当前位置:网站首页>【机器学习】:如何对你的数据进行分类?
【机器学习】:如何对你的数据进行分类?
2022-08-04 10:45:00 【JoJo的数据分析历险记】
机器学习:如何对你的数据进行分类
- 个人主页:JoJo的数据分析历险记
- 个人介绍:统计学top3研究生
- 如果文章对你有帮助,欢迎
关注、点赞、收藏、订阅专栏
机器学习:如何对你的数据进行分类
引言
如果我们希望使用机器学习来解决需要预测分类结果的业务问题,我们可以使用以下分类算法。
分类算法是用于预测输入数据属于哪个类别的机器学习方法。是一种监督的学习任务,这意味着它们需要带有标记的训练样本。
使用情景
根据症状、实验室结果和历史诊断预测临床诊断
使用索赔金额、药物倾向、疾病和提供者等数据预测医疗保健索赔是否具有欺诈性
常见的分类算法:
以下是用于预测分类结果的最常用算法的介绍:支持向量机、朴素贝叶斯、逻辑回归、决策树和神经网络 我们将探讨各个算法的基本概念和优缺点
支持向量机
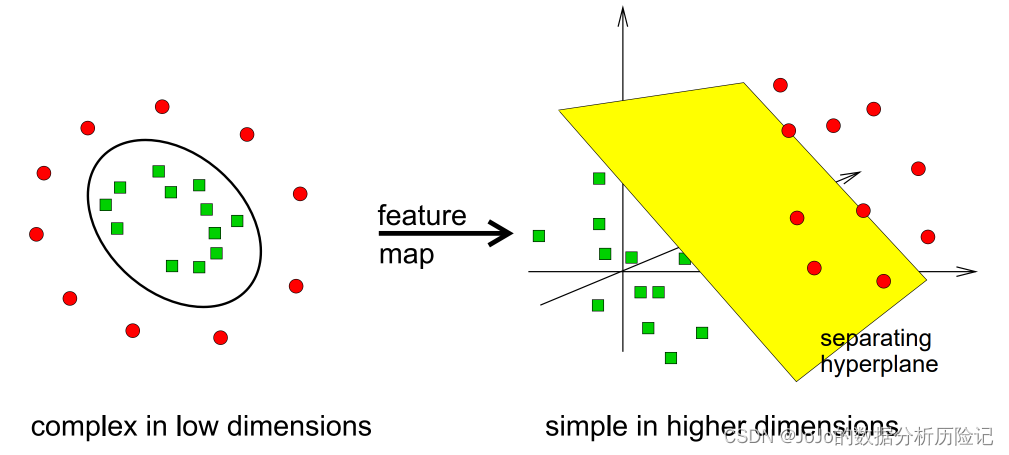
如果在 n 维空间(其中 n 是特征的数量)中绘制数据,支持向量机 (SVM) 会尝试拟合最能区分类别的超平面。当你有一个新的数据点时,它相对于超平面的位置将预测该点属于哪个类别。
优点
- 精确度高
- 可以处理线性不可分问题(结合核方法)
- 适合高维空间(许多特征)
缺点
- 解释性较差
- 在大数据集上训练是比较慢的
- 占用内存较大
朴素贝叶斯
朴素贝叶斯假设所有特征都是独立的,它们独立地贡献于目标变量类别的概率;这并不总是正确的,这就是为什么它被称为“朴素”。概率和似然值是根据它们在数据中出现的频率以及使用贝叶斯定理的公式计算的最终概率来计算的。
优点:
- 非常简单并且好解释
- 计算很快
- 适合处理高纬空间
缺点:
如果变量之间存在显着依赖性(即不满足独立性 ,现实中往往很难满足),则其效果会受到影响
如果一个出现在测试数据中的类没有出现在训练数据中,它的概率为零。对数据有一定的要求
logistic回归
逻辑回归预测二元结果的概率。如果新观察的概率高于设定的阈值,则预测其在该类中。对于有多个类的场景,有一些方法可以使用逻辑回归。
优点 :
- 计算速度快,可以使用新数据轻松更新
- 输出可以解释为概率;这可以用于排名
- 可以使用正则化技术防止过拟合
缺点 :
- 难以捕捉非线性关系
- 不能学习复杂的关系
决策树和集成方法

决策树学习如何最好地(信息增益最大)将数据集拆分为单独的分支,使其能够学习非线性关系。
随机森林 (RF) 和梯度提升树 (GBT) 是两种树算法,它们构建许多单独的树,汇集它们的预测。当他们使用融合的结果来做出最终决定时,被称为“集成模型”(Ensembel model)。
优点:
- 单个树很容易训练
- 集成模型对噪声和缺失值具有鲁棒性
- 随机森林“out-of-the-box”
缺点:
- 单个决策树容易过度拟合(这就是集成方法的用武之地!)
- 复杂的树很难解释
神经网络
神经网络可以使用对数据进行数学转换的神经元层来学习复杂的模式。输入和输出之间的层称为“隐藏层”。神经网络可以学习其他算法无法轻易发现的特征之间的关系。所以我觉得神经网络最主要的就是在做特征提取
优点:
- 非常强大/最先进的许多领域(例如计算机视觉、自然语言处理等)
- 可以学习非常复杂的关系
- 隐藏层减少了对特征工程的需求(减少了对底层数据理解难度)
缺点:
- 需要很多数据
- 容易过拟合(可以使用一些正则化方法)
- 训练时间较长
- 大型数据集需要强大的计算能力(太贵了,计算成本高)
- 模型是一个“黑箱”,无法解释,没有太多的理论
接下来我们来看看如何通过sklearn实现上述各种分类方法
代码实现:
1.数据介绍
简单演示如何使用 scikit-learn 构建常见的分类器。使用 178 种葡萄酒及其各种属性的数据集。数据中有三种不同的葡萄酒类别,目标是根据属性预测葡萄酒类别。数据取自 UCI 机器学习存储库,可在https://archive.ics.uci.edu/ml/datasets/Wine找到。
因为原始数据没有标题。第一列是我们希望预测的类,其余的属性我们将用作特征:
- Alcohol
- Malic acid
- Ash
- Alcalinity of ash
- Magnesium
- Total phenols
- Flavanoids
- Nonflavanoid phenols
- Proanthocyanins
- Color intensity
- Hue
- OD280/OD315 of diluted wines
- Proline
数据导入
import pandas as pd
import numpy as np
我们读入我们保存的数据,传递列名
wine = pd.read_csv(r"C:\Users\DELL\AppData\Roaming\Microsoft\Windows\Network Shortcuts\wine.data",
names=["class", "alcohol", "malic_acid", "ash", "alcalinity_of_ash", "magnesium", "total_phenols","flavanoids", "nonflavanoid_phenols", "proanthocyanins", "color_intensity", "hue", "od280_od315_of_diluted_wines", "proline"])
让我们看看前几行数据
wine.head()
| class | alcohol | malic_acid | ash | alcalinity_of_ash | magnesium | total_phenols | flavanoids | nonflavanoid_phenols | proanthocyanins | color_intensity | hue | od280_od315_of_diluted_wines | proline | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 14.23 | 1.71 | 2.43 | 15.6 | 127 | 2.80 | 3.06 | 0.28 | 2.29 | 5.64 | 1.04 | 3.92 | 1065 |
| 1 | 1 | 13.20 | 1.78 | 2.14 | 11.2 | 100 | 2.65 | 2.76 | 0.26 | 1.28 | 4.38 | 1.05 | 3.40 | 1050 |
| 2 | 1 | 13.16 | 2.36 | 2.67 | 18.6 | 101 | 2.80 | 3.24 | 0.30 | 2.81 | 5.68 | 1.03 | 3.17 | 1185 |
| 3 | 1 | 14.37 | 1.95 | 2.50 | 16.8 | 113 | 3.85 | 3.49 | 0.24 | 2.18 | 7.80 | 0.86 | 3.45 | 1480 |
| 4 | 1 | 13.24 | 2.59 | 2.87 | 21.0 | 118 | 2.80 | 2.69 | 0.39 | 1.82 | 4.32 | 1.04 | 2.93 | 735 |
2.训练集和测试集
拆分数据的目的是能够评估预测模型在用于看不见的数据时的质量。训练时,我们将尝试构建一个尽可能接近数据的模型,以便能够最准确地做出预测。但是,如果没有测试集,我们将面临过度拟合的风险——该模型对于它所看到的数据非常有效,但不适用于新数据。
分割比率经常被争论,在实践中可能会将的数据分成三组:训练、验证和测试。将使用训练数据来了解希望使用哪个分类器;在调整参数的同时进行测试的验证集和测试集,以了解最终模型在实践中的工作方式。此外,还有一些技术,如 K-Fold 交叉验证,也有助于减少偏差。
出于演示目的,我们只会将数据随机分成测试和训练,分成 80/20。
from sklearn.model_selection import train_test_split
# X删除我们的target
X = wine.drop(["class"], axis=1)
y = wine['class']
# 数据集拆分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123)
3.标准化处理
所有特征都是数字型的,因此我们无需担心使用 one-hot 编码等技术转换分类数据。但是,我们将演示如何将我们的数据标准化。标准化重新调整了我们的属性,因此它们的平均值为0,标准差为 1。假设分布是高斯分布(如果是,则效果更好),或者可以使用归一化在 0 和 1 的范围之间重新调整
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
train_scaled = scaler.fit_transform(X_train)
test_scaled = scaler.transform(X_test)
4.支持向量机
如果您在 n 维空间(其中 n 是特征的数量)中绘制数据,支持向量机 (SVM) 会尝试拟合最能区分类别的超平面。当你有一个新的数据点时,它相对于超平面的位置将预测该点属于哪个类别。
from sklearn import svm
model1 = svm.SVC()
model1.fit(train_scaled, y_train)
SVC()
5.朴素贝叶斯
from sklearn.naive_bayes import GaussianNB
model2 = GaussianNB()
model2.fit(train_scaled, y_train)
GaussianNB()
6.logistic回归
from sklearn.linear_model import LogisticRegression
modelog = LogisticRegression()
modelog.fit(train_scaled,y_train)
LogisticRegression()
7.决策树和随机森林
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
tree_model = DecisionTreeClassifier()
rf_model = RandomForestClassifier()
tree_model.fit(train_scaled, y_train)
rf_model.fit(train_scaled, y_train)
RandomForestClassifier()
8.神经网络
from sklearn.neural_network import MLPClassifier
model3 = MLPClassifier()
model3.fit(train_scaled, y_train)
MLPClassifier()
9.模型评估
from sklearn.metrics import accuracy_score
# 训练集精确度
print('SVM训练集精度:',accuracy_score(y_train, model1.predict(train_scaled)))
print('朴素贝叶斯训练集精度:' ,accuracy_score(y_train, model2.predict(train_scaled)))
print('logistic回归训练集精度:' ,accuracy_score(y_train, modelog.predict(train_scaled)))
print("决策树训练集精度",accuracy_score(y_train, tree_model.predict(train_scaled)))
print("随机森林训练集精度",accuracy_score(y_train, rf_model.predict(train_scaled)))
print('MLP训练集精度',accuracy_score(y_train, model3.predict(train_scaled)))
SVM训练集精度: 1.0
朴素贝叶斯训练集精度: 0.9788732394366197
logistic回归训练集精度: 1.0
决策树训练集精度 1.0
随机森林训练集精度 1.0
MLP训练集精度 1.0
# 测试集精确度
print('SVM测试集精度:',accuracy_score(y_test, model1.predict(test_scaled)))
print('朴素贝叶斯测试集季度:' ,accuracy_score(y_test, model2.predict(test_scaled)))
print('logistic回归测试集精度:' ,accuracy_score(y_test, modelog.predict(test_scaled)))
print("决策树测试集精度",accuracy_score(y_test, tree_model.predict(test_scaled)))
print("随机森林测试集精度",accuracy_score(y_test, rf_model.predict(test_scaled)))
print('MLP测试集精度',accuracy_score(y_test, model3.predict(test_scaled)))
SVM测试集精度: 0.9722222222222222
朴素贝叶斯测试集季度: 1.0
logistic回归测试集精度: 0.9722222222222222
决策树测试集精度 0.9166666666666666
随机森林测试集精度 1.0
MLP测试集精度 0.9722222222222222
总结
在红酒数据集上各个分类器的结果都不错,在具体项目中,大家可能需要使用一些更complex的模型。如果文章对你有帮助,一键三连吧,谢谢各位的支持!
边栏推荐
猜你喜欢



![[论文阅读] Unpaired Image-to-Image Translation Using Adversarial Consistency Loss](/img/4d/9c2f94f475834771f6ad6ffe8f8b35.png)
随机推荐
MATLAB程序设计与应用 3.2 矩阵变换
关于ARM2440中断源个数的一点想法[通俗易懂]
AWS Lambda相关概念与实现思路
Introduction to Mysql storage engine
什么是终端特权管理
学会使用set和map的基本接口
MySQL:完整性约束和 表的设计原则
JUC(1)线程和进程、并发和并行、线程的状态、lock锁、生产者和消费者问题
在 .NET MAUI 中如何更好地自定义控件
What is the principle of thermal imaging temperature measurement?Do you know?
MySQL最大建议行数2000w, 靠谱吗?
华为云安全云脑,让企业云化运营更放心
数据使用要谨慎——不良数据带来严重后果
OD-Model【5】:YOLOv1
iMeta | 百度认证完成,搜索“iMeta”直达出版社主页和投稿链接
What is the terminal privilege management
onlyoffice设置跟踪变化trackChanges默认为对自己启动
再次搞定 Ali 云函数计算 FC
Introduction to the core methods of the CompletableFuture interface
RAID介绍及RAID5配置实例