当前位置:网站首页>Retinaface: single stage dense face localization in the wild
Retinaface: single stage dense face localization in the wild
2022-07-03 10:01:00 【Star soul is not a dream】
Paper code :https://github.com/deepinsight/insightface/tree/master/RetinaFace.
Accurate and efficient face location in natural scenes is still a challenge . This paper presents a robust Of single-stage Face detector :RetinaFace, It USES Joint additional supervision ( contribution 1) And self supervised multi task learning ( contribution 2), Pixel face location on faces of different scales .
Five contributions :
- stay WIDER FACE Five facial signs are manually marked on the dataset , And observed that with the help of this additional monitoring signal , Face detection has been significantly improved .
- Added a self supervised grid coding Branch , Used to predict a pixel by pixel 3D Face information . This branch is in parallel with the existing supervisory branch .
- stay WIDER FACE Test set ,RetinaFace The average accuracy of (AP) Than the current average accuracy (AP) Higher than 1.1% (AP = 91.4%).
- stay IJB-C Test set ,RetinaFace Make the current best ArcFace In face authentication (face verification) Further improve (TAR=89.59 FAR=1e-6).
By using lightweight backbone ,RetinaFace Single core can CPU In real time VGA The resolution of the Image .
Automatic face location is face image analysis, such as face attributes ( expression , Age ,ID distinguish ) The prerequisite for . Face location in a narrow sense may refer to traditional face detection , It aims to estimate the face detection frame without any scale and location a priori . However , This paper refers to the generalized definition of face location , Including face detection 、 Face to face comparison ( face alignment)、 Pixelated face analysis and 3D Dense correspondence regression (3D dense correspondence regression). This dense facial positioning provides accurate facial position information for all different scales .
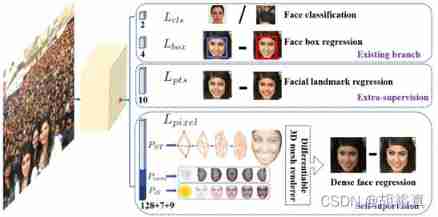
chart 1. The proposed one-stage pixel level face location method uses additional supervision (extra-supervised) And self supervised multi task learning , And existing box Classification and regression branches are parallel . Each positive anchor (positive anchor) The output is :(1) One face scores ;(2) A person's face frame ;(3) Five faces landmarks;(4) Dense objects projected on the image plane 3D Face vertex .
Usually , Face detection training process includes classification and box Return to loss .Chen Et al. Provided better feature observation for face classification based on aligned face shape , Proposed to face detection and alignment Combined in a joint cascading framework . suffer
[6] (D. Chen, S. Ren, Y. Wei, X. Cao, and J. Sun. Joint cascade face detection and alignment. In ECCV, 2014. 1, 2) Inspired by the ,MTCNN and STN Detect the face and five facial signs at the same time . Due to the limitation of training data ,JDA、MTCNN and STN Not verified yet tiny Can face detection benefit from additional supervision of five facial markers . In this paper , One of the questions we aim to answer is , Can we use additional surveillance signals constructed from five facial signs , To promote the current in WIDER FACE hard test set[60] The best performance in (90.3%[67]).
stay Mask R-CNN in , By adding the branches of the prediction object mask while recognizing and regressing the bounding box of the existing branches , The detection performance has been significantly improved . This confirms that dense pixel level annotation also helps to improve detection . Unfortunately , about WIDER FACE Challenging face , It is impossible to make intensive facial annotation ( In the form of more annotations or semantic fragments ). Due to the supervision signal, it is not easy to obtain , The question is whether we can apply unsupervised methods to further improve the face .
FAN Put forward a kind of anchor Level attention map to improve the detection of occluded faces . However , The proposed attention map is very rough , And does not contain semantic information . But recently , Self supervised 3D Morphological model has achieved good 3D face modeling in natural environment . In particular, the mesh decoder realizes real-time speed by using graph convolution in shape and texture . However , The challenges of applying grid decoder to single-stage architecture are : (1) Camera parameters are difficult to estimate accurately (2) The joint potential shape and texture are predicted in a single feature vector ( On the characteristic pyramid 1×1 Conv), instead of ROI Pooling characteristics , There is a risk of feature transfer . In this paper , We use a branch of grid decoder through self supervised learning , Used to predict pixel level in parallel with existing supervisory branches 3D Face shape . In general, our main contributions are as follows :
- On the basis of single-stage design , A new method named RetinaFace Pixel based face location method , This method adopts a multi task learning strategy to predict the face score at the same time 、 Face frame 、 The key points of five faces and the three-dimensional position and corresponding relationship of each face pixel .
- stay WIDER FACE hard On a subset ,RetinaFace It is higher than the current two-stage method 1.1%( Average accuracy reaches 91.4%)
- stay IJB-C On dataset ,RetinaFace Contribute to ArcFace Verification accuracy of (TAR =89.59% 、FAR=1e-6). This shows that better face location can significantly improve the ability of face recognition .
- By using lightweight backbone ,RetinaFace Can be in a single CPU Real time running on the core vga Resolution image .
- Additional comments and code have been released , To promote future research .
2. Related work
Image pyramid vs Characteristic pyramid :
The earliest sliding windows can be traced back to decades ago ( The classifier is applied to a dense image grid ).Viola-Jones The milestone work explores the cascade chain , It can remove false face regions from the image pyramid in real time and efficiently , This scale invariant face detection framework has been widely used . Although the sliding window on the image pyramid is the main detection paradigm , But with the emergence of the feature pyramid , Sliding anchor on multi-scale feature map Quickly occupied the dominant position of face detection .
Two stages vs . Single stage :
The current face detection method inherits some achievements of the general target detection method , It can be divided into two categories : Two stage approach ( Such as FAST R-CNN) And a one-stage approach ( Such as SSD and RetinaNet). The two-stage approach uses “ Suggestions and improvements (proposal and refinement)” Mechanism , It has high positioning accuracy . The single-stage method intensively samples the position and scale of human face , This leads to a great imbalance between positive samples and negative samples in the training process . To deal with this imbalance , Sampling and re-weighting Methods . Compared with the two-stage method , The single-stage method is more efficient , Higher recall rate , But there is a higher false positive rate 、 The risk of decreased positioning accuracy .
Context modeling :
To enhance model capture tiny The ability of contextual reasoning in face ,SSH and PyramidBox The context module is applied to the feature pyramid to expand the receptive field obtained in the Euclidean grid . To enhance CNNs The ability of non rigid transformation modeling , Deformable convolution network (DCN) A new deformable layer is used to model geometric transformation .2018 Year of WIDER Face Challenge The champion solution shows , Rigidity ( Expand ) And non rigid ( deformation ) Context modeling is complementary and orthogonal , It can improve the performance of face detection .
Multi task learning :
The combination of face detection and alignment is widely used , Because the aligned face shape provides better features for face classification . stay Mask R-CNN in , By adding a branch of the prediction object mask in parallel to the existing branch , Significantly improved detection performance .Densepose Adopted Mask-RCNN The architecture of , Get the dense part labels and coordinates in each selected area . Dense regression branches are trained through supervised learning . Besides , A dense branch is a small FCN Apply to each RoI, To predict pixel to pixel dense mapping .
3.RetinaFace
3.1 Multitasking loss
For every training anchor i , Minimize the multitask loss function :
 (1)
(1)
(1) Face classification loss  , among
, among  by anchor i Prediction probability for face , also
by anchor i Prediction probability for face , also  about positive anchor yes 1, about negative anchor yes 0. Classified loss
about positive anchor yes 1, about negative anchor yes 0. Classified loss  The second is classification ( face / Not the face ) Of softmax loss.
The second is classification ( face / Not the face ) Of softmax loss.
(2) Face frame regression loss  , among
, among  and
and  Indicates prediction box and And positive anchor The coordinates of the relevant real box . According to the literature 【16】 Standardized box regression goal ( That is, the center position 、 Width and height ) And use
Indicates prediction box and And positive anchor The coordinates of the relevant real box . According to the literature 【16】 Standardized box regression goal ( That is, the center position 、 Width and height ) And use  , here R yes The literature 【16】 Defined smooth-L1 Loss function .
, here R yes The literature 【16】 Defined smooth-L1 Loss function .
(3) Face key point regression loss  , among
, among  and
and  respectively Predicted five face key points and And right anchor About the true value . And box centre Return to similar , Five face key point regression is also based on anchor The target normalization method of the center .
respectively Predicted five face key points and And right anchor About the true value . And box centre Return to similar , Five face key point regression is also based on anchor The target normalization method of the center .
(4) Dense regression loss  ( Refer to the formula 3).
( Refer to the formula 3).
Loss balance parameters  Set to 0.25、0.1 and 0.01, It means that we have added signals from supervision The importance of better border and key positioning .
Set to 0.25、0.1 and 0.01, It means that we have added signals from supervision The importance of better border and key positioning .
[16] R. Girshick. Fast r-cnn. In ICCV, 2015. 1, 3
To be continued :
边栏推荐
- Design of charging pile mqtt transplantation based on 4G EC20 module
- When you need to use some functions of STM32, but 51 can't realize them, 32 naturally doesn't need to learn
- 4G module initialization of charge point design
- STM32 external interrupt experiment
- Fundamentals of Electronic Technology (III)__ Chapter 6 combinational logic circuit
- Swing transformer details-2
- Quelle langue choisir pour programmer un micro - ordinateur à puce unique
- 嵌入式系统没有特别明确的定义
- Project cost management__ Topic of comprehensive calculation
- 万字手撕七大排序(代码+动图演示)
猜你喜欢
C language enumeration type

Swing transformer details-1

yocto 技術分享第四期:自定義增加軟件包支持
Schematic diagram and connection method of six pin self-locking switch

Oracle数据库 SQL语句执行计划、语句跟踪与优化实例

2021-10-27

编程思想比任何都重要,不是比谁多会用几个函数而是比程序的理解
Idea remote breakpoint debugging jar package project

手机都算是单片机的一种,只不过它用的硬件不是51的芯片

STM32 serial communication principle

随机推荐
Seven sorting of ten thousand words by hand (code + dynamic diagram demonstration)
51 MCU tmod and timer configuration
There is no shortcut to learning and development, and there is almost no situation that you can learn faster by leading the way
yocto 技术分享第四期:自定义增加软件包支持
03 fastjason solves circular references
It is difficult to quantify the extent to which a single-chip computer can find a job
yocto 技術分享第四期:自定義增加軟件包支持
MySQL 数据库基础知识(系统化一篇入门)
My openwrt learning notes (V): choice of openwrt development hardware platform - mt7688
Oracle数据库 SQL语句执行计划、语句跟踪与优化实例
Timer and counter of 51 single chip microcomputer
Exception handling of arm
开学实验里要用到mysql,忘记基本的select语句怎么玩啦?补救来啦~
Fundamentals of Electronic Technology (III)__ Chapter 1 resistance of parallel circuit
Fundamentals of Electronic Technology (III)_ Integrated operational amplifier and its application__ Basic arithmetic circuit
Project cost management__ Cost management technology__ Article 8 performance review
My notes on intelligent charging pile development (II): overview of system hardware circuit design
Vscode markdown export PDF error
Gif image analysis drawing RGB to YUV table lookup method to reduce CPU occupancy
(1) What is a lambda expression