当前位置:网站首页>七夕看什么电影好?爬取电影评分并存入csv文件
七夕看什么电影好?爬取电影评分并存入csv文件
2022-08-05 07:59:00 【仙草哥哥】
需求分析
众所周知,今天已经是七夕节了。能过上节日的想必已经在出去玩以及在出去玩的路上了。下午的时候呢,我也收到了一则攻略“七夕节情侣看恐怖电影如何拉近两人之间的距离”,可惜啊,虽然攻略不错,不过看起来我是用不上了
出去玩相比也少不了看电影的环节吧?那么,看什么电影比较好呢?想必很多情侣,平日里可能并不关注电影的消息,等到了要找一个电影看的时候,就不知道应该看什么会比较好了。可能,听说最近那个叫做《独行月球》的比较火,已经突破了好多好多亿的票房了,应该去看这个电影吗?
如果问我的话,我其实也不知道。但是呢,如果要知道看什么电影比较好,一个好的方法就是,查看电影的评分,这样不就一目了然了吗?虽然评分高的电影不代表就一定好看,但是至少,说明大多数人都喜欢看对不对。说干就干,今天我们就爬取一下电影的评分

实现分析
爬虫程序都是这样,如果有反爬的话,就会比较难。没有反爬的话就会比较简单。提取数据方面,如果结构复杂,所需的内容杂乱,就会难以提取,如果是结构化的数据,比如说是ajax请求,直接能够拿到json数据的话,就会非常容易
恰好,今天电影评分既没有反爬,也是json格式的数据,所以一下子就可以轻松提取到了,非常的容易啊。当然,这也不是我们的功劳,主要还是对方网站比较大方
至于csv的读写,也是非常容易的,有很多种方式都可以实现。比如说,自己通过文件读写,按照csv的格式来读写文件。比如说通过能够操作csv的第三方库进行csv的读写。当然啦,还有一种比较简单的方式就是直接使用python中内置的csv模块。虽然功能比不上第三方库的功能强大,但是也是不错的选择
当然,也许还有的小伙伴可能不了解csv格式。其实,csv就和excel是类似的,也是能够做成excel的这种格式的,但是相对比较简单,如果你不知道这个话,可以另外去了解一下
import csv # 导入内置的csv模块
# 通过上下文管理器,正常的打开一个文件
with open("douban.csv", "w", newline="") as csvfile:
# 通过csv.writer(),创建一个writer用于后续写入csv文件
w = csv.writer(csvfile, delimiter=",")
# 通过writerow()的方法,写入csv的行
w.writerow(["标题", "评分", "地址", "图片"])
for row in r.json()["subjects"]:
w.writerow([row["title"], row["rate"], row["url"], row["cover"]])另外,可能有的小伙伴也会很困惑。如果要读取解析json文件的话,不是应该import json模块吗?为什么在下边的代码中完全没有使用到这一点呢?
事实上,在requests中,已经包含了json模块,而且有更简单的使用方式,因此直接通过requests使用json就可以了。不需要再额外的引入json的内置模块了
完整代码实现
import requests
import csv
from base64 import b64decode
headers = {"user-agent": "Mozilla/5.0"}
url = b64decode("aHR0cHM6Ly9tb3ZpZS5kb3ViYW4uY29tL2ovc2VhcmNoX3N1YmplY3RzP3R5cGU9bW92aWUmdGFnPeeDremXqCZzb3J0PXJlY29tbWVuZCZwYWdlX2xpbWl0PTIwJnBhZ2Vfc3RhcnQ9MA==").decode()
r = requests.get(url, headers=headers)
with open("douban.csv", "w", newline="") as csvfile:
w = csv.writer(csvfile, delimiter=",")
w.writerow(["标题", "评分", "地址", "图片"])
for row in r.json()["subjects"]:
w.writerow([row["title"], row["rate"], row["url"], row["cover"]])
程序运行结束以后,可以看到已经成功保存为了csv文件,效果如下

所以说,最后祝大家七夕节节日快乐,如果你能过节的话,可以根据评分赶紧去看电影啦。如果你没节可以过的话。嗯,好吧,你也可以自己去看看电影,要不,你不出门的话,别人不就都知道你没节可过了吗!
边栏推荐
猜你喜欢

Redis 全套学习笔记.pdf,太全了
![[Structural Internal Power Cultivation] The Mystery of Enumeration and Union (3)](/img/39/d20f45ccc86ebc4e5aebc8e4d0115f.png)
[Structural Internal Power Cultivation] The Mystery of Enumeration and Union (3)
Fiddler工具讲解
力扣刷题八月第一天
In the anaconda Promat interface, import torch is passed, and the error is reported in the jupyter notebook (only provide ideas and understanding!)
Support touch screen slider carousel plugin

Re regular expressions
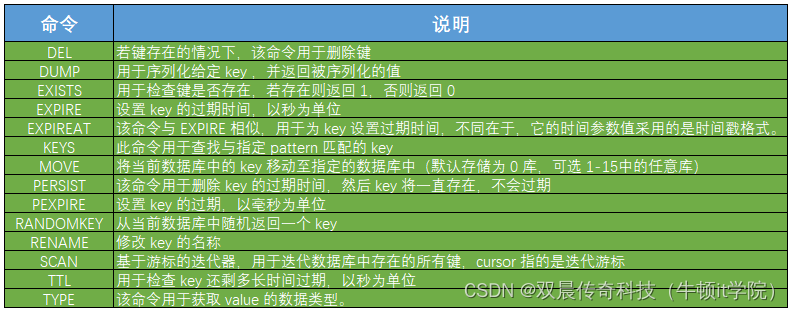
Redis常用命令
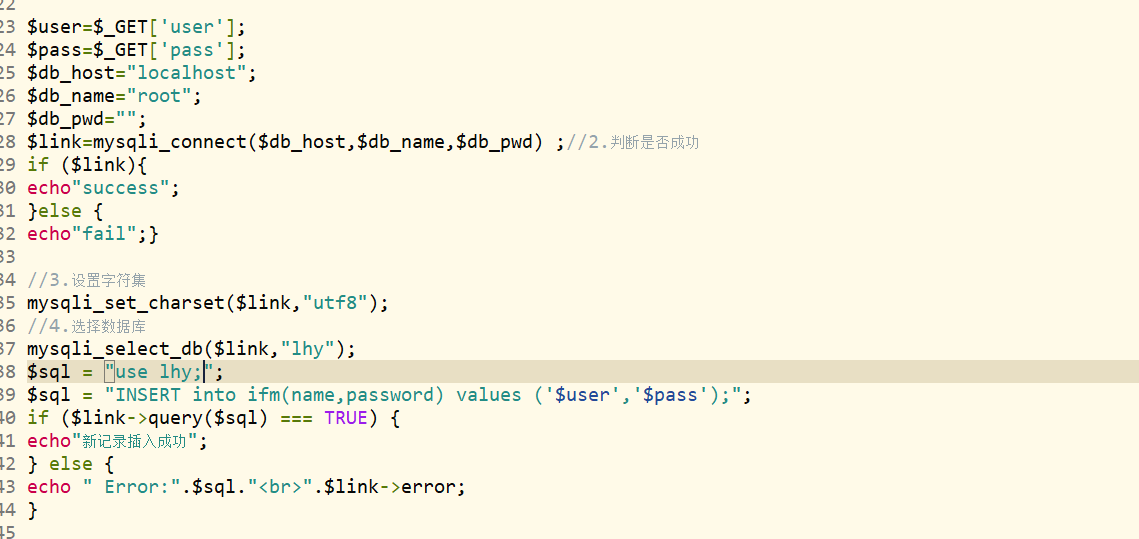
php向mysql写入数据失败

高端无主灯设计灯光设计该如何布置射灯灯具?
随机推荐
游戏模拟器成了外挂帮凶,灰产对抗再升级
DeFi 前景展望:概览主流 DeFi 协议二季度进展
U++ 创建UI
Discourse 清理存储空间的方法
Nn. Unfold and nn. The fold
环网冗余式CAN/光纤转换器 CAN总线转光纤转换器中继集线器hub光端机
v-if/v-else根据计算判断是否显示
每月稳定干2万
[NOIP2010 提高组] 机器翻译
【 LeetCode 】 235. A binary search tree in recent common ancestor
作为一个男人必须明白的22个道理
学习机赛道加速:请“卷”产品,不要“卷”营销
每一个女孩曾经都是一个没有泪的天使
网络安全研究发现,P2E项目遭遇黑客攻击只是时间问题
busybox 知:构建
行业应用软件项目经理三步曲
外企Office常用英语
Flink Learning 10: Use idea to write WordCount and package and run
Illegal key size 报错问题
Version number naming convention