当前位置:网站首页>并发编程复习
并发编程复习
2022-07-30 05:15:00 【未来很长,别只看眼前】
目录
7.HashTable 与 ConcurrentHashMap的区别
1.线程状态
1、Java中的线程状态
Java中把线程的状态分为6种:
new:使用new关键字创建线程后,此时创建出来的线程仅仅是一个Java对象,还没有和操作系统底层中真正的线程关联起来,所以这个时候这个线程不会被操作系统分配cpu去执行其他的代码,只有当你调用线程的start方法(会变成可运行状态),这个时候线程才会和操作系统中的线程关联起来,才会可以被操作系统分配cpu时间片。
runnable(可运行状态):处于可运行状态的线程才能被cpu分配时间片去执行代码。
terminated:当线程中的代码全部执行完毕了,线程就是变为终结状态,此时与底层相关联的资源也会被释放。
blocked:处于可运行状态的线程获取锁失败时就会进入阻塞状态,阻塞状态中的线程成功获取锁后就会进入可运行状态。
waiting:分为有限时间等待和无限时间等待,调用wait方法线程会进入无限时间等待,【并且会释放锁】,只有使用notify/notifyAll方法唤醒线程,唤醒后的线程【抢锁成功】才会进入可运行状态,否则抢锁失败就会进入阻塞状态;
timed_waiting:调用wait(long)和sleep(long)线程会进入有限时间等待,可以被特定的方法唤醒或者是等待时间一过,线程也会自动唤醒;注意的是,调用wait(long)的线程被唤醒后需要再去抢锁,抢夺成功才会进入可运行状态;而线程调用sleep(long)方法,只要时间一到该线程就会从等待状态变为可运行状态,不需要再去抢锁(因为调用sleep方法的线程是不会释放锁的)。
图解:

2、操作系统层面的线程状态
新建:创建线程,此时的线程还没有和操作系统建立联系。
就绪:线程有资格分到CPU时间片,但是此时还没轮到你(就是还没有分到时间片给你这个线程),这个过程就称为就绪状态。
运行:有资格分到cpu的时间片并且正在执行代码;
终结:结束线程。
阻塞:线程没有资格被分到cpu时间片,这个状态统称为阻塞状态。
总结为三个方面:
①分到CPU时间片的:运行状态。
②可以被分到cpu时间片的:就绪状态。
③分不到CPU时间片的:阻塞状态。
注意:Java中的runable涵盖了就绪,运行,阻塞IO;
看图:

2.线程池的核心参数
这里的线程池参数是指通过ThreadPoolExcete类来创建线程池中的七大参数。
七大参数:
核心线程池数目:最多保留的线程数,就是执行完任务后任然需要保留在线程池中的线程数目。核心线程数可以为0,就是线程池中全是救急线程,执行完毕后就对其进行销毁。
最大线程数目:最大线程数,数量等于 核心线程+救急线程数(救急执行完任务后一段时间会被销毁,通过生存时间来控制这个线程的存活时间)。
生存时间(keepAliveTime):针对救急线程。
时间单位:针对救急线程。
阻塞队列:当核心线程都在工作,此时再来任务,那么这个任务就会被放进阻塞队列(把任务缓存起来)。如果核心线程全部在执行任务并且这个阻塞队列放满了要执行的任务,那么这个时候再来任务,那么线程池就是去创建救急线程,把任务交给救急线程执行。当救急线程不再执行任务,那么它就会保留一段时间(keepAliveTime),然后超过时间后就会被销毁。
线程工厂:可以自己控制线程池中的线程的一些参数,比如可以为线程创建的时候起符合线程功能的名字。
拒绝策略:核心线程都在工作,任务队列也放满了,救急线程创建的个数也达到了上线,那么此时如果再来任务,就会触发这个拒绝策略(可以是抛异常,或者是不处理,或者是直接拒绝等等)。这个拒绝策略有四种。

3.对比sleep和wait
共同点:wait(),wait(long),和sleep(long) 的效果都是让当前线程暂时放弃CPU的使用权,进入阻塞状态。
方法归属不同:
①sleep(long) 是thread类中的静态方法
②wait(),wait(long) 都是object的成员方法,每个对象都有
醒来时机不同:
①执行sleep(long)和wait(long) 的线程都会在等待相应毫秒后醒来
②wait()和wait(long)还可以被notify唤醒,wait()如果不被唤醒那就会一直等待下去
③它们都可以被打断唤醒,调用interrupt可以打断两个线程,会抛异常。
锁特性不同:
①wait 方法的调用必须先获取wait对象的锁,而sleep则没有该限制(要获取锁才能调用锁对象的wait方法,不然会报非法的监视器异常)
②wait 方法执行后会释放对象的锁,允许其他线程来获得该对象锁
③sleep如果在synchronized代码块中执行,并不会释放对象锁
4.对比lock和synchronized
语法层面:
synchronized 是Java中的关键字,基于c++实现
lock 是接口,是Java API层面的工具,使用Java语言实现
使用synchronized时,退出同步代码块会自动释放锁,而使用lock时,需要手动调用unlock方法进行锁的释放
功能层面:
二者均属于悲观锁,都具有互斥,同步,锁重入的功能
lock提供了许多synchronized不具备的功能,例如获取等待状态,公平锁,可打断,可超时,多条件变量;synchronized只提供了非公平锁的实现,而lock提供了公平锁和非公平锁(一共会trylock()两次,两次都不成功后就会去阻塞队列中排队);
lock有适合不同场景的实现,如:ReentrantLock, ReentrantReadWriteLock;
性能层面:
在没有竞争的时候,synchronized是做了很多优化的,比如锁偏向,轻量级锁,在没有竞争的时候synchronized的性能还是不错的。
在竞争激烈时,Lock通常会有更好的性能。
补充:Lock锁中有两个重要的成员变量,owner和state 它们都是描述这个锁的状态,state为0表示没有线程对它加锁,如果一个线程对它加锁成功了,那么这个state就会变为1。owner表示那个线程拥有该锁,初始值是null。
5.volatile
①volatile到底能不能保证线程安全?
首先线程安全是需要考虑三个因素的:可见性,有序性,原子性。
可见性:一个线程对共享变量进行修改,另一个线程要能看到最新的结果。
有序性:一个线程内的代码要按编写顺序执行,要避免cpu对字节码的指令重排。(指令重排在单线程是没有问题的,但是在多线程就会出现问题!)
原子性:一个线程内多行代码以一个整体运行,期间不能有其他线程的代码插队。
注意:volatile只能保证共享变量的可见性和有序性,并不能保证原子性。
②可见性产生的原因竟然是因为JIT?!
可见性代码演示:
public class Volatile1 {
static boolean stop = false;
public static void main(String[] args) {
//新开一个线程来修改变量
new Thread(()->{
try {
Thread.sleep(100);
}catch (InterruptedException e){
e.printStackTrace();
}
stop = true; //修改静态变量中的值
System.out.println("新创建的线程把stop修改为ture....");
}).start();
//主线程执行
foo();
}
static void foo(){
int i = 0;
while (!stop){
i++;
}
System.out.println("循环的次数" + i);
}
}
从代码运行的结果我们可以知道,即便创建的线程修改了stop的值,但是这个主线程的foo方法中的while循环还是会一直执行,并没有停止,也就是说修改的值,对于这个主线程是不可见的!那么究竟是什么原因导致了修改的值对主线程不可见?
网上很多说法都是说是Java内存模型的问题,网上最主流的说法是:cpu把共享变量的值复制到自己的高速缓存中,然后下一次都是从高速缓存中去读取值,然后此时其他线程来修改内存中的值,此时修改后的内存中的值并没有同步到高速缓存区中,所以就导致这个while循环一直无法退出!
实际上这种说法是有问题的!!!证明如下:
如果按照这种说法,那么再加一个线程进来读取这个stop变量,那么应该也是不能读取到的,然后我们上代码来看看:
public class Volatile1 {
static boolean stop = false;
public static void main(String[] args) {
//新开一个线程来修改变量
new Thread(()->{
try {
Thread.sleep(100);
}catch (InterruptedException e){
e.printStackTrace();
}
stop = true; //修改静态变量中的值
System.out.println("新创建的线程把stop修改为ture....");
}).start();
//新创建一个线程来读取上一个线程修改的stop变量
new Thread(()->{
try {
Thread.sleep(200); //让该线程【晚一点】去读这个变量,其他线程修改后再去读
}catch (InterruptedException e){
e.printStackTrace();
}
System.out.println("第二个创建的线程读取到的stop值:" + stop);
}).start();
//主线程执行
foo();
}
static void foo(){
int i = 0;
while (!stop){
i++;
}
System.out.println("循环的次数" + i);
}
}
这个运行结果说明使用线程修改这个stop变量的值是同步到内存中去了,不然新创建的线程读取到的stop变量的值应该是false,但是运行的结果确实ture。
即便此时你再去加一个线程来读取这个stop变量,实际上它也是可以读取到这个stop的值,并且为ture。只有这个foo方法中的循环没有读取到stop修改的最新值。既然不是缓存的原因,那究竟是什么原因导致了foo方法中的循环对stop变量的修改不可见?
实际上是JIT及时编译器的原因!!!代码最后都是要交给cpu(解释器把字节码解释成机器码,cpu执行的就是机器码)来执行的,那么实际上cpu最开始还是需要从物理内存中把这个变量的具体的值读取出来。由于这个读取是非常的频繁,不同的机器读取的频率不同,我自己这台机器大概0.1秒可以读取百万次,此时JIT就会把这个foo方法当做热点代码(jit有自己的一套判断逻辑来判断你的这个代码是不是热点代码,比如循环的次数),对代码进行优化 -----> 直接对代码进行替换,直接把热点代码的字节码替换成解释后的机器码,比如之前没替换之前,每次需要对stop变量的值进行字节码解释成机器码,这一个过程使用花时间的,而替换之后就直接把这个stop变量的值变成机器码,并且把机器码缓存起来,下次后面的循环就不需要再使用解释器来解释这个字节码了。这样就少了解释的过程,效率自然就高了。 这就可以合理的解释为什么我们使用其他线程是可以读取到这个stop修改后的值。
证明:使用 JVM虚拟机参数 来停用这个JIT,看最后运行的结果是不是可以让整个while循环停下?
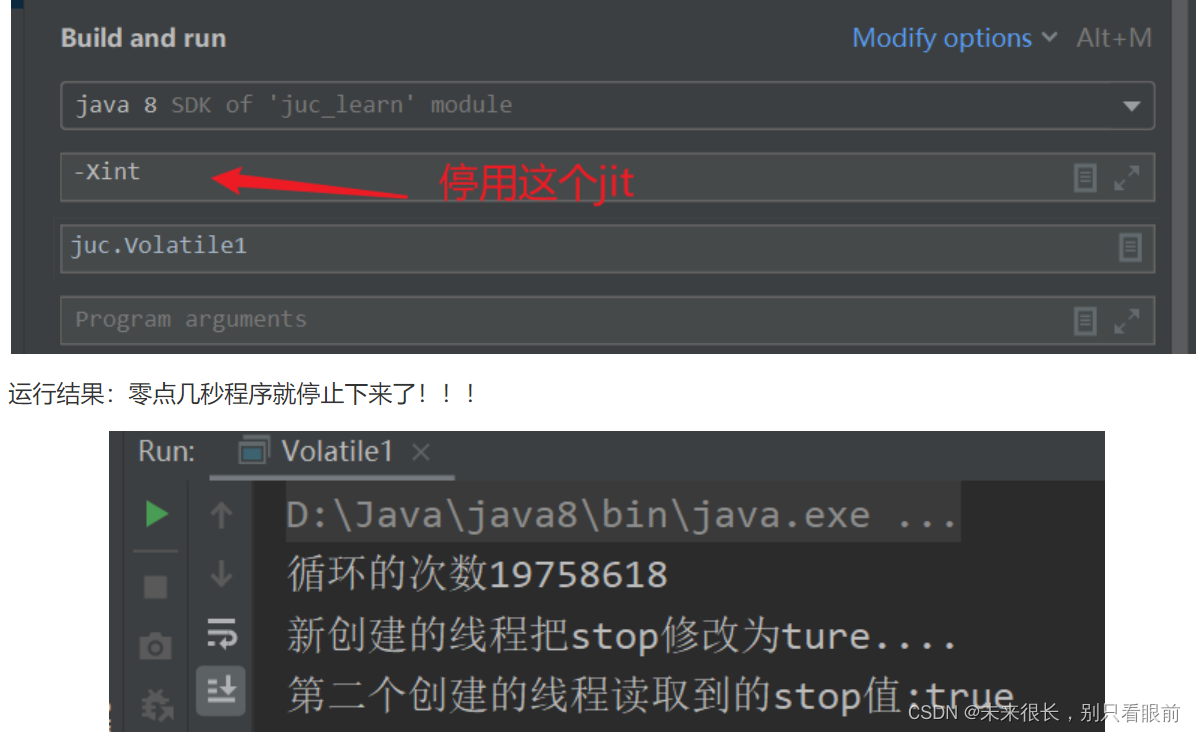
第二次运行结果:

程序都是可以停止下来了!!!
还有一种证明方式:就是让while循环的次数达不到升级为这个热点代码的阈值;把修改stop变量的线程的睡眠时间大大减少,让循环的次数大大的减少。(记得先把之前的jit停用参数给去掉)


注意:这第二种测试方法,可能由于每个人都机器性能的原因,会导致循环的次数不一致,并不是每个人都可以在1milis就可以测试出来的。
在解决可见性问题上,上面用来证明的两种方法都不是在实际生产中比较好的方法,根本解决方法还是要使用vilatile关键字,禁用JIT是会让程序的性能大打折扣。为什么volatile可以解决这个可见性的问题?那是因为一旦JIT发现这个volatile关键字,那么即便你的循环达到了升级热点代码的阈值或者是方法的调用次数达到了阈值,jit也不会去把这个代码变成热点代码。
③volatile禁止指令重排序的原理
volatile修饰的变量会被加上读写屏障;
对volatile修饰的变量进行写的时候,会阻止加了volatile代码行上面的代码跑到写屏障下面去;
对volatile修饰的变量进行读的时候,会阻止加了volatile代码行下面的代码越过屏障跑到屏障的上面去;
------> volatile使用的注意事项:(新手其实是很容易用错volatile这个关键字的)
写变量的时候,要让加了volatile修饰的变量的写在最后,就是普通变量写完了,再来写这个volatile修饰的变量。
读变量的时候,要让读取volatile修饰的变量,就是先读volatile修饰的变量,普通变量的读取在最后。
如果不遵循上面的注意事项,那么即便你用了volatile,可能也不能防止指令重排。
6.Java中的悲观锁和乐观锁
悲观锁的代表:synchronized 和 lock 锁。
其核心思想是:线程只要占有了锁,才能去操作共享变量,每次只有一个线程占锁成功,获取锁失败的线程,都需要停下来等待。
线程从运行到阻塞,再从阻塞到唤醒,涉及线程上下文切换,如果频繁发生,会影响性能。
实际上,线程在获取synchronized 和 lock 锁 时(做了优化),如果锁已被占有,都会做几次重复操作,减少阻塞的机会。
乐观锁的代表就是:AtomicInteger(底层是unsafe),使用CAS来保证原子性。
其核心思想是:无需加锁,每次只有一个线程能成功修改共享变量,其他失败的线程不需要停止,不断重试直至成功(自旋)。
由于线程一直运行,不需要阻塞,因此不涉及线程上下文切换。
它需要多核CPU的支持,切线程不应该成功cpu核数。
7.HashTable 与 ConcurrentHashMap的区别
1、HashTable 与 ConcurrentHashMap都是线程安全的Map集合。
2、HashTable并发度低,整个HashTable对应一把锁,同一时刻,只能有一个线程来操作它。
3、1.8之前ConcurrentHashMap使用了segment(段) + 数组 + 链表的结构,每个segment 对应一把锁,如果多个线程访问不同segment ,则不会产生冲突。

4、1.8及之后ConcurrentHashMap将 数组的每个头节点作为锁,如果多个线程访问的头节点不同,则不会产生冲突,增加了并发数量。(数据结构变成了 数组加链表(链表过长可以变成红黑树))

【上面两张图来源于博客:面试被问到 ConcurrentHashMap答不出 ,看这一篇就够了!_Java烂猪皮V的博客-CSDN博客】
8.threadLocal
1、ThreadLocal可以实现【共享资源】的线程隔离,让每个线程各用各的【资源对象】,避免争用引发的线程安全问题。(虽然局部变量也可以实现共享资源的隔离,但是局部变量的生命周期只有在方法内部才有效,而ThreadLocal是在整个线程内实现资源隔离,只有是同一个线程就行)
2、ThreadLocal同时实现了线程内的资源共享。
------> 线程间实现资源隔离,线程内实现资源共享。
ThreadLocal提供get和set方法来操作资源:
get方法是到当前线程获取资源
set方法是将资源存入当前线程
threadLocal原理:
其原理就是,每个线程内有一个ThreadLocalMap类型的成员变量,用来存储资源对象。
调用set方法,就是以ThreadLocal自己作为key,资源对象作为value,放入当前线程的ThreadLocalMap集合中。
调用get方法,就是以ThreadLocal自己作为key,到当前线程中查找关联的资源值。
调用remove方法,就是以ThreadLocal自己作为key, 移除当前线程关联的资源值。
ThreadLocalMap中的key为什么要设置为弱引用? (注意:ThreadLocalMap中的key是弱引用,但是value是强引用)
Thread可能需要长时间运行(如线程池中的线程),如果key不再使用,需要在内存不足(GC)时释放其占用的内存(----->为了在垃圾回收的时候释放key的内存)
但GC仅是让key的内存释放,后续还要根据key是否为null来进一步释放值的内存(值是强引用),【值的内存释放时机】有:
获取 key 发现null key
set key时,会使用启发式扫描(清除临近的null key),启发次数(扫描次数)与 元素个数 和 是否发现null key 有关。
remove时释放ThreadLocalMap中的value值(推荐),因为一般使用ThreadLocal时都把它作为静态变量(强引用),因此GC无法回收(一直无法被释放,时间久了容易导致内存泄露),所以前面两种情况只是理论上可行,而在实际生产中remove用得最多,通过remove来释放ThreadLocalMap中value的内存。
边栏推荐
猜你喜欢

Us to raise interest rates by 75 basis points in "technical recession"?Encryption market is recovering

IGBT wafers used in photovoltaic inverters

Hexagon_V65_Programmers_Reference_Manual (14)

即刻报名|如何降低云上数据分析成本?

力扣1047-删除字符串中的所有相邻重复项——栈
mysql cannot connect remotely Can't connect to MySQL server on 'xxx.xxx.xxx.xxx' (10060 "Unknown error")

容器化 | 构建 RadonDB MySQL 集群监控平台

无代码开发平台子管理员入门教程

el-table中加入el-input框和el-input-number框,实现el-table的可编辑功能

Unity踩坑记录 —— GetComponent的使用
随机推荐
C# One Week Introductory "C# - Classes and Objects" Day Six
mysql基础(4)
leetcode hot 100(刷题篇11)(231/235/237/238/292/557/240/36)offer/3/4/5
go版本升级
mysql isolation level
Acwing完全数
翻译 | 解读首部 Kubernetes 纪录片
1315_Use the LOOPBACK simulation mode to test whether the pyserial installation is successful
Docker-compose安装mysql
力扣1047-删除字符串中的所有相邻重复项——栈
Nuxt3 learning
MySQL基础(DDL、DML、DQL)
罗湖区工匠技能领军人才奖励项目申请指南
给小白的 PostgreSQL 容器化部署教程(上)
光明区关于促进科技创新的若干措施(征求意见稿)
Seata异常:endpoint format should like ip:port
Hexagon_V65_Programmers_Reference_Manual(10)
Three Solutions for SaaS Multi-tenant Data Isolation
Kyligence 出席华为全球智慧金融峰会,加速拓展全球市场
Small programs use npm packages to customize global styles