当前位置:网站首页>《ClickHouse原理解析与应用实践》读书笔记(3)
《ClickHouse原理解析与应用实践》读书笔记(3)
2022-06-30 21:10:00 【Aiky哇】
开始学习《ClickHouse原理解析与应用实践》,写博客作读书笔记。
本文全部内容都来自于书中内容,个人提炼。

第5章 数据字典
数据字典是一种存储媒介,以键值和属性映射的形式定义数据。适合保存常量或经常使用的维度表数据。
字典中的数据会主动或者被动(参数控制)加载到内存,支持动态更新。
数据字典分为内置与扩展两种形式,内置字典是ck自带的,外部扩展字典是用户通过配置定义的。
正常情况下,字典中的数据只能通过字典函数访问。例外是字典表引擎。
5.1 内置字典
ck只是提供字典的定义机制和取数函数。没有内置任何现成的数据。
5.1.1 内置字典配置说明
内置字典在默认的情况下是禁用状态,需要开启后才能使用。
将config.xml文件中path_to_regions_hierarchy_file和 path_to_regions_names_files两项配置打开就可以开启内置字典。
【现在官网都没有提供这两个参数的说明,但是代码中是饱含着两个值的。我认为是没什么必要看的,内置字典也默认禁止,大多场景应该使用的是外部字典。参考Internal Dictionaries | ClickHouse Docs】
5.1.2 使用内置字典
用到了 regionToName函数。类似这样的函数还有很多,在ClickHouse中它们被称为Yandex.Metrica函数。关于这套函数的更多用法,请参阅官方手册。
5.2 外部扩展字典
是以插件形式注册到ClickHouse中。
支持7种类型的内存布局和4类数据来源。更加常用。
参考External Dictionaries | ClickHouse Docs
5.2.1 准备字典数据
事先准备了三份测试数据,它们均使用CSV格式。用于演示。
# 企业组织数据
# flat、hashed、cache、complex_key_hashed和complex_key_cache字典的演示
# 三个字段 id、code和name
#-----------------------------------------------
1,"a0001","研发部"
2,"a0002","产品部"
3,"a0003","数据部"
4,"a0004","测试部"
5,"a0005","运维部"
6,"a0006","规划部"
7,"a0007","市场部"
#-----------------------------------------------
# 销售数据
# 用于range_hashed字典的演示
# 四个字段id、start、end和price
#-----------------------------------------------
1,2016-01-01,2017-01-10,100
2,2016-05-01,2017-07-01,200
3,2014-03-05,2018-01-20,300
4,2018-08-01,2019-10-01,400
5,2017-03-01,2017-06-01,500
6,2017-04-09,2018-05-30,600
7,2018-06-01,2019-01-25,700
8,2019-08-01,2019-12-12,800
#-----------------------------------------------
# asn数据
# 用于ip_trie字典的演示
# 三个字段ip、asn和country
#-----------------------------------------------
"82.118.230.0/24","AS42831","GB"
"148.163.0.0/17","AS53755","US"
"178.93.0.0/18","AS6849","UA"
"200.69.95.0/24","AS262186","CO"
"154.9.160.0/20","AS174","US"
#----------------------------------------------- 
5.2.2 扩展字典配置文件的元素组成
扩展字典的配置文件由config.xml文件中的dictionaries_config 配置项指定:
<!-- Configuration of external dictionaries. See:
https://clickhouse.yandex/docs/en/dicts/external_dicts/
-->
<dictionaries_config>*_dictionary.xml</dictionaries_config>Server Settings | ClickHouse Docs
在默认的情况下,ck会自动识别并加载/etc/clickhouse-server目录下所有以_dictionary.xml结尾的配置文件。
同时ck支持热加载更新配置文件。
单个字典配置文件内可以定义多个字典。
每一个字典由一 组dictionary元素定义。在dictionary元素之下又分为5个子元素,均为必填项,它们完整的配置结构如下所示:
<?xml version="1.0"?>
<dictionaries>
<dictionary>
<name>dict_name</name>
<structure>
<!—字典的数据结构 -->
</structure>
<layout>
<!—在内存中的数据格式类型 -->
</layout>
<source>
<!—数据源配置 -->
</source>
<lifetime>
<!—字典的自动更新频率 -->
</lifetime>
</dictionary>
</dictionaries>主要配置的含义:
- name:字典的名称,用于确定字典的唯一标识,必须全局唯 一,多个字典之间不允许重复。
- structure:字典的数据结构,5.2.3节会详细介绍。
- layout:字典的类型,它决定了数据在内存中以何种结构组织 和存储。目前扩展字典共拥有7种类型,5.2.4节会详细介绍。
- source:字典的数据源,它决定了字典中数据从何处加载。目 前扩展字典共拥有文件、数据库和其他三类数据来源,5.2.5节会详细 介绍。
- lifetime:字典的更新时间,扩展字典支持数据在线更新, 5.2.6节会详细介绍。
5.2.3 扩展字典的数据结构
数据结构由structure元素定义。
由键值key和属性 attribute两部分组成,分别描述字典的数据标识和字段属性。
<dictionary>
<structure>
<!— <id> 或 <key> -->
<id>
<!—Key属性-->
</id>
<attribute>
<!—字段属性-->
</attribute>
...
</structure>
</dictionary>对于key。
key用于定义字典的键值,每个字典必须包含1个键值key字段,用于定位数据,类似数据库的表主键。
键值key分为数值型和复合型两类。
数值型:数值型key由UInt64整型定义,支持flat、 hashed、range_hashed和cache类型的字典(扩展字典类型会在后面介绍)
<structure>
<id>
<!—名称自定义-->
<name>Id</name>
</id>
省略…复合型:复合型key使用Tuple元组定义,可以由1到多个字段组成,类似数据库中的复合主键。它仅支持complex_key_hashed、 complex_key_cache和ip_trie类型的字典。
<structure>
<key>
<attribute>
<name>field1</name>
<type>String</type>
</attribute>
<attribute>
<name>field2</name>
<type>UInt64</type>
</attribute>
省略…
</key>
省略…
对于attribute。
attribute用于定义字典的属性字段,字典可以拥有1到多个属性字段。
<structure>
省略…
<attribute>
<name>Name</name>
<type>DataType</type>
<!—空字符串-->
<null_value></null_value>
<expression>generateUUIDv4()</expression>
<hierarchical>true</hierarchical>
<injective>true</injective>
<is_object_id>true</is_object_id>
</attribute>
省略…
</structure>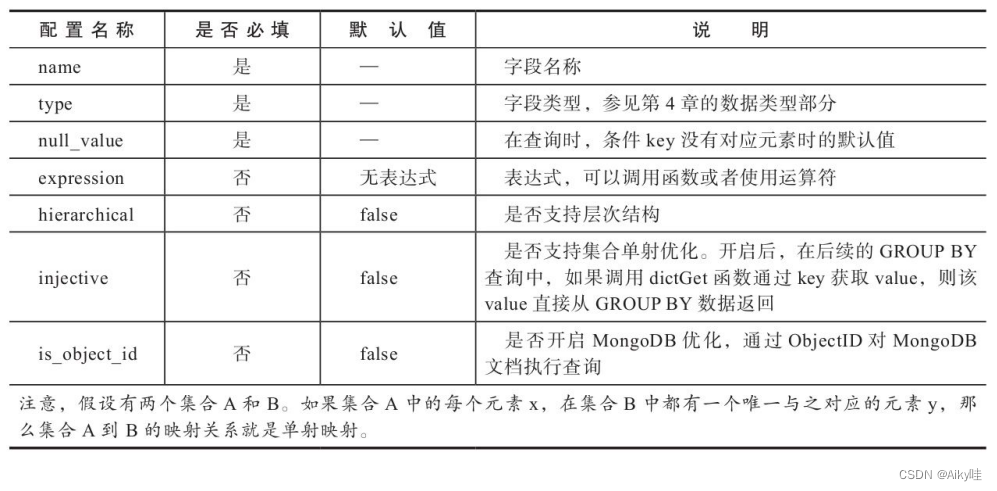
5.2.4 扩展字典的类型
layout元素决定了其数据在内存中的存储结构,也决定了该字典支持的key键类型。
使用layout元素定义,目前共有7种类型。
单数值key类型,使用单个数值型的id:
- flat
- hashed
- range_hashed
- cache
复合key类型:
- complex_key_hashed
- complex_key_cache
- ip_trie
flat类型字典
flat字典是所有类型中性能最高的字典类型。只能使用UInt64数值型 key。
在内存中使用数组结构保存。初始大小为1024,上限为500 000,超出上限,字典创建失败。
在/etc/clickhouse-server下创建flat_dictionary.xml文件:
<?xml version="1.0"?>
<dictionaries>
<dictionary>
<name>test_flat_dict</name>
<source>
<!-- 准备好的测试数据 -->
<file>
<path>/data/clickhouse/dictionaries/organization.csv</path>
<format>CSV</format>
</file>
</source>
<layout>
<flat/>
</layout>
<!-- 与测试数据的结构对应 -->
<structure>
<id>
<name>id</name>
</id>
<attribute>
<name>code</name>
<type>String</type>
<null_value/>
</attribute>
<attribute>
<name>name</name>
<type>String</type>
<null_value/>
</attribute>
</structure>
<lifetime>
<min>300</min>
<max>360</max>
</lifetime>
</dictionary>
</dictionaries>ck会自动识别配置变化,这时数据字典就已经创建好了。
系统表中查看:
SELECT name, type, key, attribute.names, attribute.types FROM system.dictionaries
hashed类型字典
也只能用UInt64数值型key。
和flat不同点:数据在内存中通过散列结构保存。没有存储上限。
复制一份上面的配置文件,改一下name和layout。
<name>test_hashed_dict</name>
<layout>
<hashed/>
</layout>
range_hashed类型字典
hashed字典的变种。
增加了指定时间区间的特性。数据散列结构存储并按照时间排序。
时间区间通过range_min和range_max元素指定,所指定的字段必须是 Date 或者 DateTime类型。
<?xml version="1.0"?>
<dictionaries>
<dictionary>
<name>test_range_hashed_dict</name>
<source>
<!-- 准备好的测试数据 -->
<file>
<path>/data/clickhouse/dictionaries/sales.csv</path>
<format>CSV</format>
</file>
</source>
<layout>
<range_hashed/>
</layout>
<!-- 与测试数据的结构对应 -->
<structure>
<id>
<name>id</name>
</id>
<range_min>
<name>start</name>
</range_min>
<range_max>
<name>end</name>
</range_max>
<attribute>
<name>price</name>
<type>Float32</type>
<null_value/>
</attribute>
</structure>
<lifetime>
<min>300</min>
<max>360</max>
</lifetime>
</dictionary>
</dictionaries>
cache类型字典
只能用UInt64数值型key。
内存中数据使用固定长度的向量数组保存。
定长的向量数组又称cells,它的数组长度由 size_in_cells (2的倍数,向上取整)指定。
不会一次性将所有数据载入内存。会在cells数组中检查该数据是否已被缓存。如果数据没有被缓存,它才会从源头加载数据并缓存到cells中。
性能优劣完全取决于缓存的命中率(缓存命中率=命中次数/查询次数),如果无法做到 99%或者更高的缓存命中率,则最好不要使用此类型。
<?xml version="1.0"?>
<dictionaries>
<dictionary>
<name>test_cache_dict</name>
<source>
<!-- 本地文件需要通过 executable形式 -->
<executable>
<command>cat /data/clickhouse/dictionaries/organization.csv</command>
<format>CSV</format>
</executable>
</source>
<layout>
<cache>
<!-- 缓存大小 -->
<size_in_cells>10000</size_in_cells>
</cache>
</layout>
<structure>
<id>
<name>id</name>
</id>
<attribute>
<name>code</name>
<type>String</type>
<null_value/>
</attribute>
<attribute>
<name>name</name>
<type>String</type>
<null_value/>
</attribute>
</structure>
<lifetime>
<min>300</min>
<max>360</max>
</lifetime>
</dictionary>
</dictionaries>
如果cache字典使用本地文件作为数据源,则必须使用executable的形式设置。
complex_key_hashed类型字典
功能方面与hashed字典完全相同。只是将单个数值型key替换成了复合型。
<?xml version="1.0"?>
<dictionaries>
<dictionary>
<name>test_complex_key_hashed_dict</name>
<source>
<file>
<path>/data/clickhouse/dictionaries/organization.csv</path>
<format>CSV</format>
</file>
</source>
<layout>
<complex_key_hashed/>
</layout>
<structure>
<!-- 复合型key -->
<key>
<attribute>
<name>id</name>
<type>UInt64</type>
</attribute>
<attribute>
<name>code</name>
<type>String</type>
</attribute>
</key>
<attribute>
<name>name</name>
<type>String</type>
<null_value/>
</attribute>
</structure>
<lifetime>
<min>300</min>
<max>360</max>
</lifetime>
</dictionary>
</dictionaries>
complex_key_cache类型字典
与cache字典的特性完全相同,只是将单个 数值型key替换成了复合型。
<?xml version="1.0"?>
<dictionaries>
<dictionary>
<name>test_complex_key_cache_dict</name>
<source>
<executable>
<command>cat /data/clickhouse/dictionaries/organization.csv</command>
<format>CSV</format>
</executable>
</source>
<layout>
<complex_key_cache>
<size_in_cells>10000</size_in_cells>
</complex_key_cache>
</layout>
<structure>
<!-- 复合型Key -->
<key>
<attribute>
<name>id</name>
<type>UInt64</type>
</attribute>
<attribute>
<name>code</name>
<type>String</type>
</attribute>
</key>
<attribute>
<name>name</name>
<type>String</type>
<null_value/>
</attribute>
</structure>
<lifetime>
<min>300</min>
<max>360</max>
</lifetime>
</dictionary>
</dictionaries>
ip_trie类型字典
复合型key,只能指定单个String类型的字段,指代IP前缀。
数据在内存中使用trie树结构保存。专门用于IP前缀查询的场景。
<?xml version="1.0"?>
<dictionaries>
<dictionary>
<name>test_ip_trie_dict</name>
<source>
<file>
<path>/data/clickhouse/dictionaries/asn.csv</path>
<format>CSV</format>
</file>
</source>
<layout>
<ip_trie/>
</layout>
<structure>
<!-- 虽然是复合类型,但是只能设置单个String类型的字段 -->
<key>
<attribute>
<name>prefix</name>
<type>String</type>
</attribute>
</key>
<attribute>
<name>asn</name>
<type>String</type>
<null_value/>
</attribute>
<attribute>
<name>country</name>
<type>String</type>
<null_value/>
</attribute>
</structure>
<lifetime>
<min>300</min>
<max>360</max>
</lifetime>
</dictionary>
</dictionaries>

在这些字典中,flat、hashed和range_hashed依次拥有最高的性能,而cache性能最不稳定。

5.2.5 扩展字典的数据源
数据源使用source元素定义。扩展字典支持3大类共计9种数据源。
本地文件类:
# 本地文件
<source>
<file>
<path>/data/dictionaries/organization.csv</path>
<format>CSV</format>
</file>
</source>
# 可执行文件
<source>
<executable>
<command>cat /data/dictionaries/organization.csv</ command>
<format>CSV</format>
</executable>
</source>
# 远程文件
<source>
<http>
<url>http://10.37.129.6/organization.csv</url>
<format>CSV</format>
</http>
</source>
数据库类:
更适合在正式的生产环境。
# mysql类型
<source>
<mysql>
<port>3306</port> 数据库端口
<user>root</user> 数据库用户名
<password></password> 数据库密码
<replica> 数据库host地址,支持MySQL集群
<host>10.37.129.2</host>
<priority>1</priority>
</replica>
<db>test</db> database数据库
<table>t_organization</table> 字典对应的数据表
<!--
<where>id=1</where> 查询table时的过滤条件,非必填项。
<invalidate_query>SQL_QUERY</invalidate_query> 指定一条SQL语句,用于在数据更新时判断是否需要更新,非必填项。
-->
</mysql>
</source>
# Clickhouse类型
<source>
<clickhouse>
<host>10.37.129.6</host>
<port>9000</port>
<user>default</user>
<password></password>
<db>default</db>
<table>t_organization</table>
<!--
<where>id=1</where>
<invalidate_query>SQL_QUERY</invalidate_query>
-->
</clickhouse>
</source>
# MongoDB类型
<source>
<mongodb>
<host>10.37.129.2</host>
<port>27017</port>
<user></user>
<password></password>
<db>test</db>
<collection>t_organization</collection> 与字典对应的collection的名称。
</mongodb>
</source>其他类型
扩展字典还支持通过ODBC的方式连接PostgreSQL和MS SQL Server数据库作为数据源。
5.2.6 扩展字典的数据更新策略
扩展字典支持数据的在线更新,更新后无须重启服务。
字典数据的更新频率由配置文件中的lifetime元素指定,单位为秒:
<lifetime>
<min>300</min>
<max>360</max>
</lifetime>min与max分别指定了更新间隔的上下限。
ck会在这个时间段随机触发更新动作,可以有效错开更新时间。
当min和max都是0的时候,将禁用字典更新。
在数据更新的过程中,旧版本的字典将持续提供服务, 只有当更新完全成功之后,新版本的字典才会替代旧版本。
ClickHouse的后台进程每隔5秒便会启动一次数据刷新的判断。
不同的数据源有不同的实现逻辑。
文件数据源
它的previous值来自系统文件的修改时间,当前后两次previous的值不相同时,才会触发数据更新。
MySQL(InnoDB)、ClickHouse和ODBC
previous值来源于 invalidate_query中定义的SQL语句。
例如在下面的示例中,如果前后两次的 updatetime 值不相同,则会判定源数据发生了变化,字典需要更新。
<source>
<mysql> 省略…
<invalidate_query>select updatetime from t_organization where id = 8</invalidate_query>
</mysql>
</source>这对源表有一定的要求,它必须拥有一个支持判断数据是否更新的字段。
MySQL(MyISAM)
在 MySQL 中,使用MyISAM表引擎的数据表支持通过SHOW TABLE STATUS命令查询修改时间。
SHOW TABLE STATUS WHERE Name = 't_organization'
其他数据源
目前无法依照标识判断是否跳过更新。
无论数据是否发生实质性更改,只要满足当前lifetime的时间要求,它们都会执行更新动作。
所以更新效率更低。
数据字典也能够主动触发更新。
SYSTEM RELOAD DICTIONARIES
SYSTEM RELOAD DICTIONARY [dict_name]5.2.7 扩展字典的基本操作
元数据查询
通过system.dictionaries系统表。
- name:字典的名称,在使用字典函数时需要通过字典名称访问数据。
- type:字典所属类型。
- key:字典的key值,数据通过key值定位。
- attribute.names:属性名称,以数组形式保存。
- attribute.types:属性类型,以数组形式保存,其顺序与attribute.names 相同。
- bytes_allocated:已载入数据在内存中占用的字节数。
- query_count:字典被查询的次数。
- hit_rate:字典数据查询的命中率。
- element_count:已载入数据的行数。
- load_factor:数据的加载率。
- source:数据源信息。
- last_exception:异常信息,需要重点关注。如果字典在加载过程中产生异常,那么异常信息会写入此字段。last_exception是获取字典调试信息的主要方式。
数据查询
正常情况下,字典数据只能通过字典函数获取。
-- dictGet('dict_name','attr_name',key)
SELECT dictGet('test_flat_dict','name',toUInt64(1))
SELECT dictGet('test_ip_trie_dict', 'asn', tuple(IPv4StringToNum('82.118.230.0')))dictGet为前缀的字典函数:
- 获取整型数据的函数:dictGetUInt8、dictGetUInt16、dictGetUInt32、 dictGetUInt64、dictGetInt8、dictGetInt16、dictGetInt32、dictGetInt64。
- 获取浮点数据的函数:dictGetFloat32、dictGetFloat64。
- 获取日期数据的函数:dictGetDate、dictGetDateTime。
- 获取字符串数据的函数:dictGetString、dictGetUUID。
字典表
字典表是使用Dictionary表引擎的数据表。
CREATE TABLE tb_test_flat_dict (
id UInt64,
code String,
name String
) ENGINE = Dictionary(test_flat_dict);使用DDL查询创建字典
从19.17.4.11版本开始,ClickHouse开始支持使用DDL查询创建字典
CREATE DICTIONARY test_dict(
id UInt64,
value String
)
PRIMARY KEY id
LAYOUT(FLAT())
SOURCE(FILE(PATH '/usr/bin/cat' FORMAT TabSeparated))
LIFETIME(1)
5.3 本章小结
数据字典的配置、更新和查询的基本操作。
在扩展字典方面,目前拥有7种类型。
数据字典能够有效地帮助我们消除不必要的JOIN操作(例如根据ID转名称),优化 SQL查询,为查询性能带来质的提升。
下一章将开始介绍MergeTree表引擎的核心原理。
【终于啊,大菜来了】
边栏推荐
- Iclr'22 spotlight | how to measure the amount of information in neural network weights?
- MySQL batch update
- 文本生成模型退化怎么办?SimCTG 告诉你答案
- Personal developed penetration testing tool Satania
- 毕业五年,想当初若没有入行测试,我是否还会如这般焦虑
- Software engineering UML drawing
- ArcGIS构建发布简单路网Network数据服务及Rest调用测试
- Binary search tree (1) - concept and C language implementation
- On the charm of code language
- Metauniverse may become a new direction of Internet development
猜你喜欢

Label Contrastive Coding based Graph Neural Network for Graph Classification

开源实习经验分享:openEuler软件包加固测试
On the charm of code language

报错:Internal error XFS_WANT_CORRUPTED_GOTO at line 1635 of file fs/xfs/libxfs/xfs_alloc.c.

Double solid histogram / double y-axis

修改已经上线的小程序名称

uniapp-富文本编辑器

asp.net core JWT传递

centos——开启/关闭oracle

DM8:生成DM AWR报告
随机推荐
The 16th Heilongjiang Provincial Collegiate Programming Contest
凤凰架构——架构师的视角
升级kube出现unknown flag: --network-plugin
防范未授权访问攻击的十项安全措施
两个skyline
ca i啊几次哦啊句iu家哦11111
. NETCORE redis geo type
Upgrade Kube with unknown flag: --network plugin
.netcore redis GEO类型
Metauniverse may become a new direction of Internet development
Radar data processing technology
判断js对象是否为空的方式
开源实习经验分享:openEuler软件包加固测试
SQL Server 提取字符串中的纯数字
文本生成模型退化怎么办?SimCTG 告诉你答案
Label Contrastive Coding based Graph Neural Network for Graph Classification
Internet of things botnet gafgyt family and backdoor vulnerability exploitation of Internet of things devices
Peking University ACM problems 1001:exposition
物联网僵尸网络Gafgyt家族与物联网设备后门漏洞利用
vncserver: Failed command ‘/etc/X11/Xvnc-session‘: 256!