当前位置:网站首页>文本生成模型退化怎么办?SimCTG 告诉你答案
文本生成模型退化怎么办?SimCTG 告诉你答案
2022-06-30 20:49:00 【智源社区】
本文主要聊聊文本生成模型退化的解决方向~
写在前面
开放式文本生成技术是各种自然语言应用(如故事生成、对话系统)中不可或缺的组成部分,其目标是根据给定语境创作一段连贯的文本。然而,基于 MLE 训练的语言模型往往面临退化问题,即随着生成文本长度的增加其质量会逐渐降低,容易出现多种层次(字、短语、句子级)的重复生成。
《A Contrastive Framework for Neural Text Generation》这篇论文中提出一种SimCTG 方法(a simple contrastive framework for neural text generation),通过抑制模型生成不自然且包含不必要重复的文本,从而缓解文本生成模型的退化问题。实验结果显示,SimCTG在所有对比基线模型中有着最好的文本生成性能,且在不同语言、不同的文本生成任务上具有通用性。
论文标题
A Contrastive Framework for Neural Text Generation
论文作者
Yixuan Su, Tian Lan, Yan Wang, Dani Yogatama, Lingpeng Kong, Nigel Collier
论文单位
剑桥大学语言技术实验室等
论文链接
https://arxiv.org/abs/2202.06417
研究背景与动机
重复生成是长文本生成中很常见的现象,如果你熟悉 huggingface 的话,你应该了解 huggingface 提供了一些“土办法”来解决重复生成问题,比如 no_repeat_ngram_size 和 repetition_penalty。它们并没有改变模型,而是基于规则直接修改模型计算的置信度(这也是为什么称之为“土办法”),虽然能减少重复,但会对文本的流畅度和语义有比较大的影响。
学术界中缓解退化问题目前主要有两种方法:一种方法是随机采样,从候选集合中按置信度顺序随机选取一些单词。虽然能减少重复的生成,但采样的方法引入了语义不一致问题,采样的文本往往与人写的前文语义关联性弱,甚至矛盾。另一种方法是通过修改模型的输出单词分布与非似然训练来解决退化问题,但非似然训练往往会导致不流畅的生成。
在这项工作中,作者另辟蹊径,认为神经语言模型的退化源于单词表示的各向异性分布,即它们的表示位于全体表示空间的一个狭窄子集中。

图 1. 解码中单词表示余弦相似度矩阵(a)GPT2 模型(b)SimCTG 模型
图 1 展示了单词表示的余弦相似度矩阵,显而易见,由 GPT-2 产生的单词表示(取自 Transformer 的最后一层)高度相似,这是非常不可取的,意味着这些表示彼此接近,自然地导致模型在不同的步骤中容易生成重复的单词。理想情况下,模型输出的单词表示应遵循各向同性分布,即单词的相似度矩阵是稀疏的,如图 1(b)所示。此外,在解码过程中,应尽可能保持文本的标记相似度矩阵的稀疏性,从而避免模型退化。
基于上述动机,作者提出“对比训练+对比搜索”的方法,鼓励模型学习各向同性的单词表示,避免模型退化。自动评测和人工评测结果表明,SimCTG 在两种语言的三个基准测试集上,达到了最好的性能。
对比训练
上面我们说到,单词表示的各向异性是模型退化的一个重要原因,那么如何改善表示空间,使其具备各向同性的特征呢?一个自然的想法是将单词之间的距离作为优化目标,这样就可以将表示空间中原本稠密分布的单词表示疏解开来,形成一个稀疏的、各向同性的表示空间。
具体来说,作者引入“对比学习”的思想,对于文本中的每一个单词,选取该单词作为锚点和正例,其他单词作为负例,以余弦相似度为距离度量,构建对比学习的三元损失。 对比学习的目标在于拉近锚点和正例的表示距离(由于锚点和正例为同一个单词,具有相同的表示,它们的余弦相似度恒等于 1),拉远锚点和负例的表示距离,这样就可以构造一个具有稀疏分布特性的良好表示空间啦!
对比学习的损失函数如下:
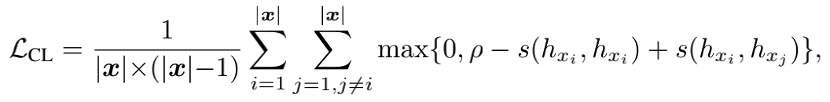
其中,




对比搜索
光有对比训练还不足以保证解码过程中单词表示的稀疏性,那么可不可以强制模型在解码中生成稀疏的单词表示呢?作者在这里设计了一个非常巧妙的方法,核心目标是生成的文本既要流畅性好,又要有信息量(不能车轱辘话反复说)。
如何保证流畅性呢?这就是语言模型的拿手领域了,通常来说,选择模型置信度越高的单词就越流畅。那么怎么才能有信息量呢?生成的每一个单词和前面的单词有足够的区分度就好了。按优先级来讲,肯定是先要保证模型生成流畅,再尽可能地减少重复。于是作者设计了这么一套解码方案:在每个解码步骤中,从模型置信度最高的候选单词集合中进行选择,从而确保生成文本是流畅、可靠的;同时,计算得到的新单词表示要和前文相似度越低越好,从而相对于先前的语境有足够的区分度。这样,生成的文本可以更好地保持与前文的语义一致性,同时避免模型退化。对比搜索解码策略可以通过如下公式表示:

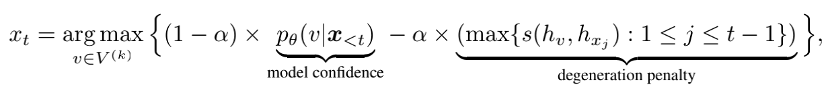
其中

 为模型置信度,
为模型置信度, 为惩罚项,通过计算候选词$v$与前文单词的余弦相似度得到。这一项表明,算法倾向于选择和前文区分度高的单词。
为惩罚项,通过计算候选词$v$与前文单词的余弦相似度得到。这一项表明,算法倾向于选择和前文区分度高的单词。
此外,对比搜索是一种贪婪搜索,其生成的文本具有确定性。 但在实际应用中,我们肯定不希望模型每次都生成一样的结果,完全没有多样性吧?为此,作者还给出一种对比搜索与核采样相结合的策略,先核采样若干步骤,引入多样性,再通过对比搜索获得一个流畅性和信息量俱佳的生成结果!
解码速度方面,由于惩罚项可以通过简单的矩阵乘法实现,并没有引入过多额外计算量,解码效率可以与其他广泛使用的解码算法(beam search 等)相媲美。
实验设置
论文提出的“SimCTG+对比搜索”方法,可以应用于任何文本生成模型,为了测试“SimCTG+对比搜索”在不同任务和语言之间的通用性,作者基于 GPT-2 模型,在文档生成和开放域对话生成任务上进行了评估。
文档生成方面,基于 GPT2-small(12 层,12 个注意力头,117M 参数)模型和 Wikitext-103 数据集进行试验。Wikitext-103 是一个文档级数据集,该数据集包含了大量的维基百科文章,目前已被广泛用于评估大规模语言模型。
评测指标上,采用困惑度、重复度、多样性和语义一致性等自动评测指标和人工评测来评价生成文本质量。开放域对话生成方面,实验采用中文 LCCC 数据集和英文 DailyDialog 数据集,通过人工评测来评价模型的性能。
实验结果与分析
文档生成

表 1 展示了在 Wikitext103 上的文档生成实验结果。首先,在 rep-n 和多样性指标上,SimCTG+对比搜索获得了最好的性能,表明它最好地解决了模型退化问题。其次,“SimCTG+对比搜索”在 MAUVE 上取得了最好的性能,表明其生成的文本在单词分布上最接近人类创作的文本。此外,在所有方法中,只有“SimCTG+对比搜索”的一致性得分超过 0.6,表明它产生了高质量和语义一致的文本。最后,gen-ppl 也验证了“SimCTG+对比搜索”的优越性,它比其他方法获得了明显更好的生成困惑度。
人工评测
文档生成方面,作者从 Wikitext-103 的测试集中随机选择了 200 个长度为 32 的前缀,采用不同的模型 (MLE、非似然和 SimCTG),以及两种解码方法(核采样和对比搜索)来生成长度为 128 的连续文本序列。所有生成结果和参考文本由 5 位评分员评估,共得到 9000 个样本。
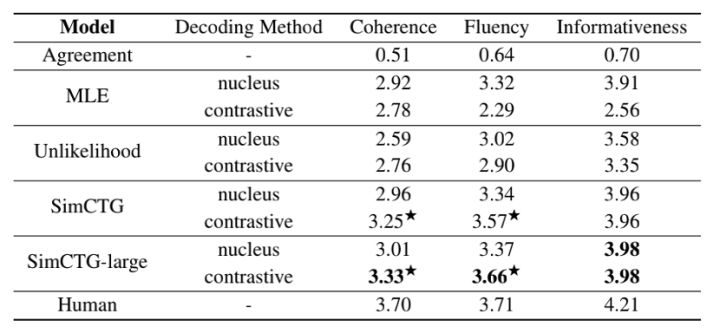
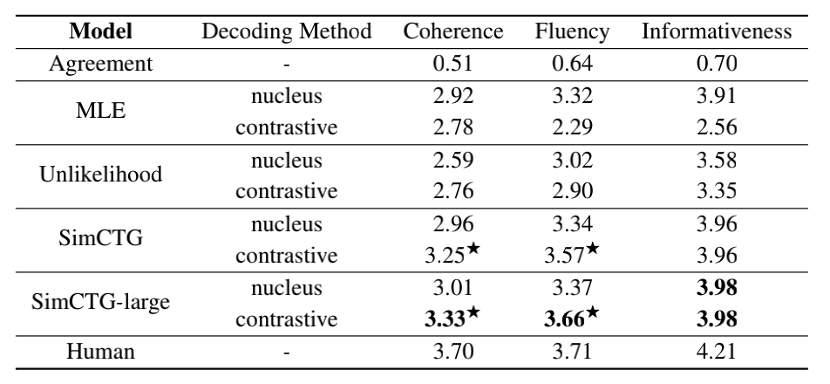
表 2. 人工评测结果
表 2 展示了文档生成的人类评测结果,首先我们可以看到,将对比搜索直接应用于 MLE 或非似然模型并不能产生令人满意的结果,这归咎于上文讨论的表示各向异性问题。其次,非似然方法的一致性得分明显低于 MLE 和 SimCTG,这表明其产生的结果最不可靠(表 1 中的 gen-ppl 得分也证实了这一点)。此外,“SimCTG+对比搜索”在一致性和流畅性方面明显优于其他模型+核采样的方法。最后,“SimCTG-large(基于 GPT-large,36 层,20 个注意力头,774M 参数量)+对比搜索”在所有指标上取得了最佳性能,甚至在流畅性指标上与人类书写的文本表现相当,这也表明“SimCTG+对比搜索”对大尺寸模型也具有通用性。


表 3. 开放域对话生成人工评测结果
表 3 显示了开放域对话生成的人工评估结果,“SimCTG+对比搜索”在各种指标上都明显优于其他方法,表明其可以推广到不同的语言和任务。在 LCCC 基准测试中,“SimCTG+对比搜索”在一致性和信息量上表现地很好,尤其是在流畅性指标上,甚至超过了人类基准!
总结
本文带领大家阅读了论文《A Contrastive Framework for Neural Text Generation》,在这项工作中,作者证明神经语言模型的退化源于单词表示的各向异性性质,并提出了一种新的方法 SimCTG,鼓励模型学习各向同性的表示空间。此外,该论文还提出了一种新的解码方法—对比搜索,确保在解码过程中生成可靠和有区分度的单词表示。自动评测和人工评测的结果均表明,“SimCTG+对比搜索”的方法大大减少了模型退化现象,明显优于当前最先进的文本生成方法。且“SimCTG+对比搜索”是模型结构无关的,可以应用于任何生成式模型;在两种语言,两个任务上的大量实验也表明,其在不同语言和任务上具有通用性。总之,论文通过一种简单有效的方法有效提升了文本生成质量,很推荐大家读一读。
欢迎关注「NLP论文领读」专栏!关注「澜舟科技」公众号,加入交流群了解更多!
本文作者:白承麟
澜舟科技算法实习生,北京交通大学自然语言处理实验室二年级硕士生,目前正在进行文本生成方向的研究。
Email: [email protected]
边栏推荐
- Summary of personal work of 21 groups in the first week of summer training
- Lumiprobe nucleic acid quantitative qudye dsDNA br detection kit
- 利用日志服务器输出各种apache的日志的TOPN
- Qiao NPMS: search for NPM packages
- No "history of blood and tears" in home office | community essay solicitation
- Go语学习笔记 - gorm使用 - 数据库配置、表新增 | Web框架Gin(七)
- Web APIs 综合案例-Tab栏切换 丨黑马程序员
- 北京大学ACM Problems 1003:Hangover
- 报错FileSystemException: /datas/nodes/0/indices/gtTXk-hnTgKhAcm-8n60Jw/1/index/.es_temp_file:结构需要清理
- 第81场双周赛
猜你喜欢

ArcMap|用字段计算器对不同类别的id赋值

STL的基本组成部分

Lumiprobe核酸定量丨QuDye dsDNA BR 检测试剂盒

阿里kube-eventer mysql sink简单使用记录

Based on the open source stream batch integrated data synchronization engine Chunjun data restore DDL parsing module actual combat sharing

毕业设计

Lumiprobe染料 NHS 酯丨BDP FL NHS 酯研究

Lumiprobe细胞生物学丨DiA,亲脂性示踪剂说明书

防范未授权访问攻击的十项安全措施

Wechat applet development practice cloud music
随机推荐
北京大学ACM Problems 1001:Exponentiation
Lumiprobe copper free click chemical solution
利用日志服务器输出各种apache的日志的TOPN
[1175. prime number arrangement]
我想知道股票开户要认识谁?另外,手机开户安全么?
BioVendor sRAGE Elisa试剂盒测试原理和注意事项
Peking University ACM problems 1001:exposition
The newly born robot dog can walk by himself after rolling for an hour. The latest achievement of Wu Enda's first disciple
Peking University ACM problems 1002:487-3279
动态样式绑定--style 和 class
MySQL简介、详细安装步骤及使用 | 黑马程序员
阿里kube-eventer mysql sink简单使用记录
北京大学ACM Problems 1004:Financial Management
企业保护 API 安全迫在眉睫
Lumiprobe biotin phosphimide (hydroxyproline) instructions
Qt和其它GUI库的对比
开发技术-获取10分钟前的时间
PHP require/include differences
MySQL introduction, detailed installation steps and usage | dark horse programmer
Evolution of screen display technology