当前位置:网站首页>Convolutional neural network (III) - target detection
Convolutional neural network (III) - target detection
2022-07-26 06:04:00 【997and】
This study note mainly records various records during in-depth study , Including teacher Wu Enda's video learning 、 Flower Book . The author's ability is limited , If there are errors, etc , Please contact us for modification , Thank you very much !
Convolutional neural networks ( 3、 ... and )- object detection
- One 、 target location (Object localization)
- Two 、 Feature point detection (Landmark detection)
- 3、 ... and 、 object detection (Object detection)
- Four 、 Convolution of sliding window (Convolutional implementation of sliding windows)
- 5、 ... and 、Bounding Box forecast (Bounding Box predictions)
- 6、 ... and 、 Occurring simultaneously than (Intersection over union)
- 7、 ... and 、 Non maximum suppression (Non-max suppression)
- 8、 ... and 、Anchor Boxes
- Nine 、YOLO Algorithm (Putting it together:YOLO algorithm)
- Ten 、( choose ) candidate region (Region proposals)
The first edition 2022-07-18 first draft
One 、 target location (Object localization)

The task of image classification is to traverse the image by algorithm , Judge whether the object is a car ;
The next section is the problem of positioning and classification , There is not only a single location and classification , There are also multiple object positioning .
Image classification is no stranger , Input image to convolutional neural network , Output an eigenvector , Feedback to softmax Unit to predict the picture type .
If you are building a auto drive system , Objects may include : Pedestrians 、 automobile 、 Motorcycle and background . Positioning can make the neural network output more 4 A digital , Write it down as bx,by,bh,bw, Is a parametric representation of the bounding box of the monitored object .
The upper left corner of the figure is (0,0), The lower right corner is (1,1), Determine the specific location of the bounding box , You need to specify the center point of the red box (bx,by), Bounding box height bh, Width bw.
Define goal tags for supervised learning tasks :
Target tag y Is defined as follows : y = ( p c b x b y b h b w c 1 c 2 c 3 ) y=\left( \begin{array}{l} pc\\ bx\\ by\\ bh\\ bw\\ c1\\ c2\\ c3\\ \end{array} \right) y=⎝⎛pcbxbybhbwc1c2c3⎠⎞
pc Indicates whether it contains objects , If the object belongs to the former 3 class , be pc=1, The background is pc=0. Four parameters of the object output frame are detected , Judge from c1,c2,c3.
The car picture shown in the picture , As below ; When there is no detected object , For example, below the right picture of the car ,pc=0, Other parameters are meaningless .
Finally, the loss function of neural network is defined , The parameter is category y And network output yhat, Adopt square error strategy .
Two 、 Feature point detection (Landmark detection)
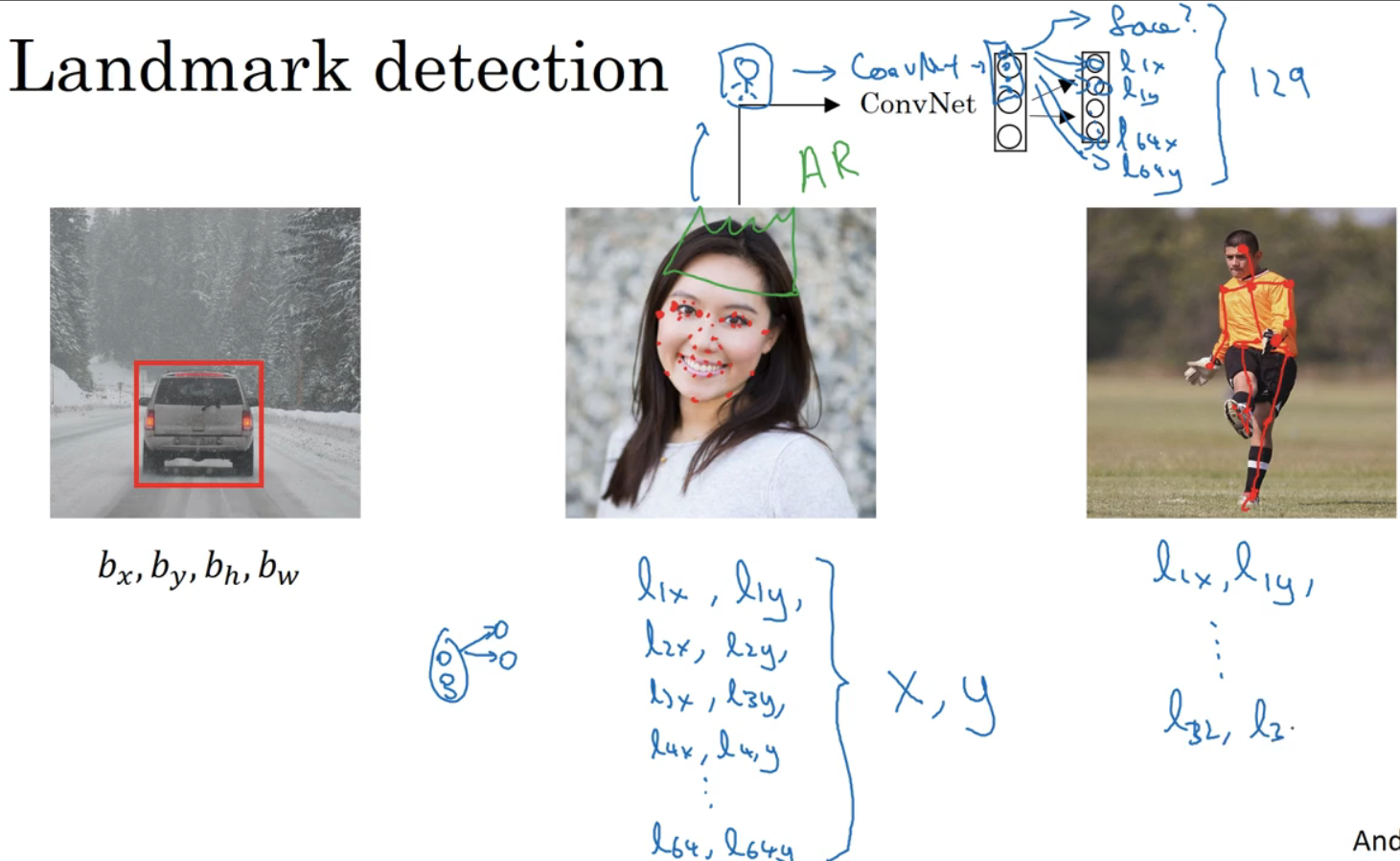
The neural network can output the feature points on the picture (x,y) Coordinate to realize the recognition of target features .
Suppose a human face recognition application is being built , Give canthus location , The output layer can output more lx and ly, As the coordinate value of the canthus . Want to know the four corner positions of two eyes , Yes (l1x,l1y) and (l2x,l2y), And so on . You can also focus on other features , If the mouth judges whether to smile , Or frown .
specific working means :
Prepare a convolution network and some feature sets , Input the face image into the convolution network , Output 1 or 0, Indicates whether there is a face , Then the output (l1x,l1y)…(l64x,l64y), There will be 129(64x2+1) Output units .
One last example , If you are interested in human posture , Some key feature points can be defined . Characteristic point 1 The characteristics of must be consistent in all pictures .
3、 ... and 、 object detection (Object detection)

Add and build a car detection algorithm :
1. Create a tag training set ,
2. Training convolution network ,
3. Convolution network output y,0 or 1 Indicates whether there is a car or not in the picture .
After training , It can be used to achieve sliding window target detection .
As shown in the test chart , A window of a specific size , Input it into convolutional neural network , Judge whether there is a car in the red box .
After the first judgment , Will process the second picture , Choose large stride and slide faster , Move the window at a fixed pace . Then use a larger red box .
This algorithm is called sliding window target detection . The disadvantage is to calculate the cost .
Four 、 Convolution of sliding window (Convolutional implementation of sliding windows)

Convert the full connection layer of neural network into convolution layer :
The above figure can be FC Replace with 5x5 Filter , application 400 individual 5x5x16 Filter ;
And then I add a 1x1 The convolution of layer , Output 1x1x400,
Finally through 1x1 Filter treatment of , Get one softmax Activation value , Through convolution network 1x1x4 The output layer of .
The paper refers to :[Sermanet,Pierre,et al.“OverfFeat:Integrated Recognition,Localization and Detection using Convolutional Networks.”]
Suppose the training set is 14x14x3, The test set is 16x16x3, Add yellow bars to the input picture , stay 16x16x3 Slide the window on the small image , Convolution network operation 4 Time , So the output 4 A label .
As shown in Fig 2 That's ok , Many calculations of volume and operation are repeated , The final output is 2x2x4.
If yes 28x28x3 The picture application of sliding window operation , The resulting 8x8x4 Result .
You can't rely on continuous convolution to recognize the car in the picture .
5、 ... and 、Bounding Box forecast (Bounding Box predictions)

As shown in the figure, the blue box may be the most matching detection box .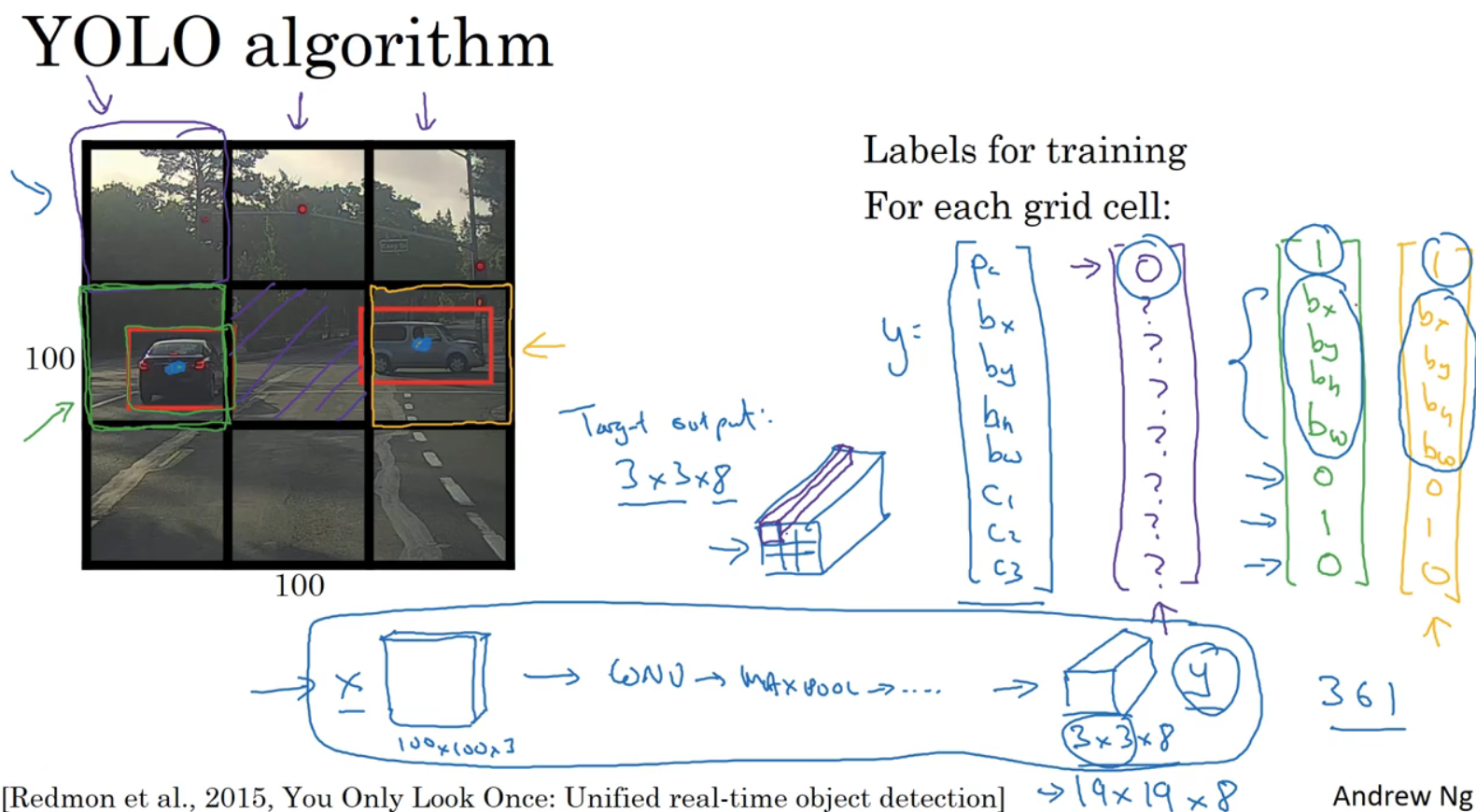
One of the more accurate bounding box algorithms is TOLO(you only look once) Algorithm . Put a grid on the image , As shown in the picture 3x3 The grid of , Apply image classification and location algorithm to 9 On a grid . Yes 9 Each box of boxes , Define the training tag as : y = ( p c b x b y b h b w c 1 c 2 c 3 ) y=\left( \begin{array}{l} pc\\ bx\\ by\\ bh\\ bw\\ c1\\ c2\\ c3\\ \end{array} \right) y=⎝⎛pcbxbybhbwc1c2c3⎠⎞
This picture has two objects ,YOLO The algorithm does , Take the midpoint of two objects , Then assign the object to the grid containing the midpoint of the object . So although the second 5 Each box contains two cars at the same time , But we take 4 and 6.
Because there is 3x3 The grid of , So the total output is 3x3x8.
If training 100x100x3 The neural network of , Through the convolution layer , Maximum pooling, etc , Finally get 3x3x8 Output size . When using back propagation to train neural networks , Enter any of x Mapping to this kind of output vector y.
The advantage of this algorithm is that the neural network can output accurate bounding boxes , So during the test , What we do is feed the image x, Then run forward to spread , Until you get the output y. Commonly used in practice 19x19x8, The mesh is much finer , The probability that multiple objects are assigned to the same lattice is much smaller .
YOLO The advantage of the algorithm is that it is a convolution implementation , Very fast , It can achieve real-time identification .
There are two cars , Take the car on the right as an example , There are objects in the red grid ,pc by 1, For its border , The upper left corner of (0,0), The lower right corner is (1,1),bx Probably 0.4,by about 0.3,bh by 0.5,bw by 0.9.bx and by Must be in 0-1 Between ,bh and bw May be greater than 1.
There are other parameterization methods , involves sigmoid function , Make sure 0-1 Between . Exponential parameterization ensures bh and bw It's all nonnegative .
6、 ... and 、 Occurring simultaneously than (Intersection over union)

Give a purple box , The result is good or bad ?
The intersection union ratio function calculates the intersection and union ratio of two bounding boxes .IOU=(A∩B)/(A∪B). General agreement , If IOU Greater than or equal to 0.5, That's right , Perfect overlap IOU by 1, You can set it higher .
7、 ... and 、 Non maximum suppression (Non-max suppression)

Target detection learned at present , It is possible to detect the same object multiple times . Non maximum suppression ensures that the algorithm detects each object only once .
Suppose pedestrians and cars are detected in the graph , Let's play one. 19x19 The grid of , Many grids will think there is a car .
Introduce the non maximum suppression step by step :
stay 361 The image detection and location algorithm is run once for each lattice . First look at the probability associated with each test result reported each time pc, the truth is that pc multiply c1、c2、c3. First look at the one with the highest probability , Highlight . Non maximum suppression will look at the remaining rectangles one by one , All have a high cross and comparison with the largest frame , These outputs will be suppressed .
Then look at the remaining rectangles , Next, the operation is similar to the above . These are the last two predictions .
As an example , Only do car testing , Yes 5 Parameters .
1. Remove all bounding boxes , Put all the predicted values , All bounding boxes pc Less than or equal to a certain threshold , such as pc Less than or equal to 0.6 Remove the bounding box of .
2. Then there is the highlight above .
8、 ... and 、Anchor Boxes

If you want to detect multiple objects in a grid , You can use anchor box.
Pictured , Pedestrian midpoint and car midpoint are almost in the same place , The results will not be detected .
anchor box thought :
Predefine two different shapes of anchor box, You can define category labels as shown in the figure .
1. Use anchor box Before , For each object in the training set image , Assign to the corresponding grid according to the midpoint position of that object .
2. Each object in the training image is assigned to a grid cell containing the midpoint of the object , as well as IoU Anchor box of the highest grid cell .
Now there are two boxes , Can be considered 3x3x2x8.
Image grid may have three objects , Or two box Same shape , Means to break the deadlock need to be introduced .
YOLO There are better practices in the later stage , namely K-mean Algorithm , Two types of object shapes can be clustered .
Nine 、YOLO Algorithm (Putting it together:YOLO algorithm)

Suppose the design algorithm detects three objects , Need to traverse 9 Lattice , Then the corresponding target vector is formed y.
As shown in Fig 8 A grid has objects , Red box , There are two anchor box, The detection is higher than one of them .

Pictured , First, abandon the one who is lower than me , If three objects are detected , Run non maximum suppression separately for each category , Processing the bounding box of the category to which the forecast results belong .
Ten 、( choose ) candidate region (Region proposals)

Sliding windows waste time in areas where there are obviously no objects .
This section cites R-CNN The algorithm of , It means with area CNN, This algorithm attempts to select some regions , It is meaningful to run convolution network classifier on these areas , Do not run the detection algorithm for each sliding window , Select only some windows to run convolution network classifier .
The segmentation algorithm detects color patches , Then make a classification .
R-CNN Too slow ;
Fast R-CNN The clustering step to get the candidate region is still very slow ;
Faster R-CNN Using convolutional neural networks , Instead of the traditional segmentation algorithm to obtain the color block of the candidate region .
边栏推荐
- PHP 多任务秒级定时器的实现方法
- 对接微信支付(二)统一下单API
- Unity2D 动画器无法 创建过渡
- 顺序查找,折半查找,分块查找 ~
- Full binary tree / true binary tree / complete binary tree~
- How to view the container name in pod
- Realize channel routing based on policy mode
- Modifiers should be declared in the correct order 修饰符应按正确的顺序声明
- Knowledge precipitation I: what does an architect do? What problems have been solved
- Redis persistence AOF
猜你喜欢
Ros2 knowledge: DDS basic knowledge

leetcode-aboutString

Ros2 preliminary: basic communication with topic

Acquisition of bidding information

ETCD数据库源码分析——Cluster membership changes日志

知识沉淀一:架构师是做什么?解决了什么问题

Introduction to three feasible schemes of grammatical generalization

金仓数据库 KingbaseES SQL 语言参考手册 (10. 查询和子查询)
![[MySQL must know and know] time function number function string function condition judgment](/img/b2/aa15bf4cd78a3742704f6bd5ecb9c6.png)
[MySQL must know and know] time function number function string function condition judgment

软件测试面试题全网独家没有之一的资深测试工程师面试题集锦
随机推荐
Mysql45 talking about logging system: how does an SQL UPDATE statement execute?
vagrant下载速度慢的解决方法
Six sixths -- it's a little late and a little shallow
Print linked list in reverse order
Servlet filter details
leetcode-Array
leetcode-aboutString
How can red star Macalline design cloud upgrade the traditional home furnishing industry in ten minutes to produce film and television level interior design effects
K. Link with Bracket Sequence I dp
平衡二叉树(AVL) ~
Excitation method and excitation voltage of hand-held vibrating wire vh501tc acquisition instrument
Jincang database kingbasees SQL language reference manual (5. Operators)
How to view the container name in pod
二叉树的性质 ~
Solve vagrant's error b:48:in `join ': incompatible character encodings: GBK and UTF-8 (encoding:: Compatib
EM and REM
"Recursive processing of subproblems" -- judging whether two trees are the same tree -- and the subtree of another tree
Kingbasees SQL language reference manual of Jincang database (7. Conditional expression)
光量子里程碑:6分钟内解决3854个变量问题
Etcd database source code analysis - cluster membership changes log