当前位置:网站首页>Sqoop installation tutorial
Sqoop installation tutorial
2022-06-11 06:03:00 【Forward ing】
Sqoop Installation tutorial
Get ready Centos System
Install virtual machine installation Centos7 when
The hard disk is set larger , Such as 40G Or more
Do not set preallocated disk space .
Network adapter set to NAT Connect







Start the virtual machine after confirmation , Select the first item on the keyboard install centos7 Back carriage return 


Click other icons and the installation will start automatically when all the icons turn black .


Enter the user name after the virtual machine is turned on root And enter the password just set .
Create new users :
[[email protected] opt]useradd hadoop
Switch to a new user :
[[email protected] opt]# su hadoop
Give new users permission :
[[email protected]] vi /etc/sudoers
( Need to use root Permission to modify this file )
Add a line to the file :
hadoop ALL=(ALL) NOPASSWD:ALL
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-trUCGEy4-1646042879265)(C:\Users\Victory\AppData\Roaming\Typora\typora-user-images\image-20220227225217456.png)]](/img/63/e504dfc8101b857fa81305de8996e1.jpg)
Setting up network
Click virtual network editor and click NAT Set and remember NAT The subnet corresponding to the virtual network card where the mode is located IP, Subnet mask and gateway IP.

Enter the virtual machine terminal , Set static IP:
vi /etc/sysconfig/network-scripts/ifcfg-ens33
NAME="ens33"
TYPE="Ethernet"
DEVICE="ens33"
BROWSER_ONLY="no"
DEFROUTE="yes"
PROXY_METHOD="none"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
IPV6_PRIVACY="no"
UUID="b00b9ac0-60c2-4d34-ab88-2413055463cf"
ONBOOT="yes"
BOOTPROTO="static"
IPADDR="192.168.186.100"
PREFIX="24"
GATEWAY="192.168.186.2"
DNS1="223.5.5.5"
DNS2="8.8.8.8"
What needs to be revised is :
- ONTBOOT Set up yes It can realize automatic networking
- BOOTPROTO=“static” Set static IP, prevent IP change
- IPADDR The first three paragraphs of the should be the same as NAT Subnet of virtual network card IP Agreement , And the fourth paragraph is in 0~254 Choose between , You can't talk to NAT The subnet mask of the virtual network card and other hosts in the same network IP repeat .
- PREFIX=24 Is the bit length of the subnet mask , Conversion to decimal is 255.255.255.0, therefore PREFIX=24 It can also be directly replaced by NETMASK=“255.255.255.0”
- DNS1 The settings are Alibaba's public DNS Address "223.5.5.5",DNS2 The settings are Google's public DNS Address "8,8,8,8"
After setting, restart the network and check the host name :
sudo service network restart
sudo service network status
ip a
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-HG5Fv9D0-1646042879266)(C:\Users\Victory\AppData\Roaming\Typora\typora-user-images\image-20220227221616630.png)]](/img/7e/06138fbc507968255fd90ce2b8bcd7.jpg)
Change host name :
hostnamectl --static set-hostname hadoop100
stay hosts File to configure the host name and native ip Mapping between :
vi /etc/hosts
#127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
#::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.186.100 hadoop100
Finally, the host name can be changed by restarting the virtual machine .
After the network configuration is completed, you can use MobaXterm The virtual machine is externally connected .

Click on SSH Then enter your host ip, The user name can be created or not :
Enter the login account and password to log in :
Use hadoop Account creation Directory :
[[email protected] opt]$ sudo mkdir /opt/download
[[email protected] opt]$ sudo mkdir /opt/data
[[email protected] opt]$ sudo mkdir /opt/bin
[[email protected] opt]$ sudo mkdir /opt/tmp
[[email protected] opt]$ sudo mkdir /opt/pkg

Change for convenience opt The users in the directory and their user groups are hadoop:
[[email protected] /]$ sudo chown hadoop:hadoop -R /opt
[[email protected] /]$ ll
[[email protected] /]$ cd opt
[[email protected] opt]$ ls

After modification, you can directly drag the file into MobaXterm The left column will upload the file :
link :https://pan.baidu.com/s/1I6ZoSiSsHh_P77vUwtyhsQ
Extraction code :1234![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-A27CIbaI-1646042879272)(C:\Users\Victory\AppData\Roaming\Typora\typora-user-images\image-20220228114653512.png)]](/img/29/96c1a2cd906bde56d37e4fe248656d.jpg)
install java Environmental Science
[[email protected] download]$ tar -zxvf jdk-8u281-linux-x64.tar.gz
The java Move the package to another directory :
[[email protected] download]$ mv jdk1.8.0_281/ /opt/pkg/java
Configure environment variables :
edit /etc/profile.d/hadoop.env.sh The configuration file ( Create if not )
[[email protected] ~]$ sudo vi /etc/profile.d/hadoop.env.sh
Add a new environment variable configuration to the above file :
# JAVA JDK1.8
export JAVA_HOME=/opt/pkg/java
PATH=$JAVA_HOME/bin:$PATH
export PATH
Make the new environment take effect immediately :
[[email protected] ~]$ source /etc/profile
Check whether the environment is configured successfully :
[[email protected] ~]$ javac
[[email protected] ~]$ java -version
To configure SSH Password free login
because Hadoop Between clustered machines ssh By default, password is required for communication , It is impossible for us to manually enter the password for each communication when the cluster is running , Therefore, it is necessary to configure the... Between machines ssh Free login . Single machine pseudo distributed Hadoop The environment sample needs to be configured from local to local ssh Connection free , The process is as follows :
First ssh-keygen Command to generate RSA Encrypted key pair ( Public and private keys ):
[[email protected] ~]$ ssh-keygen -t rsa( Press enter three times after input )
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hadoop/.ssh/id_rsa):
Created directory '/home/hadoop/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/hadoop/.ssh/id_rsa.
Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:XI6S5Nm3XT5K9mAn8QfvDwqXbOPMr4T8zmBBJKEZ5R8 [email protected]
The key's randomart image is:
+---[RSA 2048]----+
| ..+.. |
| = o |
| + . E |
| o = * . |
| = S = . o |
| . o * * o |
| B # * o|
| . / O = |
| [email protected] +|
+----[SHA256]-----+
Add the generated public key to ~/.ssh In the catalog authorized_keys In file :
[[email protected] ~]$ cd
[[email protected] ~]$ cd ~/.ssh
[[email protected] .ssh]$ ssh-copy-id hadoop100
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/hadoop/.ssh/id_rsa.pub"
The authenticity of host 'hadoop100 (192.168.186.100)' can't be established.
ECDSA key fingerprint is SHA256:4//xb3Cx42SKtg9nGAV6XXYc4MSPTusnst1P3HUfjG8.
ECDSA key fingerprint is MD5:ba:e6:34:5b:d6:28:89:d6:4f:9e:db:21:ef:a3:6c:92.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
[email protected]'s password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'hadoop100'"
and check to make sure that only the key(s) you wanted were added.
[[email protected] .ssh]$ ls
authorized_keys id_rsa id_rsa.pub known_hosts
[[email protected] .ssh]$ cat authorized_keys
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDbPSEI2ID5Ip6zeZ0krlbSILXILU5WMH2enazk5hQCPOxB1RpeHjwvuBna89e8muT3NgV34qHfzEXMw8DXJfMNnOeHkvgIFe5P4air+nhWJlMYyCzVhqzm1sO9Bmza91SQeLVvwuHVx0UsiE5iLKNc/FbDPZS5piEd3lY1gSO6zV5IAZj9CzYaIweJDFEKTVIdO8bkra5+tjS8cqSFOIeLysym9XglvqZMQmOnuUaDwaYi/KAjSung2gdPRoorTYChWoWSMtFioD+Ohxgbud9mRY/0bz4B0lmqgeZbU6n5GgAjrdkKL5Of3CxfxazhALbOI3wKqWIUASt/Wa90QXsH [email protected]
[[email protected] .ssh]$ cat id_rsa.pub
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDbPSEI2ID5Ip6zeZ0krlbSILXILU5WMH2enazk5hQCPOxB1RpeHjwvuBna89e8muT3NgV34qHfzEXMw8DXJfMNnOeHkvgIFe5P4air+nhWJlMYyCzVhqzm1sO9Bmza91SQeLVvwuHVx0UsiE5iLKNc/FbDPZS5piEd3lY1gSO6zV5IAZj9CzYaIweJDFEKTVIdO8bkra5+tjS8cqSFOIeLysym9XglvqZMQmOnuUaDwaYi/KAjSung2gdPRoorTYChWoWSMtFioD+Ohxgbud9mRY/0bz4B0lmqgeZbU6n5GgAjrdkKL5Of3CxfxazhALbOI3wKqWIUASt/Wa90QXsH [email protected]
[[email protected] .ssh]$ ll
Total usage 16
-rw-------. 1 hadoop hadoop 398 2 month 28 20:12 authorized_keys
-rw-------. 1 hadoop hadoop 1679 2 month 28 20:10 id_rsa
-rw-r--r--. 1 hadoop hadoop 398 2 month 28 20:10 id_rsa.pub
-rw-r--r--. 1 hadoop hadoop 187 2 month 28 20:12 known_hosts
[[email protected] .ssh]$ ssh hadoop100
Last login: Mon Feb 28 19:51:28 2022 from 192.168.186.1
Use ssh Command to connect to the local terminal , If you do not need to enter a password, it means that the local SSH Password free configuration succeeded :
[[email protected] .ssh]$ ssh hadoop100
Last login: Mon Feb 28 19:51:28 2022 from 192.168.186.1
At this point, it has entered another terminal ( Remote terminal ) We're going to return it to the original terminal :
[[email protected] ~]$ tty
/dev/pts/1
[[email protected] ~]$ exit
Log out
Connection to hadoop100 closed.
[[email protected] .ssh]$ tty
/dev/pts/0
install hadoop
decompression hadoop Install the package and move the extracted files :
[[email protected] download]$ tar zxvf hadoop-3.1.4.tar.gz
[[email protected] download]$ mv hadoop-3.1.4 /opt/pkg/hadoop
edit /etc/profile.d/env.sh The configuration file , Add environment variables :
# HADOOP_HOME
export HADOOP_HOME=/opt/pkg/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
Make the new environment variable take effect immediately :
[[email protected] download]$ sudo vi /etc/profile.d/hadoop.env.sh
[[email protected] download]$ source /etc/profile
Check whether the environment variables are successfully configured :
[[email protected] download]$ hadoop
modify Hadoop Relevant command execution environment
find Hadoop Install under directory hadoop/etc/hadoop/hadoop-env.sh file , Finding this place will JAVA_HOME Change to true JDK The path is just :
# export JAVA_HOME=
export JAVA_HOME=/opt/pkg/java
find hadoop/etc/hadoop/yarn-env.sh file , Make the same changes :
export JAVA_HOME=/opt/pkg/java
find hadoop/etc/hadoop/mapred-env.sh, Make the same changes :
export JAVA_HOME=/opt/pkg/java

modify Hadoop To configure
Came to hadoop/etc/hadoop/, Modify the following configuration file .
(1)hadoop/etc/hadoop/core-site.xml – Hadoop Core profile :
[[email protected] hadoop]$ vi core-site.xml
Add the following to the file
<configuration>
<!-- Appoint NameNode The address and port of . -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop100:8020</value>
</property>
<!-- Appoint HDFS The storage directory of the files generated when the system is running . -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/pkg/hadoop/data/tmp</value>
</property>
<!-- Buffer size , In the actual work, it is dynamically adjusted according to the server performance ; The default value is 4096 -->
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!-- Turn on hdfs The garbage can mechanism , Deleted data can be recycled from trash cans , Units of minutes ; The default value is 0 -->
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property>
</configuration>
Be careful : Host name to modify the actual host name of the cost machine .
hadoop.tmp.dir Very important , Save in this directory hadoop In the cluster namenode and datanode All data for .
(2)hadoop/etc/hadoop/hdfs-site.xml – HDFS Related configuration :
[[email protected] hadoop]$ vi hdfs-site.xml
Add the following to the file :
<configuration>
<!-- Set up HDFS Number of copies of data in . -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- Set up Hadoop Of Secondary NameNode The host configuration of -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop100:9868</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop100:9870</value>
</property>
<!-- Check operation HDFS User rights of the file system . -->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
dfs.replication The default is 3, To save virtual machine resources , I'm going to set it to 1
Fully distributed ,SecondaryNameNode and NameNode Should be deployed separately
dfs.namenode.secondary.http-address The default is local , If it is pseudo distributed, it can be configured without
dfs.permissions Permission is set to not check
(3)hadoop/etc/hadoop/mapred-site.xml – mapreduce Related configuration
[[email protected] hadoop]$ vi mapred-site.xml
Add the following to the file :
<configuration>
<!-- Appoint MapReduce Procedure by Yarn To schedule . -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- Mapreduce Of Job History server host port settings . -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop100:10020</value>
</property>
<!-- Mapreduce Of Job Historical records Webapp End address . -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop100:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/opt/pkg/hadoop</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/opt/pkg/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/opt/pkg/hadoop</value>
</property>
</configuration>
mapreduce.jobhistory Related configurations are optional , For viewing MR Historical log of the task .
Here is the host name (hadoop100) Don't get it wrong , Otherwise, the task execution will fail , And it is not easy to find the reason .
It needs to be started manually MapReduceJobHistory Background services can be used in Yarn Page to open the history log .
(4) To configure yarn-site.xml
[[email protected] hadoop]$ vi yarn-site.xml
Add the following to the file :
<configuration>
<!-- Set up Yarn Of ResourceManager Node hostname . -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop100</value>
</property>
<!-- Set up Mapper Send data to Reducer End of the way . -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- Whether to enable the log mobile function . -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- Log retention time (7 God ). -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<!-- If vmem、pmem Insufficient resources , Will report a mistake , Set resource monitoring as false -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
(5)workers DataNode Node configuration
[[email protected] hadoop]$ vi workers
The contents of the document shall be modified as follows ( Host name ), It was localhost, It doesn't matter if you don't change .
hadoop100

Format name node
[[email protected] hadoop]$ hdfs namenode -format
After the format is successful, the following contents will appear :
2022-02-28 20:56:14,269 INFO common.Storage: Storage directory /opt/pkg/hadoop/data/tmp/dfs/name has been successfully formatted.
2022-02-28 20:56:14,342 INFO namenode.FSImageFormatProtobuf: Saving image file /opt/pkg/hadoop/data/tmp/dfs/name/current/fsimage.ckpt_0000000000000000000 using no compression
2022-02-28 20:56:14,465 INFO namenode.FSImageFormatProtobuf: Image file /opt/pkg/hadoop/data/tmp/dfs/name/current/fsimage.ckpt_0000000000000000000 of size 393 bytes saved in 0 seconds .
2022-02-28 20:56:14,481 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
2022-02-28 20:56:14,487 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid = 0 when meet shutdown.
2022-02-28 20:56:14,487 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hadoop100/192.168.186.100
************************************************************/

Run and test
start-up Hadoop Environmental Science , Just started Hadoop Of HDFS The system will be in safe mode for a few seconds , No data processing during safe mode , Is that why it's not recommended start-all.sh The script starts at one time DFS The process and Yarn process , It starts first dfs after 30 Seconds or so before starting Yarn The related process .
(1) Start all DFS process :
[[email protected] hadoop]$ start-dfs.sh
Starting namenodes on [hadoop100]
Starting datanodes
Starting secondary namenodes [hadoop100]
[[email protected] hadoop]$ jps
2545 SecondaryNameNode
2258 NameNode
2363 DataNode
2685 Jps
[[email protected] hadoop]$
(2) Start all YARN process :
[[email protected] hadoop]$ start-yarn.sh
Starting resourcemanager
Starting nodemanagers
[[email protected] hadoop]$ jps
2545 SecondaryNameNode
3217 Jps
2258 NameNode
2363 DataNode
2795 ResourceManager
2910 NodeManager
[[email protected] hadoop]$
(3) start-up MapReduceJobHistory Background services – For viewing MR Execution history log
[[email protected] hadoop]$ mr-jobhistory-daemon.sh start historyserver
WARNING: Use of this script to start the MR JobHistory daemon is deprecated.
WARNING: Attempting to execute replacement "mapred --daemon start" instead.
[[email protected] hadoop]$ jps
2545 SecondaryNameNode
2258 NameNode
2363 DataNode
2795 ResourceManager
3309 JobHistoryServer
3549 Jps
2910 NodeManager
Web Interface for verification
First, perform host mapping on the machine , Follow the path to find hosts The file of :
Add this line to configure the mapping :
Then you can use the host name and port number to access .
You can also use it directly ip Address access web Interface 192.168.186.100:9870192.168.186.100:50070

Pay attention to the use of web Stop the firewall before accessing !!
# Stop firewall
[[email protected] ~]$ systemctl stop firewalld.service
==== AUTHENTICATING FOR org.freedesktop.systemd1.manage-units ===
Authentication is required to manage system services or units.
Authenticating as: root
Password:
polkit-agent-helper-1: pam_authenticate failed: Authentication failure
==== AUTHENTICATION FAILED ===
Failed to stop firewalld.service: Access denied
See system logs and 'systemctl status firewalld.service' for details.
[[email protected] ~]$ systemctl stop firewalld.service
==== AUTHENTICATING FOR org.freedesktop.systemd1.manage-units ===
Authentication is required to manage system services or units.
Authenticating as: root
Password:
==== AUTHENTICATION COMPLETE ===
# View firewall status
[[email protected] ~]$ systemctl status firewalld.service
● firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; enabled; vendor preset: enabled)
Active: inactive (dead) since One 2022-02-28 21:28:26 CST; 15s ago
Docs: man:firewalld(1)
Process: 687 ExecStart=/usr/sbin/firewalld --nofork --nopid $FIREWALLD_ARGS (code=exited, status=0/SUCCESS)
Main PID: 687 (code=exited, status=0/SUCCESS)
# Boot from boot “ Ban ”
[[email protected] conf]$ systemctl stop firewalld.service
==== AUTHENTICATING FOR org.freedesktop.systemd1.manage-units ===
Authentication is required to manage system services or units.
Authenticating as: root
Password:
==== AUTHENTICATION COMPLETE ===
[[email protected] conf]$ systemctl disable firewalld.service
==== AUTHENTICATING FOR org.freedesktop.systemd1.manage-unit-files ===
Authentication is required to manage system service or unit files.
Authenticating as: root
Password:
==== AUTHENTICATION COMPLETE ===
Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service.
Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.
==== AUTHENTICATING FOR org.freedesktop.systemd1.reload-daemon ===
Authentication is required to reload the systemd state.
Authenticating as: root
Password:
==== AUTHENTICATION COMPLETE ===
Test cases
Use the official sample program to test Hadoop colony
start-up DFS and YARN process , Find the location of the test program :
[[email protected] data]$ cd /opt/pkg/hadoop/share/hadoop/mapreduce/
[[email protected] mapreduce]$ ls
hadoop-mapreduce-client-app-3.1.4.jar hadoop-mapreduce-client-hs-plugins-3.1.4.jar hadoop-mapreduce-client-shuffle-3.1.4.jar lib
hadoop-mapreduce-client-common-3.1.4.jar hadoop-mapreduce-client-jobclient-3.1.4.jar hadoop-mapreduce-client-uploader-3.1.4.jar lib-examples
hadoop-mapreduce-client-core-3.1.4.jar hadoop-mapreduce-client-jobclient-3.1.4-tests.jar hadoop-mapreduce-examples-3.1.4.jar sources
hadoop-mapreduce-client-hs-3.1.4.jar hadoop-mapreduce-client-nativetask-3.1.4.jar jdiff
Prepare the input file and upload it to HDFS System
[[email protected] data]$ vi wc.txt
The contents of the document are as follows :
hadoop hadoop hadoop
hi hi hi hello hadoop
hello world hadoop
[[email protected] mapreduce]$ hadoop fs -mkdir /wcinput
[[email protected] mapreduce]$ hadoop fs -put /opt/data/wc.txt /wcinput
Run the official sample program wordcount, And output the result to /output/wc In
[[email protected] mapreduce]$ hadoop jar hadoop-mapreduce-examples-3.1.4.jar wordcount /wcinput /wcoutput
Console output :
2022-02-28 22:02:51,968 INFO client.RMProxy: Connecting to ResourceManager at hadoop100/192.168.186.100:8032
2022-02-28 22:02:53,112 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/hadoop/.staging/job_1646054452694_0001
2022-02-28 22:02:53,487 INFO input.FileInputFormat: Total input files to process : 1
2022-02-28 22:02:54,469 INFO mapreduce.JobSubmitter: number of splits:1
2022-02-28 22:02:55,223 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1646054452694_0001
2022-02-28 22:02:55,224 INFO mapreduce.JobSubmitter: Executing with tokens: []
2022-02-28 22:02:55,480 INFO conf.Configuration: resource-types.xml not found
2022-02-28 22:02:55,480 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2022-02-28 22:02:56,061 INFO impl.YarnClientImpl: Submitted application application_1646054452694_0001
2022-02-28 22:02:56,168 INFO mapreduce.Job: The url to track the job: http://hadoop100:8088/proxy/application_1646054452694_0001/
2022-02-28 22:02:56,169 INFO mapreduce.Job: Running job: job_1646054452694_0001
2022-02-28 22:03:09,586 INFO mapreduce.Job: Job job_1646054452694_0001 running in uber mode : false
2022-02-28 22:03:09,588 INFO mapreduce.Job: map 0% reduce 0%
2022-02-28 22:03:17,740 INFO mapreduce.Job: map 100% reduce 0%
2022-02-28 22:03:25,864 INFO mapreduce.Job: map 100% reduce 100%
2022-02-28 22:03:26,884 INFO mapreduce.Job: Job job_1646054452694_0001 completed successfully
2022-02-28 22:03:27,018 INFO mapreduce.Job: Counters: 53
File System Counters
FILE: Number of bytes read=66
FILE: Number of bytes written=443475
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=164
HDFS: Number of bytes written=40
HDFS: Number of read operations=8
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=5728
Total time spent by all reduces in occupied slots (ms)=5239
Total time spent by all map tasks (ms)=5728
Total time spent by all reduce tasks (ms)=5239
Total vcore-milliseconds taken by all map tasks=5728
Total vcore-milliseconds taken by all reduce tasks=5239
Total megabyte-milliseconds taken by all map tasks=5865472
Total megabyte-milliseconds taken by all reduce tasks=5364736
Map-Reduce Framework
Map input records=3
Map output records=11
Map output bytes=107
Map output materialized bytes=66
Input split bytes=101
Combine input records=11
Combine output records=5
Reduce input groups=5
Reduce shuffle bytes=66
Reduce input records=5
Reduce output records=5
Spilled Records=10
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=206
CPU time spent (ms)=2040
Physical memory (bytes) snapshot=322527232
Virtual memory (bytes) snapshot=5471309824
Total committed heap usage (bytes)=165810176
Peak Map Physical memory (bytes)=210579456
Peak Map Virtual memory (bytes)=2732216320
Peak Reduce Physical memory (bytes)=111947776
Peak Reduce Virtual memory (bytes)=2739093504
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=63
File Output Format Counters
Bytes Written=40
View results :
[[email protected] mapreduce]$ hadoop fs -cat /wcoutput/part-r-00000
hadoop 4
hadoop` 1
hello 2
hi 3
world 1

Shut down the cluster :
[[email protected] mapreduce]$ stop-all.sh
WARNING: Stopping all Apache Hadoop daemons as hadoop in 10 seconds.
WARNING: Use CTRL-C to abort.
Stopping namenodes on [hadoop100]
Stopping datanodes
Stopping secondary namenodes [hadoop100]
Stopping nodemanagers
Stopping resourcemanager
[[email protected] mapreduce]$ mr-jobhistory-daemon.sh stop historyserver
WARNING: Use of this script to stop the MR JobHistory daemon is deprecated.
WARNING: Attempting to execute replacement "mapred --daemon stop" instead.
[[email protected] mapreduce]$ jps
4481 Jps
[[email protected] mapreduce]$
At this stage of setup, you can take snapshots :

The virtual machine must be suspended or shut down before shutting down the computer , In this way, the virtual machine is not easy to break .
Create a script to start the cluster
[[email protected] bin]$ touch start-cluster.sh
[[email protected] bin]$ chmod u+x start-cluster.sh
[[email protected] bin]$ vi start-cluster.sh
The contents of the document are as follows :
start-dfs.sh
sleep 30
start-yarn.sh
sleep 20
mr-jobhistory-daemon.sh start historyserver
Execute the script file to start the cluster :
[[email protected] bin]$ ./start-cluster.sh
Starting namenodes on [hadoop100]
Starting datanodes
Starting secondary namenodes [hadoop100]
Starting resourcemanager
Starting nodemanagers
WARNING: Use of this script to start the MR JobHistory daemon is deprecated.
WARNING: Attempting to execute replacement "mapred --daemon start" instead.
[[email protected] bin]$ jps
5795 JobHistoryServer
5013 SecondaryNameNode
5384 NodeManager
4811 DataNode
5259 ResourceManager
5851 Jps
4703 NameNode
To configure zookeeper
Unzip the installation package and move it to another directory :
[[email protected] download]$ tar zxvf apache-zookeeper-3.5.9-bin.tar.gz
[[email protected] download]$ mv apache-zookeeper-3.5.9-bin /opt/pkg/zookeeper
modify zookeeper The configuration file :
[[email protected] bin]$ cd /opt/pkg/zookeeper/conf/
[[email protected] conf]$ ls
configuration.xsl log4j.properties zoo_sample.cfg
[[email protected] conf]$ mv zoo_sample.cfg zoo.cfg
[[email protected] conf]$ vi zoo.cfg
Because it is a single machine, only one location needs to be modified :
dataDir=/opt/tmp/zookeeper

start-up zookeeper:
[[email protected] zookeeper]$ bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /opt/pkg/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[[email protected] zookeeper]$ bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/pkg/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: standalone
The above configuration is single machine zookeeper, But generally a single machine zookeeper No need to configure multiple zookeeper Clusters are easy to use , requirement zookeeper Is odd ,3 platform 5 It's like this . Therefore, the next step is to configure the fake on a single machine zookeeper colony :
[[email protected] zookeeper]$ cd conf
[[email protected] conf]$ cp zoo.cfg zoo1.cfg
[[email protected] conf]$ vi zoo1.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/opt/tmp/zk1(zk2|zk3)
# the port at which the clients will connect
clientPort=2181(2|3)
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.1=hadoop100:2888:3888
server.2=hadoop100:2889:3889
server.3=hadoop100:2890:3890
The next two configuration files are modified in the same way :
[[email protected] conf]$ cp zoo1.cfg zoo2.cfg
[[email protected] conf]$ cp zoo1.cfg zoo3.cfg
[[email protected] conf]$ vi zoo2.cfg
[[email protected] conf]$ vi zoo3.cfg
To configure zookeeper Environmental Science :
[[email protected] bin]$ sudo vi /etc/profile.d/hadoop.env.sh
Add the following to the file :
# ZOOKEEPER 3.5.9
export ZOOKEEPER_HOME=/opt/pkg/zookeeper
PATH=$ZOOKEEPER_HOME/bin:$PATH
[[email protected] bin]$ source /etc/profile
Mark the data of the corresponding server stored in each server :
[[email protected] bin]$ mkdir /opt/tmp/zk1
[[email protected] bin]$ mkdir /opt/tmp/zk2
[[email protected] bin]$ mkdir /opt/tmp/zk3
[[email protected] bin]$ echo 1 > /opt/tmp/zk1/myid
[[email protected] bin]$ echo 2 > /opt/tmp/zk2/myid
[[email protected] bin]$ echo 3 > /opt/tmp/zk3/myid
Start the three zookeeper colony :
[[email protected] bin]$ zkServer.sh start $ZOOKEEPER_HOME/conf/zoo1.cfg
ZooKeeper JMX enabled by default
Using config: /opt/pkg/zookeeper/conf/zoo1.cfg
Starting zookeeper ... STARTED
[[email protected] bin]$ zkServer.sh start $ZOOKEEPER_HOME/conf/zoo2.cfg
ZooKeeper JMX enabled by default
Using config: /opt/pkg/zookeeper/conf/zoo2.cfg
Starting zookeeper ... STARTED
[[email protected] bin]$ zkServer.sh start $ZOOKEEPER_HOME/conf/zoo3.cfg
ZooKeeper JMX enabled by default
Using config: /opt/pkg/zookeeper/conf/zoo3.cfg
Starting zookeeper ... STARTED
[[email protected] bin]$ zkServer.sh status $ZOOKEEPER_HOME/conf/zoo1.cfg
ZooKeeper JMX enabled by default
Using config: /opt/pkg/zookeeper/conf/zoo1.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
[[email protected] bin]$ zkServer.sh status $ZOOKEEPER_HOME/conf/zoo2.cfg
ZooKeeper JMX enabled by default
Using config: /opt/pkg/zookeeper/conf/zoo2.cfg
Client port found: 2182. Client address: localhost. Client SSL: false.
Mode: leader
[[email protected] bin]$ zkServer.sh status $ZOOKEEPER_HOME/conf/zoo3.cfg
ZooKeeper JMX enabled by default
Using config: /opt/pkg/zookeeper/conf/zoo3.cfg
Client port found: 2183. Client address: localhost. Client SSL: false.
Mode: follower
[[email protected] bin]$
Continue to modify the run cluster script created above :
[[email protected] bin]$ cd /opt/bin
[[email protected] bin]$ vi start-cluster.sh
The contents of the document are as follows :
start-dfs.sh
sleep 30
start-yarn.sh
sleep 20
mr-jobhistory-daemon.sh start historyserver
zkServer.sh start $ZOOKEEPER_HOME/conf/zoo1.cfg
zkServer.sh start $ZOOKEEPER_HOME/conf/zoo2.cfg
zkServer.sh start $ZOOKEEPER_HOME/conf/zoo3.cfg
sleep 6
zkServer.sh status $ZOOKEEPER_HOME/conf/zoo1.cfg
zkServer.sh status $ZOOKEEPER_HOME/conf/zoo2.cfg
zkServer.sh status $ZOOKEEPER_HOME/conf/zoo3.cfg
View the cluster process :
[[email protected] bin]$ jps
2369 NodeManager
2259 ResourceManager
3222 QuorumPeerMain
1816 DataNode
2024 SecondaryNameNode
3272 QuorumPeerMain
3336 QuorumPeerMain
1705 NameNode
2778 JobHistoryServer
3503 Jps
install HBASE
decompression hbase Install the package and move it to the fixed directory :
[[email protected] bin]$ cd /opt/download/
[[email protected] download]$ tar zxvf hbase-2.2.3-bin.tar.gz
[[email protected] download]$ mv hbase-2.2.3 /opt/pkg/hbase
Add to environment variables :
[[email protected] download]$ sudo vi /etc/profile.d/hadoop.env.sh
[[email protected] download]$ source /etc/profile
Add the following to the file :
# HBASE 2.3.3
export HBASE_HOME=/opt/pkg/hbase
PATH=$HBASE_HOME/bin:$PATH
see hbase edition :
[[email protected] download]$ hbase version
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/pkg/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/pkg/hbase/lib/client-facing-thirdparty/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
HBase 2.2.3
Source code repository git://hao-OptiPlex-7050/home/hao/open_source/hbase revision=6a830d87542b766bd3dc4cfdee28655f62de3974
Compiled by hao on 2020 year 01 month 10 Japan Friday 18:27:51 CST
From source with checksum 097925184b85f6995e20da5462b10f3f
It needs to be solved hadoop and hbase Of jar Packet collision , Delete conflicting jar package :
[[email protected] ~]$ cd /opt/download/
[[email protected] download]$ cd $HBASE_HOME
[[email protected] hbase]$ cd lib/client-facing-thirdparty/
[[email protected] client-facing-thirdparty]$ rm slf4j-log4j12-1.7.25.jar
Look again hbase There will be no conflict between versions :
[[email protected] client-facing-thirdparty]$ hbase version
HBase 2.2.3
Source code repository git://hao-OptiPlex-7050/home/hao/open_source/hbase revision=6a830d87542b766bd3dc4cfdee28655f62de3974
Compiled by hao on 2020 year 01 month 10 Japan Friday 18:27:51 CST
From source with checksum 097925184b85f6995e20da5462b10f3f
modify hbase-env.sh file
[[email protected] conf]$ cd ../conf/
[[email protected] conf]$ ls
hadoop-metrics2-hbase.properties hbase-env.cmd hbase-env.sh hbase-policy.xml hbase-site.xml log4j-hbtop.properties log4j.properties regionservers
[[email protected] conf]$ vi hbase-env.sh
Add the following sentence to the document :
export JAVA_HOME=/opt/pkg/java
export HBASE_MANAGES_ZK=false ( Don't use hbase Self contained zookeeper colony )

modify hbase-site.xml file :
[[email protected] conf]$ vi hbase-site.xml
The content of the document is :
<configuration>
<!-- Appoint hbase stay HDFS Path stored on -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop100:8020/hbase</value>
</property>
<!-- Appoint hbase Distributed running or not -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- Appoint zookeeper The address of , Multiple use “,” Division -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop100:2181,hadoop100:2182,hadoop100:2183</value>
</property>
<!-- Appoint hbase Manage Pages -->
<property>
<name>hbase.master.info.port</name>
<value>16010</value>
</property>
<!-- In the case of distributed, be sure to set , Otherwise, it is easy to appear Hmaster Can't get up -->
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
</configuration>
modify regionservers The configuration file , Appoint HBase Host name of the slave node :
[[email protected] conf]$ vi regionservers
The content of the document is :hadoop100
start-up HBase It needs to be started in advance HDFS And ZooKeeper colony :
If it's not turned on hdfs, Please run the command :start-dfs.sh
If it's not turned on zookeeper, Please run the command :zkServer.sh start conf/zoo.cfg
Check whether the prerequisites for successful opening :
[[email protected] conf]$ jps
2369 NodeManager
2259 ResourceManager
3222 QuorumPeerMain
1816 DataNode
2024 SecondaryNameNode
3272 QuorumPeerMain
3336 QuorumPeerMain
1705 NameNode
2778 JobHistoryServer
3886 Jps
Execute the following command to start HBase colony :
[[email protected] conf]$ start-hbase.sh
running master, logging to /opt/pkg/hbase/logs/hbase-hadoop-master-hadoop100.out
hadoop100: running regionserver, logging to /opt/pkg/hbase/logs/hbase-hadoop-regionserver-hadoop100.out
[[email protected] conf]$ jps
2369 NodeManager
4050 HMaster
2259 ResourceManager
4372 Jps
3222 QuorumPeerMain
1816 DataNode
2024 SecondaryNameNode
3272 QuorumPeerMain
3336 QuorumPeerMain
1705 NameNode
2778 JobHistoryServer
4204 HRegionServer
see web Interface :192.168.186.100:16010
Get into hbase:
[[email protected] conf]$ hbase shell
HBase Shell
Use "help" to get list of supported commands.
Use "exit" to quit this interactive shell.
For Reference, please visit: http://hbase.apache.org/2.0/book.html#shell
Version 2.2.3, r6a830d87542b766bd3dc4cfdee28655f62de3974, 2020 year 01 month 10 Japan Friday 18:27:51 CST
Took 0.0182 seconds
hbase(main):001:0> status
1 active master, 0 backup masters, 1 servers, 0 dead, 2.0000 average load
Took 1.1952 seconds
Test to create a table :
hbase(main):002:0> list
TABLE
0 row(s)
Took 0.0477 seconds
=> []
hbase(main):003:0> create 'test','cf'
Created table test
Took 2.4675 seconds
=> Hbase::Table - test
hbase(main):004:0> put 'test','rowid001','cf:c1','1010'
Took 0.4597 seconds
hbase(main):005:0> scan 'test'
ROW COLUMN+CELL
rowid001 column=cf:c1, timestamp=1646071482951, value=1010
1 row(s)
Took 0.0829 seconds
hbase(main):006:0> exit
[[email protected] conf]$

边栏推荐
- Array partial method
- Elk log system practice (V): install vector and output data to es and Clickhouse cases
- Review Servlet
- What is a planning BOM?
- Warmly celebrate that yeyanxiu, senior consultant of Longzhi, won the title of "atlassian Certified Expert"
- Experimental report on information management and information system [information security and confidentiality] of Huazhong Agricultural University
- After adding the header layout to the recyclerview, use the adapter Notifyitemchanged (POS,'test') invalid local refresh
- Sword finger offer 32: print binary tree from top to bottom
- Gilde failed to go to the listener to call back the reason record when loading the Gaussian blur image
- [daily exercises] merge two ordered arrays
猜你喜欢

Login and registration based on servlet, JSP and MySQL
This is probably the most comprehensive project about Twitter information crawler search on the Chinese Internet

More than 20 cloud collaboration functions, 3 minutes to talk through the enterprise's data security experience

ThymeleafEngine模板引擎
![[IOS development interview] operating system learning notes](/img/1d/2ec6857c833de00923d791f3a34f53.jpg)
[IOS development interview] operating system learning notes

Summarize the five most common BlockingQueue features

Getting started with kotlin

Cenos7 builds redis-3.2.9 and integrates jedis

Detailed steps for installing mysql-5.6.16 64 bit green version
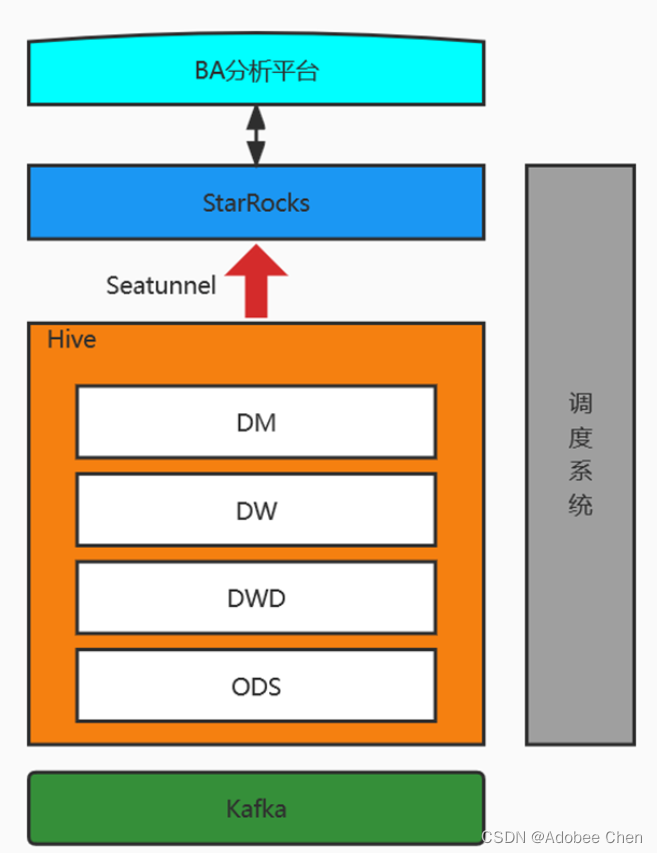
Implementation of data access platform scheme (Youzu network)
随机推荐
Servlet
NDK learning notes (14) create an avi video player using avilib+window
Super (subclass)__ init__ And parent class__ init__ ()
Informatica:数据质量管理六步法
Getting started with kotlin
箭头函数的this指向
Sqli-labs less-01
Deployment of Flink
Clojure installation of metabase source code secondary development
Clear function of ArrayList
Utiliser le fichier Batch Enum
ELK日志系统实战(五):安装vector并将数据输出到es、clickhouse案例
Mingw-w64 installation instructions
Database basic instruction set
Servlet
Distributed framework ray - detailed introduction to starting ray and connecting clusters
ThymeleafEngine模板引擎
OJDBC在Linux系统下Connection速度慢解决方案
What do you need to know about Amazon evaluation?
11. Gesture recognition