当前位置:网站首页>Meta agent model can be migrated to resist attacks
Meta agent model can be migrated to resist attacks
2022-06-29 18:44:00 【Ghost road 2022】
1 introduction
This paper is about the portability of black box attacks . In the current large number of studies , Many methods directly attack the agent model and obtain the transferable countermeasure samples to deceive the target model , However, due to the mismatch between the agent model and the target model , Their attack effects are limited . In this paper , The author solves this problem from a new angle , By training a meta agent model (MSM), So that attacks on this model can be more easily migrated to other models . The objective function of this method is mathematically expressed as a two-level optimization problem , In order to make the training process gradient effective , A new gradient updating process is proposed , It is proved theoretically that . Experimental results show that , By attacking meta agent model , We can obtain more transportable countermeasure samples to cheat the black box model including countermeasure training , The attack success rate is much higher than the existing methods . According to the algorithm framework , I use pytorch A simple code implementation , Interested people can change the data set part of the code and try to run .
Thesis link : https://arxiv.org/abs/2109.01983
2 Preliminary knowledge
FGSM Attack is a single step attack based on gradient , The classification loss function is increased by using the gradient rising method , Thus, the classification confidence of the target classifier is reduced . The formula is as follows : x a d v = C l i p ( x + ϵ ⋅ s i g n ( ∇ x L ( f ( x ) , y ) ) ) x_{adv}=\mathrm{Clip}(x+\epsilon \cdot \mathrm{sign}(\nabla_{x}L(f(x),y))) xadv=Clip(x+ϵ⋅sign(∇xL(f(x),y))) among x x x It is a clean sample , x a d v x_{adv} xadv To counter the sample , y y y Is the corresponding category label , ϵ \epsilon ϵ Is the attack step size , And there are ϵ < L ∞ \epsilon < L_\infty ϵ<L∞. f f f Is the target classifier being attacked , C l i p \mathrm{Clip} Clip Is a truncation function , L L L Is the cross entropy loss function .
PGD An attack is an extension FGSM Multi step attack mode of attack , The specific formula is as follows : x a d v k = C l i p ( x a d v k − 1 + ϵ T ⋅ s i g n ( ∇ x a d v k − 1 L ( f ( x a d v k − 1 ) , y ) ) ) x^k_{adv}=\mathrm{Clip}(x^{k-1}_{adv}+\frac{\epsilon}{T}\cdot \mathrm{sign}(\nabla_{x^{k-1}_{adv}}L(f(x^{k-1}_{adv}),y))) xadvk=Clip(xadvk−1+Tϵ⋅sign(∇xadvk−1L(f(xadvk−1),y))) x a d v k x^{k}_{adv} xadvk For the first time k k k Counter samples generated in step , also x a d v 0 x_{adv}^0 xadv0 Indicates the initial clean sample , The number of iterations of the attack is T T T.
3 Paper method
For black box attacks , The internal parameter information of the target model is hidden from the attacker and query access is not allowed . Attackers can only access data sets used by the target model , And a single or group of source models that share a dataset with the target model . The existing transportable anti attack methods carry out various attacks on these source models , And hope to obtain the transferable countermeasure samples that can deceive the unknown target model . In this paper, the author proposes a new meta learning migration attack framework to train meta agent model , Its goal is to attack the meta agent model to produce more powerful transferable countermeasures than the original model .
Make A \mathcal{A} A To counter attack algorithms , M θ \mathcal{M}_\theta Mθ Is with a parameter of θ \theta θ Meta - agent model , Give a sample x x x, attack M θ \mathcal{M}_\theta Mθ The counter sample of can be expressed as A ( M θ , x , y ) = x a d v = C l i p ( x + ϵ ⋅ s i g n ( ∇ x L ( M θ ( x ) , y ) ) ) \mathcal{A}(\mathcal{M}_\theta,x,y)=x_{adv}=\mathrm{Clip}(x+\epsilon\cdot \mathrm{sign}(\nabla_x L(\mathcal{M}_\theta(x),y))) A(Mθ,x,y)=xadv=Clip(x+ϵ⋅sign(∇xL(Mθ(x),y))) Because when attacking , Only one set of source models can be obtained F 1 , ⋯ , F N \mathcal{F}_1,\cdots,\mathcal{F}_N F1,⋯,FN, So we need to evaluate the countermeasure samples in the source model A ( M θ , x , y ) \mathcal{A}(\mathcal{M}_\theta,x,y) A(Mθ,x,y) The portability of , And by maximizing this N N N The meta agent model is optimized by using the parameters of the source model , The specific form is as follows arg max θ E ( x , y ) ∼ D [ ∑ i = 1 N L ( F i ( A ( M θ , x , y ) ) , y ) ] \arg\max\limits_{\theta}\mathbb{E}_{(x,y)\sim D}\left[\sum\limits_{i=1}^N L(\mathcal{F}_i(\mathcal{A}(\mathcal{M}_\theta,x,y)),y)\right] argθmaxE(x,y)∼D[i=1∑NL(Fi(A(Mθ,x,y)),y)] among D D D For the distribution of training data . The structure and training process of the goal are shown in the figure below , It can be regarded as a meta learning or two-level optimization method . In Inner optimization , The counter sample is generated by the white box attack on the meta proxy model, which is usually a gradient rising method , And in outer optimization , The authors send the countermeasure samples into the source model to calculate the robust loss .
- In the process of generating countermeasure samples by inner layer optimization , The author designed a self-made PGD Attack methods , The original PGD Attack because of s i g n \mathrm{sign} sign function , The gradient will disappear when the network parameters are updated for back propagation . Is the first k k k Step generated gradient g e n s k g^k_{ens} gensk The calculation formula of is as follows : { g 1 k = g k s u m ( a b s ( g k ) ) g t k = 2 π ⋅ a r c t a n ( g k m e a n ( a b s ( g k ) ) ) g s k = s i g n ( g k ) g e n s k = g 1 k + γ 1 ⋅ g t k + γ 2 ⋅ g s k \left\{\begin{aligned}g_1^k&=\frac{g^k}{\mathrm{sum}(\mathrm{abs}(g^k))}\\g^k_t&=\frac{2}{\pi}\cdot \mathrm{arctan}(\frac{g^k}{\mathrm{mean}(\mathrm{abs}(g^k))})\\g^k_s&=\mathrm{sign}(g^k)\\g^k_{ens}&=g^k_1+\gamma_1 \cdot g_t^k +\gamma_2 \cdot g^k_s\end{aligned}\right. ⎩⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎧g1kgtkgskgensk=sum(abs(gk))gk=π2⋅arctan(mean(abs(gk))gk)=sign(gk)=g1k+γ1⋅gtk+γ2⋅gsk Make γ 1 = γ 2 = 0.01 \gamma_1=\gamma_2=0.01 γ1=γ2=0.01, g 1 k g_1^k g1k and g 2 k g_2^k g2k Ensure that the objective function is differentiable with respect to the parameters of the meta surrogate model , a r c t a n \mathrm{arctan} arctan Is an approximation of a symbolic function , 1 m e a n ( a b s ( g k ) ) \frac{1}{\mathrm{mean}(\mathrm{abs}(g^k))} mean(abs(gk))1 prevent a r c t a n \mathrm{arctan} arctan Fall into a linear region . γ 2 ⋅ g s k \gamma_2\cdot g^k_s γ2⋅gsk by g e n s k g_{ens}^k gensk Each pixel of provides a lower bound . The formula for generating countermeasure samples is as follows : x a d v k = C l i p ( x a d v k − 1 + ϵ c T ⋅ g e n s k − 1 ) x_{adv}^k =\mathrm{Clip}(x_{adv}^{k-1}+\frac{\epsilon_c}{T}\cdot g_{ens}^{k-1}) xadvk=Clip(xadvk−1+Tϵc⋅gensk−1) iteration T T T Get the final confrontation sample after step x a d v T x^{T}_{adv} xadvT.
- Countermeasure samples to be generated x a d v T x^{T}_{adv} xadvT Input to N N N Calculate the corresponding countermeasure loss in the three meta models L ( F i ( x a d v T ) , y ) L(\mathcal{F}_i(x^T_{adv}),y) L(Fi(xadvT),y), N N N The greater the confrontation loss of the source model, the greater the generated confrontation samples generated by the agent model x a d v T x^{T}_{adv} xadvT There is also a higher possibility to cheat the source model .
- The weight parameters of the network are optimized by maximizing the objective function of the meta agent model , The specific parameter optimization formula is as follows θ ′ = θ + α ⋅ ∑ i = 1 N ∇ θ L ( F i ( x a d v ⊤ ) , y ) \theta^{\prime}=\theta+\alpha \cdot \sum\limits_{i=1}^N \nabla_\theta L(\mathcal{F}_i(x^{\top}_{adv}),y) θ′=θ+α⋅i=1∑N∇θL(Fi(xadv⊤),y) Through this training process , The meta proxy model is trained to learn a specific weight , The generated countermeasure samples will have higher mobility .
To calculate ∇ θ L ( F 1 ( x + ϵ c ⋅ g e n s 0 ) , y ) \nabla_\theta L(\mathcal{F}_1(x+\epsilon_c\cdot g^0_{ens}),y) ∇θL(F1(x+ϵc⋅gens0),y) For example , According to the chain rule , x x x And θ \theta θ It's independent of each other , Then there are ∂ L ( F 1 ( x + ϵ c ⋅ g e n s 0 ) , y ) ∂ g e n s 0 ⋅ g e n s 0 ∂ θ \frac{\partial L(\mathcal{F}_1(x+\epsilon_c \cdot g^0_{ens}),y)}{\partial g^0_{ens}}\cdot \frac{g^0_{ens}}{\partial \theta} ∂gens0∂L(F1(x+ϵc⋅gens0),y)⋅∂θgens0 The above formula can be further extended to ∇ θ g e n s 0 = ∇ θ g 1 0 + γ 1 ⋅ ∇ θ g t 0 + γ 2 ⋅ ∇ θ g s 0 \nabla_\theta g^0_{ens}=\nabla_\theta g_1^0 +\gamma_1\cdot \nabla_{\theta}g_t^0+\gamma_2 \cdot \nabla_\theta g_s^0 ∇θgens0=∇θg10+γ1⋅∇θgt0+γ2⋅∇θgs0 Again because g s 0 g_s^0 gs0 be equal to s i g n ( g 0 ) \mathrm{sign}(g^0) sign(g0), Symbolic functions introduce discrete operations , be g s 0 g_s^0 gs0 The gradient of 0 0 0. So we can further get ∇ θ g e n s 0 = ∇ θ g 1 0 + γ ⋅ g t 0 = ∇ θ ( ∇ x L ( M θ ( x ) , y ) s u m ( a b s ( ∇ x L ( M θ ( x ) , y ) ) ) ) + γ 1 ⋅ ∇ θ ( a r c t a n ( ∇ x L ( M θ ( x ) , y ) m e a n ( a b s ( ∇ x L ( M θ ( x ) , y ) ) ) ) ) \begin{aligned}\nabla_\theta g_{ens}^0&=\nabla_\theta g_1^0 +\gamma \cdot g_t^0\\&=\nabla_\theta\left(\frac{\nabla_x L(\mathcal{M}_\theta(x),y)}{\mathrm{sum}(\mathrm{abs}(\nabla_x L(\mathcal{M}_\theta(x),y)))}\right)\\&+\gamma_1 \cdot \nabla_\theta\left(\mathrm{arctan}\left(\frac{\nabla_x L(\mathcal{M}_\theta(x),y)}{\mathrm{mean}(\mathrm{abs}(\nabla_x L(\mathcal{M}_\theta(x),y)))}\right)\right)\end{aligned} ∇θgens0=∇θg10+γ⋅gt0=∇θ(sum(abs(∇xL(Mθ(x),y)))∇xL(Mθ(x),y))+γ1⋅∇θ(arctan(mean(abs(∇xL(Mθ(x),y)))∇xL(Mθ(x),y))) In this formula , ∇ x L ( M θ ( x ) , y ) \nabla_x L(\mathcal{M}_\theta(x),y) ∇xL(Mθ(x),y) Is parameter dependent θ \theta θ, The optimizer that optimizes the meta agent model is SGD Optimizer . The training process of meta countermeasure attack algorithm is as follows :
4 experimental result
The table below shows that it is in Cifar-10 On dataset 8 Migration attack success rate of target networks , The meta agent model uses this 8 From the training of source model . The quantitative results in the following table show that , The method proposed in the paper MTA-PGD The performance of is much better than that of all previous methods , The migration success rate against attacks is significantly improved .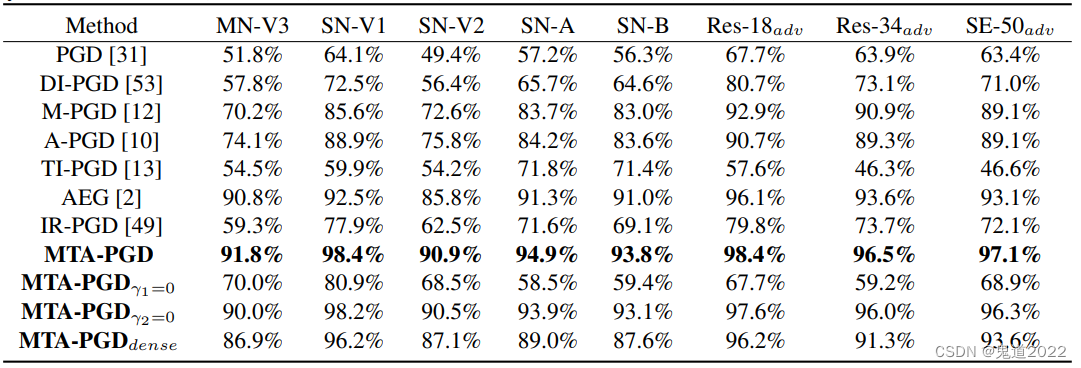
The following figure shows the exploration in Cifar-10 On dataset , The relationship between the number of iterations in the anti attack algorithm and the success rate of migration attack . As you can see from the left half of the picture , Overall, the best number of iteration attacks is T t = 7 T_t=7 Tt=7; It can be seen from the right half of the picture , With the number of iterations T v T_v Tv An increase in , The success rate of migration attacks has also increased significantly .
As shown in the figure below , Qualitative visualization results generated for different attack methods . You can intuitively find , The anti disturbance generated by the method proposed in this paper is more targeted , And the visually generated countermeasure sample is more similar to the original clean sample .
5 Code implementation
Specific in the paper pytorch The simple code implementation of is as follows , The key steps involved in the algorithm flow chart of this paper are implemented , Parts of the dataset and model can be replaced by themselves .
iport torch
import torch.nn as nn
import torch.utils.data as Data
import numpy as np
import os
import torch.nn.functional as F
from copy import deepcopy
def generate_dataset(sample_num, class_num, X_shape):
Label_list = []
Sample_list = []
for i in range(sample_num):
y = np.random.randint(0, class_num)
Label_list.append(y)
Sample_list.append(np.random.normal(y, 0.2, X_shape))
return torch.tensor(Sample_list).to(torch.float32), torch.tensor(Label_list).to(torch.int64)
class Normal_Dataset(Data.Dataset):
def __init__(self, Numpy_Dataset):
super(Normal_Dataset, self).__init__()
self.data_tensor = Numpy_Dataset[0]
self.target_tensor = Numpy_Dataset[1]
def __getitem__(self, index):
return self.data_tensor[index], self.target_tensor[index]
def __len__(self):
return self.data_tensor.size(0)
class Classifer(nn.Module):
def __init__(self):
super(Classifer, self).__init__()
self.conv1 = nn.Conv2d(in_channels = 3, out_channels = 10, kernel_size = 9) # 10, 36x36
self.conv2 = nn.Conv2d(in_channels = 10, out_channels = 20, kernel_size = 17 ) # 20, 20x20
self.fc1 = nn.Linear(20*20*20, 512)
self.fc2 = nn.Linear(512, 7)
def forward(self, x):
in_size = x.size(0)
out = self.conv1(x)
out = F.relu(self.conv2(out))
out = out.view(in_size, -1)
out = F.relu(self.fc1(out))
out = self.fc2(out)
out = F.softmax(out, dim=1)
return out
class MTA_training(object):
def __init__(self, sml, dataloader, bs, msm, epsilon, iteration, gamma_1, gamma_2):
self.source_model_list = source_model_list
self.dataloader = dataloader
self.batch_size = batch_size
self.meta_surrogate_model = meta_surrogate_model
self.epsilon = epsilon
self.iteration = iteration
self.dataloader = dataloader
self.gamma1 = gamma1
self.gamma2 = gamma2
def single_attack(self, x, y, meta_surrogate_model):
delta = torch.zeros_like(x)
delta.requires_grad = True
outputs = meta_surrogate_model(x + delta)
loss = nn.CrossEntropyLoss()(outputs, y)
loss.backward()
grad = delta.grad.detach()
## The equation (4) of the paper
g_1 = grad/torch.sum(torch.abs(grad))
g_t = 2/np.pi * torch.atan(grad/torch.mean(torch.abs(grad)))
g_s = torch.sign(grad)
g_ens = g_1 + self.gamma1 * g_t + self.gamma2 * g_s
## The equation (5) of the paper
x_adv = torch.clamp(x + self.epsilon/ self.iteration * g_ens, 0 ,1)
return x_adv
def training(self, epoch):
loss_fn = nn.CrossEntropyLoss()
optim = torch.optim.SGD(meta_surrogate_model.parameters(), lr=0.001)
for X, Y in self.dataloader:
theta_old_list = []
for parameter in meta_surrogate_model.parameters():
theta_old_list.append(deepcopy(parameter.data))
X_adv = X
for k in range(self.iteration):
X_adv = self.single_attack(X_adv, Y, self.meta_surrogate_model)
loss = 0
for source_model in self.source_model_list:
outputs = source_model(X_adv)
loss += loss_fn(outputs , Y)
optim.zero_grad()
loss.backward()
optim.step()
for parameter_old, parameter in zip(theta_old_list, meta_surrogate_model.parameters()):
parameter.data = 2 * parameter.data - parameter_old.data
if __name__ == '__main__':
batch_size = 2
epsilon = 0.03
iteration = 10
epoch = 1
gamma1 = 0.01
gamma2 = 0.01
numpy_dataset = generate_dataset(10, 7, (3, 44, 44))
dataset = Normal_Dataset(numpy_dataset)
dataloader = Data.DataLoader(
dataset = dataset,
batch_size = batch_size,
num_workers = 0,)
source_model_list = []
source_model1 = Classifer()
source_model2 = Classifer()
source_model_list.append(source_model1)
source_model_list.append(source_model2)
meta_surrogate_model = Classifer()
meta_training = MTA_training(source_model_list, dataloader, batch_size, meta_surrogate_model, epsilon, iteration, gamma1, gamma2)
meta_training.training(10)
边栏推荐
- 面霸篇:MySQL六十六问,两万字+五十图详解!
- Shell basic syntax -- process control
- Panda Parkour JS games code
- 您好,请问mysql cdc、和postgresql cdc有官网样例吗?给个链接学习了
- SD6.22集训总结
- Apache inlong million billion level data stream processing
- SD6.24集训总结
- 保持jupyter notebook在终端关闭时的连接方法
- Adobe Premiere基础-时间重映射(十)
- Basis of data analysis -- prediction model
猜你喜欢

The 8th "Internet +" competition - cloud native track invites you to challenge

Adobe Premiere Basics - general operations for editing material files (offline files, replacing materials, material labels and grouping, material enabling, convenient adjustment of opacity, project pa

Application and practice of DDD in domestic hotel transaction -- Theory

源码安装MAVROS

Apache Doris basic usage summary

jdbc_ Related codes

Leetcode 984. String without AAA or BBB (thought of netizens)

Travel card "star picking" hot search first! Stimulate the search volume of tourism products to rise

Adobe Premiere foundation - opacity (matte) (11)

JWT login authentication
随机推荐
Adobe Premiere基础-素材嵌套(制作抖音结尾头像动画)(九)
[Nanjing University] information sharing of the first and second postgraduate entrance examinations
Shandong University project training (VI) Click event display line chart
mysql -connector/j驱动下载
RocketMQ的tag过滤和sql过滤
6.29模拟赛总结
C Primer Plus Chapter 12_ Storage categories, links, and memory management_ Codes and exercises
C Primer Plus 第12章_存储类别、链接和内存管理_代码和练习题
svg画圆路径动画
2022.6.29-----leetcode.535
SD6.23集训总结
AMAZING PANDAVERSE:META”无国界,来2.0新征程激活时髦属性
Svg circle drawing path animation
Up to 81.98%! Announcement of undergraduate study rate of more than 100 "double first-class" Universities
2022.6.29-----leetcode. five hundred and thirty-five
markdown知识轻轻来袭
VMware installation esxi
My first experience of remote office | community essay solicitation
Stepping on the pit: json Parse and json stringify
How to use idea?