当前位置:网站首页>第三章 Encog Workbench
第三章 Encog Workbench
2022-07-22 18:55:00 【MisterZhang666】
• Encog Workbench的结构
• 一个简单的XOR示例
• 使用EncogAnalyst
• Encog分析报告
Encog Workbench是一个GUI应用程序,它能够学习大量不同的机器学习任务而不用编写java或者c#代码,EncogWorkbench本身是用java编写的,但生成的文件,可以使用于任何Encog框架。
EncogWorkbench是分布式,作为一个单一的自执行jar文件,在大多数操作系统,EncogWorkbench JAR文件简单地通过双击启动,包括了MicrosoftWindows, Macintosh和各种各样的liunx系统,使用下面的控制命令启动:

上面的jar文件可能有不同的名字,这取决于Encog的版本,不过文件名的某个地方会有“encog-workbench”和“executable”的字样,所有第三方jar文件都被放置在这个jar里,不需要其他jar文件。
3.1 Encog Workbench结构
在学习怎样使用Encog Workbench之前,我们先来学习关于它的结构,工作台使用的项目目录包含一个项目所需的所有文件,Encog Workbench工程不包含任何子目录,同时,如果子目录被添加进Encog Workbench工程,
一个EncogWorkbench工程里面也没有主“工程文件”,通常一个readme.txt或者readme.html文件是放在Encog Workbench里面以说明如何理解这个项目,然而,这个文件是工程创建者自己处理。
这里有几个不同的文件类型可能会放在Encog Workbench工程里面呢,这些文件由他们的扩展名组织,Encog Workbench由这些文件的扩展名知道如何处理这些文件,以下是Encog Workbench识别的扩展名:
以下这节将讨论每一个文件的目标
3.1.1 Workbench CSV文件
CSV文件是“comma separated values(逗号分隔值)”的首字母缩写,然而,CSV文件不总是 “逗号分隔”,世界上有些地方使用十进制逗号代替小数点的情况尤其如此,Encog使用的CSV文件可以基于小数逗号,在这种情况下,应该使用分号(;)作为字段分隔符。
CSV文件也可能使用头部来定义每一列的标题,列标题是可选的,但是强烈建议,通过Encog创建的CSV文件和用户提供的CSV文件的列标题名,属性是一致性的。
一个CSV文件通过Encog定义数据的使用,在CSV文件中每一行定义一个训练集元素和每一列定义一个属性,
特别地如果一个训练集元素的属性是未知的,那就应该在这行或者列中放置一个”?”字符,本章最后在Encog分析讨论那讨论Encog处理缺失值的各种方式。
一个CSV文件不能直接使用于神经网络的训练,首先不许转化为一个EGB文件,CSV文件转换为EGB文件,右击CSV文件,选择“Export to Training(EGB)”, EGB文件很好地定义了列输入和理想的数据,而CSV文件不提供任何区分,然而,CSV文件是用户提供的原始数据,此外,一些CSV数据文件是由用户通过Encog处理生成的。
3.1.2 Workbench EG文件
Encog EG文件储存了大量不同的对象类型,但是它自己是一个简单的文本文件,EG文件里面的所有数据是以小数点和逗号分隔存储,不管Encog运行在哪个地区,CSV文件都能够按照当地数字格式规则格式化,EG文件不是这样,所有的Encog平台保持了EG文件的一致。
EG文件存储以下的对象类型:
• 机器学习方法(i.e. 神经网络)
• NEAT populations
• 训练延续数据
Encog Workbench将展示位于工程目录的任意EG文件的对象类型,每一个Encog EG文件仅仅存储一个对象,如果多个对象需要存储,它们必须存储在独立的EG文件中。
3.1.3 Workbench EGA文件
Encog Analyst脚本文件,及EGA文件,持有Encog Analyst的实例,这些文件持有关于一个CSV文件设计到分析的统计信息,EGA文件也持有怎样处理原始数据的脚本信息描述,EGA文件通过workbech执行。
完整的讨论EGA文件和每一个可能的配置/脚本项目超出了本书的范围,然而,未来的书将致力于Encog Analyst, 此外,能够在以下找到关于Encog Analyst脚本文件的参考信息:
http://www.heatonresearch.com/wiki/EGA_File
在这章最后,我们将创建一个EGA文件分析iris数据集。
3.1.4 Workbench EGB文件
Encog二进制文件,及EGB文件,持有训练数据,在前面讨论中,对于Encog CSV文件通常转为EGB文件,数据存储一个平台独立的二进制格式,由于这样,EGB文件读速度远远快于CSV文件,此外,EGB文件内部包含了当前输入和理想的数量列,CSV文件在训练之前必须转换为EGB文件,转换一个CSV文件到一个EGB文件,右击选择CSV文件和选择“Export to Training(EGB)”。
3.1.5 Workbench Image文件
Encog workbench不直接处理图像文件,但是能够通过双击显示,Encog workbench有能力显示PNG,JPG和GIF文件。
3.1.6 Workbench Text文件
Encog Workbench不直接使用文本文件,然而,文本文件是工程文件使用者存储说明的一种方式,例如,readme.txt文件能够被添加到工程和显示分析细节,Encog workbench能够显示text和html两种文件.
3.2一个简单的XOR例子
这里有大量不同的方式使用EncogWorkbench, Encog Analyst能够使用来创建工程包括规范化,训练和分析,然而,所有个人也能够手动创建和训练神经网络的部分,如果数据直接规范化,Encog Analyst也就不是必要的了。
在这节我们将看到怎样使用EncogWorkbench而不是Encog Analyst去创建一个简单的XOR神经网络,XOR数据集不要求任何的规范化因为它早就已经在0到1范围了。
我们开始创建一个新工程。
3.2.1 新建一个工程
首先启动EncogWorkbench创建一个新工程,一旦Encog Workbench启动,就有个creating a new project(创建一个新工程),opening anexisting project(打开一个存在的工程)或者quitting will appear的选项,选择创建一个新工程和将其命名为“XOR”,这将创建一个新的空的名字为XOR的文件夹,你现在将在图3.1中看到Encog Workbench:
这是一个EncogWorkbench的基本布局,这儿是三个主区域,在左侧高矩形部分显示所有工程文件,当前的这个工程没有文件,你也能够看见日志输出和状态信息,日志输出上面的矩形是文档打开区域,Encog workbench看起来非常像IDE,开发人员应该很熟悉。
3.2.2 生成训练数据
下一步就是获取训练数据,这儿有几种方式,首先,Encog Workbench支持拖拽,例如,能够将CSV从操作系统中拖和拽就像复制进入这个工程,使源文件不改变,这些文件将出现在工程树结构中。
Encog Workbench 平台内置了大量的训练集,此外,它也够下载外部数据例如股票价格和太阳黑子信息,太阳黑子能够在时间序列预测实验中使用。
Encog Workbench构建一个XOR训练集及访问它,选择 Tolls->Generate Training Data, 打开“CreateTraining Data”对话框,选择“XOR 训练集”和命名为“xor.csv”, 这个新CSV文件将显示在工程树种。
如果你双击“XOR.csv”文件,你将看见以下的训练集:
重要的是要注意文件的头,当生成EGB文件时候必须指定。
3.2.3 创建一个神经网络
现在训练数据已创建,也应该创建一个神经网络来学习这个xor数据,创建一个神经网络,选择 File->new file, 然后选择 machine learningmethod 并且将神经网络命名为”xor.eg”,选择”feedforward neural network”,这将显示如下的对话框:
一定要填写完整上面的表格,这儿应该有两个输入神经元,一个输出神经元和一个单一隐藏层有两个神经元,两个的激活函数选择为sigmoid, 一旦神经网络创建,它将出现在工程树结构中。
3.2.4 神经网络的训练
现在是训练这个神经网络的时候了,你看到目前这个神经网络还未训练,如果简单地确定该神经网络未训练,双击EG文件包含神经网络,这将显示图3.3

屏幕上显示这个神经网络的基本统计信息,要看跟多细节,选择“visualize”按钮和选择“network structure”, 这将显示图3.4:
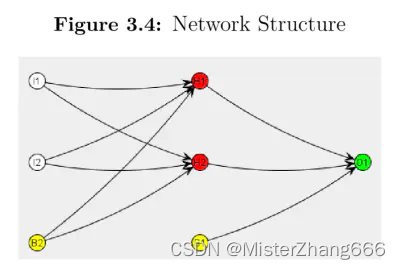
从这个结构中可以看到输入和输出神经元,隐藏层和偏执神经元之间的所有连接可见,偏执神经元,以及隐藏层,它们帮助神经网络学习。
这些已完成,是时候真真训练这个神经网络了,先关闭这个图显示和神经网络,这里工作台里面应该没有文档打开。
右击“xor.csv”训练数据,选择“Exportto Training(EGB)”, 在出现的对话框中填入两个输入神经元和一个输出神经元,在下一个对话框中,一定要指定标题,一旦这些完成,一个EGB文件将添加到工程树中,结果将有三个文件:EG文件,EGB文件和CSV文件。
训练这个神经网络,选择”Tools->Train”,这将打开一个对话框,选择一个训练集和机器学习方法,由于这里仅仅是一个EG文件和EGB文件,因此这个对话框应该默认为正确的值,点击“Load to Memory”复选框,因为这是一个很小的训练集,所以没有理由不加载到内存中。
从这里可以选择很多不同的训练方法,对于这个示例,选择“Propagation-Resilient”,对于这个训练类型接受所有默认参数,一旦这些完成,训练程序选项卡将出现,点击“Start”开始训练。
训练通常在一秒以内完成,然而,如果训练持续了几秒钟,那可能需要点击下拉列表“”进行重置,选择重置这个网络,因为神经网络启动是随机权重的,训练时间将会不同,在一个小的神经网络,例如XOR,权重可能很糟糕足以让神经网络不训练,如果是这样,简单地重置网络重新训练它。
3.2.5 神经网络的评估
这里有两种方式评价神经网络,首先是通过选择”Tools->Evaluate Network”来简单计算神经网络的错误率,将提示你机器学习方法和使用训练数据,当计算再一次指定训练集的时候将显示你的神经网络错误率。
例如,错误率将是一个百分比,当计算这个百分比的时候,低的百分比是最好的,其他机器学习方法也许生成一个错误数字或者其他的值。
对于更多先进的计算,选择“Tools->ValidationChart”.这将产生类似于图3.5的输出: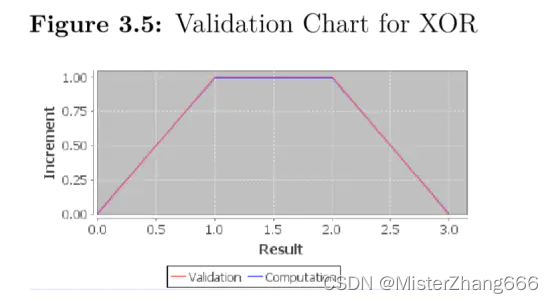
这个图形化的描述显示了神经网络的计算与理想值(验证)相匹配,如本例所示,他们非常接近。
3.3使用Encog分析
在上一节我们使用了workbench的一个不需要规范化的简单数据集,在这节我们将使用EncogAnalyst向更复杂的数据集工作 ---- 这个iris数据集已经示范了好几次了。规范化过程也早已经探索过了。然而,这里将使用EncogAnalyst提供一个例子,怎样规范化和产生一个神经网络。
Iris数据集已经建立在Encog Workbench平台上了,所以很容易为它创建一个数据集。创建一个新的Encog Workbench工程正如上一节所描述,这里将其命名为’Iris”。获取这个iris数据集,选择“Tools->Generate Training Data”, 选择”IrisDataset” 和将其命名为”iris.csv”。
右击iris.csv文件并且选择“AnalystWizard”,这将弹出如图3.6的对话框:
你可以都接受大部分默认值,然而,”Target Field”和”CSV File Headers”字段应该改变,target指定为”species”和指定有标题。其他两个选项卡应该保持不变。点击OK,之后将生产一个EGA文件。
这个练习也提供了怎样处理错误值的选项,虽然这个iris数据集没有错误值,但不是每个示例数据集都是这种情况。默认的操作是丢弃他们,然而,你也可以选择平均它们。
双击这个EGA文件看到如图3.7内容:
从这个选显卡你能够执行这个EGA文件,点击“Execute”和一个状态对话框将显示。在这里,点击“Start”开始处理,完整的执行在大多数计算机中应该不到一分钟。
• 第一步:随机化– 洗牌这个文件将其为一个随机顺序。
• 第二步:隔离– 创建一个训练数据集合一个评价数据集
• 第三步:规范化–为所选的机器学习方法规范化这个数据让其可用
• 第四步:生成– 生成训练数据到一个EGB文件让其能够使用训练
• 第五步:创建– 生成选择机器学习方法
• 第六步:训练– 训练选择的机器学习方法
• 第七步:评估– 评估机器学习方法
这个过程将创建大量的文件,在这个工程中完整的文件列表如下:
• Iris.csv – 原始数据
• Iris.ega – EGA文件,这是Encog Analyst脚本
• Iris_eval.csv – 评价数据
• Iris_norm.csv – iris_train.csv规范化版本
• Iris_output.csv – 来自iris_eva.csv运行的输出
• Iris_random.csv – 来自运行iris.csv的随机输出
• Iris_train.csv – 训练数据
• Iris_train.eg – 训练的机器学习方法
• Iris_train.egb – 从iris_norm.egb创建的二进制数据
对于向导程序如果改变EGA脚本文件或者使用了不同选项,你可能有不同的步骤。
看看网络是这样执行的,打开iris_output.csv文件,你将看到如下的列表3.2:
这个描述了神经网络怎样去尝试预测每一行的iris属于哪个种类,正如你看见的,这里显示的所有行都是正确的,这些数据项是神经网络最初没有被训练过的。
3.4 Encog分析报告
这一节将讨论怎样用EncogWorkbench产生多种Encog 分析报告,对于产生这些报告,打开EGA文件如图3.7所示,点击“Visualize”按钮你能得到几个可视化选项,能够选择“Range Report”或者“Scatter Plot”两者之一,这两个将在下一节讨论。
3.4.1 范围报告
范围报告显示通过EncogAnalyst执行使用的每一个属性范围,图3.8开始显示这个范围报告: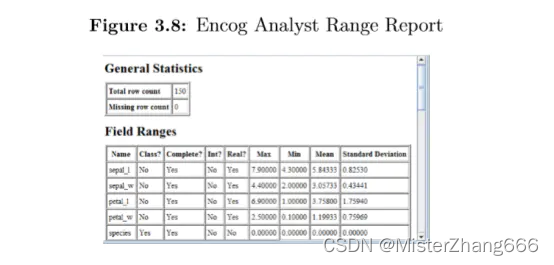
这里只显示顶部的部分,另外能够通过上下滚动来查看更多信息。
3.4.2 散点图
还可以显示散点图来查看两个或多个属性间的关系,当选择这个散点图显示的时候,Encog Analyst将提示你选择哪一个属性关联,如果你只是选择两个,则显示一个普通的散点图,如果你选择所有的四个,你将被显示多变量的散点图,如图3.9所示:

这说明了四个属性是如何关联的,查看属性是如何关联,选择对角线上的两个正方形,沿着每个行和列,相交的平方是这两个属性之间的关系,同样重要的是要注意,对角线上方形形成的三角形是对角线下方三角形的图像(反向)
3.5总结
这章介绍了EncogWorkbench, Encog Workbench是一个神经网络可视化工作和其他机器学习方法的GUI应用程序,这个工作台是一个java应用程序,在任何Encog平台产生数据。
这章演示了对于数据早就规范化的情况下怎样直接使用Encog Workbench创建和训练一个神经网络,这是训练和评估神经网络一个很好的方式,创建和训练神经网络都在这个工作台上完成。
对于更多复杂的数据,EncogAnalyst是一个执行自动化的强大的工具,它也组织了一个神经网络执行一些列任务,iris数据集的使用说明了怎样使用EncogAnalyst。
到目前为止,这本书介绍了怎样使用Encog Analyst规范化和处理数据,下一章将说明怎样用Encog框架代码直接构造神经网络,不用EncogAnalyst。
边栏推荐
- 如何打包你的项目并且可以让别的用户通过pip安装
- 【JS】ES6-箭头函数
- USACO data set (2022.07.22)
- Centos7 installing and uninstalling mysql5.7
- My code - speed version
- ZLMediaKit尝试解决GB28181(UDP方式)的视频花屏问题
- Image-to-Image Translation with Conditional Adversarial Networks 论文笔记
- Live video system source code, save platform video content locally
- 华泰证券ETF基金开户怎么样安全吗
- Oracle switches users and queries database commands under linux environment
猜你喜欢

SFM与MVS区别

Real time face detection using mediapipe and opencv

【机器学习】模型选择(性能度量)原理及实战

Evolution Atlas of interface documents. People who have used the first interface document tool are exposed to their age

Understand JS prototype and prototype chain in one article

urllib下载(urlretrieve())

图文并茂演示小程序movable-view的可移动范围
![[machine learning basics] unsupervised learning (5) -- generation model](/img/55/14c03c170ae73e121ca89b716bf9c6.png)
[machine learning basics] unsupervised learning (5) -- generation model

Configure point cloud library pcl1.12.1 for visualstudio2019 under win10 system

1. Summary of strengthening learning foundation
随机推荐
Brief analysis of mobile app security testing of software testing, shared by Beijing third-party software testing institutions
7.20 Codeforces Round #763 (Div. 2) C(二分) D(数学期望)背包+树形dp复习
Which one works better, Yapi or apifox? In depth analysis of the functional features of Yapi and apifox
【黄啊码】MySQL入门—3、我用select *,老板直接赶我坐火车回家去,买的还是站票
Zhang Li, President of China Electronic Information Industry Development Research Institute: building China's leading open source value chain
Image-to-Image Translation with Conditional Adversarial Networks 论文笔记
Idea debug is stuck during startup. Solution
R 语言绘制 倾斜图
How to configure a cute little shark theme for typera?
Video knowledge points (17) - flv Skills of playing local video files with JS
Add t.test significance to R language box diagram-
关系型数据库数据库基本概念
Chapter 6.3: manual compilation of starrocks under arm architecture (expansion)
Tan Zhongyi, the initiator of xingce community: promote the intelligent transformation of enterprises by means of open source
urllib的一个类型和六个方法
Jmeter-记一次自动化造数引发的BeanShell写入excel实例
R language rendering space visualization
MNIST dataset
Dao智能合约Dapp系统开发技术
IDEA DEBUG启动一直卡着不动解决办法