当前位置:网站首页>CMU提出NLP新范式—重构预训练,高考英语交出134高分
CMU提出NLP新范式—重构预训练,高考英语交出134高分
2022-06-28 01:03:00 【智源社区】
本文提出的重构预训练(reStructured Pre-training,RST),不仅在各种 NLP 任务上表现亮眼,在高考英语上,也交出了一份满意的成绩。
我们存储数据的方式正在发生变化,从生物神经网络到人工神经网络,其实最常见的情况是使用大脑来存储数据。随着当今可用数据的不断增长,人们寻求用不同的外部设备存储数据,如硬盘驱动器或云存储。随着深度学习技术的兴起,另一种有前景的存储技术已经出现,它使用人工神经网络来存储数据中的信息。
研究者认为,数据存储的最终目标是更好地服务于人类生活,数据的访问方式和存储方式同样重要。然而,存储和访问数据的方式存在差异。历史上,人们一直在努力弥补这一差距,以便更好地利用世界上存在的信息。如图 3 所示:

在生物神经网络(如人脑)方面,人类在很小的时候就接受了课程(即知识)教育,以便他们能够提取特定的数据来应对复杂多变的生活。
对于外部设备存储,人们通常按照某种模式(例如表格)对数据进行结构化,然后采用专门的语言(例如 SQL)从数据库中有效地检索所需的信息。
对于基于人工神经网络的存储,研究人员利用自监督学习存储来自大型语料库的数据(即预训练),然后将该网络用于各种下游任务(例如情绪分类)。
来自 CMU 的研究者提出了一种访问包含各种类型信息数据的新方法,这些信息可以作为指导模型进行参数优化的预训练信号。该研究以信号为单位结构化地表示数据。这类似于使用数据库对数据进行存储的场景:首先将它们构造成表或 JSON 格式,这样就可以通过专门的语言 (如 SQL) 准确地检索所需的信息。
此外,该研究认为有价值的信号丰富地存在于世界各类的数据中,而不是简单地存在于人工管理的监督数据集中, 研究人员需要做的是 (a) 识别数据 (b) 用统一的语言重组数据(c)将它们集成并存储到预训练语言模型中。该研究称这种学习范式为重构预训练(reStructured Pre-training,RST)。研究者将这个过程比作「矿山寻宝」。不同的数据源如维基百科,相当于盛产宝石的矿山。它们包含丰富的信息,比如来自超链接的命名实体,可以为模型预训练提供信号。一个好的预训练模型 (PLM) 应该清楚地了解数据中各种信号的组成,以便根据下游任务的不同需求提供准确的信息。

论文标题:
reStructured Pre-training
论文链接:
https://arxiv.org/pdf/2206.11147.pdf
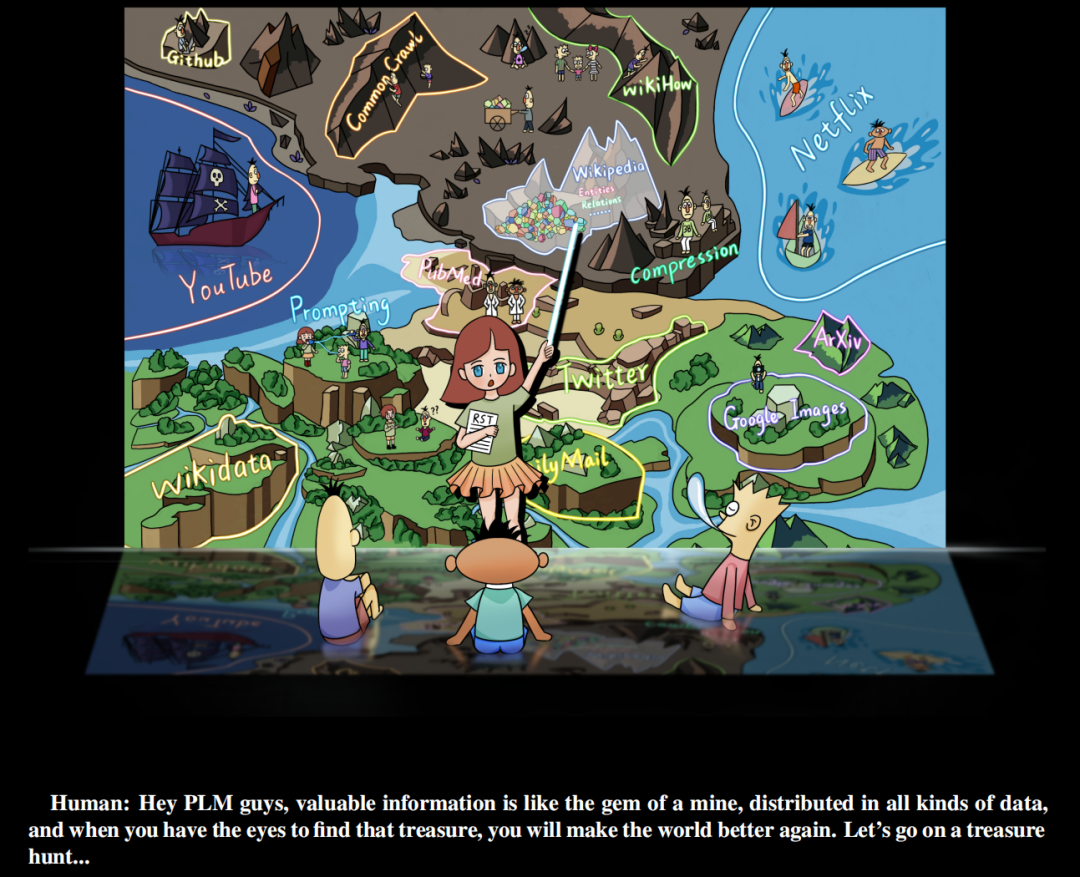
▲ 预训练语言模型寻宝
该研究提出自然语言处理任务学习的新范式,即 RST,该范式重新重视数据的作用,并将模型预训练和下游任务的微调视为数据的存储和访问过程。在此基础上,该研究实现了一个简单的原则,即良好的存储机制不仅应该具有缓存大量数据的能力,还应该考虑访问的方便性。
在克服了一些工程挑战后,该研究通过对重构数据(由各种有价值的信息而不是原始数据组成)进行预训练来实现这一点。实验证明,RST 模型不仅在来自各种 NLP 任务(例如分类、信息抽取、事实检索、文本生成等)的 52/55 流行数据集上表现大幅超过现有最好系统(例如,T0),而且无需对下游任务进行微调 。在每年有数百万学生参加的中国最权威的高考英语考试中也取得了优异的成绩。
具体而言,本文所提出的高考 AI (Qin) 比学生的平均分数高出 40 分,比使用 1/16 参数的 GPT3 高出 15 分。特别的 Qin 在 2018 年英语考试中获得了 138.5 的高分(满分 150)。
此外,该研究还发布了高考基准(Gaokao Benchmark)在线提交平台,包含 2018-2021 年至今 10 篇带注释的英文试卷(并将每年进行扩展),让更多的 AI 模型参加高考,该研究还建立了一个相对公平的人类和 AI 竞争的测试平台,帮助我们更好地了解我们所处的位置。另外,在前几天(2022.06.08)的 2022 年高考英语测试中,该 AI 系统获得了 134 分的好成绩,而 GPT3 只获得了 108 分。

该研究的主要贡献包括:
1. 提出 NLP 方法的演进假说。该研究试图通过探索现代 NLP 技术发展之间的内在联系,从全局的角度建立了「NLP 技术演进假说」。简而言之,该假说的核心思想是:技术的迭代总是沿着这样的方向发展:即开发者只需做更少的事情便可以来设计更好、更通用的系统。

重构预训练


重构工程


在55种常用的NLP数据集上的实验












边栏推荐
- 字节跳动面试官:一张图片占据的内存大小是如何计算
- Flask基础:模板渲染+模板过滤使用+控制语句
- 11 timers for STM32F103
- JS implementation clock
- Flashtext, a data cleaning tool, has directly increased the efficiency by dozens of times
- 【电梯控制系统】基于VHDL语言和状态机实现的电梯控制系统的设计,使用了状态机
- 转载文章:数字经济催生强劲算力需求 英特尔发布多项创新技术挖掘算力潜能
- 初始线性回归
- Interpretation of the source code of scheduledthreadpoolexecutor (II)
- Character interception triplets of data warehouse: substrb, substr, substring
猜你喜欢

Cloud native (30) | kubernetes' app store Helm

Opencv -- Hough transform and some problems encountered

【历史上的今天】6 月 5 日:洛夫莱斯和巴贝奇相遇;公钥密码学先驱诞生;函数语言设计先驱出生
字节跳动面试官:一张图片占据的内存大小是如何计算
![[today in history] June 10: Apple II came out; Microsoft acquires gecad; The scientific and technological pioneer who invented the word](/img/0d/9f99eb3dcb73c912987b81fba71890.png)
[today in history] June 10: Apple II came out; Microsoft acquires gecad; The scientific and technological pioneer who invented the word "software engineering" was born

第一次使用gcc和makefile编写c程序
![[today in history] June 6: World IPv6 launch anniversary; Tetris release; Little red book established](/img/06/895913d2c54b03cde86b3116955a9e.png)
[today in history] June 6: World IPv6 launch anniversary; Tetris release; Little red book established
> Could not create task ‘:app:MyTest.main()‘. > SourceSet with name ‘main‘ not found.问题修复

MySQL collection, here are all the contents you want

【历史上的今天】6 月 20 日:MP3 之父出生;富士通成立;谷歌收购 Dropcam
随机推荐
【历史上的今天】6 月 10 日:Apple II 问世;微软收购 GECAD;发明“软件工程”一词的科技先驱出生
ROS+Gazebo中红绿黄交通灯如何实现?
[today in history] June 10: Apple II came out; Microsoft acquires gecad; The scientific and technological pioneer who invented the word "software engineering" was born
Keil "St link USB communication error" solution
畢業總結
MFC common current path
被通知裁员后拿到5个offer
MFC常用 当前路径
Truth table of common anode digital tube
【历史上的今天】6 月 20 日:MP3 之父出生;富士通成立;谷歌收购 Dropcam
Solutions to st link USB communication error
Teach you how to realize pynq-z2 bar code recognition
The graduation season is coming, and the number of college graduates in 2022 has exceeded 10 million for the first time
【历史上的今天】6 月 7 日:Kubernetes 开源版本发布;《魔兽世界》登陆中国;分组交换网络发明者出生
[inverted pendulum control] Simulink simulation of inverted pendulum control based on UKF unscented Kalman filter
【二維碼圖像矯正增强】基於MATLAB的二維碼圖像矯正增强處理仿真
"Dadao Zhichuang" won a ten million prea+ round of financing and launched a technology consumption robot
【历史上的今天】6 月 19 日:iPhone 3GS 上市;帕斯卡诞生;《反恐精英》开始测试
math_(函数&数列)极限的含义&误区和符号梳理/邻域&去心邻域&邻域半径
Cloud native (30) | kubernetes' app store Helm