当前位置:网站首页>Reading notes of Clickhouse principle analysis and Application Practice (1)
Reading notes of Clickhouse principle analysis and Application Practice (1)
2022-06-30 21:19:00 【Aiky WOW】
Begin to learn 《ClickHouse Principle analysis and application practice 》, Write a blog and take reading notes .
The whole content of this article comes from the content of the book , Personal refining .
Foreword and recommendations
skip
The first 1 Chapter ClickHouse The past and this life
Follow ck It doesn't matter much , Just go through it once . You can jump directly without looking .
1.1 Tradition BI System war
To solve the problem of data islands , People put forward the concept of data warehouse . That is, by introducing a database dedicated to analyzing class scenarios , Gather scattered data in one place .
On 20 century 90 years , Someone put forward for the first time BI( business intelligence ) System The concept of . Since then, , People usually use BI The term "system" refers to such an analytical system . Compared with online transaction processing system , We put this kind of BI The system is called Online analytics (OLAP) System .
BI defects :
- The system requires a higher level of enterprise informatization , Usually only large and medium-sized enterprises have the ability to implement
- The audience is narrow , The main audience is the management or decision-making level in the enterprise
- The research and development process is lengthy
1.2 modern BI The new trend of thought of the system
modern BI Changes in the design idea of the system :
- Lightweight . Even if only based on simple Excel Documents can also be used for data analysis .
- Diverse audiences . Everyone can do it .
- Although it is still privatized , But the user experience tends to respond quickly , Simple and easy to use .
Tradition BI System is OLTP Type database ( Relational database ).
modern BI The typical application scenario of the system is multidimensional analysis , by OLAP Type database .
1.3 OLAP Common architecture categories
OLAP It means looking at data through many different dimensions , Conduct in-depth analysis .
Explanation of several analysis operations of data , The concept of things , Understanding can :
- Scroll up : From low level to high level . For example, from “ City ” Remit Coalescence “ province ”, take “ wuhan ”“ yichang ” Converge into “ hubei ”.
- Run in : Contrary to the previous volume , From high-level to low-level detail data penetration . For example, from “ province ” Drill down to “ City ”, from “ Hubei province ” Penetrate to “ wuhan ” and “ yichang ”.
- section : Look at one layer of the cube , Set one or more dimensions to a single fixed value , Then look at the remaining dimensions , For example, fix the commodity dimension to “ football ”.
- cutting : Similar to slicing , Just change a single fixed value into multiple values . For example, will quotient The product dimension is fixed to “ football ”“ Basketball ” and “ Table Tennis ”.
- rotate : Rotate one side of the cube , If you want to map data to a two-dimensional table , Then you have to rotate , This is equivalent to row column replacement .
An example is shown in the figure 1-1.

common OLAP The architecture is roughly divided into three categories :
- ROLAP(Relational OLAP, Relational type OLAP). Use the relational model directly to build , Data models often use star models or snowflake models . The most direct implementation method . The disadvantage is that The requirement for real-time data processing capability is very high .
- MOLAP(Multidimensional OLAP, Multidimensional OLAP). The core idea is to use pre aggregated results , Use space for time Finally, the query performance is improved . It's to relieve ROLAP Performance issues . The disadvantage is that Dimension preprocessing may lead to data expansion .
- HOLAP(Hybrid OLAP, Hybrid architecture OLAP). Comprehend ROLAP and MOLAP Integration of the two .
Regardless of performance , Consider purely from a model point of view ,ROLAP Architecture is better . Simpler and easier to understand . It directly faces the detailed data query , No preprocessing required .
1.4 OLAP Realize the evolution of technology
The evolution process is simply divided into two stages :
- Traditional relational database stage . There are serious performance problems .
- ROLAP Under the architecture , Use Oracle、MySQL A kind of database is used as the carrier of storage and calculation
- MOLAP Under the architecture , The data cube is realized in the form of materialized view .
- Big data technology stage .
- ROLAP Under the architecture , Use Hive and SparkSQL A system of equal distribution .
- MOLAP Under the architecture , Depending on the MapReduce,Spark,HBase, There is still a dimension explosion 、 The real-time performance of data synchronization is not high .
1.5 A dark horse born in the sky
Is blowing black farts , say ck What a bull .
ck Both use ROLAP Model , At the same time, it has the same level MOLAP Performance of .
1.5.1 The world's martial arts are only fast
ck have ROLAP、 Online real-time check Inquiry 、 complete DBMS、 The column type storage 、 No data preprocessing is required 、 Support batch change new 、 Have a very perfect SQL Support and function 、 Support high availability 、 Do not rely on Hadoop complex ecology 、 Out of the box and many other features .
1.5.2 The community is active
ClickHouse It's an open source software , follow Apache License 2.0 agreement . Community renewal is active .
1.6 ClickHouse Development history of
With Yandex.Metrica Business development ,ClickHouse The underlying architecture goes through four stages :
1.6.1 It makes sense MySQL period
The data acquisition link of traffic is as follows : The application on the website first passes through Yandex Site provided SDK Collect data in real time and send it to the remote receiving system , Then, the receiving system writes the data into MySQL colony . Lead to Data is stored completely randomly on disk , And will produce a large number of disk fragments .
1.6.2 A new way Metrage period
Metrage In design with MySQL Completely different :
- At the data model level , It USES Key-Value Model ( Key value Yes ) Instead of the relational model ;
- At the index level , It USES LSM Trees have replaced B+ Trees ;
- At the data processing level , From real-time query to preprocessing .
LSM Trees are also a very popular index structure , Originated in Google Of Big Table, Now the most representative use LSM The system of tree index structure is HBase.LSM Write data flow :
- Save data in memory .( The pre written log is guaranteed not to be lost )
- Memory data sorting .
- Threshold reached , Background thread brushes memory data to disk .
- The data in the field is in order , Therefore, sparse index can be used to optimize query performance .
Pretreatment upper , Pre aggregate the data to be analyzed . Aggregate the result data according to KeyValue Form storage of .
The new problem is Dimension combination explosion , Because all dimension combinations need to be calculated in advance .
1.6.3 Self breakthrough OLAPServer period
- Data model , We have switched back to the relational model .
- Storage structure , It is associated with MyISAM The table engine is similar , It is divided into index file and data file .
- Index aspect , Used LSM Sparse index of tree .
- Data file design , Continue to use LSM Tree data segment , That is, the data in the data segment is orderly , Locate data segments with sparse indexes .
- Column storage is introduced , Each column field is stored independently .
OLAPServer The positioning of is only related to Metrage Form complementarities , So it's missing Some basic functions . Such as no DBMS Basic management functions (DDL Query etc. )
1.6.4 It's a matter of course ClickHouse Time
The problem of prepolymerization :
- Pre aggregation cannot satisfy custom analysis .
- The explosion of dimension combination will lead to data inflation .
- Traffic data is received online in real time , Therefore, pre aggregation also needs to consider how to update data in time .
because OLAPServer Successful experience , The choice tends to be real-time aggregation .

1.7 ClickHouse The meaning of the name
ClickHouse The full name is Click Stream,Data WareHouse, abbreviation ClickHouse.
1.8 ClickHouse Applicable scenarios
Great for business intelligence ( That's what we're talking about BI led Domain ), besides , It can also be widely used in advertising traffic 、Web、App Traffic 、 telecom 、 Finance 、 Electronic Commerce 、 Information security 、 Network game 、 Internet of things and many other fields Domain .
1.9 ClickHouse Scenarios that are not applicable
Should not be used for any OLTP Scenarios for transactional operations , reason :
- Unsupported transaction .
- Not good at querying by row granularity .
- Not good at deleting data by line .
1.10 Who is using ClickHouse
Reference resources ClickHouse Case introduction on the official website (https://clickhouse.yandex/ ).
1.11 Summary of this chapter
stay BI The thinking in the process of the system from tradition to modern .
ck Development history of .
The first 2 Chapter ClickHouse Architecture Overview
And Hadoop Other numbers of Ecology According to the library ,ClickHouse It's more like a “ Tradition ”MPP Architecture database , It didn't pick use Hadoop The master-slave architecture commonly used in Ecology , Instead, it uses a multi master peer-to-peer network structure , Same as It is also based on the relational model ROLAP programme .
2.1 ClickHouse The core feature of
ClickHouse Is a MPP Architecture column storage database .
2.1.1 complete DBMS function
ck It can be called a DBMS(Database Management System, Database management system ).
It has some basic functions :
- DDL( Data definition language ): You can create... Dynamically 、 Modify or delete a database 、 Tables and views , Without having to restart the service .
- DML( Data operation language ): It can be queried dynamically 、 Insert 、 Modify or delete data .
- Access control : You can set the operation authority of database or table according to user granularity , Secure data .
- Data backup and recovery : Provides data backup export and import recovery mechanism , Satisfy Requirements of production environment .
- Distributed management : Provide cluster mode , Can automatically manage multiple database nodes .
2.1.2 Column storage and data compression
Make queries faster , The simplest and most effective way is to reduce the data scanning range and the size of data transmission .
Advantages of columnar storage :
- Effectively reduce the amount of data to be scanned during query . If you only need some column data , Columnar storage can directly return data ; Row storage needs to obtain the whole row of data and then filter .
- More friendly to data compression . The essence of compression is to scan the data according to a certain step size , When the duplicate part is found, the code is converted . So the more repetitions , The better the compression , The smaller the package , The faster the transmission .
2.1.3 Vectorization execution engine
Vectorization is a feature of register hardware .
Need to use CPU Of SIMD(Single Instruction Multiple Data) Instructions . That is to operate multiple data with a single instruction .
It is an implementation way to improve performance through data parallelism ( Others are instruction level parallelism and thread level parallelism ), Its principle is CPU Parallel operation of data is realized at register level .
Storage media distance CPU Closer , The faster you access the data . On the contrary, the slower .

So the use of CPU Features of vectorization execution sex , It is very important to improve the performance of the program .
ClickHouse At present, we use SSE4.2 Instruction sets implement vectorized execution .
2.1.4 Relationship model and SQL Inquire about
ClickHouse Use a relational model to describe Describe the data and provide the concept of traditional database ( database 、 surface 、 Views and functions, etc ). Therefore, systems based on traditional relational databases or data warehouses are migrated to ClickHouse The cost will be lower .
stay SQL In terms of analysis ,ClickHouse Case sensitive , It means SELECT a and SELECT A The semantic meaning is different .
2.1.5 A variety of table engines
And MySQL similar ,ClickHouse It also abstracts the storage part , Take the storage engine as a layer independent interface . Support specific scenarios through specific table engines , Very flexible .
2.1.6 Multithreading and distributed
Multithreading is to improve the performance through thread level parallelism .
because SIMD It is not suitable for scenarios with more branch judgments ,ClickHouse It also uses multithreading technology to speed up , This is complementary to vectorized execution .
In the distributed world , There is a golden rule —— Computational mobility is more cost-effective than data mobility . Between servers , The cost of transmitting data over the network is high , Push the calculation query of data directly to data The server is more suitable .
ClickHouse In terms of data access , Both support partition ( Vertical expansion , Using the principle of multithreading ), It also supports fragmentation ( Horizontal scaling , Using the distributed principle ), It can be said that the multi-threaded and distributed technology is applied to the extreme .
2.1.7 Multi master architecture
ClickHouse Then Multi-Master Multi master architecture , Each node in the cluster has equal roles , The client can get the same effect when visiting any node . The advantage is that the system architecture is simpler , It can avoid single point of failure .
More suitable for multiple data centers , Different live .
2.1.8 Online query
In the scenario of complex query , It can also be extremely responsive , And there is no need for any preprocessing of the data .
2.1.9 Data fragmentation and distributed query
Data slicing is to slice data horizontally , Using the idea of divide and conquer .
ck Each cluster consists of 1 To a number of pieces , And each slice corresponds to ClickHouse Of 1 Service nodes .
ClickHouse Local tables are provided (Local Table) And distributed tables (Distributed Table) The concept of .
A local table is equivalent to a piece of data . The distributed table itself does not store any data , It is the access agent for the local table , Its role is similar to the role of the database middleware . With the help of distributed tables , Can proxy access to multiple pieces of data , So as to realize distributed query .
Sub database and sub table of similar database , Very flexible .
2.2 ClickHouse Architecture design
2.2.1 Column And Field
Column and Field yes ClickHouse The most basic mapping unit of data .
First say Column
stay IColumn Interface object , This paper defines the methods of various relational operations on data .
【 The interface is defined in the source code /src/Columns/IColumn.h in 】

It defines the methods of performing various relational operations on data , For example, insert data insertRangeFrom and insertFrom Method 、 For pagination cut, With And for filtering filter Such method .

The specific implementation objects of these methods are based on the data Different types , Implemented by the corresponding object , for example ColumnString、ColumnArray and ColumnTuple etc. .
Most occasions ,ClickHouse Will operate data as a whole column .
Besides, Field
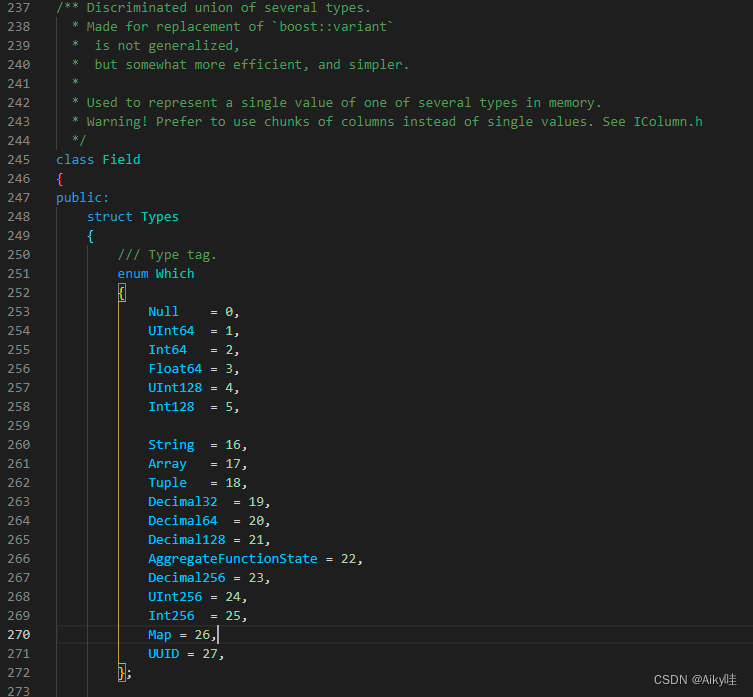
If you need to manipulate a single specific value ( That is, a row of data in a single column ), You need to use Field object ,Field Object represents a single value .
And Column The idea of object generalization design is different ,Field Objects use aggregate design patterns . stay Field Objects are aggregated internally Null、UInt64、String and Array etc. 13 Data types and corresponding processing logic .
【 It's defined in src/Core/Field.h in 】

2.2.2 DataType
【 Now? 21.8 Serialization is not in the version of IDateType 了 , The definition is class ISerialization in , This is not the author's problem , yes ck The updated version is too fast , The introduction in this part of the book has fallen behind the version 】
【IDateType It's defined in src/DataTypes/IDataType.h】

2.2.3 Block And Block flow
ClickHouse Internal data manipulation is oriented to Block Object , And in the form of a stream .
although Column and Filed It is the basic mapping unit of data , But for the actual operation , They also lack the necessary information . Data types and column names .
Block An object can be seen as a subset of a data table . The essence is made up of data objects 、 A triple of data types and column names , namely Column、DataType And column name string .
【 This is actually the same as tidb Of chunk The design is similar , Is a batch of data . It's defined in src/Core/Block.h in 】

Block Flow operations have two sets of top-level interfaces :
- IBlockInputStream Responsible for data reading and relational operations
- 【 It's defined in src/DataStreams/IBlockInputStream.h】
- IBlockOutputStream Responsible for outputting data to the next link
- 【 It's defined in src/DataStreams/IBlockOutputStream.h】
Block Flows also use generalized design patterns , The various operations on the data will eventually be converted into the implementation of one of the streams .IBlockInputStream The interface defines a number of read Virtual method , The concrete implementation logic is filled by its implementation class .
IBlockInputStream The interface covers ClickHouse All aspects of data intake . These implementation classes can be roughly divided into three categories :
- The first is used to process data definitions DDL operation , for example DDLQueryStatusInputStream etc. ;
- The second type is used to deal with relational operations , for example LimitBlockInputStream、JoinBlockInputStream And AggregatingBlockInputStream etc. ;
- The third is to echo the table engine , Each table engine has a corresponding BlockInputStream Realization , for example MergeTreeBaseSelectBlockInputStream(MergeTree Watch engine )、 TinyLogBlockInputStream(TinyLog Watch engine ) And KafkaBlockInputStream(Kafka Watch engine ) etc. .
IBlockOutputStream Design and IBlockInputStream cut from the same cloth . It is basically used for related processing of table engine , Responsible for writing data to the next link or final destination , for example MergeTreeBlockOutputStream、 TinyLogBlockOutputStream And StorageFileBlock-OutputStream etc. .
2.2.4 Table
There is no such thing as... In the underlying design Table object , It directly uses IStorage Interface refers to the data table .
【 It's defined in src/Storages/IStorage.h】

Different table engines are implemented by different subclasses , for example IStorageSystemOneBlock( The system tables )、StorageMergeTree( Merge tree table engine ) and StorageTinyLog( Log table engine ) etc. .
IStorage Interface defined DDL( Such as ALTER、RENAME、OPTIMIZE and DROP etc. )、read and write Method , They are responsible for the definition of data 、 Query and write . In data query ,IStorage Be responsible for according to AST The instruction requirements of the query statement , Returns the original data of the specified column .
Further processing of the data 、 Computing and filtering , It will be handed over to Interpreter Interpreter object processing .
2.2.5 Parser And Interpreter
Parser The parser is responsible for creating AST object .
【Parser It's defined in src/Parsers/IParser.h】

Interpreter The interpreter is responsible for explaining AST, And further create the query execution pipeline .
【Interpreter It's defined in src/Interpreters/IInterpreter.h】

They are associated with IStorage Together , The whole data query process is concatenated .
Different SQL sentence , Through different Parser Implement class parsing . for example , It's responsible for parsing DDL Query statement ParserRenameQuery、ParserDropQuery and ParserAlterQuery Parser , There are also people who are responsible for parsing INSERT Of the statement ParserInsertQuery Parser , And responsible for SELECT Of the statement ParserSelectQuery etc. .
Interpreter The interpreter works like Service The service layer is the same , Play a series integral The role of a query process , It depends on the type of interpreter , Aggregate the resources it needs . First, it will parse AST object ; And then execute “ Business logic ”( For example, branch judgment 、 Set up Parameters 、 Call interface, etc ); Eventually return IBlock object , Set up a in the form of thread Query execution pipeline .
【 It's easy to understand ,sql The execution process of must first be parsed into ast The parse tree , According to ast Parse tree generation execution plan .Parser And Interpreter That's what it's for .】
2.2.6 Functions And Aggregate Functions
ck Provide common functions and aggregate functions .
Ordinary functions are defined by IFunction Interface definition , There are dozens of function implementations , for example FunctionFormatDateTime、FunctionSubstring etc. . In the process of function execution , It doesn't work line by line , Instead, it uses vectorization to directly act on a whole column of data .
【IFunction Interface defined in src/Functions/IFunction.h, But according to the code comments , This interface is obsolete .】

Aggregate functions are defined by IAggregateFunction Interface definition , Compared to ordinary functions without state , Aggregate functions are stateful . With COUNT For example, aggregate functions , Its AggregateFunctionCount The state of the is used as an integer UInt64 Record .
The state of aggregate functions supports serialization and deserialization , So it can be transmitted between distributed nodes , To achieve incremental computing .
【 I don't quite understand what the author means by this state , I personally understand that it should be the intermediate result of the aggregation process , That's what the notes say .IAggregateFunction Interface defined in src/AggregateFunctions/IAggregateFunction.h】

2.2.7 Cluster And Replication
ClickHouse The cluster is divided into several parts (Shard) form , And each piece goes through a copy (Replica) form .
【ck The fragmentation of is a logical concept , Replica is a physical concept , It's easy to get confused here .】
ck The characteristics of clustering :
- ClickHouse Of 1 Nodes can only have 1 A shard , That is to say, if we want to achieve it 1 Fragmentation 、1 copy , You need to deploy at least 2 Service nodes .
- Fragmentation is just a logical concept , Its physical bearing is still borne by the replica .
for instance , Single slice and single copy configuration :

Single slice and two copies configuration :

2.3 ClickHouse Why so fast
When designing software architecture , The principle of design should be to design from top to bottom , Or should we design from the bottom up ? In the traditional sense , Or in my opinion , Nature is top-down design , We're usually taught to do top-level design .
and ClickHouse The bottom-up approach is adopted in the design of the .
2.3.1 Look at the hardware , Think before you do
For the purpose of maximizing the power of hardware , ClickHouse It will be done in memory GROUP BY, And use HashTable Loading data . At the same time, I am very concerned about CPU L3 Level cache .
Because once L3 Cache failure of Will bring 70~100ns Delay of . That means in a single core CPU On , It wastes 4000 Ten thousand times / Second operation ; But in a 32 Thread CPU On , It may be wasted 5 100 million times / Second operation .
Pay attention to these details , therefore ClickHouse It can be done in benchmark query 1.75 100 million times / Second data scanning performance .
2.3.2 The algorithm comes first , Abstract after
Take strings for example , There is a book dedicated to string search , be known as “Handbook of Exact String Matching Algorithms”, List 35 A common string search algorithm .
Guess ClickHouse Which one of them was used ? The answer is none of them . Why is that ? Because the performance is not fast enough . In terms of string search , For different scenes , ClickHouse Finally, these algorithms are selected : For constants , Use Volnitsky Algorithm ; For a very large amount of , Use CPU The vectorization execution of SIMD, Violence optimization ; Regular matching uses re2 and hyperscan Algorithm . Performance is the primary consideration of algorithm selection .
【 This is an awkward place , Do you compare people with pure violence , How can performance be faster than suffix automata and so on , I think it is to cater to liecun , The operation can do simd, It's definitely not that the algorithm in people's letters is bad 】
2.3.3 Have the courage to taste , If you can't, change it
If there is a new algorithm with powerful performance in the world , ClickHouse The team will immediately incorporate it and validate it .
If the effect is good , Just keep it ; If the performance is unsatisfactory , Just throw it away .
2.3.4 Specific scenario , Special optimization
【 There's nothing to remember 】
2.3.5 Keep testing , Continuous improvement
【 There's nothing to remember 】
2.4 Summary of this chapter
Exhibition ck Core features .
Show me more ck The bottom design idea .
边栏推荐
- 对多态的理解
- To the Sultanate of Anderson
- Personal developed penetration testing tool Satania
- 测试勋章1234
- SQL Server 提取字符串中的纯数字
- 代码改变一小步,思维跨越一大步
- How can I get the stock account opening discount link? In addition, is it safe to open a mobile account?
- 我想知道股票开户要认识谁?另外,手机开户安全么?
- 针对美国国家安全局“酸狐狸”漏洞攻击武器平台的分析与应对方案建议
- uniapp-富文本编辑器
猜你喜欢










随机推荐
测试媒资缓存问题
Et la dégradation du modèle de génération de texte? Simctg vous donne la réponse
加密与解密以及OpenSSL的应用
ArcGIS构建发布简单路网Network数据服务及Rest调用测试
uniapp怎么上传二进制图片
FreeRTOS记录(九、一个裸机工程转FreeRTOS的实例)
[grade evaluator] how to register a grade evaluator? How many passes?
Radar data processing technology
将博客搬至CSDN
Adobe Photoshop (PS) - script development - remove file bloated script
ncat详细介绍(转载)
stacking集成模型预测回归问题
多态在代码中的体现
一文读懂什么是MySQL索引下推(ICP)
twelve thousand three hundred and forty-five
docker安装mysql
数字货币:影响深远的创新
Electronic scheme development - Intelligent rope skipping scheme
ceshi deces
Adobe-Photoshop(PS)-脚本开发-去除文件臃肿脚本