQL avoids the method of repeatedly inserting records (ignore, replace, on duplicate key update)
- Bee framework, an ORM framework that can be learned in ten minutes --bee
猜你喜欢
![[Oracle database] mammy tutorial Day12 character function](/img/77/3b3aa643b0266e709019399b17bb93.png)
[Oracle database] mammy tutorial Day12 character function

Weekly recommended short video: what is the "computing world"?

【Oracle 数据库】奶妈式教程 day13 日期函数

QT combox的使用示例

Learn data warehouse together - Zero
![[Oracle database] mammy tutorial Day11 numerical function](/img/75/6a4340a7e9c6ee5f75a95bb3b6747f.png)
[Oracle database] mammy tutorial Day11 numerical function
Mt4/mql4 getting started to proficient in foreign exchange EA automatic trading tutorial - identify the emergence of the new K line

开展有效的创客教育课程与活动

Any to Any 实时变声的实现与落地丨RTC Dev Meetup
Type of sub database and sub table
随机推荐
DTD constraints
C#实现语音朗读功能
How can MySQL query the records with the largest consumption amount of each user?
Sqlserver paging
Restrict input type (multiple methods)
Calculation days ()
How to create an index
QT custom composite control (class promotion function)
Summary of basic knowledge of Oracle database SQL statement II: data operation language (DML)
Introduction to bee's main functions and features
Summary of basic knowledge of Oracle database SQL statements I: Data Definition Language (DDL)
Use of keepalived high availability cluster
【Oracle 数据库】奶妈式教程 day11 数值函数
Fusing and current limiting
Mt4/mql4 getting started to be proficient in EA tutorial lesson 6 - common functions of MQL language (VI) - common order function
Multiple ways for idea to package jars
QT error prompt 1:invalid use of incomplete type '***‘
Dom4j+xpath parsing XML files
矩阵运算
Multi tenancy and Implementation