当前位置:网站首页>一次做数据报表的踩坑经历,让我领略了数据同步增量和全量的区别
一次做数据报表的踩坑经历,让我领略了数据同步增量和全量的区别
2022-08-03 14:53:00 【InfoQ】

一、背景介绍

二、问题概述
- 全量导入:定时的将所有数据更新一次,然后重新进行导入。如果数据量不大的话,这种方案就适合,但是考虑到,如果以后数据量庞大的话,这种方案效率不高。
- 增量导入:数据库中的每张表都会有一个更新时间的字段,如果数据有更新,只需要根据更新时间的字段,将最新的一条数据拉过来,然后覆盖掉之前的数据,这样的好处就是,数据量不会变得很大,不会有冗余的脏数据产生,感觉效率挺不错的。
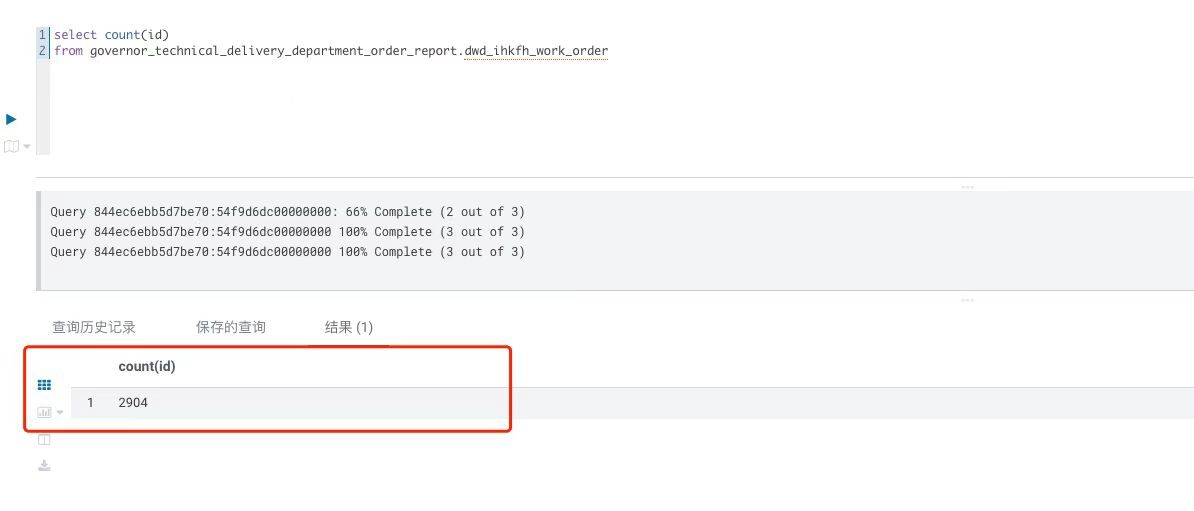
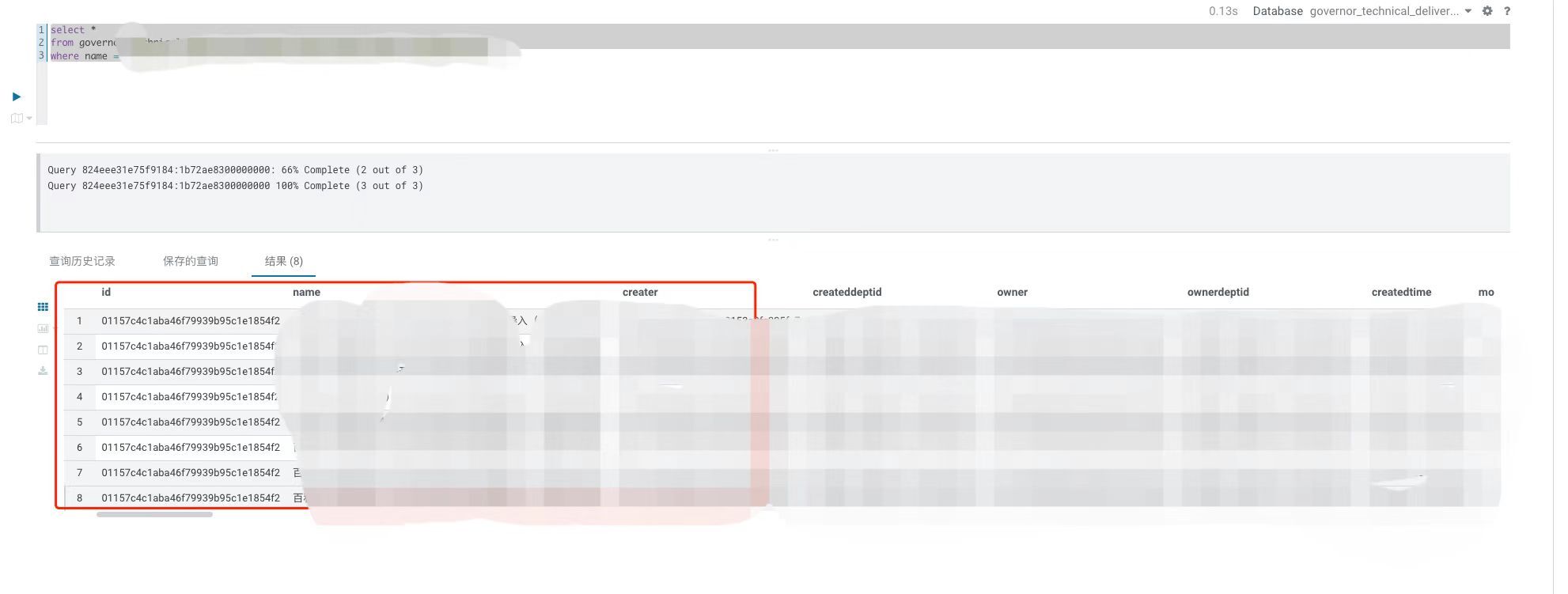
select count(*) from xxx ;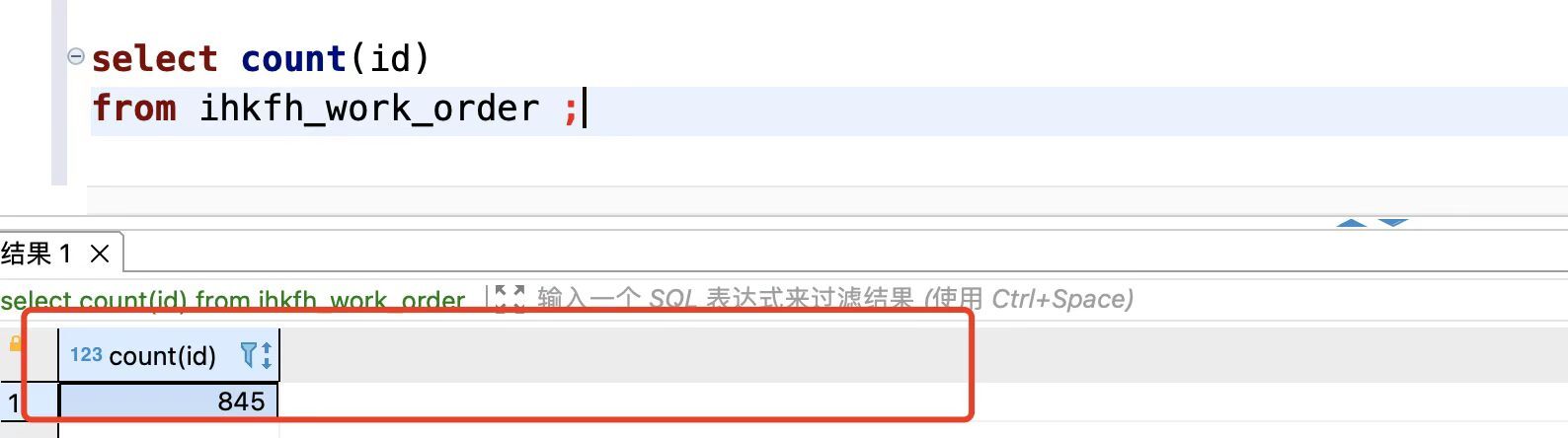
三、聊聊全量和增量
- 数据如果保留多份或者多处使用,就会存在一致性问题,解决一致性问题就需要同步,
- 同步分为两大类:全量和增量
- 每天定时(避开业务高峰期)或者周期性,全量把数据从一个地方拷贝到另外一个地方;
- 采用直接全部覆盖(使用“新”数据覆盖“旧”数据);或者更新逻辑(覆盖前判断下,如果新旧不一致,就更新。
- 增量的基础是全量,就是要使用某种方式先把全量数据拷贝过来,然后再采用增量方式同步更新;
- 抓取某个时刻(更新时间)或者检查点(checkpoint)以后的数据来同步,不是无规律的全量同步。
- 全量是有规律的、周期性的;增量是无规则、无规律的;
- 增量的基础是全量;
- 全量会让新的数据覆盖掉旧的数据,而增量无法覆盖旧数据;

四、总结

边栏推荐
- HDU 1160 FatMouse's Speed(最长递减子序列变形)
- eolink告诉你,国内Api行业,可以内卷到什么程度?
- 【MATLAB项目实战】基于CNN_SVM的图像花卉识别
- How to connect a VMware virtual machine to the network "recommended collection"
- Detailed explanation of cloud hard disk EVS and how to use and avoid pits [HUAWEI CLOUD is simple and far]
- 问题4:什么是缺陷?你们公司缺陷的优先级是怎样划分的?
- 2022-08-03日报:汪林望 vs 刘铁岩:AI、机器学习在材料科学研究中能发挥哪些作用?
- The difference between servlet and jsp _ the difference between servlet and class
- 你把 浏览器滚动事件 玩明白
- MMA安装及使用优化
猜你喜欢
System learning Shell regular expressions
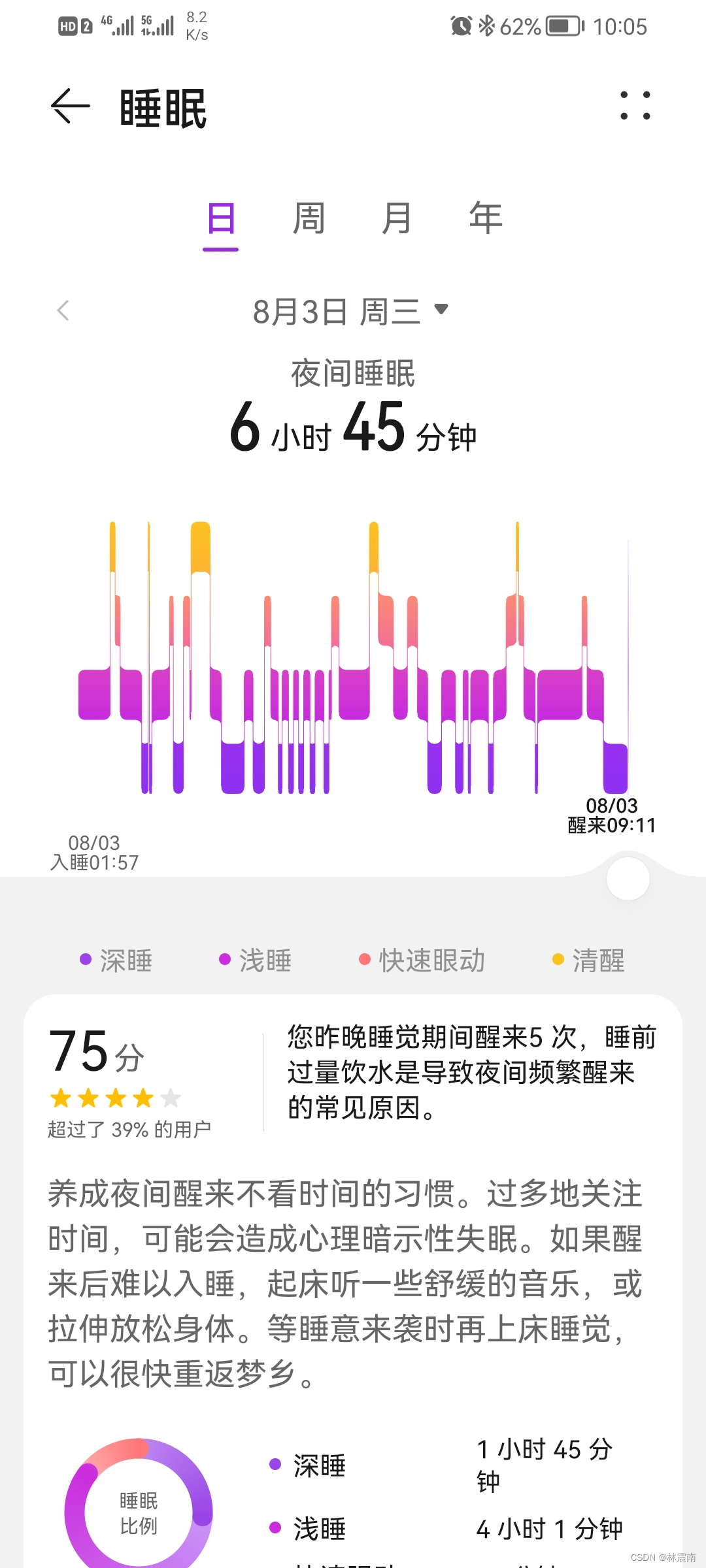
今日睡眠质量记录75分

MySQL性能优化的'4工具+10技巧'
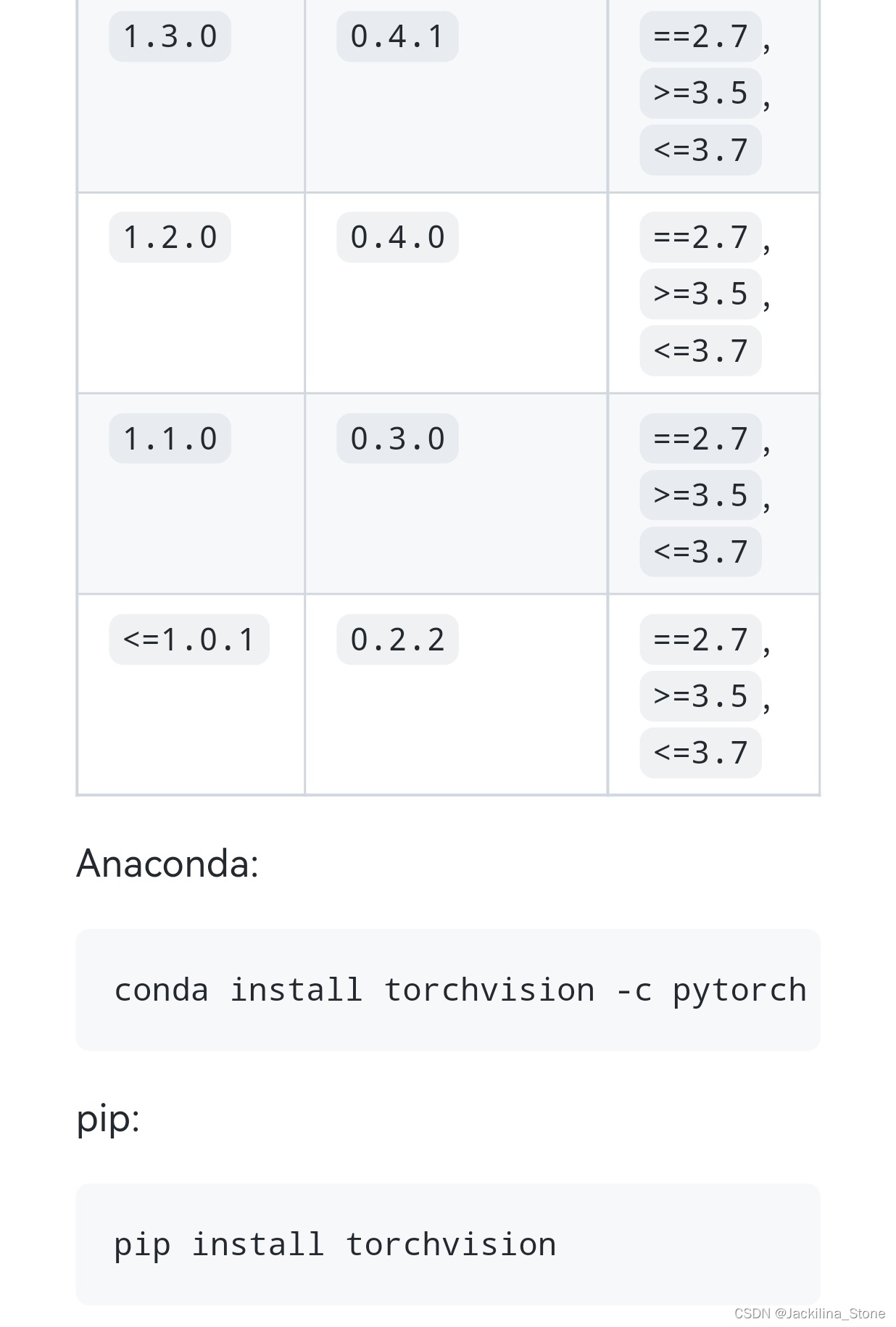
【问题】torch和torchvision对应版本
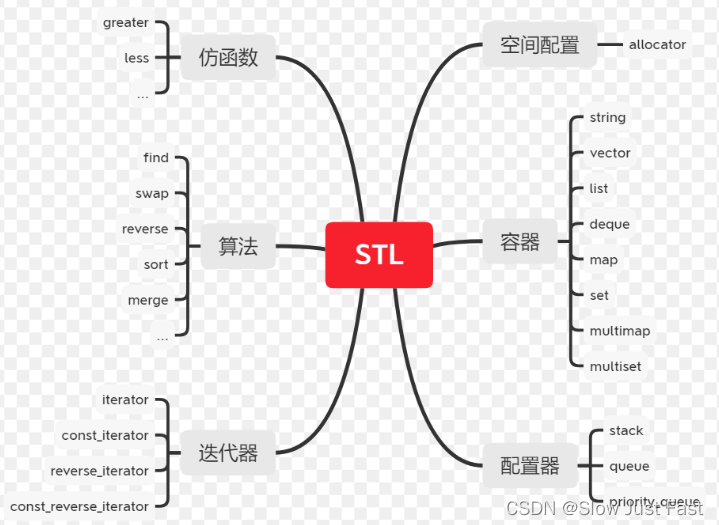
STL简介
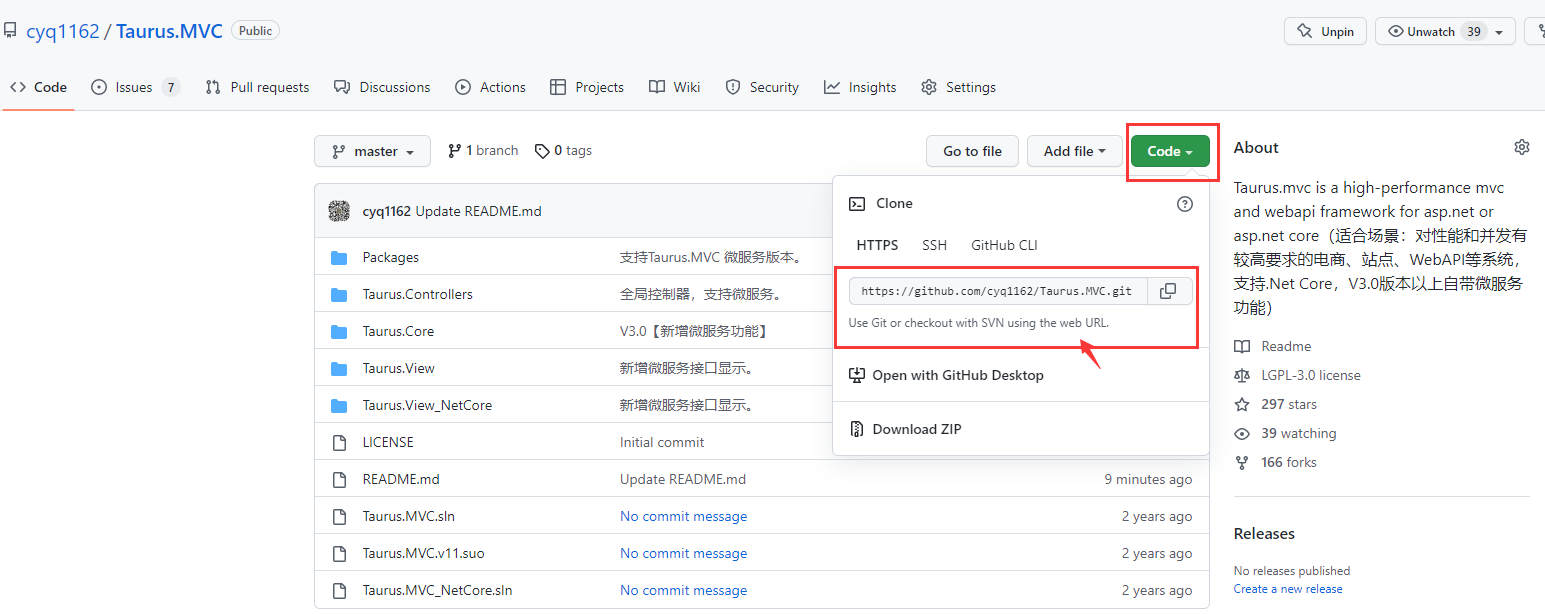
Taurus.MVC WebAPI 入门开发教程1:框架下载环境配置与运行(含系列目录)。
Mysql 生成排序序号
![[The Beauty of Software Engineering - Column Notes] 36 | What exactly do DevOps engineers do?](/img/7e/405a32a67ba48342179bfbcb214f09.png)
[The Beauty of Software Engineering - Column Notes] 36 | What exactly do DevOps engineers do?

Tao Te: Engine or baggage?

王守创:多组学整合分析揭示植物代谢多样性的分子机制(8月2号晚)
随机推荐
地球自转加快
[The Beauty of Software Engineering - Column Notes] 36 | What exactly do DevOps engineers do?
STL简介
跨桌面端之组件化实践
redis的使用方法
内心的需求
UE4 C disk cache solution
PHP中高级面试题 – 第三天
夜神浏览器fiddler抓包
162_Power Query is a custom function for quickly merging tables in a folder TableXlsxCsv_2.0
未来无法预料
WMS软件国内主要供应商分析
C语言将GLib库添加到CMake工程中
一文搞懂$_POST和php://input的区别
【问题】使用pip安装第三方库的时候遇到“timeout”的解决方法
你没见过的《老友记》镜头,AI给补出来了|ECCV 2022
网络通信的过程
【报错】import cv2 as cv ModuleNotFoundError: No module named ‘cv2
Clickhouse填坑记3:Left Join改Right Join导致统计结果错误
选择合适的 DevOps 工具,从理解 DevOps 开始