当前位置:网站首页>输入的查询SQL语句,是如何执行的?
输入的查询SQL语句,是如何执行的?
2022-07-04 18:35:00 【51CTO】
摘要:输入一条语句,返回一个结果,却不知道这条语句在 MySQL 内部的执行过程。
本文分享自华为云社区《 一条查询SQL是如何执行的》,作者: 共饮一杯无 。
执行如下SQL,我们看到的只是输入一条语句,返回一个结果,却不知道这条语句在 MySQL 内部的执行过程。

上图给出的是 MySQL 的基本架构示意图,从中你可以清楚地看到 SQL 语句在 MySQL 的各个功能模块中的执行过程。大体来说,MySQL 可以分为 Server 层和存储引擎层两部分。
Server 层包括连接器、查询缓存、分析器、优化器、执行器等,涵盖 MySQL 的大多数核心服务功能,以及所有的内置函数(如日期、时间、数学和加密函数等),所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图等。
而存储引擎层负责数据的存储和提取。其架构模式是插件式的,支持 InnoDB、MyISAM、Memory 等多个存储引擎。现在最常用的存储引擎是 InnoDB,它从 MySQL 5.5.5 版本开始成为了默认存储引擎。也可以通过指定存储引擎的类型来选择别的引擎,比如在 create table 语句中使用 engine=memory, 来指定使用内存引擎创建表。
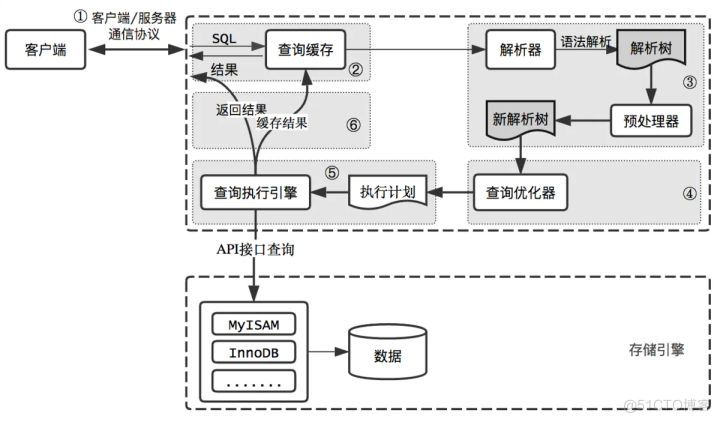
一条SQL查询的完整执行流程如上图所示。
Server服务层
连接器
连接数据库最开始肯定是连接器。连接器负责跟客户端建立连接、获取权限、维持和管理连接。连接命令一般是这么写的:
输完命令之后,你就需要在交互对话里面输入密码。虽然密码也可以直接跟在 -p 后面写在命令行中,但这样可能会导致你的密码泄露。如果你连的是生产服务器,强烈建议你不要这么做。
连接命令中的 mysql 是客户端工具,用来跟服务端建立连接。在完成经典的 TCP 握手后,连接器就要开始认证你的身份,这个时候用的就是你输入的用户名和密码。
- 如果用户名或密码不对,你就会收到一个"Access denied for user"的错误,然后客户端程序结束执行。
- 如果用户名密码认证通过,连接器会到权限表里面查出你拥有的权限。之后,这个连接里面的权限判断逻辑,都将依赖于此时读到的权限。
这就意味着,一个用户成功建立连接后,即使你用管理员账号对这个用户的权限做了修改,也不会影响已经存在连接的权限。修改完成后,只有再新建的连接才会使用新的权限设置。
连接完成后,如果你没有后续的动作,这个连接就处于空闲状态,你可以在 show processlist 命令中看到它。文本中这个图是 show processlist 的结果,其中的 Command 列显示为“Sleep”的这一行,就表示现在系统里面有一个空闲连接。

客户端如果太长时间没动静,连接器就会自动将它断开。这个时间是由参数 wait_timeout 控制的,默认值是 8 小时。
如果在连接被断开之后,客户端再次发送请求的话,就会收到一个错误提醒: Lost connection to MySQL server during query。这时候如果你要继续,就需要重连,然后再执行请求了。
数据库里面,长连接是指连接成功后,如果客户端持续有请求,则一直使用同一个连接。短连接则是指每次执行完很少的几次查询就断开连接,下次查询再重新建立一个。
建立连接的过程通常是比较复杂的,所以我建议你在使用中要尽量减少建立连接的动作,也就是尽量使用长连接。但是全部使用长连接后,你可能会发现,有些时候 MySQL 占用内存涨得特别快,这是因为 MySQL 在执行过程中临时使用的内存是管理在连接对象里面的。这些资源会在连接断开的时候才释放。所以如果长连接累积下来,可能导致内存占用太大,被系统强行杀掉(OOM),从现象看就是 MySQL 异常重启了。
怎么解决这个问题呢?你可以考虑以下两种方案。
- 定期断开长连接。使用一段时间,或者程序里面判断执行过一个占用内存的大查询后,断开连接,之后要查询再重连。
- 如果你用的是 MySQL 5.7 或更新版本,可以在每次执行一个比较大的操作后,通过执行 mysql_reset_connection 来重新初始化连接资源。这个过程不需要重连和重新做权限验证,但是会将连接恢复到刚刚创建完时的状态。
查询缓存
连接建立完成后,你就可以执行 select 语句了。执行逻辑就会来到第二步:查询缓存。
MySQL 拿到一个查询请求后,会先到查询缓存看看,之前是不是执行过这条语句。之前执行过的语句及其结果可能会以 key-value 对的形式,被直接缓存在内存中。key 是查询的语句,value 是查询的结果。如果你的查询能够直接在这个缓存中找到 key,那么这个 value 就会被直接返回给客户端。
如果语句不在查询缓存中,就会继续后面的执行阶段。执行完成后,执行结果会被存入查询缓存中。你可以看到,如果查询命中缓存,MySQL 不需要执行后面的复杂操作,就可以直接返回结果,这个效率会很高。
但是大多数情况下我会建议你不要使用查询缓存,为什么呢?因为查询缓存往往弊大于利。
查询缓存的失效非常频繁,只要有对一个表的更新,这个表上所有的查询缓存都会被清空。因此很可能你费劲地把结果存起来,还没使用呢,就被一个更新全清空了。对于更新压力大的数据库来说,查询缓存的命中率会非常低。除非你的业务就是有一张静态表,很长时间才会更新一次。比如,一个系统配置表,那这张表上的查询才适合使用查询缓存。
好在 MySQL 也提供了这种“按需使用”的方式。你可以将参数 query_cache_type 设置成 DEMAND,这样对于默认的 SQL 语句都不使用查询缓存。而对于你确定要使用查询缓存的语句,可以用 SQL_CACHE 显式指定,像下面这个语句一样:
需要注意的是,MySQL 8.0 版本直接将查询缓存的整块功能删掉了,也就是说 8.0 开始彻底没有这个功能了。
分析器
如果没有命中查询缓存,就要开始真正执行语句了。首先,MySQL 需要知道你要做什么,因此需要对 SQL 语句做解析。
分析器先会做“词法分析”。你输入的是由多个字符串和空格组成的一条 SQL 语句,MySQL 需要识别出里面的字符串分别是什么,代表什么。
MySQL 从你输入的"select"这个关键字识别出来,这是一个查询语句。它也要把字符串“T”识别成“表名 T”,把字符串“ID”识别成“列 ID”。
做完了这些识别以后,就要做“语法分析”。根据词法分析的结果,语法分析器会根据语法规则,判断你输入的这个 SQL 语句是否满足 MySQL 语法。
如果你的语句不对,就会收到“You have an error in your SQL syntax”的错误提醒,比如下面这个语句 select 少打了开头的字母“s”。
一般语法错误会提示第一个出现错误的位置,所以你要关注的是紧接“use near”的内容。
优化器
经过了分析器,MySQL 就知道你要做什么了。在开始执行之前,还要先经过优化器的处理。
优化器是在表里面有多个索引的时候,决定使用哪个索引;或者在一个语句有多表关联(join)的时候,决定各个表的连接顺序。通常两种执行方法的逻辑结果是一样的,但是执行的效率会有不同,而优化器的作用就是决定选择使用哪一个方案。优化器阶段完成后,这个语句的执行方案就确定下来了,然后进入执行器阶段。
执行SQL查询的时候优化器主要执行如下任务:
- 选择最合适的索引;
- 选择表扫还是走索引;
- 选择表关联顺序;
- 优化 where 子句;
- 排除管理中无用表;
- 决定 order by 和 group by 是否走索引;
- 尝试使用 inner join 替换 outer join;
- 简化子查询,决定结果缓存;
MySQL 查询优化器有几个目标,但是其中最主要的目标是尽可能地使用索引,并且使用最严格的索引来消除尽可能多的数据行。
优化器试图排除数据行的原因在于它排除数据行的速度越快,那么找到与条件匹配的数据行也就越快。如果能够首先进行最严格的测试,查询就可以执行地更快。
执行器
MySQL 通过分析器知道了你要做什么,通过优化器知道了该怎么做,于是就进入了执行器阶段,开始执行语句。
开始执行的时候,要先判断一下你对这个表 T 有没有执行查询的权限,如果没有,就会返回没有权限的错误,如下所示 (在工程实现上,如果命中查询缓存,会在查询缓存返回结果的时候,做权限验证。查询也会在优化器之前调用 precheck 验证权限)。
如果有权限,就打开表继续执行。打开表的时候,执行器就会根据表的引擎定义,去使用这个引擎提供的接口。
比如我们这个例子中的表 T 中,ID 字段没有索引,那么执行器的执行流程是这样的:
- 调用 InnoDB 引擎接口取这个表的第一行,判断 ID 值是不是 10,如果不是则跳过,如果是则将这行存在结果集中;
- 调用引擎接口取“下一行”,重复相同的判断逻辑,直到取到这个表的最后一行。
- 执行器将上述遍历过程中所有满足条件的行组成的记录集作为结果集返回给客户端。
至此,这个语句就执行完成了。
对于有索引的表,执行的逻辑也差不多。第一次调用的是“取满足条件的第一行”这个接口,之后循环取“满足条件的下一行”这个接口,这些接口都是引擎中已经定义好的。
你会在数据库的慢查询日志中看到一个 rows_examined 的字段,表示这个语句执行过程中扫描了多少行。这个值就是在执行器每次调用引擎获取数据行的时候累加的。
在有些场景下,执行器调用一次,在引擎内部则扫描了多行,因此引擎扫描行数跟 rows_examined 并不是完全相同的。
存储引擎
通过 show engines;查看引擎类型,可以看出来要用到事务只能用InnoDB引擎类型。

InnoDB存储引擎
InnoDB是MySQL的默认事务型引擎,也是最重要、使用最广泛的存储引擎,并且有行级锁定和外键约束。它被设计用来处理大量的短期(short-lived)事务,短期事务大部分情况是正常提交,很少会被回滚。InnoDB的性能和自动崩溃恢复特性,使得它在非事务型存储的需求中也很流行。除非有非常特别的原因需要使用其他的存储引擎,否则应该优先考虑InnoDB引擎。
InnoDB的适用场景/特性,有以下几种:
- 经常更新的表,适合处理多重并发的更新请求。
- 支持事务。
- 可以从灾难中恢复(通过bin-log日志等)。
- 外键约束。只有他支持外键。
- 支持自动增加列属性auto_increment。
MyISAM存储引擎
MyISAM提供了大量的特性,包括全文检索、压缩等,但不支持事务和行级锁,支持表级锁。 对于只读的数据,或者表较小、可以忍受修复操作的场景,依然可以使用MyISAM。
MyISAM的适用场景/特性,有以下几种:
- 不支持事务的设计,但是并不代表着有事务操作的项目不能用MyISAM存储引擎,完全可以在程序层进行根据自己的业务需求进行相应的控制。
- 不支持外键的表设计。
- 查询速度很快,如果数据库insert和update的操作比较多的话比较适用。
- 整天 对表进行加锁的场景。
- MyISAM极度强调快速读取操作。
- MyIASM中存储了表的行数,于是SELECT COUNT(*) FROM TABLE时只需要直接读取已经保存好的值而不需要进行全表扫描。如果表的读操作远远多于写操作且不需要数据库事务的支持,那么MyIASM也是很好的选择。
MySQL内建的其他存储引擎
MySQL还有一些特殊用途的存储引擎,在一些特殊场景下用起来会很爽的。在MySQL新版本中,有些可能因为一些原因已经不再支持了,还有一些会继续支持,但是需要明确地启用后才能使用。
Archive存储引擎
Archive引擎只支持insert和select操作,并且在MySQL 5.1之前连索引都不支持。
Archive引擎会缓存所有的写并利用zlib对插入的行进行压缩,所以比MyISAM引擎的磁盘I/O更少。但是每次select查询都需要进行全表扫描,所以Archive更适合日志和数据采集类应用,况且这类应用在做数据分析时往往需要全表扫描。
Archive引擎支持行级锁和专用的缓冲区,所以可以实现高并发的插入。在一个查询开始直到返回表中存在的所有行之前,Archive引擎会阻止其他的select执行,以实现一致性读。另外,这也实现了批量插入在完成之前对读操作是不看见的。
Blackhole存储引擎
Blackhole引擎没有实现任何的存储机制,它会丢失所有插入的数据,不做任何保存。怪哉,岂不是一无用处?但是服务器会记录Blackhole的日志,所以可以用于复制数据到备库,或者只是简单地记录到日志。这种特殊的存储引擎可以在一些特殊的复制架构和日志审核时发挥作用。
但这种存储引擎的存在,至今还是有些难以理解。
CSV存储引擎
CSV引擎可以将普通的CSV文件作为MySQL的表来处理,但这种表不支持索引。
CSV引擎可以在数据库运行时拷入或者拷出文件,可以将Excel等电子表格软件中的数据存储为CSV文件,然后复制到MySQL数据目录下,就能在MySQL中打开使用。同样,如果将数据写入到一个CSV引擎表中,其他的外部程序也能立即从表的数据文件中读取CSV格式的数据。
因此,CSV引擎可以作为一种数据交换的机制,是非常有用的。
Memory存储引擎
如果需要快速地访问数据,并且这些数据不会被修改,重启以后丢失也没有关系,那么使用Memory引擎是非常有用的。Memory引擎至少比MyISAM引擎要快一个数量级,因为所有的数据都保存在内存中,不需要进行磁盘I/O。Memory引擎的表结构在重启以后还会保留,但数据会丢失。
Memory引擎在很多场景下可以发挥很好的作用:
- 用于查找或者映射表,例如将邮箱和州名映射的表。
- 用于缓存周期性聚合数据的结果。
- 用于保存数据分析中产生的中间数据。
Memory引擎支持Hash索引,因此查找非常快。虽然Memory的速度非常快,但还是无法取代传统的基于磁盘的表。Memory引擎是表级锁,因此并发吸入的性能较低。
如果MySQL在执行查询的过程中,需要使用临时表来保存中间结果,内部使用的临时表就是Memory引擎。如果中间结果太大超出了Memory的限制,或者含有BLOB或TEXT字段,则临时表会转换成MyISAM的引擎。
看了上面的说明,大家就会经常混淆Memory和临时表了。临时表是指使用CREATE TEMPORARY TABLE语句创建的表,它可以使用任何存储引擎,因此和Memory不是一回事。临时表只在单个连接中可见,当连接断开时,临时表也将不复存在。
关于临时表和Memory引擎的那些事,可参考MySQL · 引擎特性 · 临时表那些事儿。
MySQL的存储引擎及第三方存储引擎,还有很多,在此就不一一介绍了,后续如有需要,再进一步来谈谈。
如何选择合适的存储引擎呢
这么多存储引擎,真是眼花缭乱,我们该如何选择呢?
大部分情况下,都会选择默认的存储引擎——InnoDB,并且这也是最正确的选择,所以Oracle在MySQL 5.5版本时终于将InnoDB作为默认的存储引擎了。
对于如何选择合适的存储引擎,可以简单地归纳为一句话:”除非需要用到某些InnoDB不具备的特性,并且没有其他可以替代,否则都应该优先选择InnoDB引擎”。
例如,如果要用到全文检索,建议优先考虑InnoDB加上Sphinx的组合,而不是使用支持全文检索的MyISAM。当然,如果不需要用到InnoDB的特性,同时其他引擎的特性能够更好地满足需求,就可以考虑一下其他存储引擎。
除非万不得已,建议不要混合使用多种存储引擎,否则可能带来一系列复杂的问题,以及一些潜在的bug和边界问题。
如果需要使用不同的存储引擎,建议考虑从以下几个因素进行衡量考虑。
- 事务
- 备份
- 恢复
- 特有的特性
其他查找引擎SQL
通过下面的命令查看默认的存储引擎。
若有收获,就点个赞吧
边栏推荐
- Basic use of kotlin
- 1006 Sign In and Sign Out(25 分)(PAT甲级)
- 【毕业季】绿蚁新醅酒,红泥小火炉。晚来天欲雪,能饮一杯无?
- 1009 Product of Polynomials(25 分)(PAT甲级)
- How to use async Awati asynchronous task processing instead of backgroundworker?
- 公司要上监控,Zabbix 和 Prometheus 怎么选?这么选准没错!
- Abc229 summary (connected component count of the longest continuous character graph in the interval)
- 牛客小白月赛7 E Applese的超能力
- Master the use of auto analyze in data warehouse
- Actual combat simulation │ JWT login authentication
猜你喜欢
Chrome development tool: what the hell is vmxxx file
牛客小白月赛7 谁是神箭手

Pytoch learning (4)
Siemens HMI download prompts lack of panel image solution

HMM隐马尔可夫模型最详细讲解与代码实现

Dark horse programmer - software testing - 09 stage 2-linux and database -31-43 instructions issued by modifying the file permission letter, - find the link to modify the file, find the file command,

Master the use of auto analyze in data warehouse
华为nova 10系列支持应用安全检测功能 筑牢手机安全防火墙
Chrome开发工具:VMxxx文件是什么鬼
上线首月,这家露营地游客好评率高达99.9%!他是怎么做到的?

随机推荐
Mysql database basic operation -ddl | dark horse programmer
Niuke Xiaobai monthly race 7 I new Microsoft Office Word document
Explore the contour drawing function drawcontours() of OpenCV in detail with practical examples
1007 Maximum Subsequence Sum(25 分)(PAT甲级)
Some thoughts on whether the judgment point is located in the contour
双冒号作用运算符以及命名空间详解
Dark horse programmer - software testing - stage 08 2-linux and database-23-30-process port related, modify file permissions, obtain port number information, program and process related operations, Li
牛客小白月赛7 I 新建 Microsoft Office Word 文档
需求开发思考
牛客小白月赛7 F题
HDU 1097 A hard puzzle
[problem] Druid reports exception SQL injection violation, part always true condition not allow solution
Double colon function operator and namespace explanation
92. (cesium chapter) cesium building layering
Hough transform Hough transform principle
YOLOv5s-ShuffleNetV2
牛客小白月赛7 谁是神箭手
Educational Codeforces Round 22 E. Army Creation
Introduction to polyfit software
The company needs to be monitored. How do ZABBIX and Prometheus choose? That's the right choice!